-
-
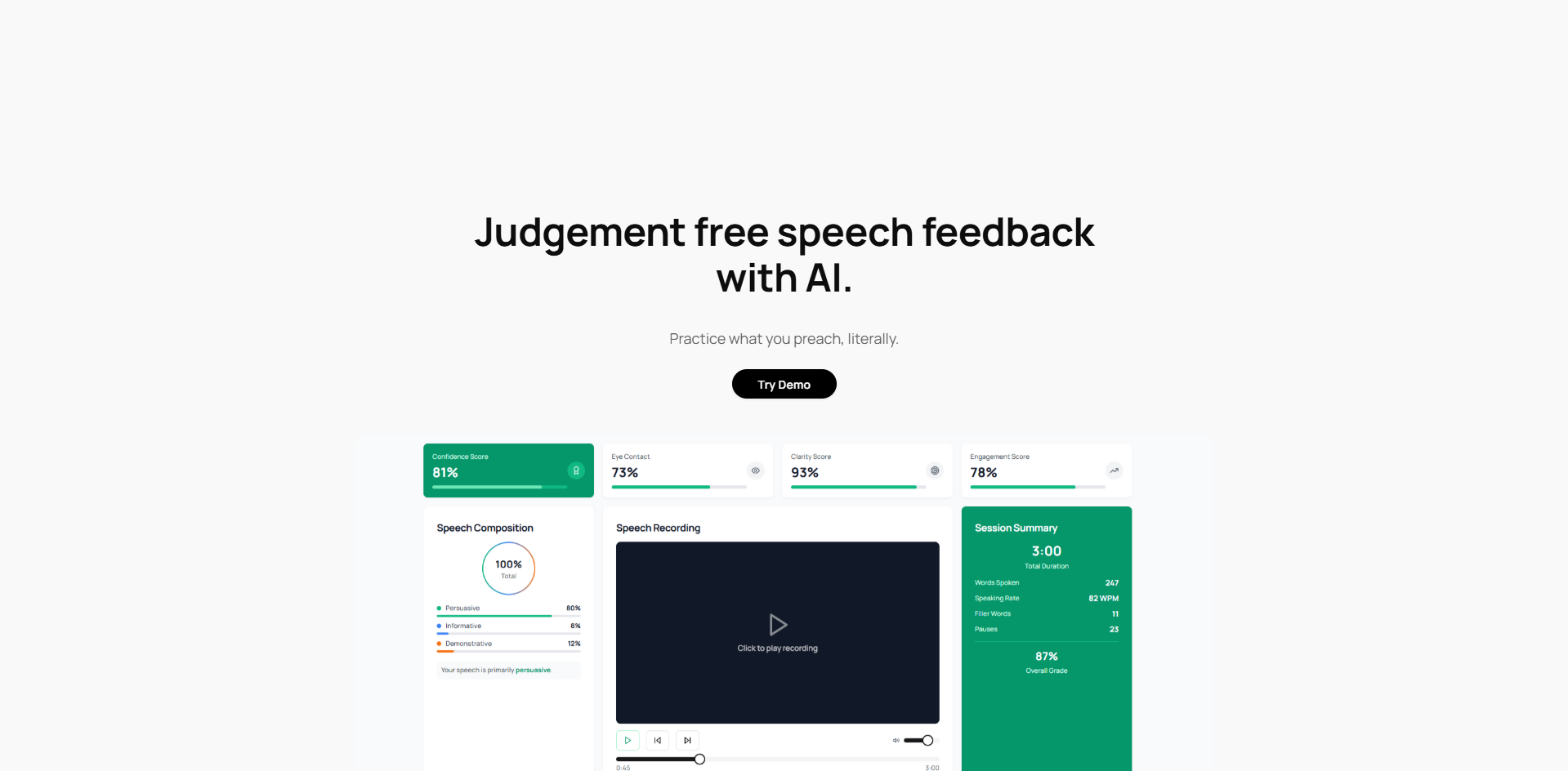
Landing page
-
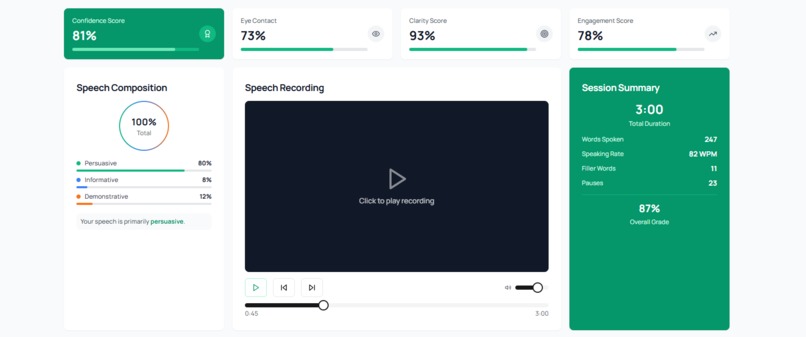
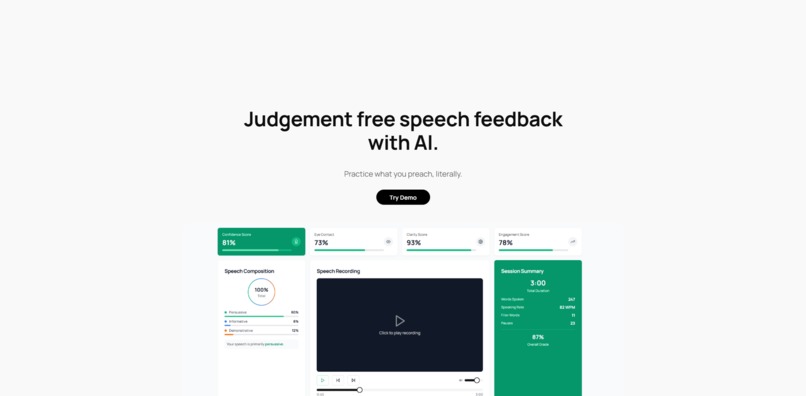
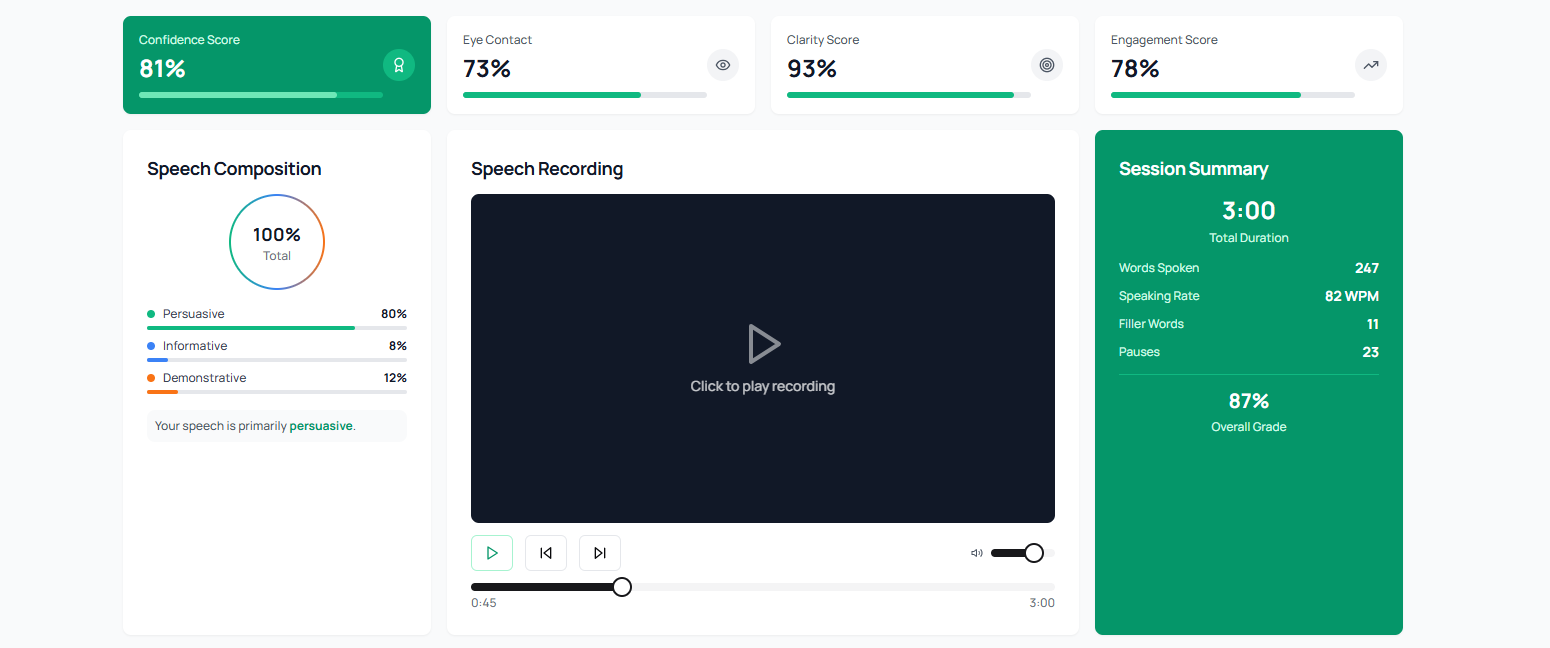
the GUI dashboard for speech feedback
LINK TO PRESENTATION: https://www.canva.com/design/DAGrE--GGnI/W6aRTbNCHWL99e8bQgEZrw/view?utm_content=DAGrE--GGnI&utm_campaign=designshare&utm_medium=link2&utm_source=uniquelinks&utlId=ha520fd15c4
Inspiration
We need great communicators in the workspace, especially with the rising technical capabilities of AI. Currently, we see a market gap in the hiring process, which leads to unnecessary HR and training costs for companies, and less talents in the job market being selected for interviews.
We hope to fill this gap to ensure that companies get the right talent they need while reducing the costs of the whole interviewing, onboarding, and training process for each talent.
What it does
Pre-hire: Presense serves as a screening tools which quantifies interviewees' communication into visualizable data analytics for HR to make more informed decisions.
Post-Hire: Presense serves as a training tool to help corporates streamline the new-hire onboarding process.
