-

logo
-
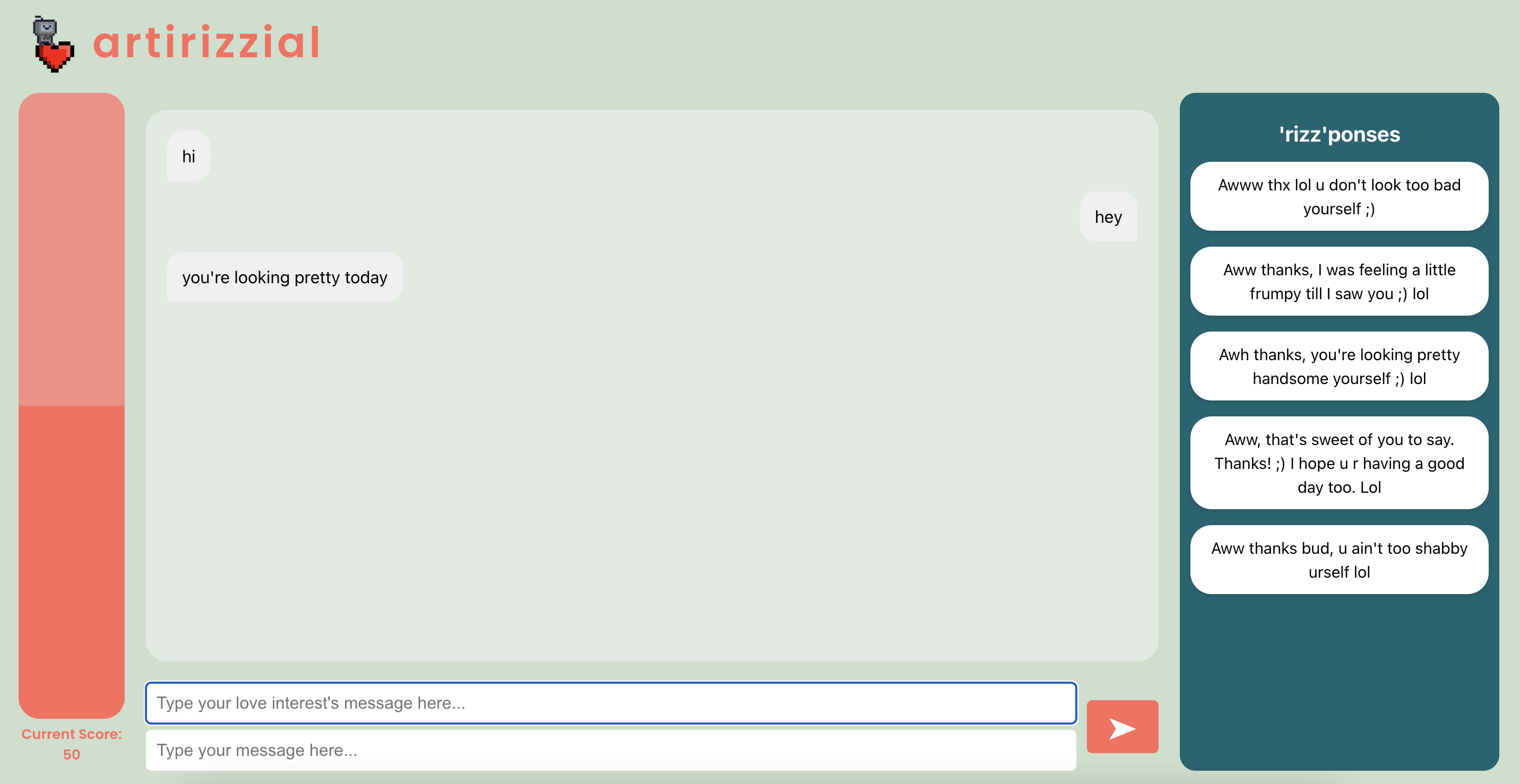
The UI interface
-
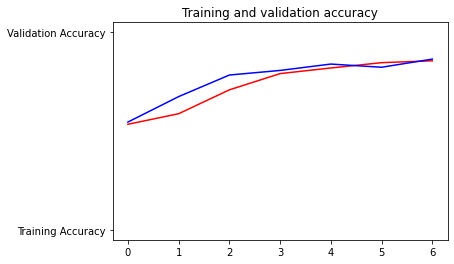
accuracy graph over epochs
-
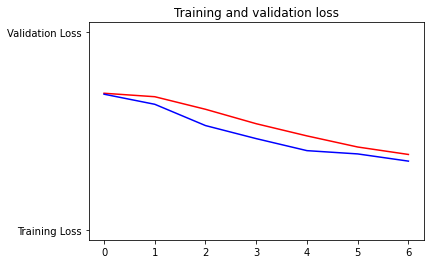
loss value over epochs
-
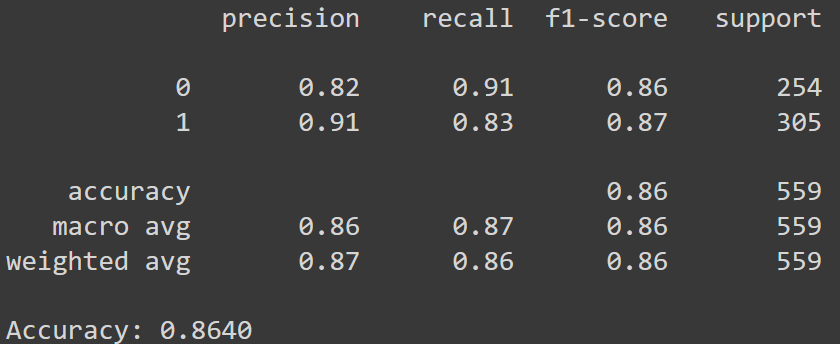
Classification report with accuracy values
-
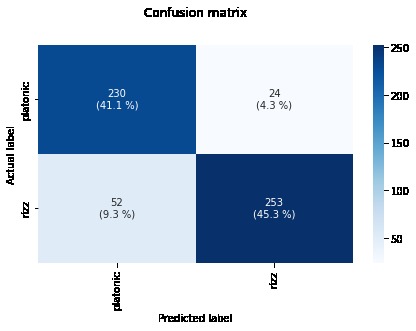
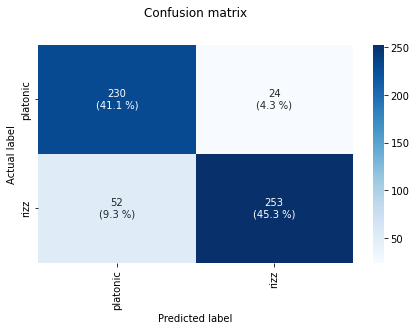
Confusion Matrix

What it does
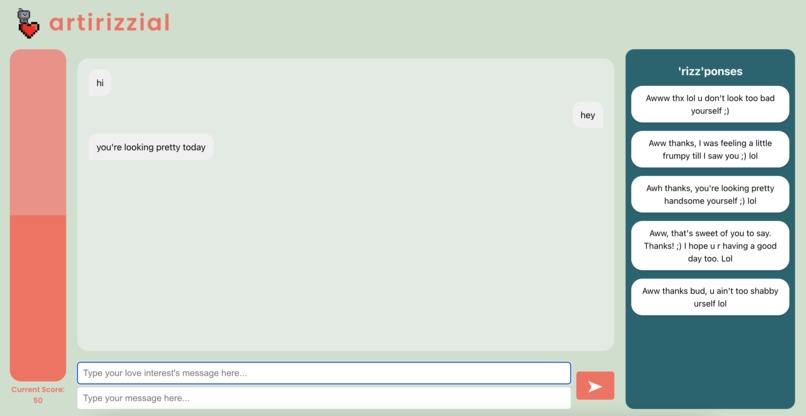
The website has two functionalities: 1) as you input messages between you and your love interest, the Artirizzial Intelligence bot gives recommended "rizzponses" that are sure to kick up the heat of your conversation! 2) the left-side interest meter updates based on the flirtatiousness of the current conversation, powered by our sentiment analysis ML model, indicating how flirty your conversation is getting!
(note: "rizz" is a new popular slang term short for "charisma." It is most often used to describe a state of "being smooth" or "having game." Ex. Elvin gets more than 20 tinder matches a day - he has "so much rizz!")
Motivations
With the excitement of Valentine's Day still in the air, love is on everyone's mind. What better than an analysis tool to help your relationship dreams come true!? Difficult conversations are daunting due to factors like fear, lack of confidence, emotional involvement, power dynamics, and poor communication skills. They can be emotionally taxing and practicing beforehand can help reduce anxiety and boost confidence. Research shows 63% find it challenging to initiate sensitive conversations, leading to social anxiety and isolation. A relationship helper chatbot provides confidential and accessible support to individuals dealing with complex relationships. It offers a convenient platform for seeking guidance and can be available 24/7. It can be particularly helpful for those who are hesitant to seek advice from friends or family members.
How we built it: Data Science and ML
Data Collection
Finding sources for data collection was one of our biggest challenges as a) there are no great public datasets of transcriptions of "flirty" conversations and b) it is difficult to categorize what is a "flirty" conversation in the first place. We ended up collecting data from a wide range of sources. For our conversations labeled as "platonic", we utilized Amazon's topical chat dataset, which can be found here. For conversations labeled as "flirty" (or for our purposes, "rizz"), we collected data from three sources. First, we built a reddit scraper to collect transcriptions from r/texttranscripts, a subreddit dedicated to posting transcriptions of flirting conversations had with the opposite gender. Second, we collected messages from websites such as this one to add to our dataset.
Finally, we also utilized the Google Cloud Vision API to pull text msgs from hundreds of screenshots of tinder/hinge direct messages across Google Images.
Even as our faith in humanity, as well as our own personal sanity, exponentially declined looking through these data sources, we built a dataset of around 6000 sample conversations to train our rizz detection model with.
