-
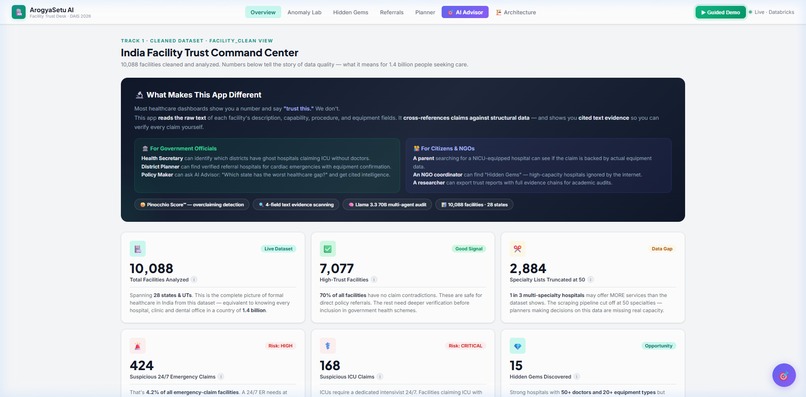
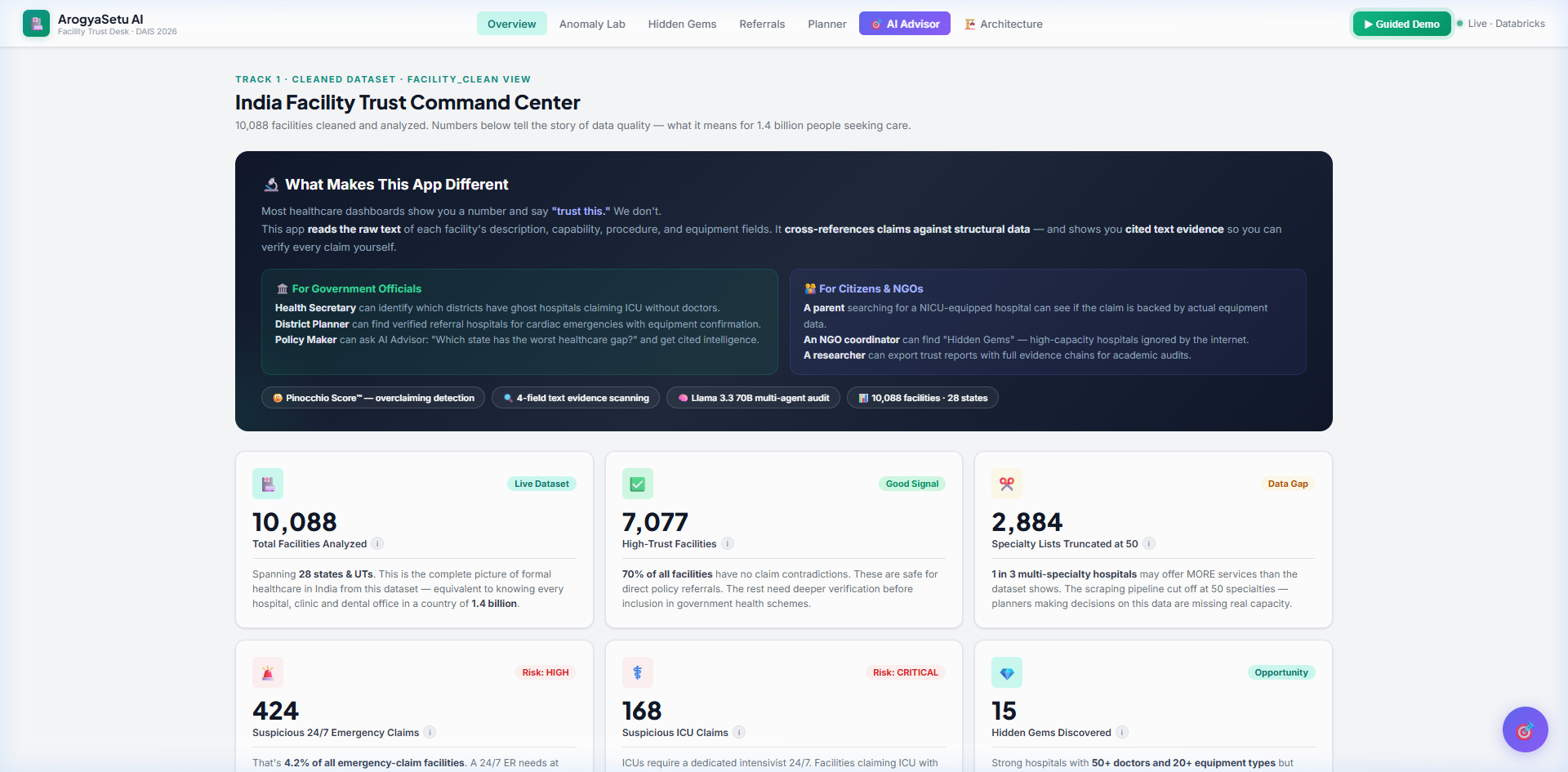
Overview Dashboard — KPI cards, trust stats, facility table
-
