-
-
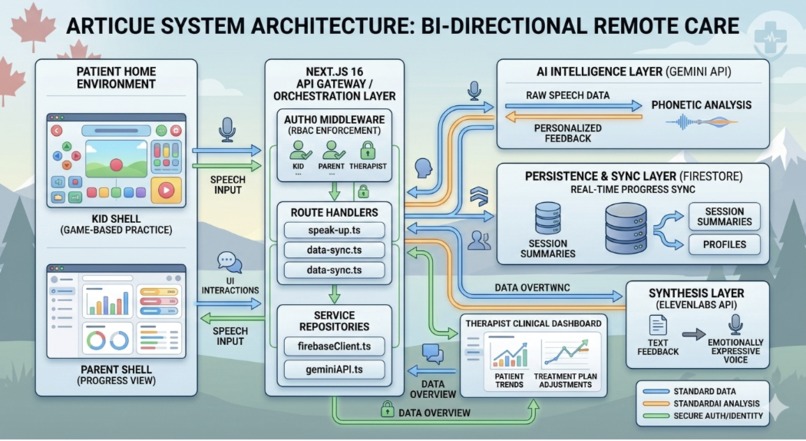
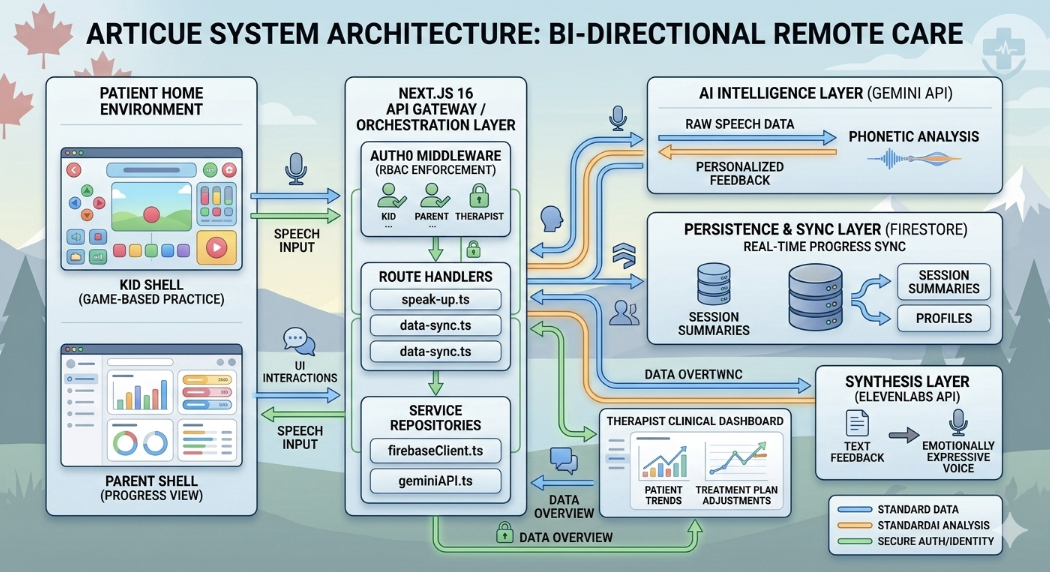
System Architecture
Inspiration
Canada prides itself on universal healthcare, but for thousands of families, that promise breaks down the moment their child needs speech therapy. 1 in 5 preschoolers has a speech or language impediment. The wait for a government-funded speech-language pathologist? Up to 920 days. Nearly three years of a child's life, and the most critical window for language development, all spent on a waitlist. We kept thinking about what that actually looks like. A four-year-old who can't say their own name. Parents watching their kid fall behind in school while they're told to keep waiting. Private therapy exists, but at $4,000 a month, it's not a real option for most Canadian families.
ArtiCue started from a simple question: what if the wait didn't have to matter?
