-
-

-

-
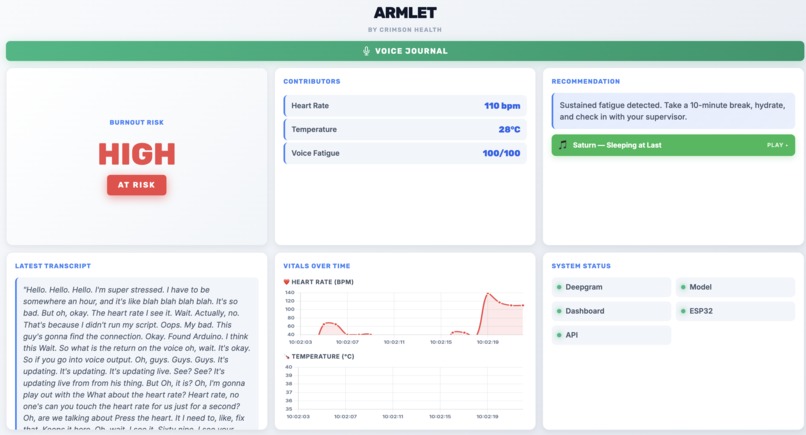
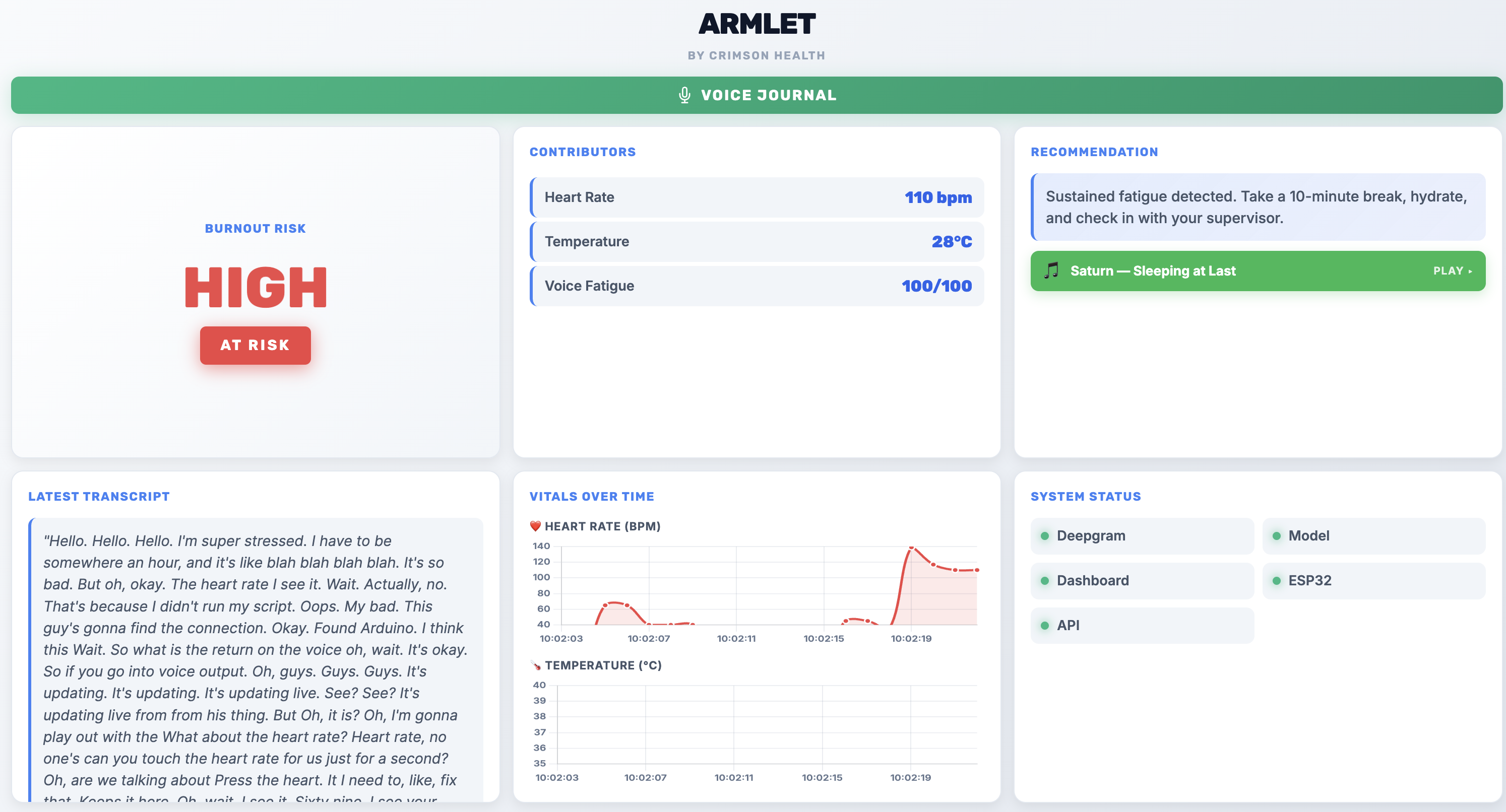
high level burnout alert
-
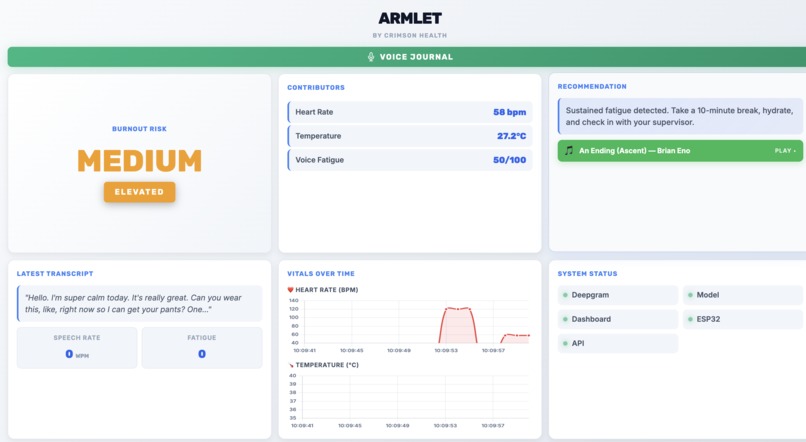
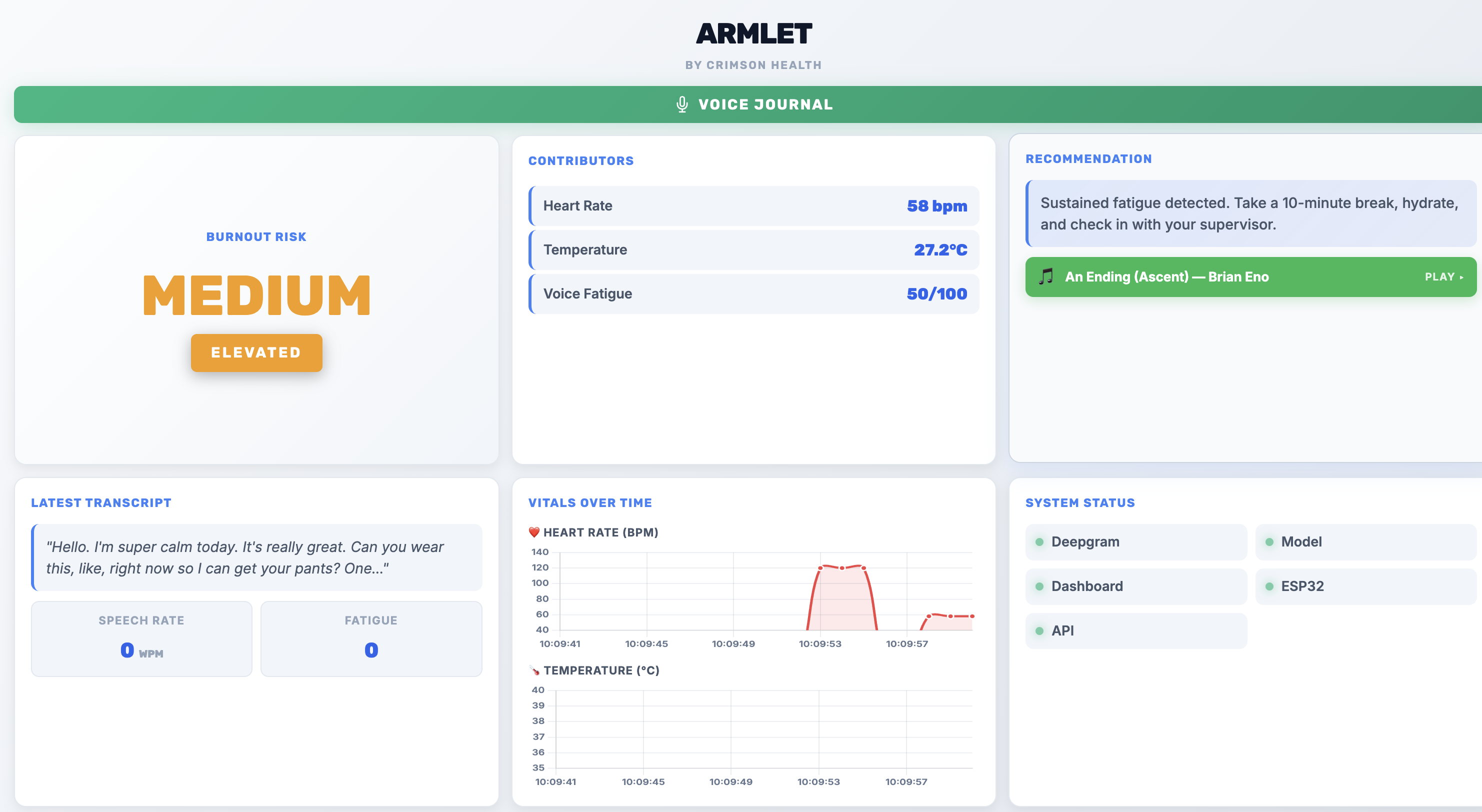
medium level burnout alert
-

-

-






Armlet by Crimson Health
Target Tracks:
Inspiration
A burned-out nurse on hour 11 of a double shift makes more medical errors. A first responder experiencing acute stress loses situational awareness. Current wellness solutions check in after the shift, when the damage is already done.
We were inspired by the unsung heroes in healthcare and emergency services to build a solution that catches the psychological and physiological "drift" into severe burnout in real time, quietly and privately, during the shift before it becomes a safety issue.
The Problem: 12-hour shifts create a massive "blind spot" for cognitive fatigue. Waiting for post-shift survey check-ins fails to protect workers or patients in the moments that matter most.
What it does
