-
-

Our landing page
-
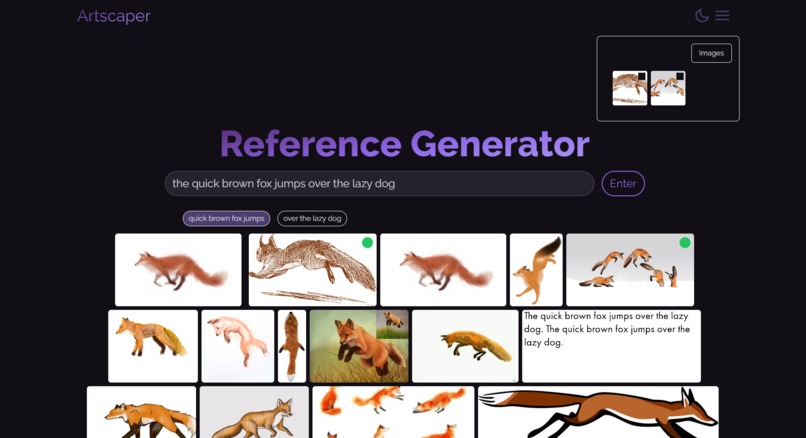
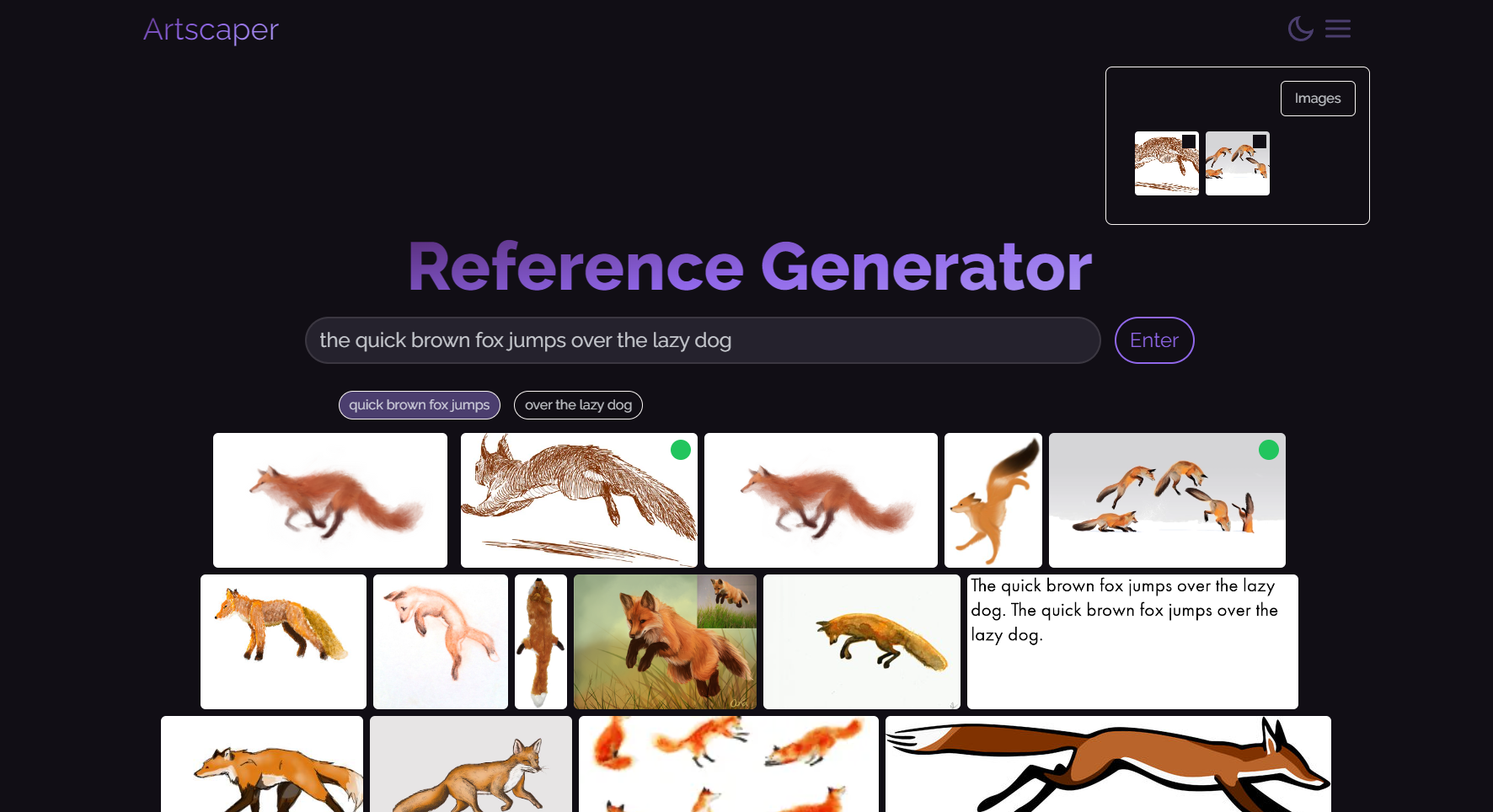
