-
-

Front Page
-

Problem
-
Architecture
-
2.0
-

Flow
-
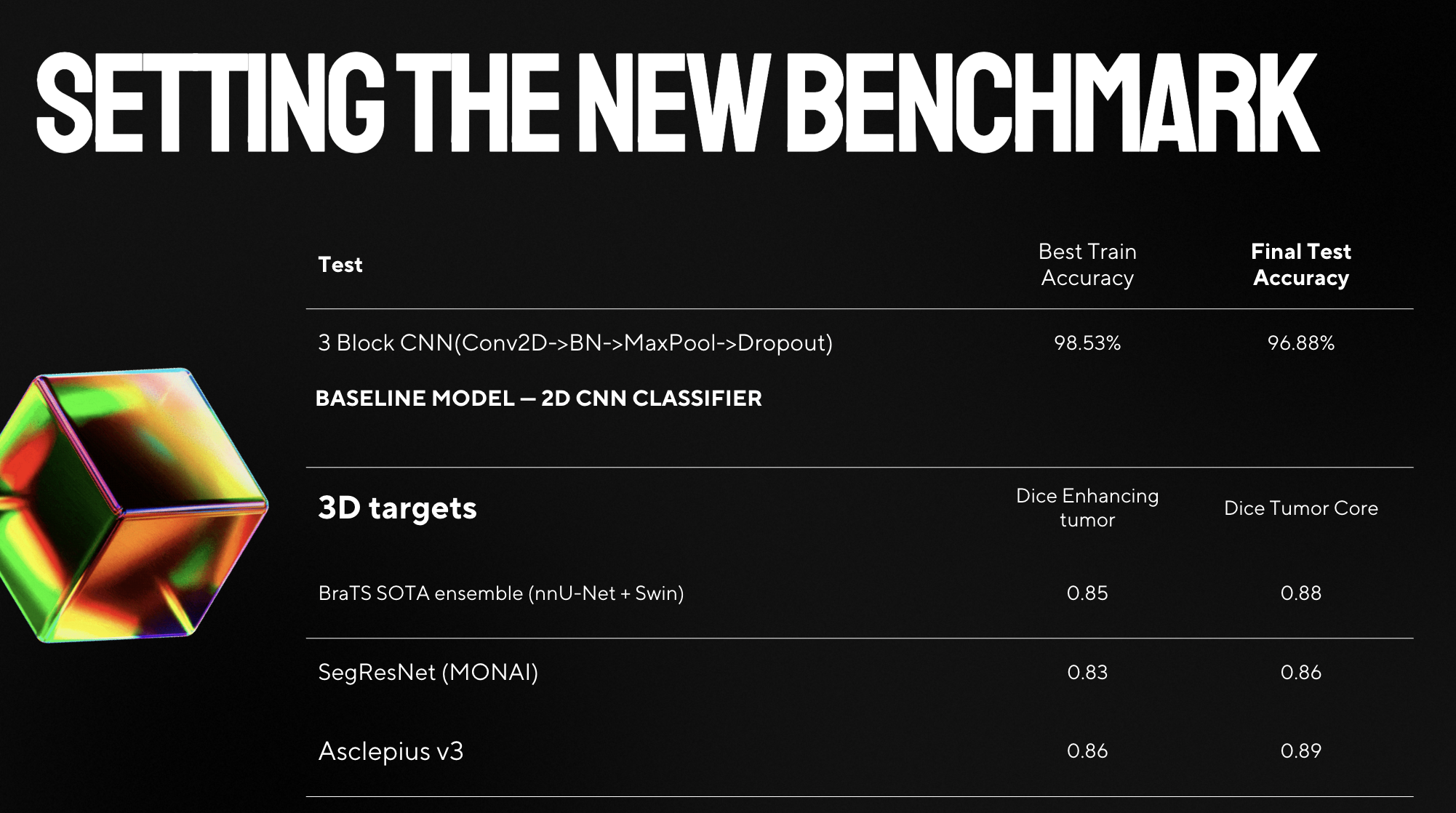
Benchmarks
-

Target Market




Inspiration
Most medical AI today operates in a vacuum it looks at a single scan, makes a classification, and stops there. But oncology isn't a single snapshot; it's a dynamic, evolving timeline. As Team Deranked , our goal was to build something that mirrors how real doctors think. We didn't just want to detect a brain tumor; we wanted to understand its trajectory. Asclepius was inspired by the need to reduce the immense cognitive load on oncologists by bridging the gap between raw pixel perception (MRI scans) and longitudinal clinical reasoning, turning isolated data points into a cohesive, actionable patient story.