Armlet is a wearable sensor and dashboard ecosystem designed specifically for mission-critical personnel. Crimson Health is the idea of a research based company that supports AI products within the healthcare industry.
- Real-Time Physiology: The armband continuously streams temperature and heart rate metrics to evaluate acute physiological stress, processed through a model trained to also incorporate motion data.
- Dual-Signal Voice Analysis: Through short, spoken mid-shift check-ins, Armlet uses Deepgram to transcribe speech, then analyzes it through two independent signals: what was said (semantic sentiment) and how it was said (acoustic tone, via a dedicated speech-emotion model).
- Live Risk Scoring: A central hub processes physiological and voice inputs to compute a live burnout risk score and trace shift-long drift trends.
- Intelligent Intervention: When stress crosses a critical safety threshold, the system triggers an empathetic voice nudge via Deepgram's Text-to-Speech (TTS), privately prompting the worker to take a break.
How we built it
The Technical Topology
| Layer | Component | Protocol / Framework | Purpose |
|---|---|---|---|
| Wearable Node | ESP32 + temp + heart-rate sensors | UDP Socket | Low-overhead biometric streaming |
| Edge Gateway | UDP Socket | Ingests sensor packets and routes them for inference | |
| Intelligence | Random Forest (WESAD, ONNX) | ONNX Runtime | Computes live burnout risk score from sensor data |
| Voice: Semantic | Deepgram STT + VADER | REST API | Transcribes check-ins and scores sentiment |
| Voice: Tone | wav2vec2-based speech-emotion model |
Local inference | Analyzes vocal stress independent of words spoken |
| Voice: Output | Deepgram TTS | REST API | Generates spoken intervention nudges |
| Observability | Arize SDK | Logging API | Monitors live data ingestion accuracy |
- The Hardware: An ESP32 microcontroller paired with temperature and heart-rate sensors forms the wearable node, housed in a 3D-printed armband pod, streaming biometric data via low-overhead UDP.
