-
-
Home page
-
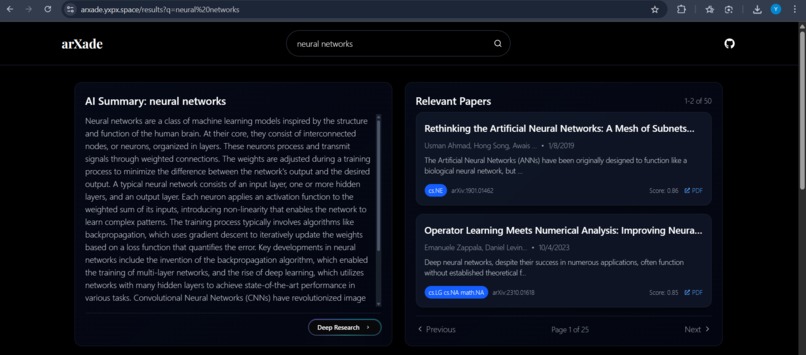
Results page (a)
-
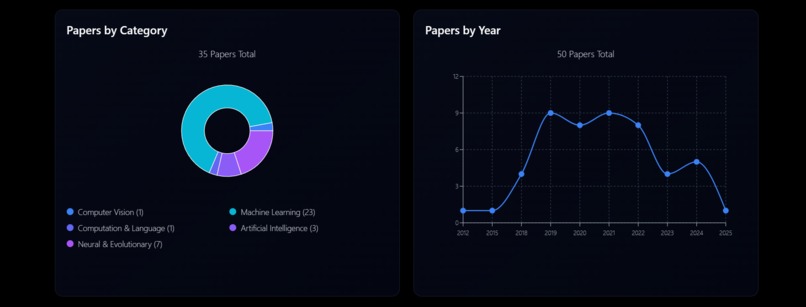
Results page (b)
-

Results page (c)