We also realized something important: we can't instantly train more SLPs. But we can extend their reach. ArtiCue doesn't replace therapists, it multiplies them. A child waiting to finally get a SLP can start making progress. Additionally, a child practicing at home every day between appointments gets more out of every session. We're moving from a model where care is a scarce commodity to one where support is accessible from anywhere
We built ArtiCue because no Canadian child should have to wait years to find their voice.
What it does
ArtiCue brings speech therapy into the home through Nova, a friendly animated companion who talks, celebrates, and guides kids through exercises the same way a real therapist would. She's voiced by ElevenLabs, so when she says a word, she says it clearly, warmly, and at the right pace for a child to follow. Kids practice through five exercise types, each based on real clinical methods:
- Word Practice -- say a word, get instant AI feedback on how you did
- Blend It! -- targets childhood apraxia using DTTC methodology
- Rhyme Time -- builds phonological awareness through rhyming games
- Sound Hunt -- semantic feature analysis for vocabulary development
- Speak Up! -- volume and clarity training based on LSVT LOUD
Parents get a dashboard showing their child's accuracy over time, XP earned, current streak, and an AI-generated prediction of how many weeks until mastery. There's also a chatbot that answers parents' questions about speech development, but it only answers using peer-reviewed research pulled live from PubMed, Semantic Scholar, and E.R.I.C, providing dependable information when waiting times can’t be.
How we built it
Gemini 2.5 Flash Gemini does a lot of the heavy lifting, but not in a generic way. We built five separate clinical functions on top of it:
analyzePhoneme()scores a child's pronunciation attempt with age-specific grading. A 5-year-old substituting /w/ for /r/ is developmentally normal; Gemini knows that and grades accordinglyanalyzePronunciationAudio()is a multimodal fallback. When Web Speech API transcription fails, we encode the raw audio as base64 and send it directly to Gemini to listen to and scoreanalyzeVoiceAttempt()is a stricter grader used in Speak Up! mode, focused on whether the word was recognizable and spoken with enough volume and claritygenerateSessionCelebration()writes a personalized end-of-session message based on how the child actually didpredictImprovement()takes the child's full session history and outputs weekly improvement rate, weeks to mastery, and a plain-English insight for the parent
ElevenLabs
Every word Nova says goes through ElevenLabs. This matters most in demonstrateWord(). Before a child attempts a word, Nova says it out loud so they have a clear audio model to copy. We fire a custom nova-speaking browser event during playback so Nova's Lottie animation syncs to her voice in real time. She has 7 animation states (idle, talking, celebrating, waving, sitting, sad, incorrect) and switches between them based on what's happening in the session.
Auth0 We use Auth0 for role-based authentication. Parents and children have separate experiences. Kids can't see the dashboard, parents can't accidentally be put into an exercise session. All Firestore session data is scoped to the authenticated user ID. The research chatbot also enforces a rate limit of 20 questions per user per day for a singular topic, tracked in Firestore per Auth0 identity, keeping the tool trustworthy for a healthcare context to not generate redundant data.
The Research Chatbot Every parent question goes through:
- A keyword classifier that checks it's actually about speech/language before touching any API
- A Firestore cache check to avoid redundant lookups
- Parallel queries to PubMed, Semantic Scholar, and ERIC, each filtered to specific tier-1 SLP journals like the Journal of Speech, Language, and Hearing Research and the American Journal of Speech-Language Pathology
- A fallback to OpenAlex if fewer than 2 results come back
- Deduplication across all four sources
- Gemini synthesising only those abstracts into a cited, parent-friendly answer, with an explicit instruction not to add anything that isn't in the sources
The Session Loop
Each exercise runs as a stateful agentic pipeline: startSession > Web Speech API > POST /api/analyze (Gemini) > ElevenLabs /api/tts > recordAttempt > endSession > generateSessionCelebration > predictImprovement
Challenges we ran into
Initially, we were utilizing the Web Speech API to record and transcribe the audio of the child, but it was very unpredictable across browsers and clashed with our state management approach in React, making it difficult to debug. We then turned to the MediaRecorder to provide hold-to-record audio recording capabilities and took advantage of the native multimodal audio input capabilities of the Gemini 2.5 Flash to handle transcription and analysis. We left the Web Speech API active as a fallback option, utilizing it to record the transcript if possible to speed up text-based analysis, and otherwise relying on the audio being sent to the Gemini application.
