-
-
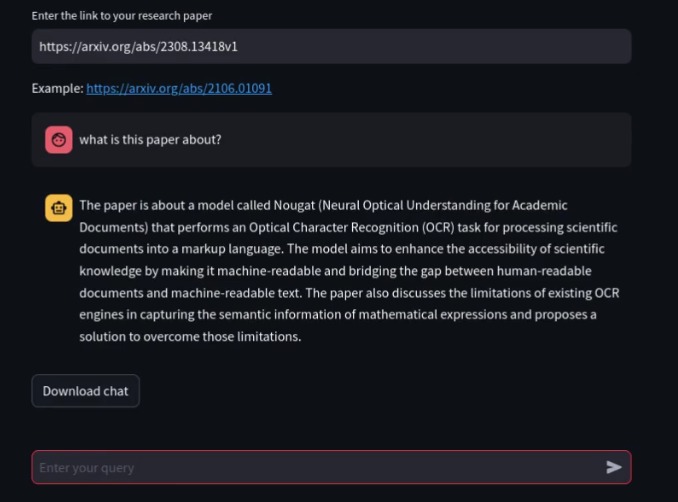
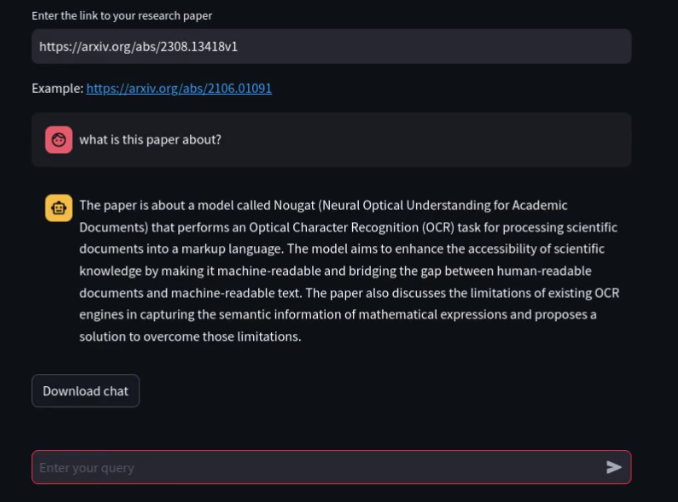
How Arxix-Researcher works
Inspiration
Let's face it! Reading 100s of pages of research papers is never a fun way to spend your time. That's why I have created Arxiv-Researcher
What it does
Arxiv-Researcher helps you gain insights from Arxiv research papers faster by allowing you to chat with the research paper.
How we built it
Under the hood, the Arxiv paper gets downloaded and the text is extracted from the PDF and is converted into embeddings which are then stored in a vector database. When the user asks a question, the vector database retrieves relevant passages and then GPT summarises them, resulting in a coherent answer.
Challenges we ran into
- Retrieval of text from PDFs is not an easy task! Especially, text from tables. Thankfully, Langchain had a perfect solution for this problem.
- Streamlit kept on refreshing everytime a small change is made in the app, causing the app to run from the start. I had to learn about state management in streamlit which was very confusing at the start but I got a hold of it pretty soon and made this app a reality.
- I couldn't host the app because streamlit kept on throwing errors in the terminal. However, the app works perfectly fine on your local.
What's next for Arxiv Researcher
Right now, we only support Arxiv, but we plan on supporting other popular research paper archives as well.
Built With
- langchain
- python





Log in or sign up for Devpost to join the conversation.