-
-
Main Screen
-
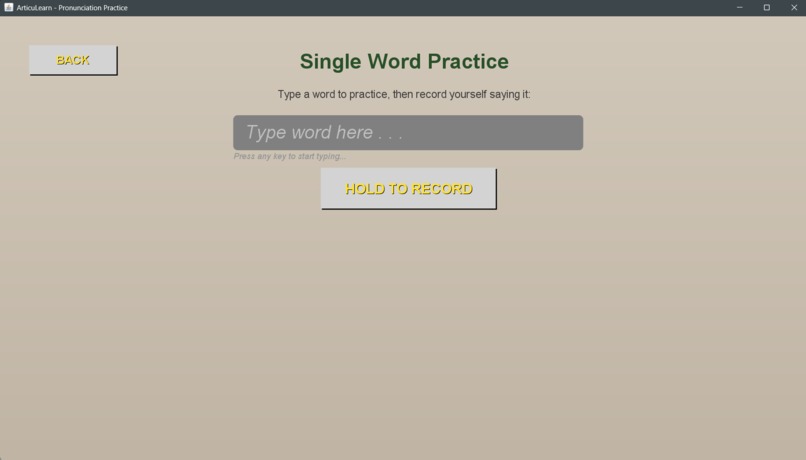
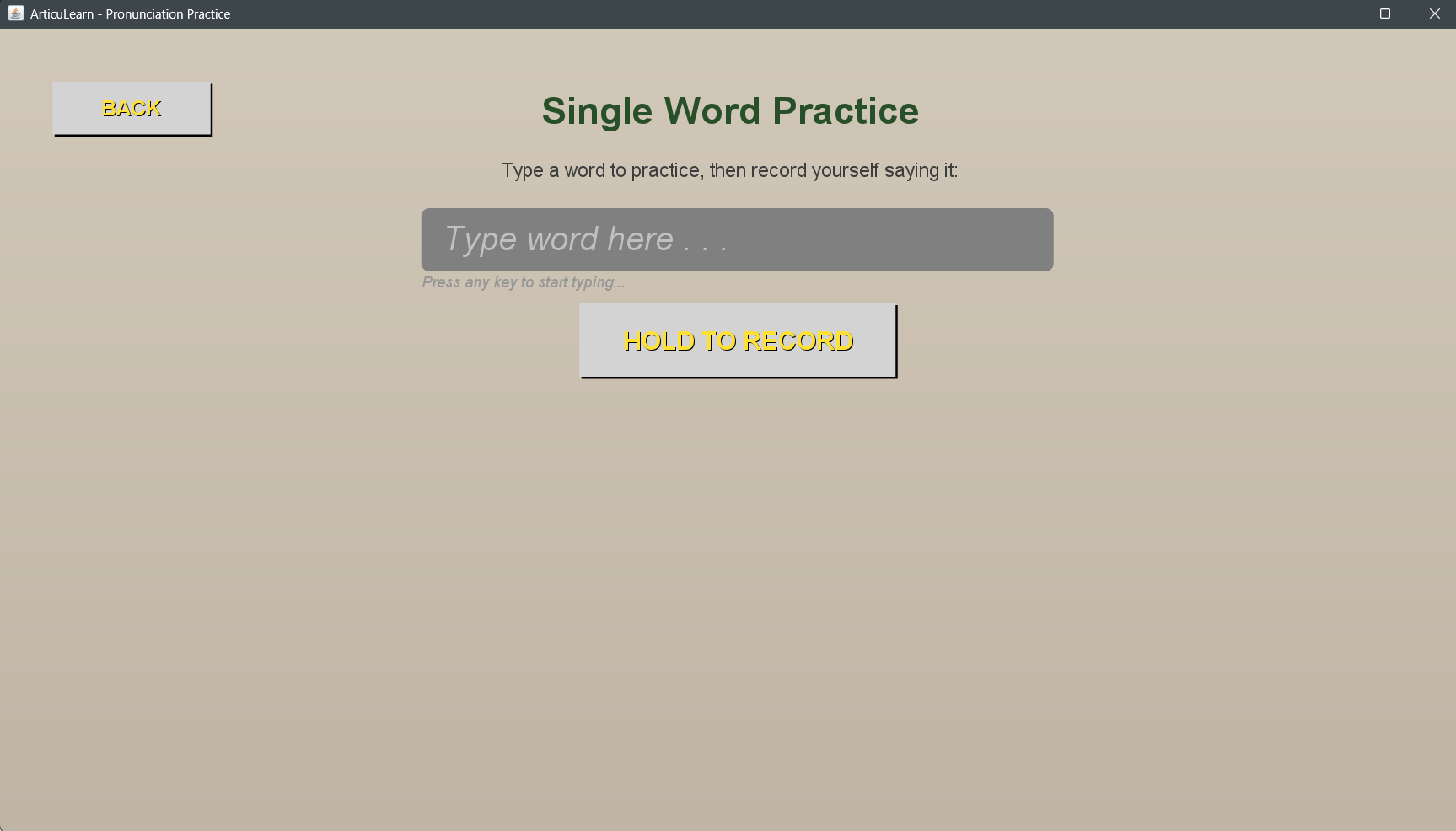
