-
-
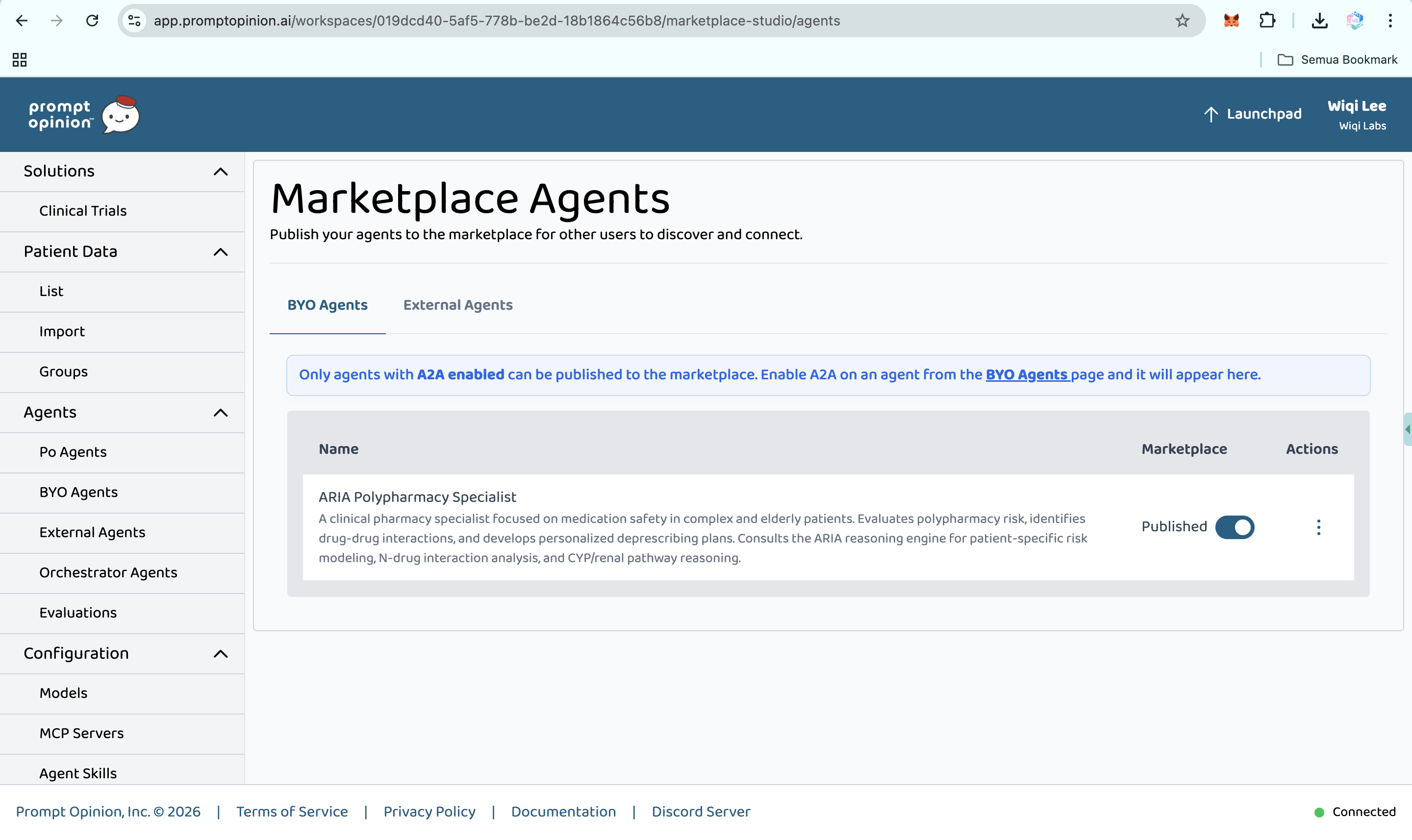
Marketplace Agents (https://app.promptopinion.ai/workspaces/019dcd40-5af5-778b-be2d-18b1864c56b8/marketplace-studio/agents)
-
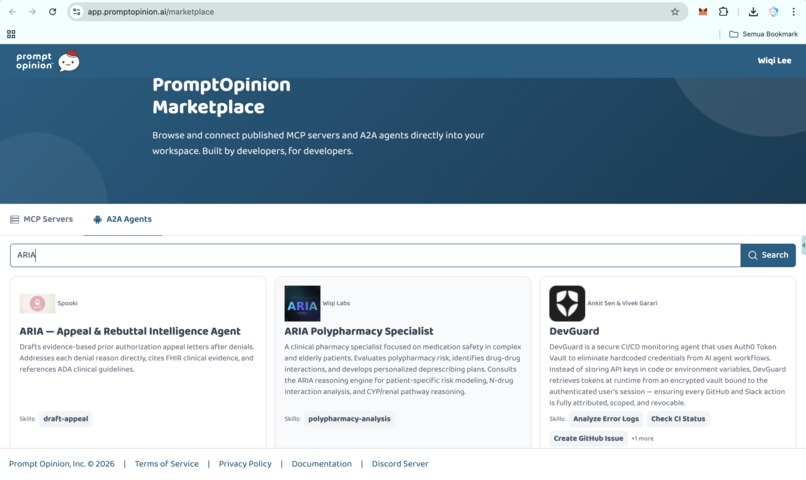
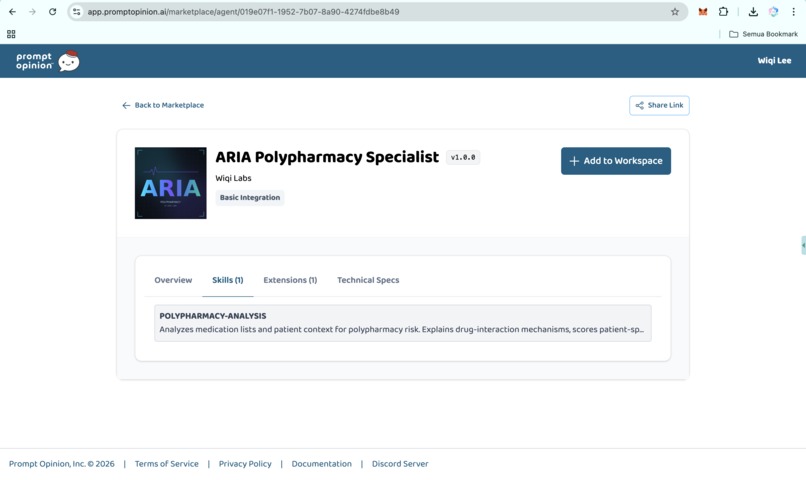
PromptOpinion Marketplace (ARIA Polypharmacy Specialist)
-