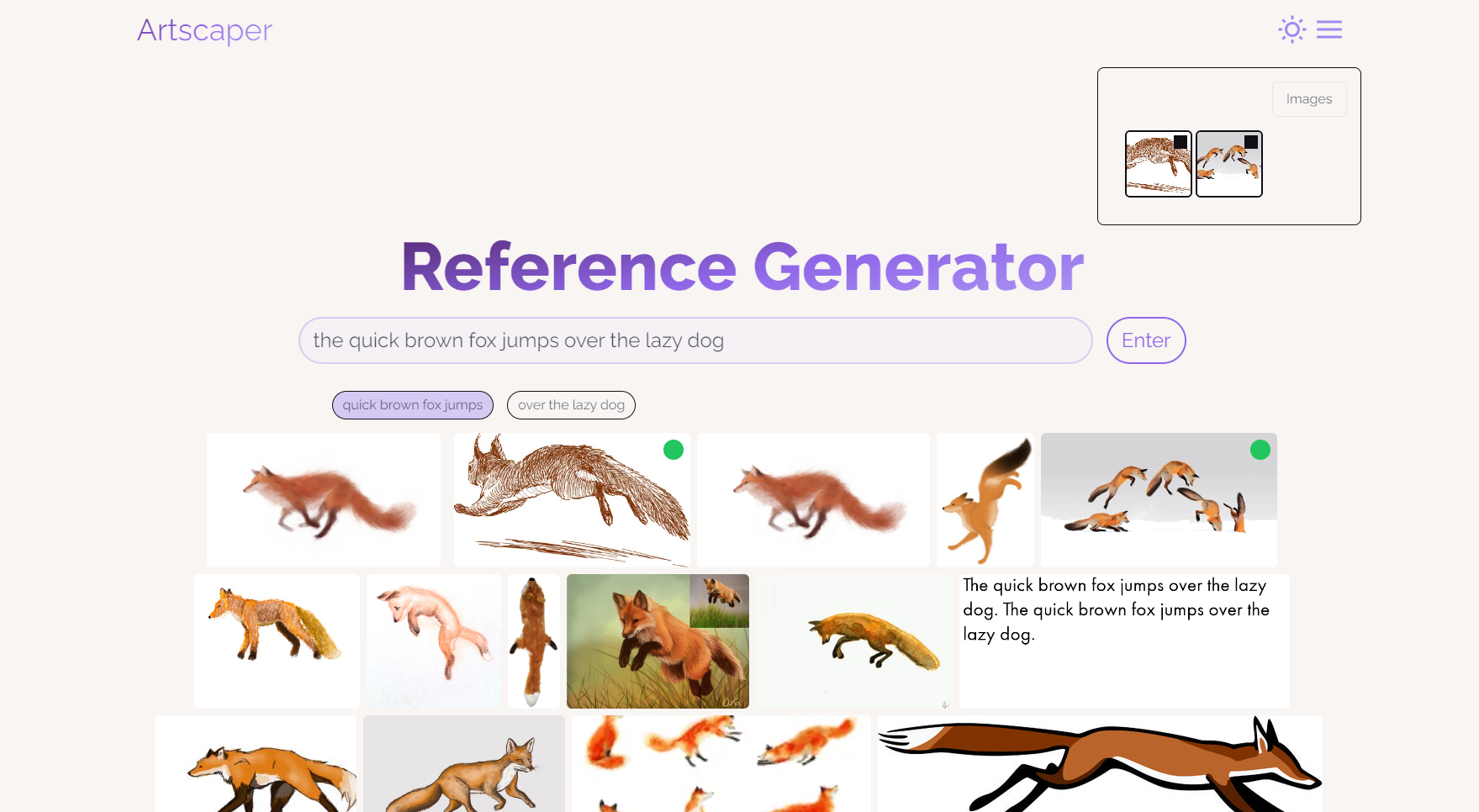
Results from a sentence query
-

Light mode!