Data Processing Because the data was taken from so many sources, the data required a lot of cleaning before it could be processed. The way each source of data was cleaned can be found in the Data Processing and Reddit Scraper colab files. Once the data was fairly cleaned, the data was exported into csv files to be utilized for training.
Before the data could be inputted into the model, the data from various sources was combined into a singular dataframe. Then, the sentences from the dataframe were preprocessed to allow for better input into the model. We experimented with three preprocessing techniques: removing stopwords, stemming, and lemmatization. We chose to use lemmatization over stemming for increased semantic preservation, and chose not to remove stopwords as they carried meaningful information relevant to a sentence's "flirting" characteristic, leading to better model performance than when stopwords were removed. Then, the sentences were vectorized and split into train, test, and validation sets to use in training the model.
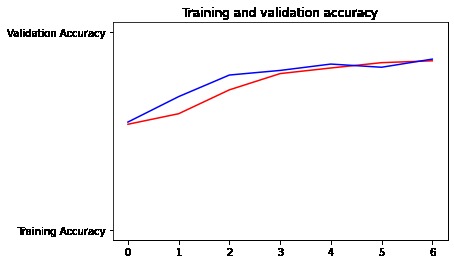
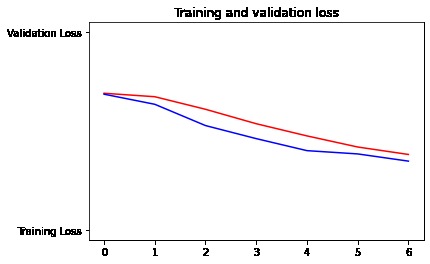
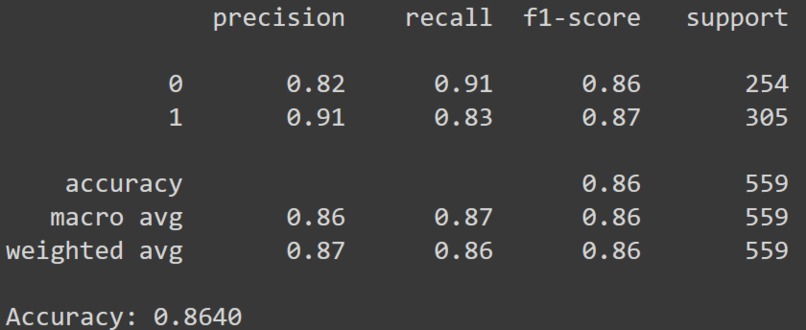
Model Traning and Testing After various experimenting with various model architectures, we decided upon a LSTM model with 2 LSTM layers, as it was able to extract speech characteristics and semantics the best. We were able to achieve an accuracy of 86% on the validation set. Interestingly, as can be seen by the confusion matrix, even the model had trouble telling if a message was flirty or not more often than confusing a non-flirty message for flirty. Further details of the results of our model can be seen in our image gallery.
How we built it: Response Generation
In order to generate possible responses based off of the user-inputted text messages, we used the davinci model from the OpenAI API. We fine-tuned the model by prompt-engineering it with examples of text message conversations and certain guidelines, such as suggesting the use of internet slang and text messaging lingo. The user-inputted text messages were received by the backend and ran through the response generator. The resulting output was parsed through in order to obtain solely the text message content while ignoring whitespace or deviant formatting. The formatted string is then sent back to the front end to be displayed on the UI.
How we built it: Backend
For the backend, we used the Flask framework in order to connect our React frontend with our Python backend. We faced a lot of difficulties in this process as we realized HTTP protocols were extremely strict, and as new developers, we had to learn how to troubleshoot CORS errors and figure out request and response protocols. Additionally, it was quite challenging to integrate prediction using our TensorFlow .h5 model into our back end.
How we built it: Frontend
For the frontend, we used the React framework in order to build our UI and webpage functionalities. Users were able to input text messages between themselves and their potential love interest, which was then read and received by the backend. We also displayed the response of the backend, which was the AI-generated potential responses to the existing text message conversation. A progress bar is also displayed that indicates how well the user is performing in regards to their levels of flirtatiousness.
Challenges we ran into
What we learned
We learned so much about every single step of the development stack. In terms of data science, we learned a lot about RNNs and how they work, how to scrape for data, preprocessing techniques for data, and prompt engineering for LLMs. Nobody on our team had worked with backend development before, so we were starting here from scratch. We learned how to use Flask to power our API. Additionally, we learned how to use the OpenAI API, as well as how to use React to make API calls.
What's next for Artirizzial Intelligence
We want to be able to use the Google Cloud Vision API so that users can take and upload pictures of their conversations to automatically input messages. Additionally, we would like to bolster our dataset to be able to make more accurate predictions.
Built With
- css
- flask
- git
- github
- google-cloud-vision
- google-colab
- heroku
- html5
- javascript
- keras
- openai
- python
- react
- scikit-learn
- tensorflow






Log in or sign up for Devpost to join the conversation.