https://app.promptopinion.ai/marketplace/agent/019e07f1-1952-7b07-8a90-4274fdbe8b49
-
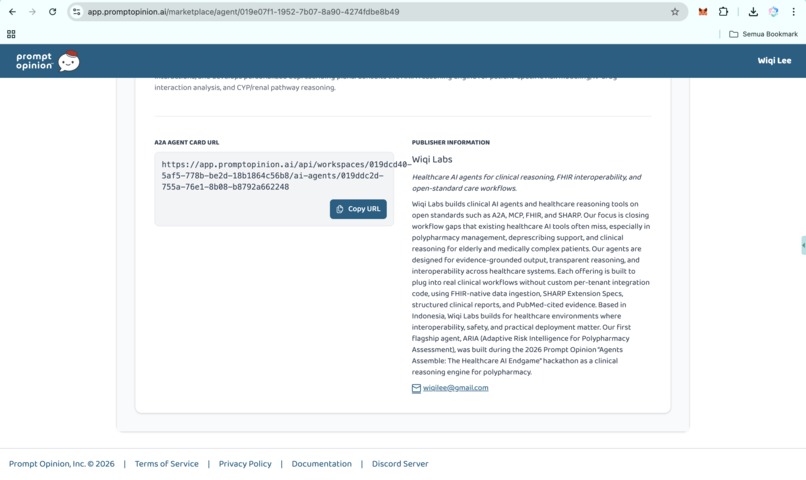
https://app.promptopinion.ai/marketplace/agent/019e07f1-1952-7b07-8a90-4274fdbe8b49
-
https://app.promptopinion.ai/marketplace/agent/019e07f1-1952-7b07-8a90-4274fdbe8b49
-
https://app.promptopinion.ai/marketplace/agent/019e07f1-1952-7b07-8a90-4274fdbe8b49