Single Word Screen
-

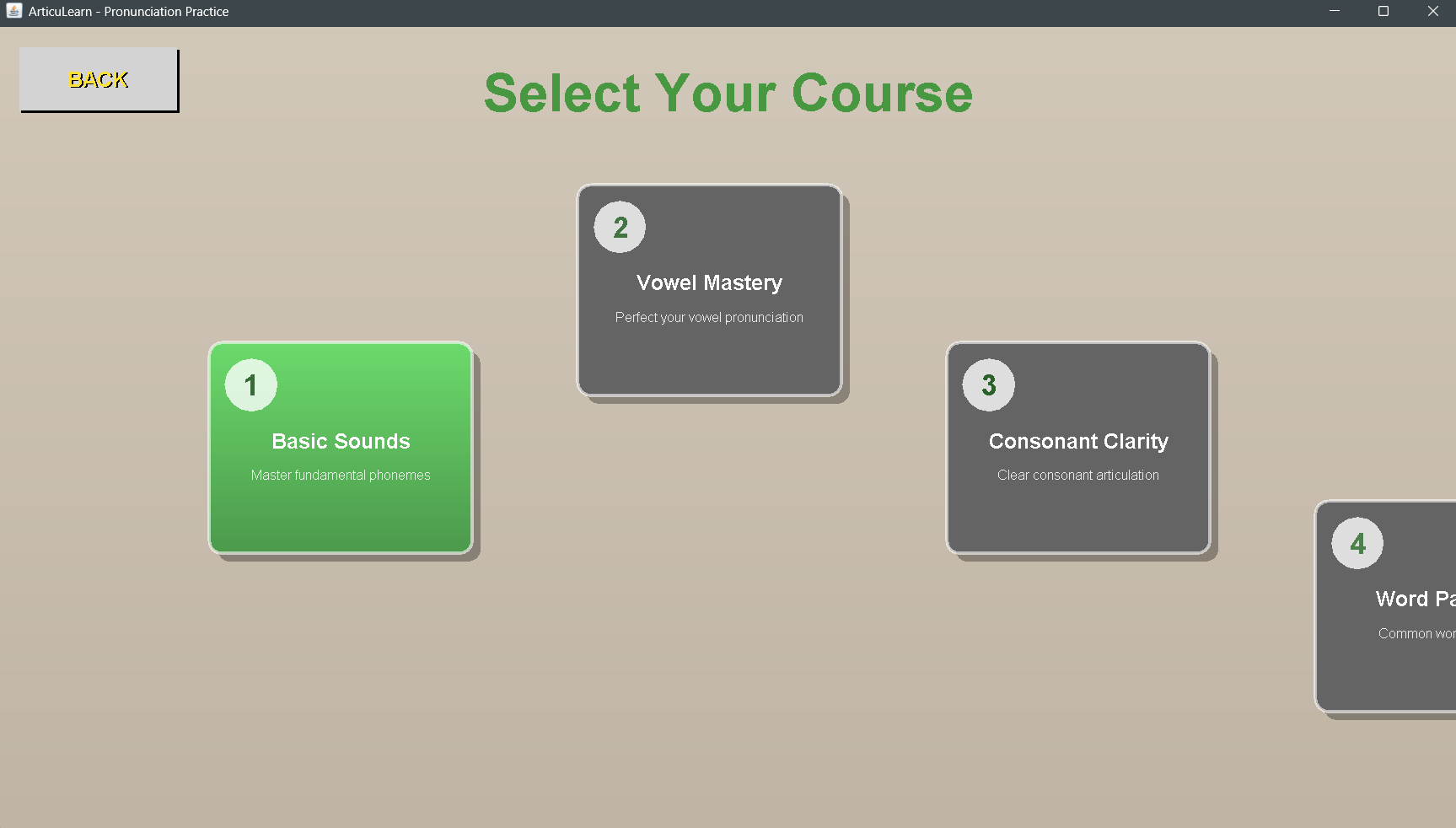
Course Selection Screen
-

Course Panel.