How we built it
Frontend Framework: React.js Styling: Tailwind CSS A single-page application (SPA) built in React, styled with Tailwind’s utility classes for rapid, responsive UI development.
Backend Framework: FastAPI Language: Python 3.11.9 Exposes REST endpoints, orchestrating AI calls.
AI / LLM Services gpt-4o-transcriber, Purpose: Verbatim audio/video transcription Integration: Called from your FastAPI routes
Eye Detection Model Purpose: Scoring eye contact Integration: Model initialized via tensorflow.js
Gemini Purpose: Higher-level language understanding, speech analysis processing Integration: Invoked as a second-stage agent after transcription
Challenges we ran into
Speech Transcription:
One of the most significant difficulty we faced was achieving truly verbatim transcription while maintaining high accuracy. In particular, detecting and preserving every filler word (“um,” “uh,” “like”), stuttered syllable, false start, and overlapping utterance required tuning both our prompt and the transcription model’s parameters. Through testing, error analysis, and prompt refinement, we were able to significantly improve both the completeness of our verbatim captures and the overall intelligibility of the final transcripts.
CV: Integrating features like the Eye Contact Analyzer into the front end through Java Script. Finding image datasets of eyes across the internet to leverage for training an ML model that identifies different eye positions during the talking stage.
Frontend/UX:
Initializing the model on the front-end required graceful loading of the model and webcam, such as to not introduce any lag in the webcam feed, which also meant the model needed to be lightweight.
Accomplishments that we're proud of
Meeting new people, learning from the resume roast workshop, and also putting together a full-stack, working MVP in just 2 days!
What we learned
Integration and full stack development
What's next for Presense
Marketing campaigns
We can customize individual HR company partnerships by catering/fine tuning our model to their average demographics of employees and workers through company data.
Our model can webscrape a diverse array of datasets from all genders/races to avoid biases
Built With
- fastapi
- gemini2.0
- gpt4o
- javascript
- python
- react
- tailwind
- tensorflow





Log in or sign up for Devpost to join the conversation.