-
https://app.promptopinion.ai/marketplace/agent/019e07f1-1952-7b07-8a90-4274fdbe8b49
-
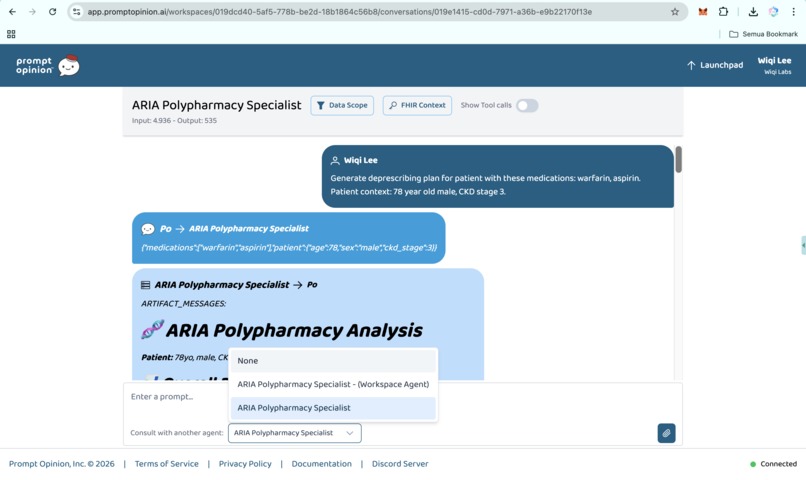
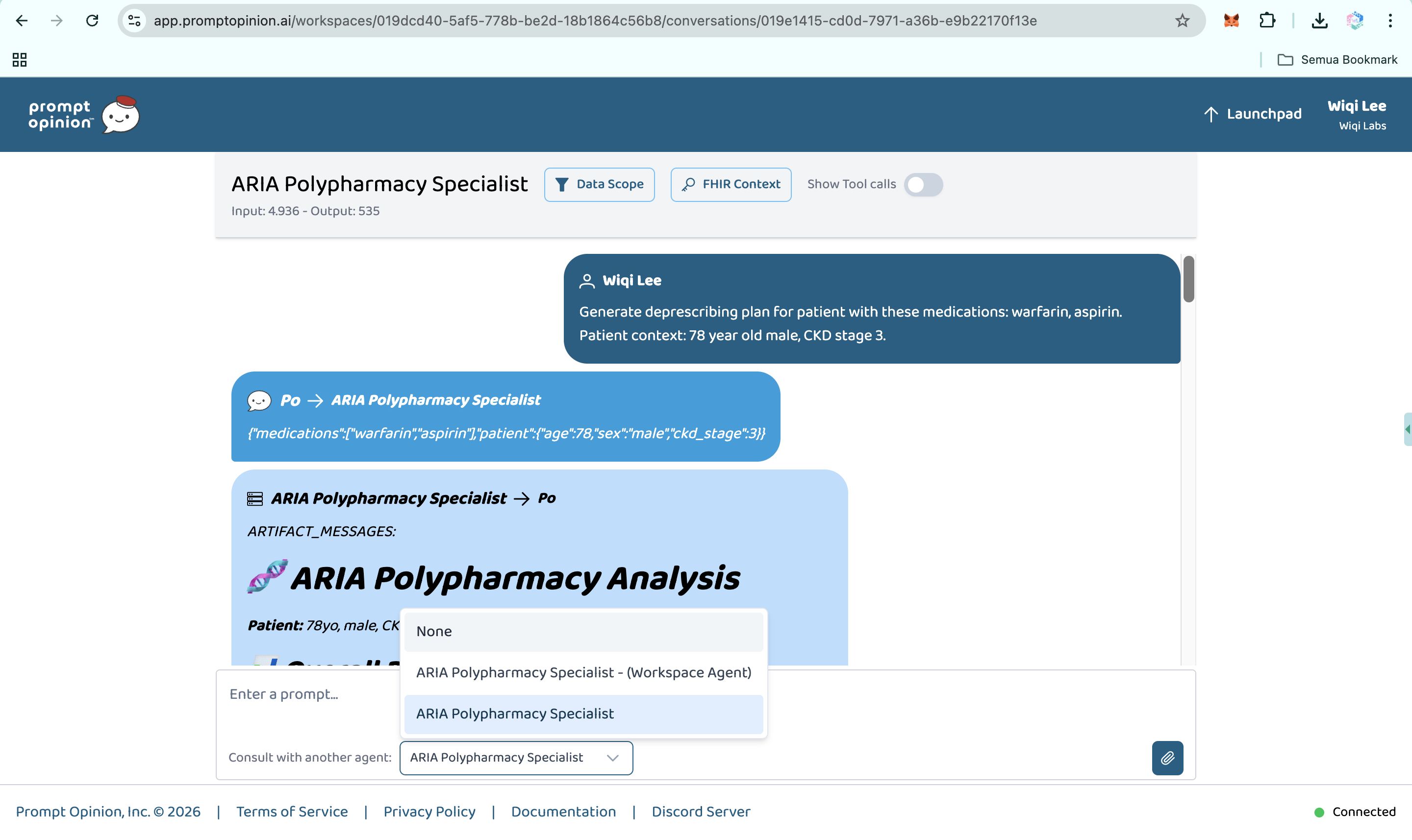
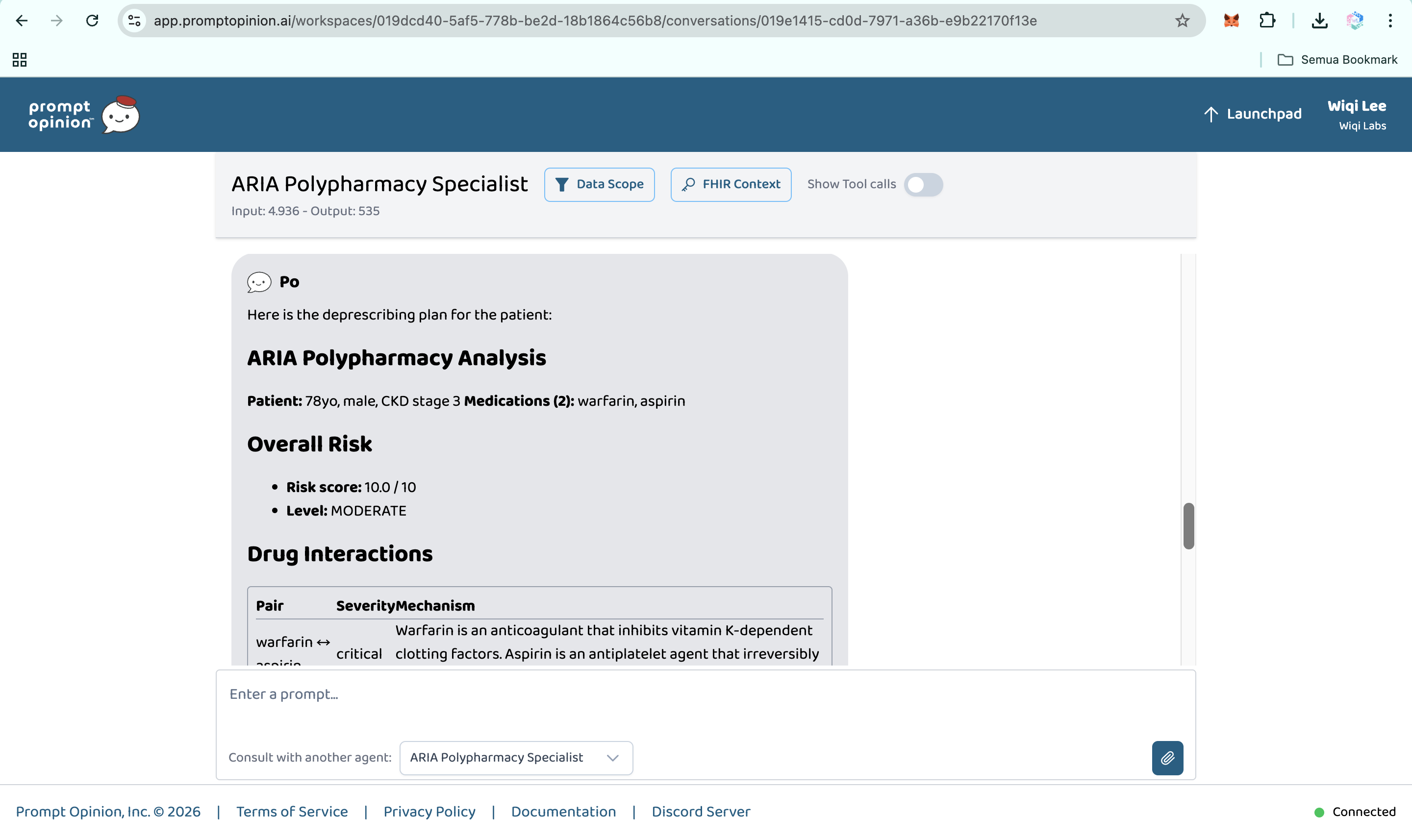
Prompt Opinion test: ARIA Polypharmacy Specialist generated full polypharmacy analysis with deprescribing plan, risk score & monitoring.