What it does
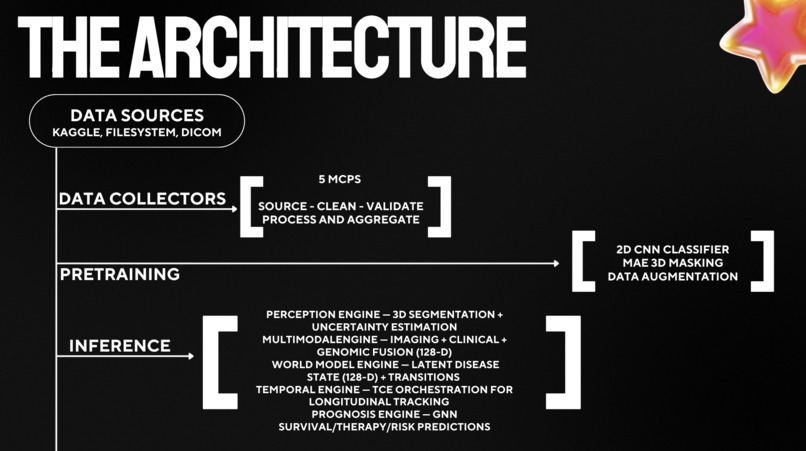
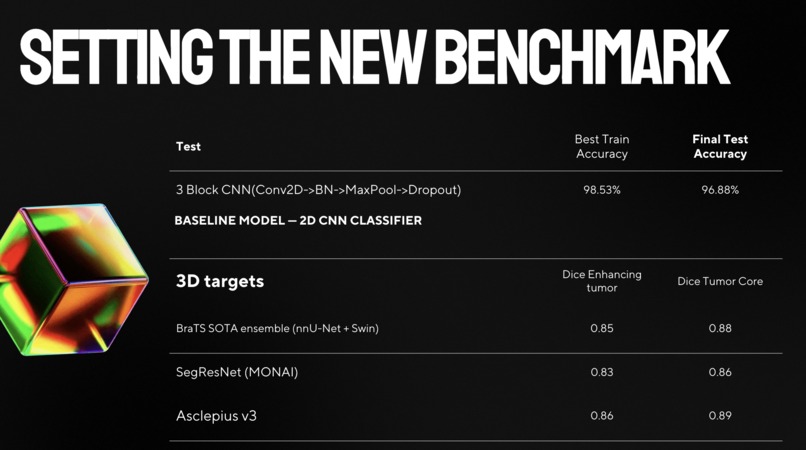
Asclepius is a full-scale Clinical Intelligence Engine. At its core, it ingests patient MRI scans and runs them through a custom CNN classifier to detect and segment brain tumors. But that's just layer one.