-
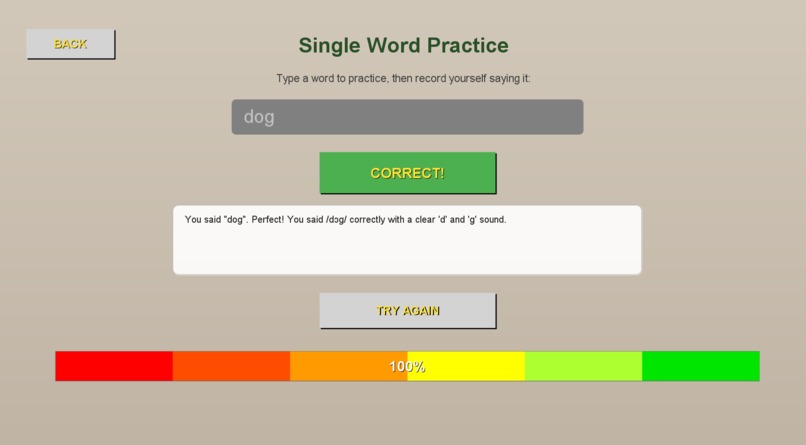
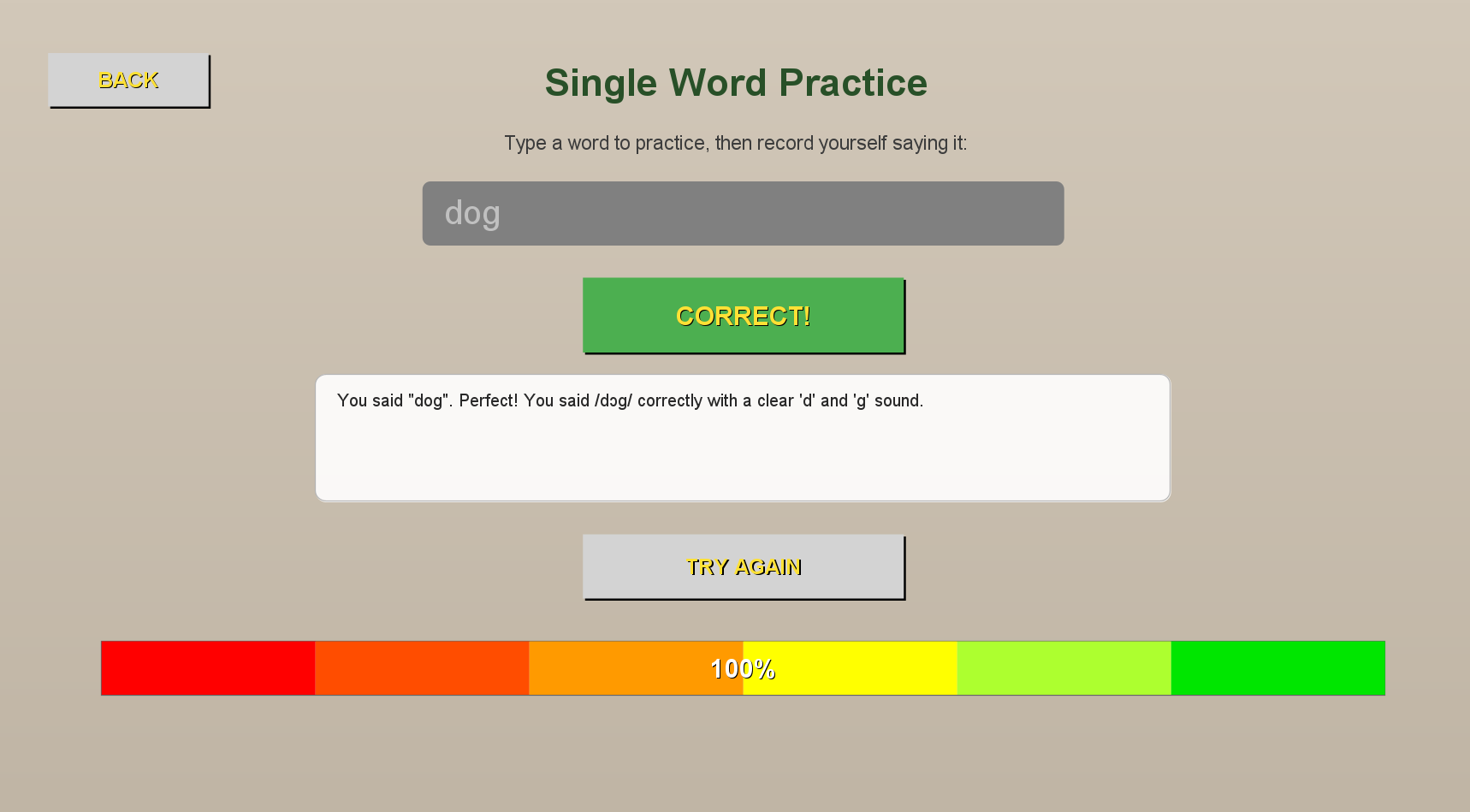
Response After Correction.