Inspiration
Existing research discovery tools often make finding specific, niche papers incredibly difficult. Researchers face information overload and keyword limitations, leading to inefficient and time-consuming searches for truly relevant material on platforms like arXiv. We aimed to build a smarter, more intuitive solution.
What it does
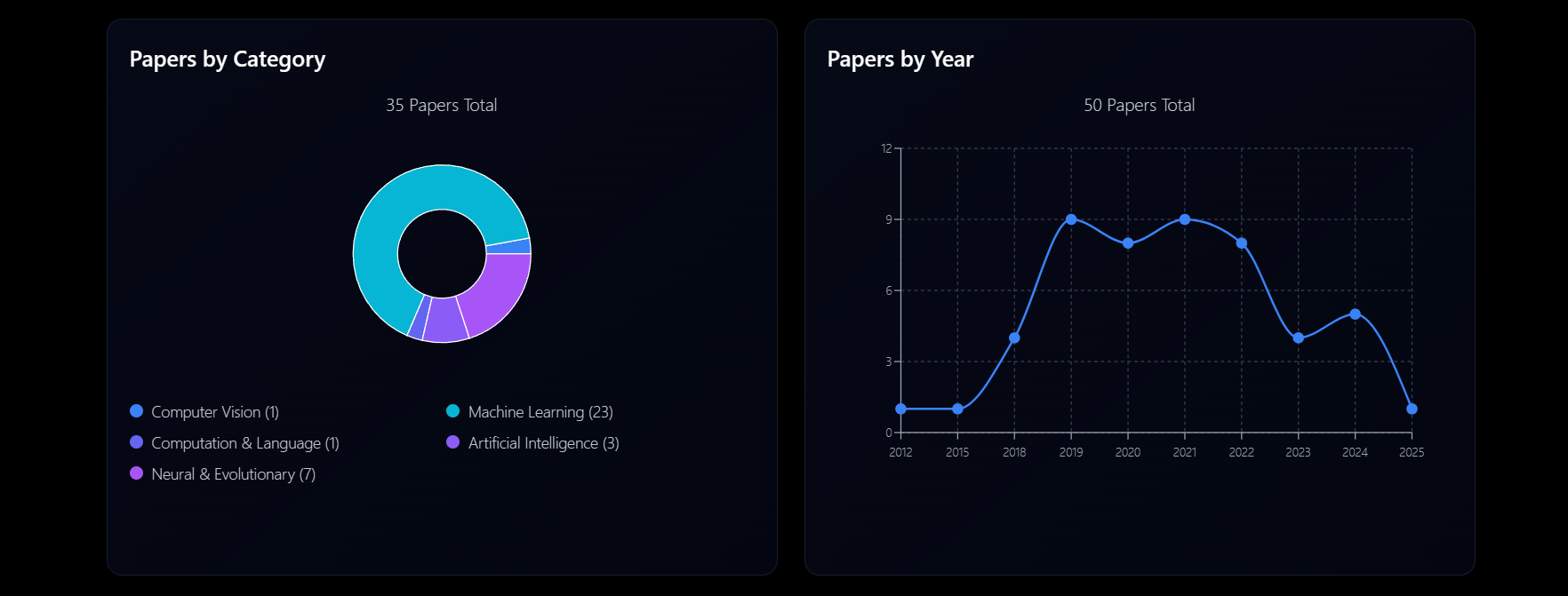
arXade enhances the process of finding arXiv papers by implementing intelligent search powered by text embeddings. This technology allows our system to comprehend the conceptual meaning behind a user's query, rather than simply matching keywords. As a result, users can locate highly relevant research papers more accurately and quickly. Furthermore, arXade provides AI-generated summaries, utilizing the Gemini AI for rapid insight extraction, and offers contextual recommendations to facilitate deeper research analysis. The platform also includes data visualization features, such as word clouds, category distribution and timeline charts, to offer unique perspectives on research trends.
How we built it
Our text embeddings were generated using Gemini API's text-embedding-004 model, subsequently quantized to int8 to optimize for efficiency. This processed dataset, comprises over 450,000 papers and derived from primary arXiv paper categories, is hosted on MongoDB. For the interactive user interface, Next.js was utilized, while FastAPI handled backend functionalities. MongoDB Atlas served as the database, notably for its vector search capabilities. The Google Gemini AI is a core component, powering all our artificial intelligence features, including summaries and deep research analysis. To ensure consistent environments and efficient, serverless scalability, the entire application is containerized using Docker and deployed on Google Cloud Run.
Challenges we ran into
Building arXade during a hackathon brought up several tough challenges. A big one was handling the huge dataset of arXiv metadata embeddings. We tried different methods like quantization and dimensionality reduction, and decided on quantization to make things run faster. Also, this was our first time using Google Cloud Run, so getting our multiple services to deploy and work together took a lot of debugging and time. Getting past these hurdles and making sure our frontend, backend, and the Gemini AI talked to each other smoothly and securely was a really good learning experience.
Accomplishments that we're proud of
We're really proud of several things we achieved. First, we successfully built a semantic search engine that actually understands what you mean, not just the words you type. Getting those AI-powered summaries and smart recommendations working with Gemini AI, which truly help in research, was another key achievement. We also managed to optimize our database for performance, which was crucial. And finally, successfully containerizing and deploying our entire multi-service application on Google Cloud Run during the hackathon was a major win for our team.
What we learned
Our team gained a much better understanding of vector databases, especially how they work within MongoDB Atlas for semantic search. We also got hands-on experience with advanced features of the Google Gemini AI and learned how to fine-tune AI prompts. Debugging and getting our complex, containerized application up and running across different Google Cloud services, particularly on Google Cloud Run, gave us huge insights into modern cloud development.
What's next for arXade
Our immediate goal would be to expand the dataset to include a wider range of scientific fields, moving beyond just computer science. We're also keen to explore more advanced AI features. Imagine personalized research feeds tailored to your interests, or even a system where you can ask questions and get direct answers from paper collections. Beyond that, we're thinking about adding collaborative research spaces and connecting with other academic platforms to build an even more complete research environment.
Built With
- docker
- fastapi
- google-cloud
- mongodb
- nextjs



Log in or sign up for Devpost to join the conversation.