-
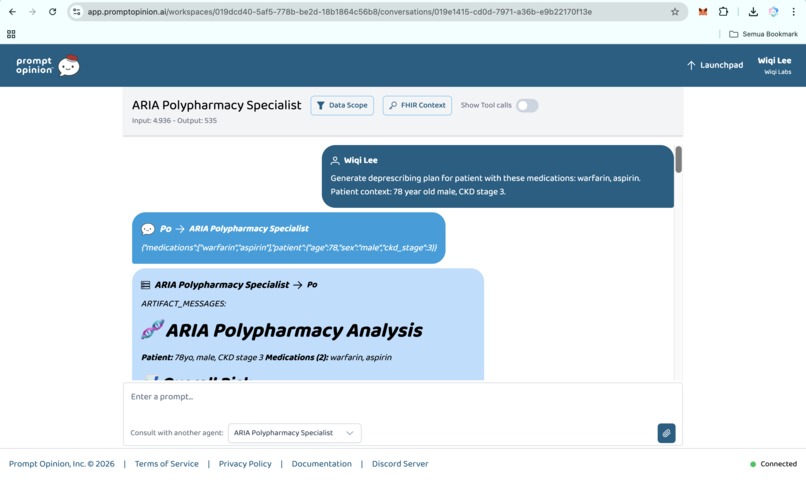
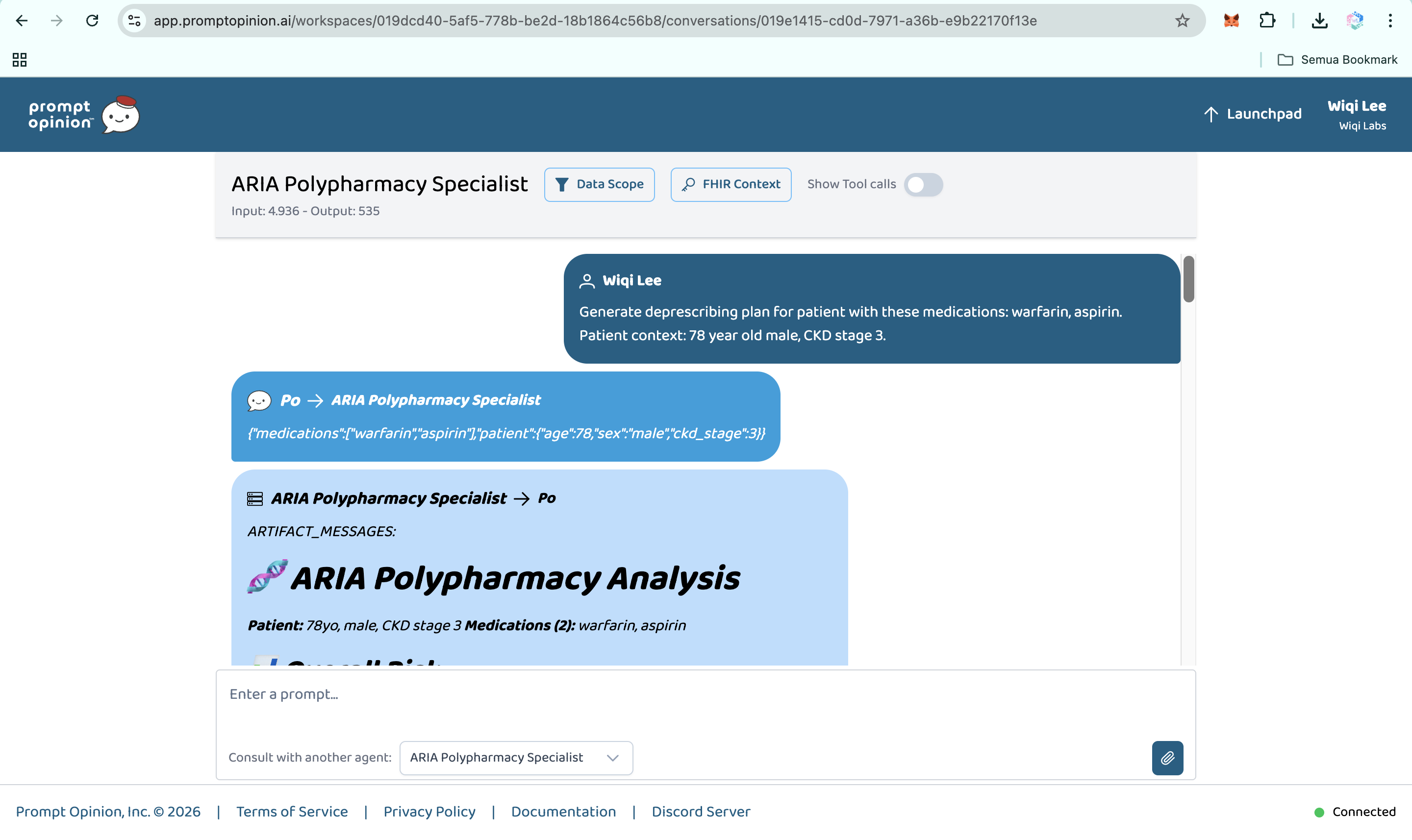
Prompt Opinion test: ARIA Polypharmacy Specialist generated full polypharmacy analysis with deprescribing plan, risk score & monitoring (2)
-
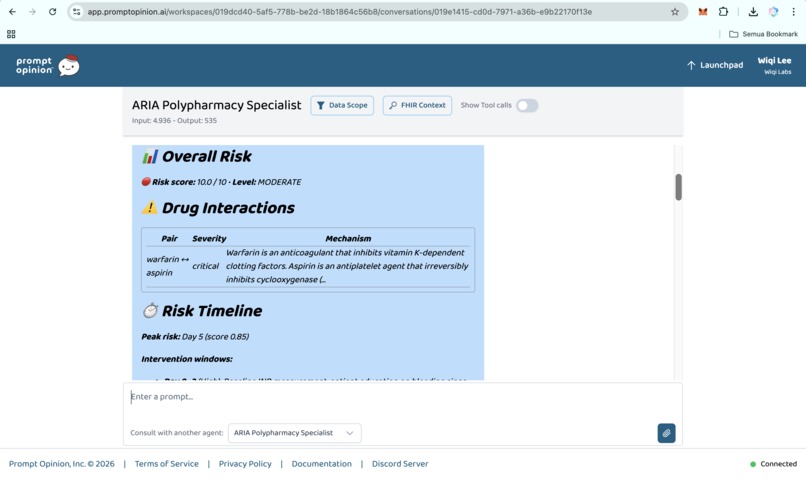
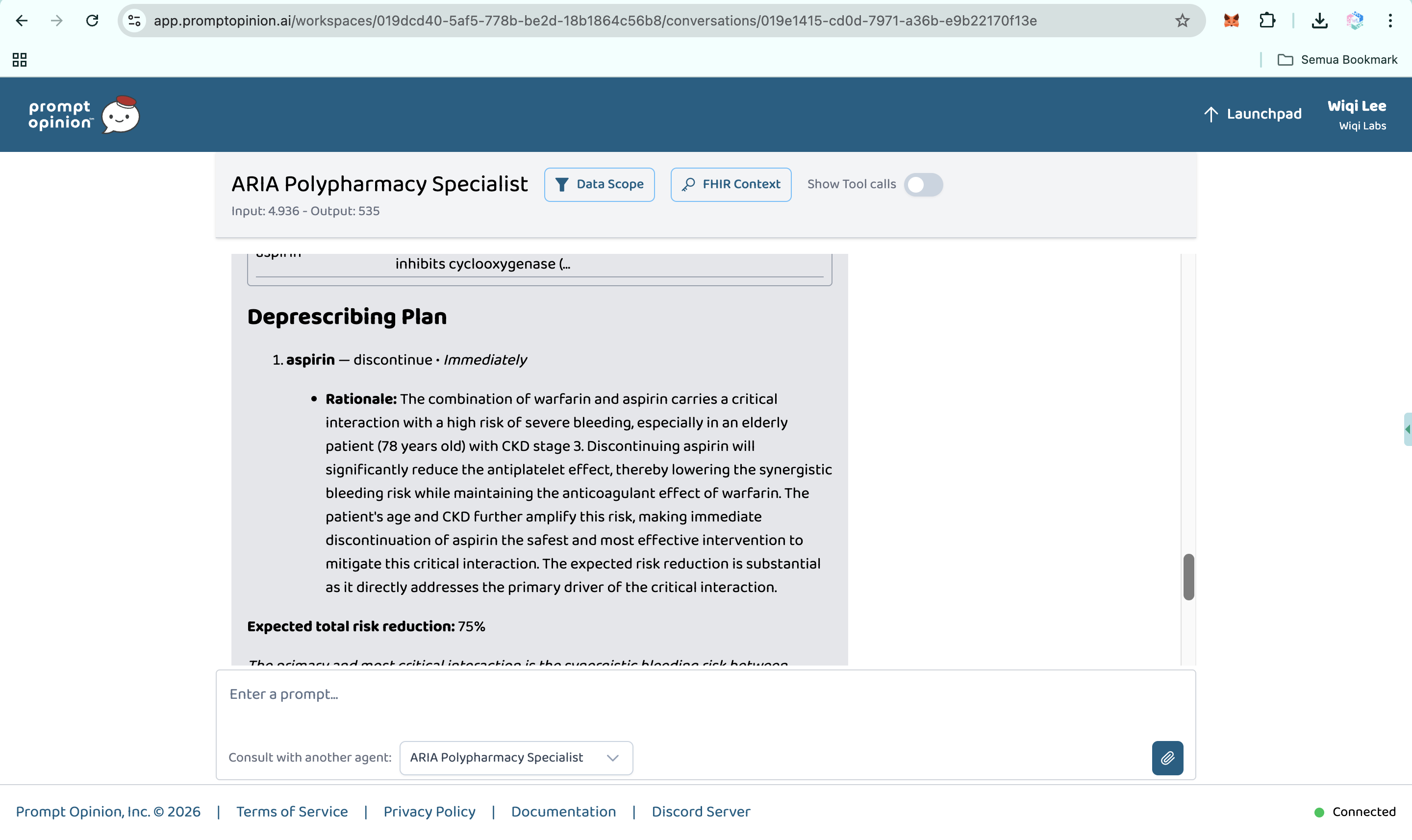