Inspiration
430 million people worldwide suffer from disabling hearing loss. 70 million are completely deaf. Over 80% live in developing countries without access to proper resources. Yet here's the striking reality: over 90% of deaf people still use spoken language in their daily lives. Millions of people desperately want to communicate clearly through speech, but traditional speech therapy costs hundreds of dollars per session and simply isn't available in most parts of the world. We saw an opportunity to help with pronunciation learning. Bringing professional-grade speech coaching to anyone, anywhere, for free.
What it does
ArticuLearn is your personal AI pronunciation coach, available 24/7, completely free, and accessible from any computer. Our App has 2 modes:
In Self Learn Mode, users choose any word they want to master. They hit record, speak the word, and within seconds, our AI analyzes their pronunciation. The system provides phonetic breakdowns showing exactly how they said it versus how it should sound, personalized improvement tips tailored to their specific errors, and accuracy scores so they can track their progress numerically.
In Course Mode, users follow expertly crafted pronunciation lessons that guide them from basics to advanced speech patterns, with structured progression and performance tracking through curated word lists.
How we built it
We built ArticuLearn using Java Swing for the desktop GUI, providing an interface for both Self Learn and Course modes. The application captures audio through Java Sound API and saves recordings as WAV files. We manually constructed multipart/form-data HTTP requests using Java's built-in HttpClient to communicate with the OpenAI Whisper API for accurate speech-to-text transcription. The transcribed text is then sent to ChatGPT API which analyzes pronunciation accuracy, provides phonetic breakdowns, and generates personalized feedback with percentage scores.
Challenges we ran into
One of our biggest challenges was manually implementing multipart/form-data encoding for file uploads to the OpenAI API. Understanding HTTP boundaries, proper formatting with \r\n line breaks, and constructing the request body byte-by-byte was complex and error-prone. We also struggled with audio capture and format compatibility, ensuring our WAV files met OpenAI's requirements. Parsing and displaying feedback from ChatGPT in a user-friendly way required careful text formatting in Swing components. Additionally, managing API response times and providing smooth UI feedback during asynchronous API calls without freezing the interface was technically demanding.
Accomplishments that we're proud of
We're extremely proud of creating a fully functional pronunciation learning tool that provides real-time, AI-powered feedback. Successfully implementing direct API integration with both Whisper and ChatGPT taught us about HTTP protocols and APIs. Having both a Self Learn and Course offers flexibility for different learning styles. The accuracy percentage calculation and detailed phonetic feedback give users concrete metrics to track their improvement. We're particularly proud of the polished user interface with intuitive recording controls, color-coded feedback, and retry functionality that makes learning engaging and motivating.
What we learned
We gained hands-on experience with HTTP protocol internals, particularly multipart/form-data encoding and boundary construction. We learned how to effectively integrate multiple AI APIs to create a cohesive user experience. Working with Java Sound API taught us about audio capture, sampling rates, and audio format specifications. In our Computer Science Club, we learnt syntax for certain codes for contests. Through this project, we learnt how to use code for an actual project and application. An example of this would be dynamic programming that we used in our project.
What's next for ArticuLearn
We plan to expand ArticuLearn with more comprehensive course content covering various difficulty levels and language-specific pronunciation challenges. We want to add progress tracking and analytics so users can visualize their improvement over time with graphs and statistics. Implementing speech comparison audio playback—allowing users to hear their recording versus a native speaker—would provide valuable auditory feedback. We're considering adding support for multiple languages beyond English to help non-native speakers worldwide. Additionally, we didn't have the time to integrate, but we have a demo of mouth lip reading to give feedback to your mouth movements and what to improve.










Log in or sign up for Devpost to join the conversation.