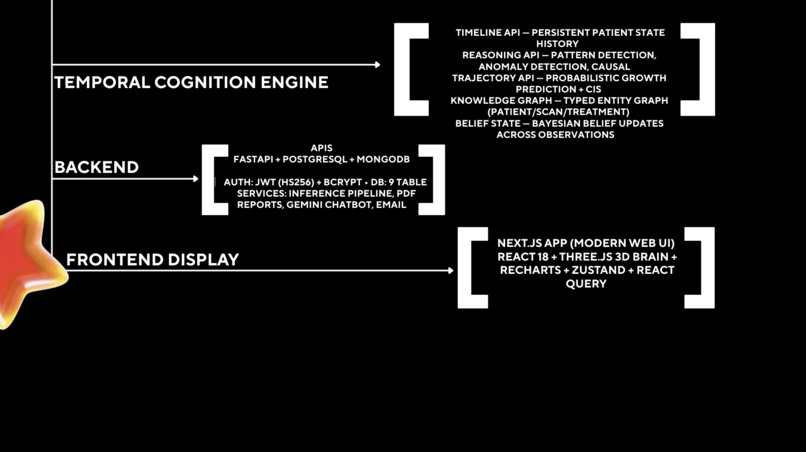
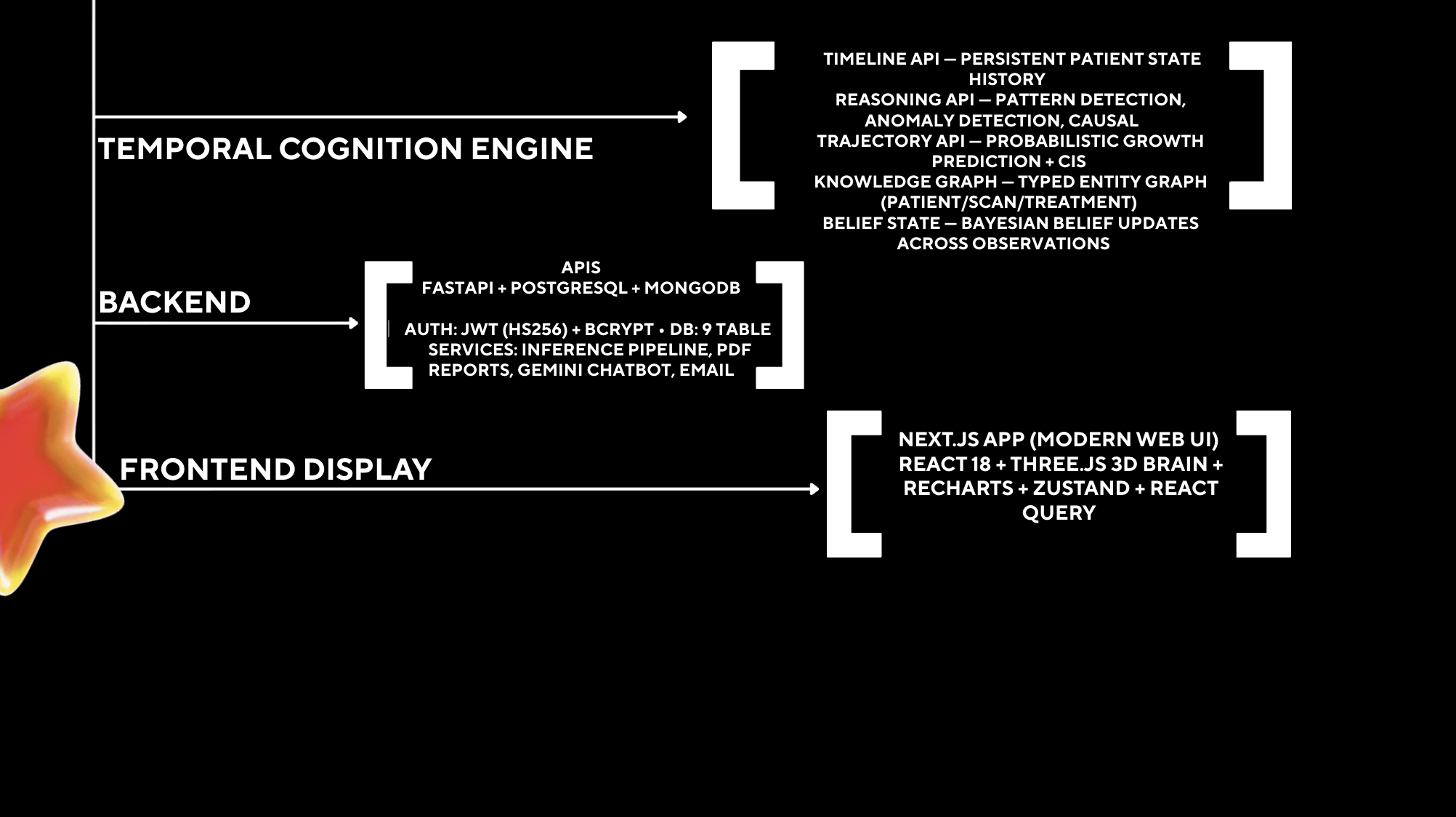
The system then feeds this data into our Temporal Cognition Engine (TCE), which tracks the tumor's progression over time. It compares current scans to historical data, models the latent state of the disease, and predicts patient prognosis. Finally, using a RAG pipeline powered by MongoDB Atlas and Gemini 2.5 Flash, it synthesizes all this multimodal data scans, clinical history, and treatment timelines into readable, highly accurate clinical summaries and therapy recommendations for the physician.
How we built it
We architected Asclepius with a strict separation of concerns, heavily utilizing a modern, high-performance stack:
Frontend: We built a highly interactive Command Center using Next.js 14, styled with Tailwind CSS and animated with Framer Motion. We also integrated Three.js for rendering complex 3D brain visualizations in the browser.
Backend: We used FastAPI for its incredible speed and native async support, hooking it up to a PostgreSQL database (via async SQLAlchemy) to handle complex relational patient data and lineage tracking.
The Brains: The core ML pipeline utilizes TensorFlow/Keras for the vision models. To handle the cognitive reasoning and memory, we leveraged MongoDB Atlas for vector search and similarity matching, piping context into Google Gemini 2.5 Flash to power the AI clinical assistant and automated reporting.
Challenges we ran into
The Temporal Cognition Engine (TCE): Building a 4-layer architecture that doesn't just store events but actually performs delta analysis and causal reasoning between different points in time was incredibly complex.
Multimodal Orchestration: Synchronizing the standard inference pipeline (the CNN) with the cognitive pipeline (Gemini + RAG) required building a robust internal data orchestrator so the Next.js frontend wouldn't bottleneck while waiting for responses.