Prompt Opinion test: ARIA Polypharmacy Specialist generated full polypharmacy analysis with deprescribing plan, risk score & monitoring (3)
-
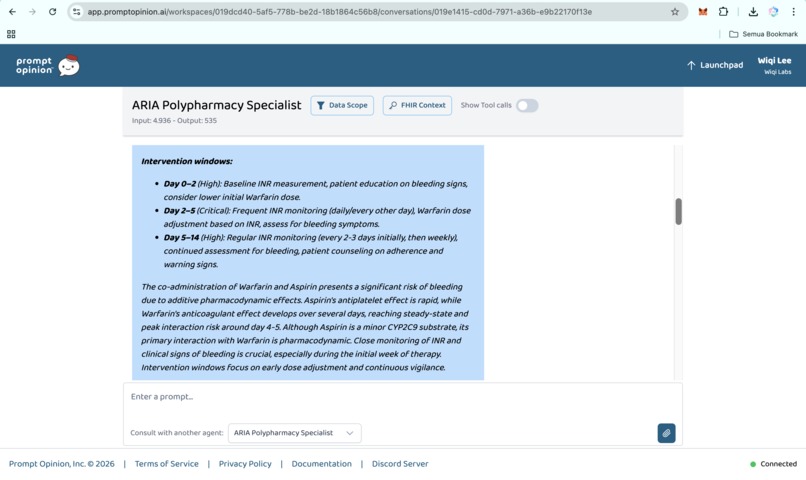
Prompt Opinion test: ARIA Polypharmacy Specialist generated full polypharmacy analysis with deprescribing plan, risk score & monitoring (4)
-
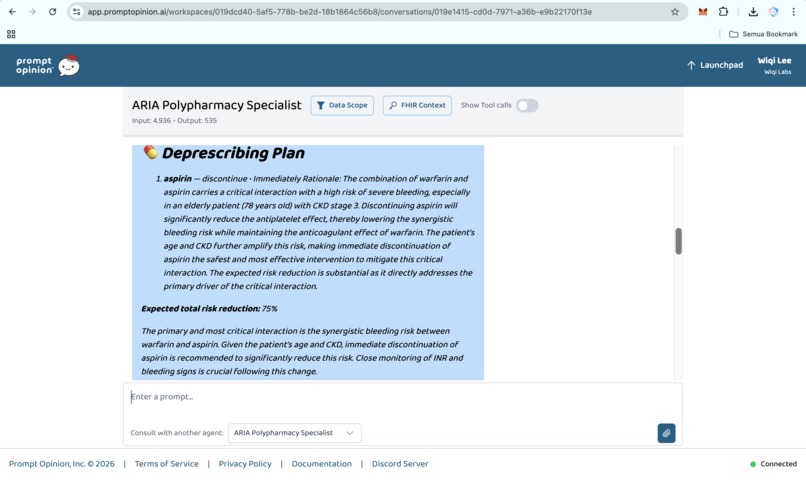