-
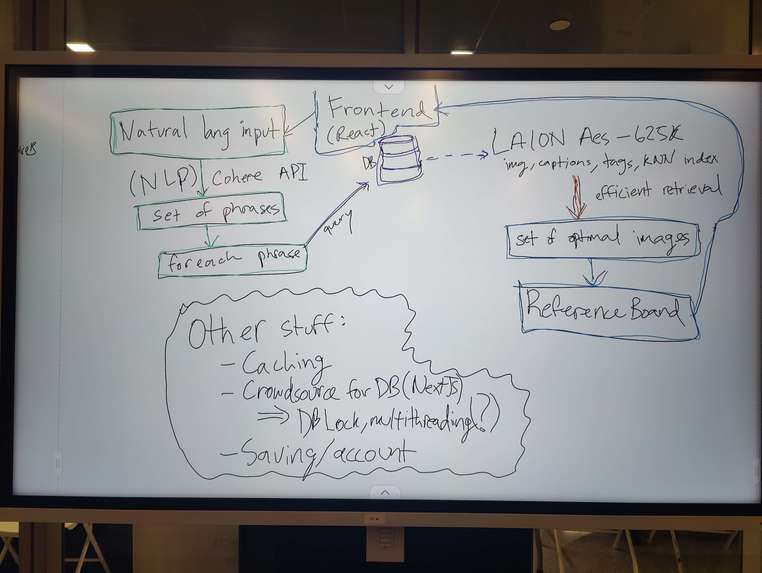
Our initial systems diagram


Inspiration
Forrest is the main inspiration for this project - along with his studies in engineering, he considers himself to be an amateur digital artist. With two years of experience, it became clear to him that as art was moving towards digital expansion, the amount of resources increased, but to an extent where information became overloaded and decreased in quality.
One of the most time-consuming parts of the digital art workflow is finding a good set of reference images - for example, in order to draw this piece of art, Forrest had to find images of things such as Tibetan clothing and the lighting of fire. Since he couldn't find all these things easily, he had to create his own reference images in Blender, a 3D modeling software.
We believe that as digital resources grow, artists should have more efficient means of getting their creative ideas onto paper. So, our team aims to create an all-in-one web suite for artists to discover resources, grow their brand, and network with other art communities. In accomplishing this, we set out to start by making a tool which allows artists to discover relevant reference images better than current tools like Pinterest and Google Search.
What it does
Our tool allows users to type in a description of what they want to draw. For example, an input description could be "A Tibetan huntress wearing traditional oriental dress is on the hunt at night, as fire blazes around her."
If you were to type this description into Pinterest or Google Search, you wouldn't be able to get reference images for each part - i.e. a Tibetan huntress, a traditional oriental dress, night, and a blazing fire.
This is exactly what our tool does. We use natural language processing to automatically break down that description into relevant phrases and generate new phrases the user may draw inspiration from. They'll see multiple images for each phrase ranked by similarity, can move between phrases, and have the ability to favorite the images they want to use. There's also a safeguard system in place to reject input descriptions which may be toxic or antagonistic.
How we built it
- The frontend is React/Next.js. The frontend sends a request to the backend API, calling a Python script and inputting a sentence from the user describing what they want to get reference images for.
