-
-

-
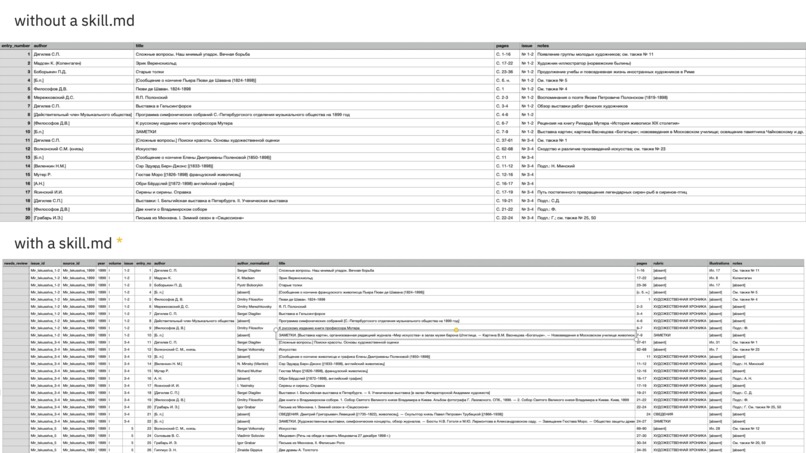
Results with and without the generated skill

ArkSkill
Built for humanities scholars by humanities scholars
Inspiration
The ArkSkill team comes from Digital Humanities — a field where computational methods deepen and scale our understanding of cultural phenomena. Across years of research and collaboration, one pattern kept emerging.
Bibliographies, indexes, and tables of contents are among the richest primary sources available to humanities scholars. They map what was published, discussed, and distributed — by whom, when, and where. They reveal canons, trace networks, and expose gaps. Yet most exist only as typed pages in physical volumes: undigitized, unrecognized, and effectively unanalyzable. The data is there. Getting to it is the problem.
Computational methods offer a way in — but the entry barrier is high. Humanities researchers rarely have programming experience, and data extraction is consistently rated as the most challenging and time-consuming step in any digital project. Some seek external funding to hire technical specialists. Many simply don't begin. Others turn to AI.
But most AI interactions are improvised. Researchers re-explain their source every session, correct the same mistakes, and start over with every new conversation. The results are inconsistent, hard to scale, and far from the precision research demands.
What It Does
ArkSkill structures that interaction. Researchers fill out an eight-question form about their source — title, type, language, a sample entry, expected output fields, and a few structural parameters. ArkSkill produces a SKILL.md file that encodes a data specialist's approach for their specific case:
- what fields to extract
- how to handle edge cases and OCR artifacts
- how to flag uncertain entries for human review
- how to structure the output for downstream cleaning
Claude reads it once and behaves like a collaborator who already knows the archive.
Once the skill is generated, users download it alongside a plain-language installation guide. We also introduce them to OpenRefine — a free, open-source data cleaning tool — with a beginner's guide written by our team.
How We Built It
ArkSkill is a single-page React application built with Vite and TypeScript, deployed on Vercel.
The core insight was that skill generation requires no backend. The SKILL.md file is produced entirely client-side through structured string interpolation: user inputs are validated, sanitized, and injected into a carefully authored template. The template itself encodes years of practical knowledge about historical structured data — the system fields, the edge case handling rules, the review flagging logic.
One non-trivial engineering problem was YAML frontmatter correctness. The sample_entry field allows free-form multiline text, which breaks standard YAML scalar parsing if not handled carefully. We solved this with the YAML block scalar format (|), combined with consistent 2-space indentation applied programmatically:
const indentedSample = sampleEntry
.trim()
.split("\n")
.map(line => " " + line.trim())
.join("\n");
This ensures the frontmatter parses correctly regardless of what the user pastes — OCR artifacts, dot-leaders, inconsistent spacing, or mixed-language text.
The UI follows a deliberate design language: IBM Plex Mono throughout, a warm off-white background (#f5f2ec), black borders, and a signature gold (#EDBF6F) used sparingly for emphasis. The isometric grid background is a nod to the structured, tabular nature of the data ArkSkill helps extract.
Challenges
Anticipating every edge case is genuinely impossible. Even with deep expertise in historical structured sources, we can't predict every field variation, OCR artifact, or typographic convention across all document types. ArkSkill doesn't pretend otherwise — it's a scaffold, not a guarantee.
YAML is fragile. Free-form user input in a structured file format requires careful sanitization at every level: trailing commas in field lists, inconsistent whitespace, special characters in source titles, multiline sample entries with colons or dashes that YAML interprets as syntax.
Designing for non-technical users without oversimplifying. The eight-question form had to be simple enough for a historian with no data background, while capturing enough specificity to produce a genuinely useful skill. Every label, placeholder, and hint text went through multiple revisions to strike that balance.
What We Learned
The most important thing we learned is that the bottleneck in humanities data work isn't AI capability — it's the interface between researcher knowledge and AI behavior. A well-authored instruction file closes that gap more reliably than any amount of prompt engineering in the moment. The skill format works because it makes implicit expertise explicit and persistent.
We also learned that for this use case, a static client-side architecture is not a limitation but a feature. No database, no authentication, no API keys — the tool is inspectable, forkable, and deployable by anyone. That matters for a research community that values transparency and reproducibility.
Try It Out
Live site: arkskill.vercel.app
Fill out the eight-question form and download your SKILL.md in under five minutes. No account required.
Limitations
ArkSkill is a scaffold, not a guarantee. It encodes a specialist's approach — but no template can anticipate every document type, every OCR failure mode, or every research question. The goal is to make the first step easier and the whole process more consistent, not to replace human judgment at the edges.
Impact
ArkSkill closes a specific but underserved gap: between humanities researchers, their data, and the AI tools they're already using. It doesn't replace data specialists — it puts their expertise in the hands of researchers who don't have one. Free, open, and built by researchers who have at some point faced the same wall.
Built With
- claude
- openrefine
- react
- vercel
- vite

Log in or sign up for Devpost to join the conversation.