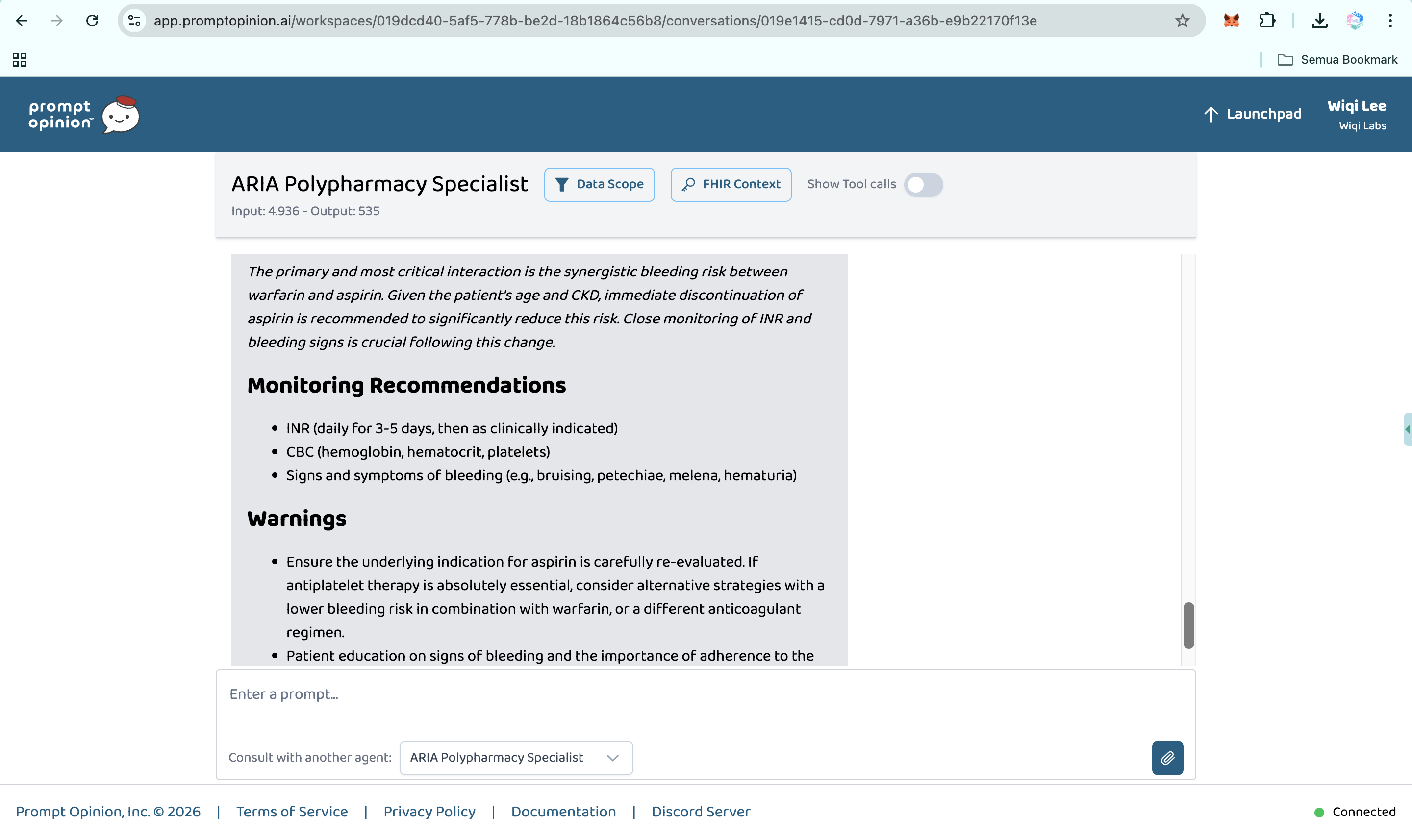
Prompt Opinion test: ARIA Polypharmacy Specialist generated full polypharmacy analysis with deprescribing plan, risk score & monitoring (5)
-
Prompt Opinion test: ARIA Polypharmacy Specialist generated full polypharmacy analysis with deprescribing plan, risk score & monitoring (6)
-