We noticed that the latest Auth0 version 4 updated 4 days prior to this hackathon. We spent a large amount of time wondering what went wrong, only to realized that the documentation just wasn't widely available and up to date. We ended up adjusting to this version for our project
Initially we ran into issues using the client-side Firebase SDK, which kept throwing permission errors due to Firestore security rules being difficult to configure correctly. We switched to the Firebase Admin SDK which handles all database operations server-side through our Next.js API routes, completely bypassing those issues. This turned out to be the better architecture anyway since it keeps our database logic centralized and secure, making the app more robust for both demo and future deployment.
Accomplishments that we're proud of
- Full speech therapy pipeline — we built a complete end to end pipeline where a child speaks into a microphone, their voice is captured, sent to Gemini for phoneme analysis, and Nova responds with personalized voiced feedback in real time. Getting all of those pieces working together reliably was a significant technical achievement.
- Nova's voiced feedback with ElevenLabs — integrating ElevenLabs TTS to give Nova a warm consistent voice across all activities, including the sequential syllable sounding out in Blend It, required building a robust global audio queue that handles playback, cancellation, and caching cleanly.
- Five fully functional kid activities — Word Practice, Blend It, Sound Hunt, Rhyme Time, and Speak Up are all working with real speech input, real AI analysis, and real feedback tailored to each child's target sounds and age.
- **Auth0 and Firebase integration — **getting Auth0 v4 working with Next.js 16's new proxy architecture and migrating to Firebase Admin SDK for secure server-side data access were both non-trivial challenges that we worked through and got running cleanly.
- Child-centered design — the app tracks XP, streaks, and session history per child, with a parent dashboard showing progress over time, making it feel like a complete product rather than just a demo.
What we learned
- Working with cutting edge frameworks is hard: building on Next.js 16 with the new App Router and Auth0 v4 meant a lot of the documentation was outdated or nonexistent. We learned to read source code, check GitHub issues, and figure things out from first principles rather than relying on tutorials.
- AI APIs have real constraints: we learned that not all Gemini models support audio input, that free tier quota runs out fast when you are actively developing, and that ElevenLabs has concurrent request limits that require careful queue management. Working around these constraints taught us a lot about building resilient API integrations.
- Browser APIs are inconsistent: the Web Speech API behaved differently across browsers and fought against our React state management in ways that were hard to debug. Switching to MediaRecorder gave us much more control and was a valuable lesson in choosing the right tool for the job.
- Debugging async audio pipelines is uniquely difficult: the Blend It syllable skipping bug taught us that audio playback, promises, and React state updates interact in subtle ways that are hard to trace. We learned to use browser traces, console logs at every step, and mock audio responses to isolate exactly where things break.
- Architecture decisions compound: the early decision to use Firebase Admin SDK server-side instead of client-side Firebase saved us from a whole class of security and permission bugs, and taught us that getting the architecture right early is worth the upfront investment
What's next for ArtiCue
- Native iOS app via Capacitor
- An SLP portal so therapists can assign exercises and track patients remotely
- French Canadian support for families across Quebec
- Offline mode for rural and remote communities
- A push toward provincial health coverage as a recognized digital therapy tool
AI technical demo with basic walkthrough - https://youtu.be/mpBsgAv-E5k demo with description: https://youtu.be/nndhehSQGhc
Built With
- auth0
- elevenlabs
- firebase
- firestore
- google-gemini-api
- lottie
- next.js-16
- python
- recharts
- tailwind-css
- typescript
- vercel
- web-speech-api

Log in or sign up for Devpost to join the conversation.