-

Welcome to Kadakkk!
-
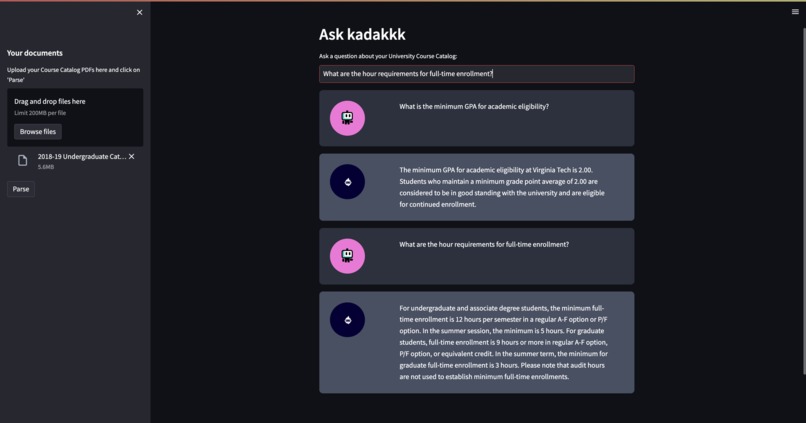
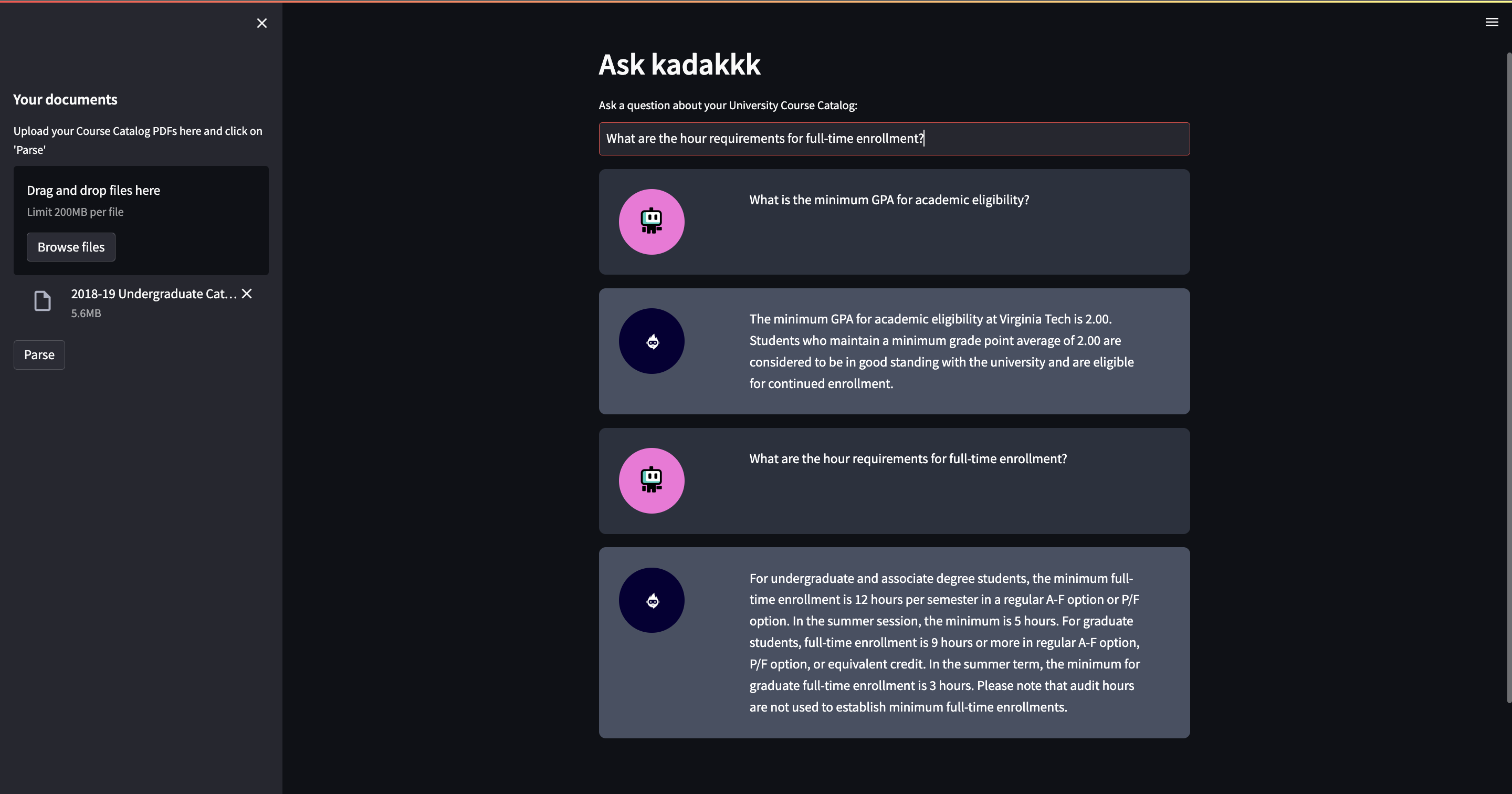
Kadakkk's UI interface

Inspiration
Empowering Students with Seamless Access to Course Information
What it does
Our application processes LONG University Course Catalog pdfs uploaded by the user. It extracts text from the PDFs, splits the text into chunks, and creates a conversational retrieval chain based on the processed text. Users can ask questions related to the documents, and the system provides relevant responses using language models.
How we built it
We built the application using Flask and Python. We utilized Streamlit for the user interface. Text extraction from PDFs was done using PyPDF2. The text was split into chunks using the langchain library's CharacterTextSplitter. We used OpenAIEmbeddings and HuggingFaceInstructEmbeddings for generating embeddings, and FAISS for creating the vector store. For conversational responses, we employed the ChatOpenAI model.
Challenges we ran into
One of the main challenges was figuring out how to work with embeddings effectively. We also faced difficulties in optimizing the processing time for large documents.
Accomplishments that we're proud of
We are proud of learning about embeddings, vectors, NLP, and working with large language models (LLMs) for conversational purposes.
What we learned
Through this project, we gained valuable experience in working with LLMs, embeddings, and various NLP techniques. We also improved our understanding of AI/ML workflows.
What's next for Kadakkk
In the future, we aim to improve the processing time of the application to make it more efficient. We also plan to enhance the user experience by adding more features and refining the conversational capabilities of the system.
Elevator Pitch
Have a question related to your courses or course catalog? Don't want to sift through lengthy documents? Simply ask Kadak! Our application processes your documents, extracts relevant information, and provides quick and accurate responses to your queries. Say goodbye to long searches and hello to instant answers with Kadak!



Log in or sign up for Devpost to join the conversation.