- The Python script will start by checking the phrase for toxicity using a large-scale machine learning architecture called a transformer, which has been trained on millions of toxic sentences. If the input sentence is classified as "too toxic", a warning notification gets sent back to frontend, where the user will see that their request has been rejected.
- If the input is accepted, the script uses a model from spaCy, an NLP library - this model is also pre-trained on several transformers. The model will annotate the part of speech for each word in each sentence, and will generate a dependency graph to show which words relate to other words. Based on this, we generate short chunks of phrases centered around a noun. For each of these chunks, we'll do a bit more analysis to reorder words in the phrases and remove filler words.
- We also rank phrases so we only show the most relevant ones to users. Since our generated phrases don't have rankings, we estimate them by calculating confidence values for another NLP algorithm called RAKE (Rapid Automatic Keyword Extraction) through a library called NLTK (the Natural Language Toolkit). We also factor in some custom heuristics of our own (capital letters, phrase length).
- Once complete, a list of the best ranked phrases are sent back to the frontend. This frontend will query a cloud endpoint which hosts the LAION-5B dataset, a dataset with 5 billion images, each with their own caption and aesthetic score. This is also the dataset which is used by Stable Diffusion, a popular model which generates art.
- For each phrase from our backend, we use an efficient search library called Faiss, which can quickly calculate the similarity between the phrase and the captions in the dataset. It also uses an algorithm called K-nearest neighbors to find a range of images quickly, as it would be very inefficient to compare 5 billion images one by one.
- Finally, the user will see a list of images for each phrase sorted by similarity.
- The site is hosted with AWS.
Challenges we ran into
- We ran into a ton of dependency issues, specifically with Canvas and Konva.
- It turns out that breaking down a sentence into a set of relevant phrases is an incredibly hard problem, and is an active area of research in natural language processing. We tested over 10 different APIs, including Cohere, OpenAI's GPT-3, and several large architectures on Hugging Face before realizing that they weren't well suited for the information we were looking to get out of each description.
- Deploying to the cloud has its own challenges, such as determining hardware and optimizing our code to be runnable on sustainable computing systems. We needed to decide on what types of frameworks to use, what services to use (Firebase vs AWS), as well as how we are designing for future-proofing.
- CSS is hard.
Accomplishments that we're proud of
- Before entering this hackathon, we committed fully to the goal of future-proofing our code. As a result, every decision we've made on the systems side has been oriented towards writing code that can be reused later on. For example, we chose the harder route of using LAION over a Google Search API because we knew that Google was trend-based, and wouldn't be reliable for artists looking for a more constant set of references.
- This was by far the most time any of us have dedicated to a hackathon. We're proud of the commitment we were able to show and hope to carry that same spirit as we develop this platform beyond this hackathon.
What we learned
- We learned increasingly that machine learning models are only as good as the data given to it. We initially tried to use some models like co.here and OpenAI's GPT-3 for captioning and phrase detection; however, they were not trained to determine phrases from semantics, even if their zero-touch algorithms are very efficient.
- We also learned about the importance of UX in user design. Since we are a heavily customer focused and are working with creatives who enjoy aesthetics, we spent a good deal of our time discussing UX and UI ideation and how we can have our users aid us in our development.
- Finally, we learned that infrastructure for a system like Artscaper is a lot more complex than we thought. We were initially keen on pushing out many more features, and didn't consider the amount of moving parts we'd need to keep track of.
What's next for Artscaper
- Continue to improve on our semantic keyphrase extraction systems (combining with large scale transformers, advanced regex queries with part-of-speech tags, max spanning trees for dependency graphs, graph neural networks, etc.)
- Expand to a richer variety of datasets (Image Emotion, AffectNet, Fashion-Gen, etc.) to account for additional intangibles like mood, lighting, and environment
- Transition to crowdsourced datasets to allow for references which are curated by artists, for artists
- Build account systems to allow users to favorite reference boards and interact with others
- Conduct outreach with artists and gather a strong initial user base
Built With
- amazon-web-services
- bert
- faiss
- hugging-face
- k-nearest-neighbors
- machine-learning
- natural-language-processing
- nextjs
- nltk
- python
- react
- spacy
- tailwindcss
- transformer





Log in or sign up for Devpost to join the conversation.