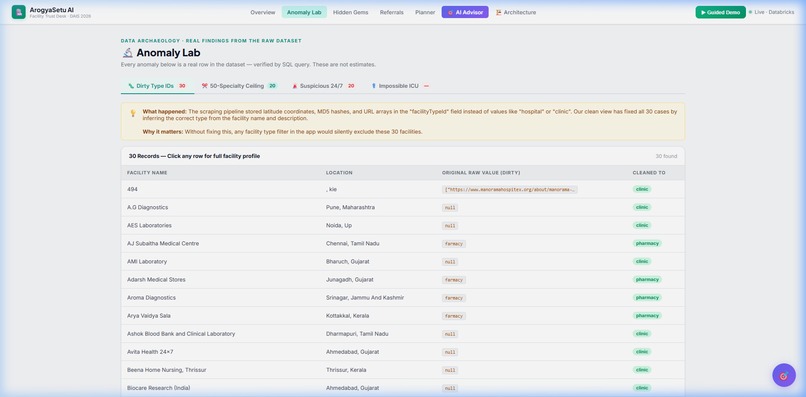
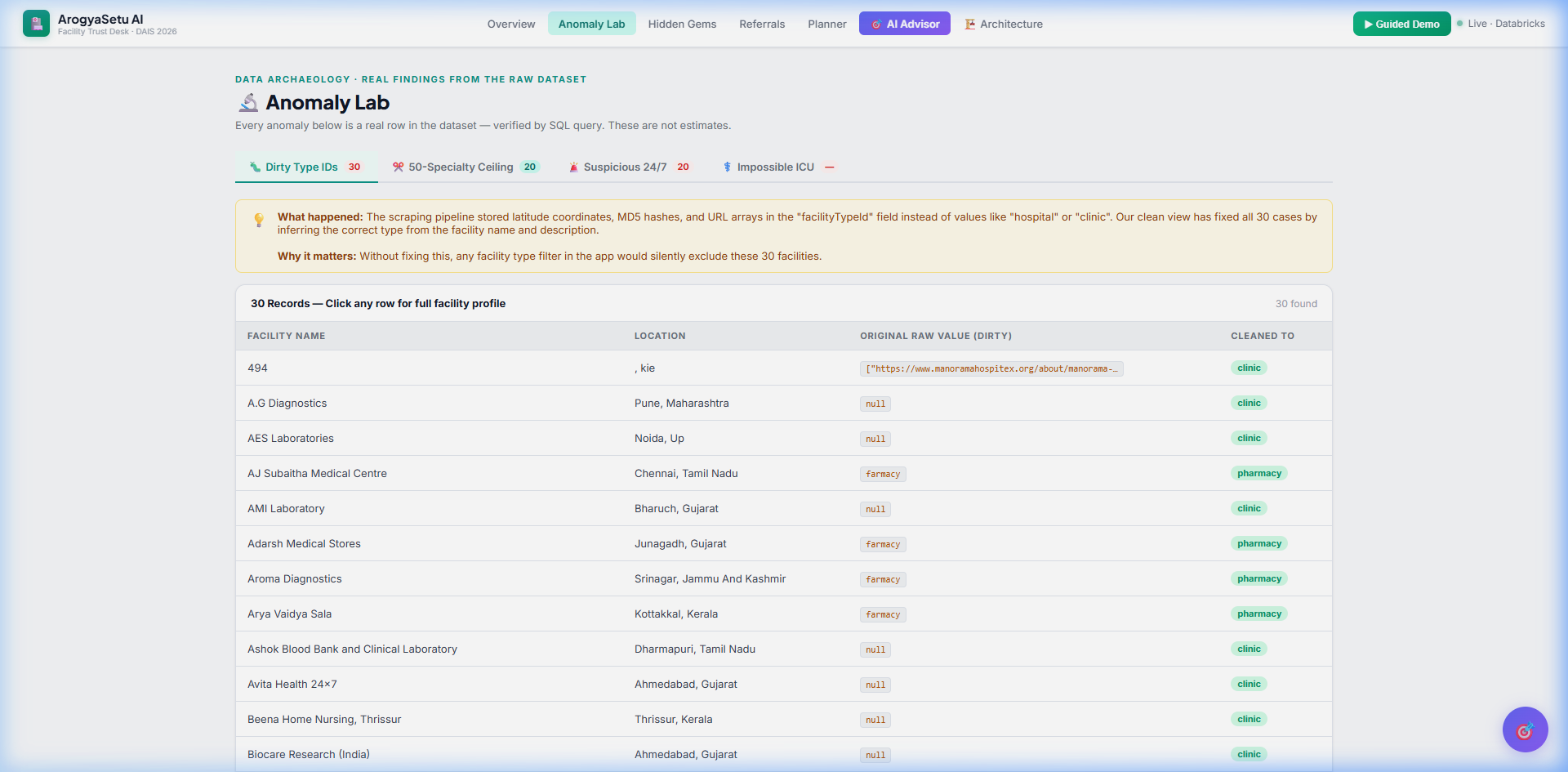
Anomaly Lab — Data archaeology with dirty type IDs
-
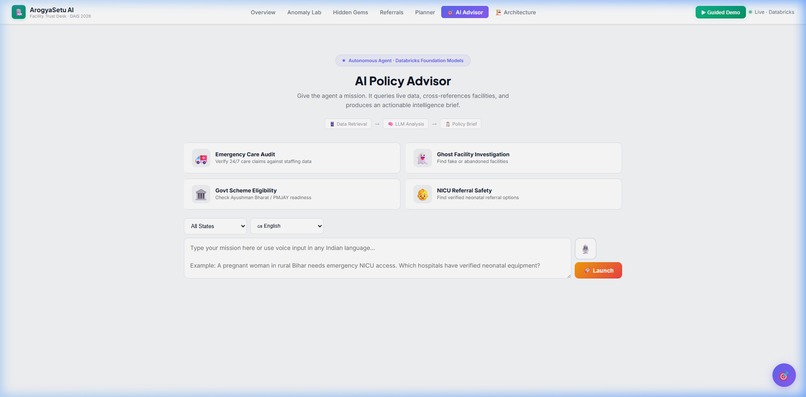