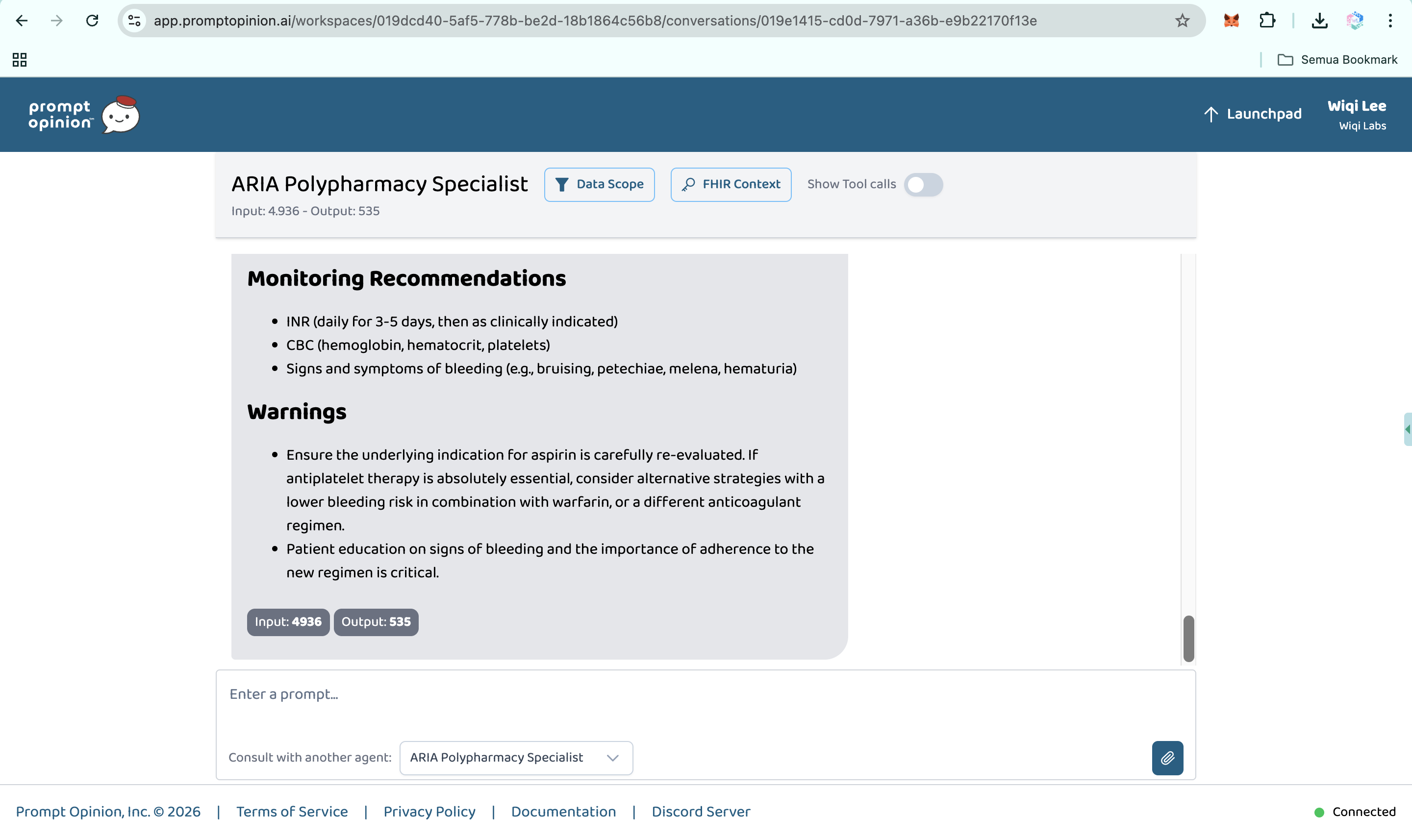
Prompt Opinion test: ARIA Polypharmacy Specialist generated full polypharmacy analysis with deprescribing plan, risk score & monitoring (7)
-
Prompt Opinion test: ARIA Polypharmacy Specialist generated full polypharmacy analysis with deprescribing plan, risk score & monitoring (8)
-