- The Machine Learning Pipeline: We trained a Random Forest classifier on the WESAD (Wearable Stress and Affect Detection) dataset using temperature, heart rate (derived from BVP via peak detection), and motion features, validated with leave-one-subject-out (LOSO) cross-validation to achieve a mean F1 of 0.86. The model was exported to ONNX for fast local inference.
- The Voice Pipeline: We built two independent voice-based stress signals from a single check-in: Deepgram STT feeding a VADER sentiment score (semantic), and a separate pretrained
wav2vec2speech-emotion model analyzing the raw waveform (tone). In testing, these two signals failed on completely non-overlapping cases such as sentiment missed stress expressed through urgency without negative words, tone missed calm speech that simply sounded heavy, and combining them corrected both individually-wrong predictions. - Monitoring: The full pipeline's predictions are logged and monitored live via Arize for observability into real-world model behavior.
Challenges we ran into
- A missing sensor, mid-event. Our hardware kit arrived without the motion sensor we'd planned and trained on. Rather than retrain under time pressure, we used mean-imputed placeholder values for the motion features at inference time and live predictions currently rely most heavily on temperature and heart rate, with the architecture designed to incorporate live motion data as a third signal going forward.
- A dependency dead end. Our first choice of pretrained tone model required a package incompatible with our Python version. Rather than lose hours fighting an install, we swapped to a different pretrained model that worked natively in our environment.
- Hardware Availability & Data Simulation: Because we couldn't deploy every planned sensor on a breadboard overnight, we wrote a custom dataset replayer that streamed exact, chronologically balanced rows from WESAD over local sockets, mimicking live physiological shifts until our physical pipeline was fully flashed.
Accomplishments that we're proud of
- End-to-End Live Loop: We avoided a slide-based presentation entirely. Sitting still and speaking calmly registers low stress; moving erratically and speaking under stress causes our live dashboard to instantly spike and trigger a real voice intervention.
- A genuinely multimodal voice result. Our semantic and tone models don't just both "work", they fail on different, specific, identifiable cases, and combining them measurably corrects both. That's not an assumption, it's something we tested for directly.
- Deep Sponsor Integration: Deepgram forms a structural two-way loop (STT + TTS), not a single bolted-on call, and Arize monitors real-world model execution live.
- Clean Physical Presentation: We moved away from the "spaghetti-wire breadboard" look with a tightly packaged, intentional physical form factor.
What we learned
- Combining signals only helps if you check where each one fails. Two models that are each "pretty good" but wrong in the same way don't actually help each other, and verifying that ours weren't with real test data, was one of the most useful things we did all weekend.
- Architecting for the edge. Designing for mission-critical, safety-relevant software taught us how to partition systems into high-reliability and high-flexibility layers.
What's next for Armlet by Crimson Health
- Trust & Data Security: As Armlet handles sensitive biometric and voice data, productionizing this would require end-to-end encryption for sensor-to-hub transmission, on-device data minimization (processing and discarding raw audio rather than storing it), and clear consent and control for the wearer over what's shared with any supervisor-facing dashboard.
- Additional Environmental Sensing: Adding a humidity sensor alongside temperature and motion would let the system distinguish environmental heat stress (e.g., a first responder working in a hot, humid environment) from internal physiological stress, something temperature alone can't fully separate.
- True Form-Factor Customization: Transitioning from the ESP32 development board to a custom PCB and a fully optimized, ergonomically fitted enclosure.
- Production-Grade Acoustic Modeling: Training a tone classifier on first-responder-specific voice data, rather than relying on a general-purpose pretrained emotion model.






Log in or sign up for Devpost to join the conversation.