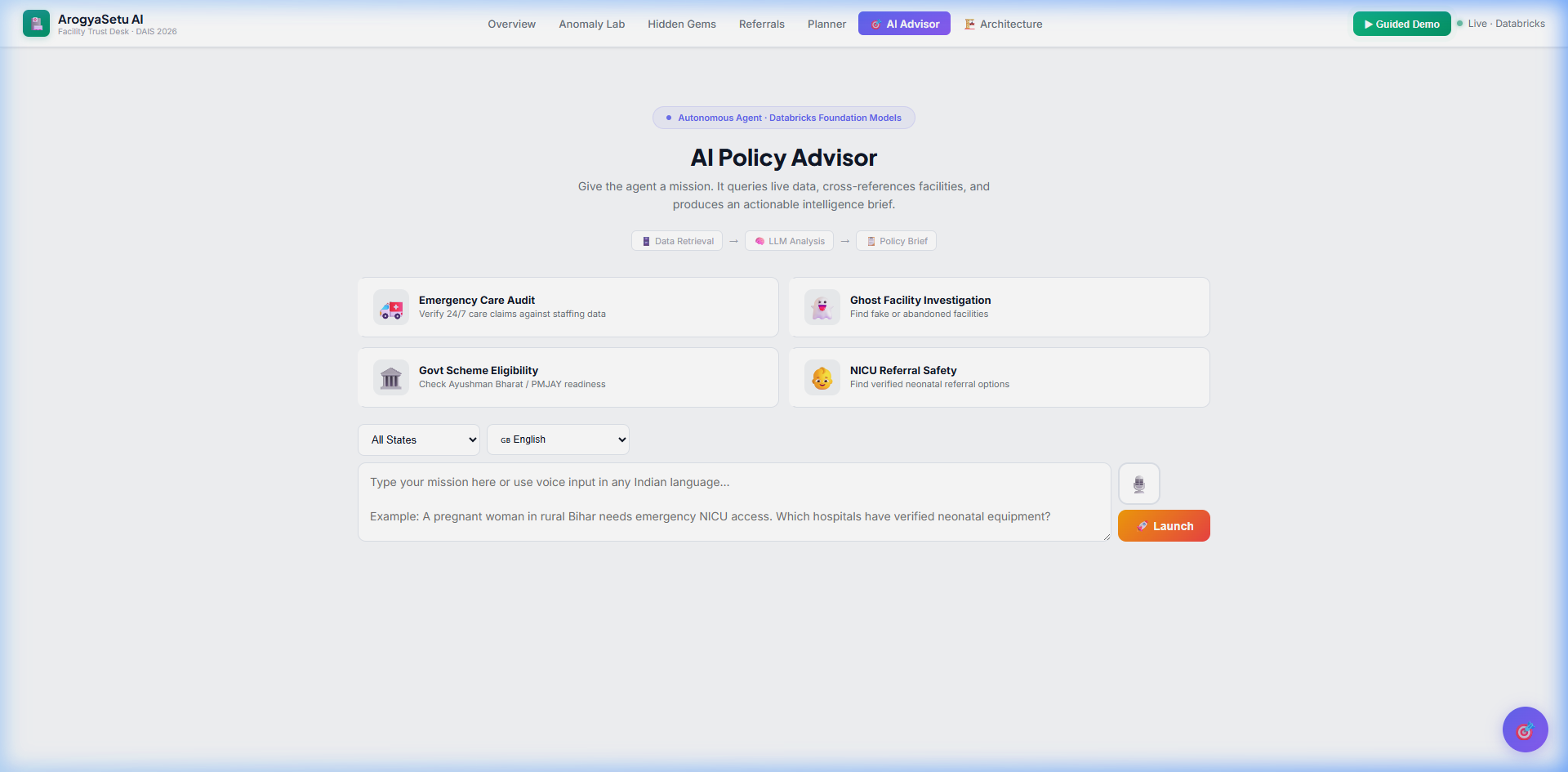
AI Policy Advisor — Mission cards, voice input, LLM pipeline
-
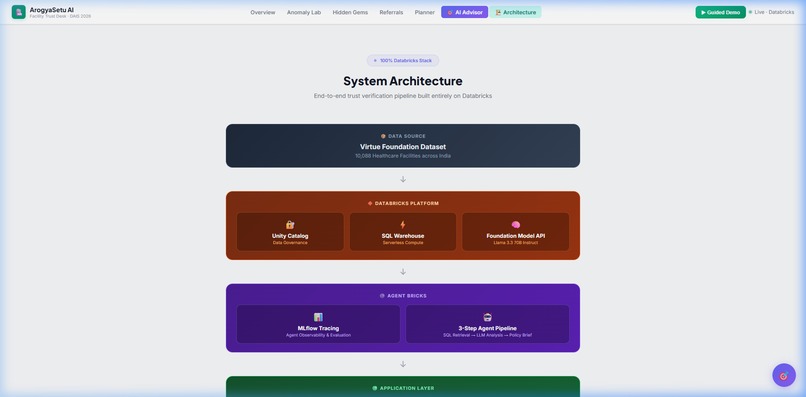