Local Hardware Constraints: Training complex 3D medical imaging models and running heavy vector intelligence locally requires serious compute. Balancing the load between standard CPU operations and ensuring the models were optimized enough to iterate quickly was a constant tightrope walk.
Accomplishments that we're proud of
The UI/UX: We managed to avoid the clunky, outdated interfaces typical of medical software. The Next.js frontend is sleek, intuitive, and genuinely looks like a production-ready product.
Graceful Degradation: Designing the system so that the core PostgreSQL + FastAPI backend still functions perfectly even if the MongoDB vector intelligence layer drops offline.
What we learned
Building Asclepius was a masterclass in full-stack AI deployment. We deepened our understanding of integrating standard REST APIs with complex, multi-agent AI pipelines. We learned how to structure unstructured medical data into vector embeddings for similarity search, and we figured out how to write robust Pydantic schemas that keep data strictly validated across a massive Python backend.
What's next for Asclepius
We have a clear roadmap laid out in our codebase:
Federated Learning: Implementing the federated/ module to allow different hospitals to train the core models collaboratively without sharing sensitive patient data.
Regulatory Compliance: Fleshing out the regulatory/ templates to align the software with FDA and EU MDR standards for Software as a Medical Device (SaMD).
Self-Supervised Pretraining: Utilizing MAE 3D and SimCLR 3D to improve the model's baseline understanding of volumetric medical data without requiring massive amounts of labeled data.

Log in or sign up for Devpost to join the conversation.