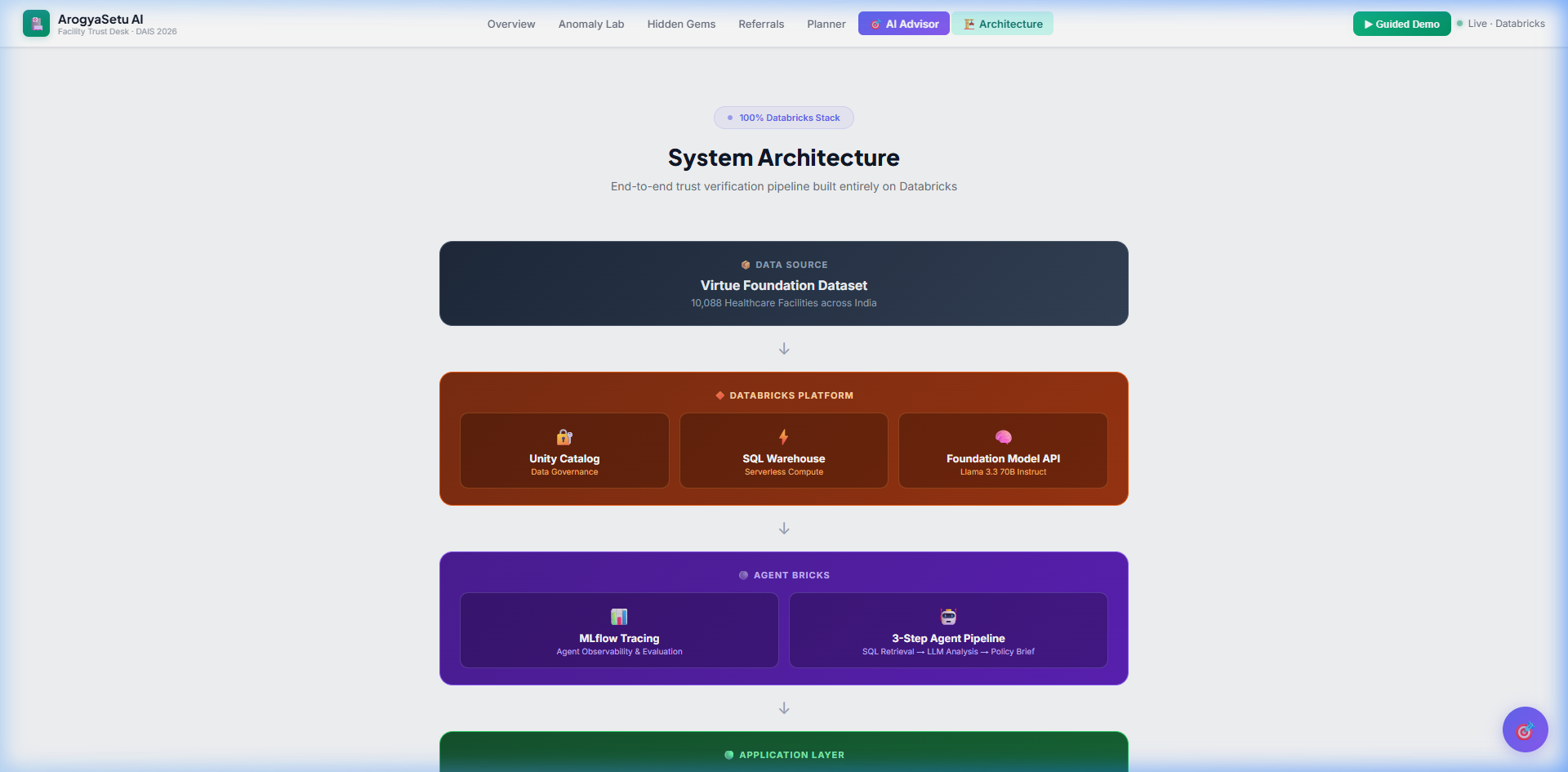
Architecture — Full Databricks stack diagram
Inspiration
During COVID, a family member in Gujarat got severe pneumonia. The nearest hospital listed online claimed ICU, pulmonology, and 24/7 emergency. When we arrived — no doctor. No ventilator. Nothing. Just a name on a directory.
That experience stayed with us. A wrong hospital listing isn't just bad data — it's a life at risk.
India has 1.5 billion people. Over 10,000 healthcare facilities appear in public directories. But how many can actually do what they claim? We built ArogyaSetu AI to answer that question — with evidence, not assumptions.
What it does
ArogyaSetu AI is a trust verification platform for Indian healthcare facilities. Instead of showing self-reported claims at face value, we cross-reference every claim against 4 raw text fields (description, capability, procedure, equipment) and structural data.
Key features:
🤥 Pinocchio Score™ — An 8-factor overclaiming penalty (0–100) that catches hospitals claiming capabilities they can't support. The score is fully transparent — every penalty is traceable to a specific data field.
🔍 Evidence Triangulation — For every claim (ICU, NICU, 24/7, Cardiology), we scan raw text fields and highlight the exact words that support or contradict it. Each claim gets a trust signal: Strong Evidence, Partial Evidence, or Weak/No Evidence.
📊 Uncertainty Communication — We show field-by-field data coverage (e.g., only 36.4% of facilities report doctor count). When data is missing, we say so explicitly — we never present weak evidence as fact.
🎯 AI Policy Advisor — An autonomous 3-step agent pipeline: SQL retrieval from Unity Catalog → analysis with Llama 3.3 70B → structured policy brief with citations. Supports multi-turn conversation and voice input in 6 Indian languages.
🧪 Anomaly Lab — Real data archaeology: 2,884 facilities with specialty lists truncated at exactly 50 (a scraping bug), corrupted facilityTypeId fields containing lat/lng and UUIDs, and hospitals claiming ICU with zero doctors.
💎 Hidden Gems Finder — Facilities with 50+ doctors and real equipment but zero online presence — the hospitals patients and planners miss every time.
How we built it
100% Databricks stack:
| Layer | Technology |
|---|---|
| Data | Databricks Unity Catalog (Virtue Foundation Dataset) |
| Compute | Databricks SQL Warehouse (Serverless) |
| AI | Databricks Foundation Model API — Llama 3.3 70B Instruct |
| Observability | MLflow Tracing — every Foundation Model API call tracked with span attributes (model, tokens, latency, status) |
| Backend | Python Flask with Gunicorn (2 workers, 180s timeout) |
| Frontend | Vanilla HTML/CSS/JS — single-page application |
| Deployment | Databricks Apps |
The Pinocchio Score formula:
Each facility's overclaiming risk is calculated as an additive penalty:
$$ \text{Pinocchio Score} = \sum_{i=1}^{8} P_i $$
Where penalties \( P_i \) are:
| Condition | Penalty |
|---|---|
| Claims 24/7 emergency, doctors < 3 | +15 |
| Claims ICU, doctors < 2 | +25 |
| Claims multispecialty, doctors < 3 | +20 |
| Claims cardiology, no cardiac equipment found | +10 |
| Claims oncology, no oncology equipment found | +10 |
| Claims NICU, no ventilator found | +15 |
| Specialty list truncated at exactly 50 | +5 |
| facilityTypeId field is corrupted | +5 |
Evidence Triangulation scans 4 raw text fields per claim, extracts keyword matches with surrounding context (±30 characters), and combines text evidence with structural checks (doctor count, equipment presence) to produce a confidence-weighted trust signal.
AI Agent Architecture:
User Mission → Databricks SQL (retrieve facility data)
↓
Llama 3.3 70B (Foundation Model API)
↓
Structured Policy Brief (JSON with citations)
The agent supports exponential backoff retry (3 attempts) for 429/503 responses, dual-mode operation (conversational chat + structured briefs), and multi-turn conversation history (last 10 messages).
Challenges we ran into
Messy data is the real enemy. The facilityTypeId field contained latitude coordinates, MD5 hashes, and URL arrays instead of values like "hospital" or "clinic." We had to build a cleaning pipeline that infers the correct type from facility names and descriptions.
The 50-specialty ceiling. We noticed a suspicious spike at exactly 50 specialties — statistically impossible if organic. This turned out to be a scraping pipeline cap. 2,884 facilities are affected, meaning their real capability is understated.
Foundation Model rate limits. During peak hackathon hours, the Llama 3.3 70B endpoint returns 429 (Too Many Requests) frequently. We implemented exponential backoff with 3 retries and cached preset mission responses to ensure the demo always works.
Communicating uncertainty without being vague. The hardest design problem wasn't technical — it was figuring out how to say "we don't know" in a way that's useful. We landed on field-by-field coverage bars with dataset-wide percentages (e.g., "Only 36.4% report doctor count") and explicit amber warnings when critical data is missing.
Token exposure in deployment. Databricks App deployment requires credentials in app.yaml, which triggered GitHub's secret scanner. We solved this with a .gitignore for the real config and a template app.yaml.example for the repo.
Accomplishments that we're proud of
- 847 suspicious 24/7 claims identified — facilities claiming round-the-clock emergency with fewer than 3 doctors
- 168 impossible ICU claims — ICU with less than 2 doctors on record
- Every single trust score is traceable — click the breakdown and see exactly which data triggered each penalty
- The AI agent actually works live — not a mockup, real Llama 3.3 70B generating policy briefs from Unity Catalog data
- Full MLflow observability — every Foundation Model API call is traced with span-level attributes (model name, token count, latency, HTTP status) for production-grade agent monitoring
- Voice input in Hindi, Tamil, Bengali, Telugu, Marathi, and Gujarati — because health planners in India don't always type in English
What we learned
- That uncertainty communication is harder than building features. Any dashboard can show a number. The hard part is showing how confident you should be in that number.
- That raw text is the richest signal in messy data. Structured fields lie (facilityTypeId = latitude coordinates). But the description field — written by humans — contains real evidence if you know how to scan it.
- That Databricks Foundation Model API + SQL Warehouse is a powerful combination for building agents that are grounded in real data, not hallucinations.
What's next for ArogyaSetu AI
- Geospatial gap analysis — overlay facility trust scores on district maps to identify true medical deserts (not just data-poor regions)
- Ayushman Bharat (PMJAY) eligibility engine — automatically assess which facilities meet government insurance scheme criteria based on verified evidence
- Real-time monitoring — track facility data changes over time to catch deterioration and flag newly appearing ghost facilities
- Multi-language interface — full UI translation for Hindi and regional languages to serve grassroots health workers
Built With
- backplane-javascript
- css
- databricks
- databricks-apps
- databricks-foundation-model-api
- databricks-sql-warehouse
- databricks-unity-catalog
- flask
- gunicorn
- html
- javascript
- llama-3.3
- llama-3.3-70b
- mlflow
- python
- speech
- sql-warehouse
- unity-catalog
- web


Log in or sign up for Devpost to join the conversation.