Prompt Opinion test: ARIA Polypharmacy Specialist generated full polypharmacy analysis with deprescribing plan, risk score & monitoring (9)
-
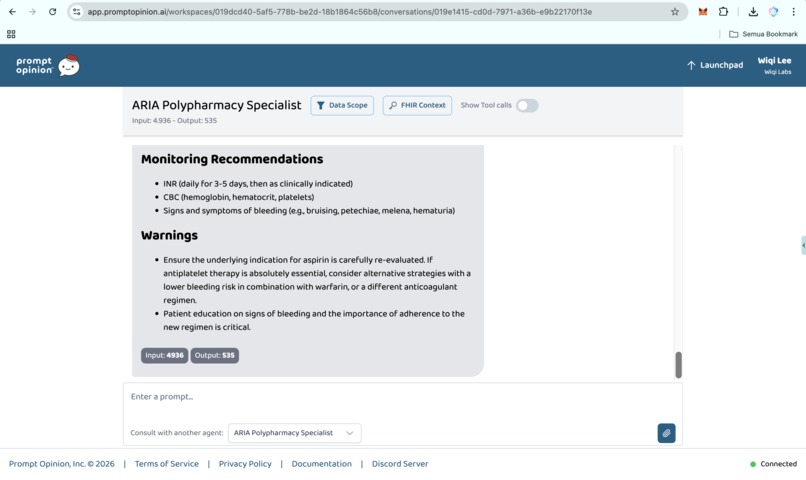
Prompt Opinion test: ARIA Polypharmacy Specialist generated full polypharmacy analysis with deprescribing plan, risk score & monitoring (10)
-
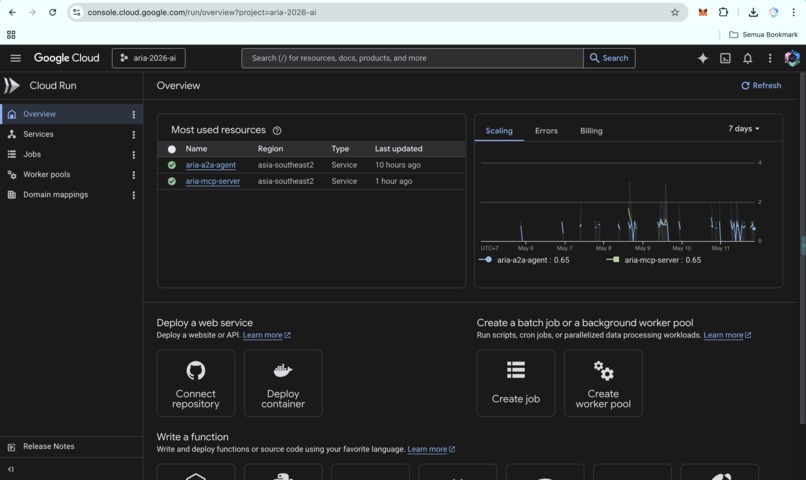
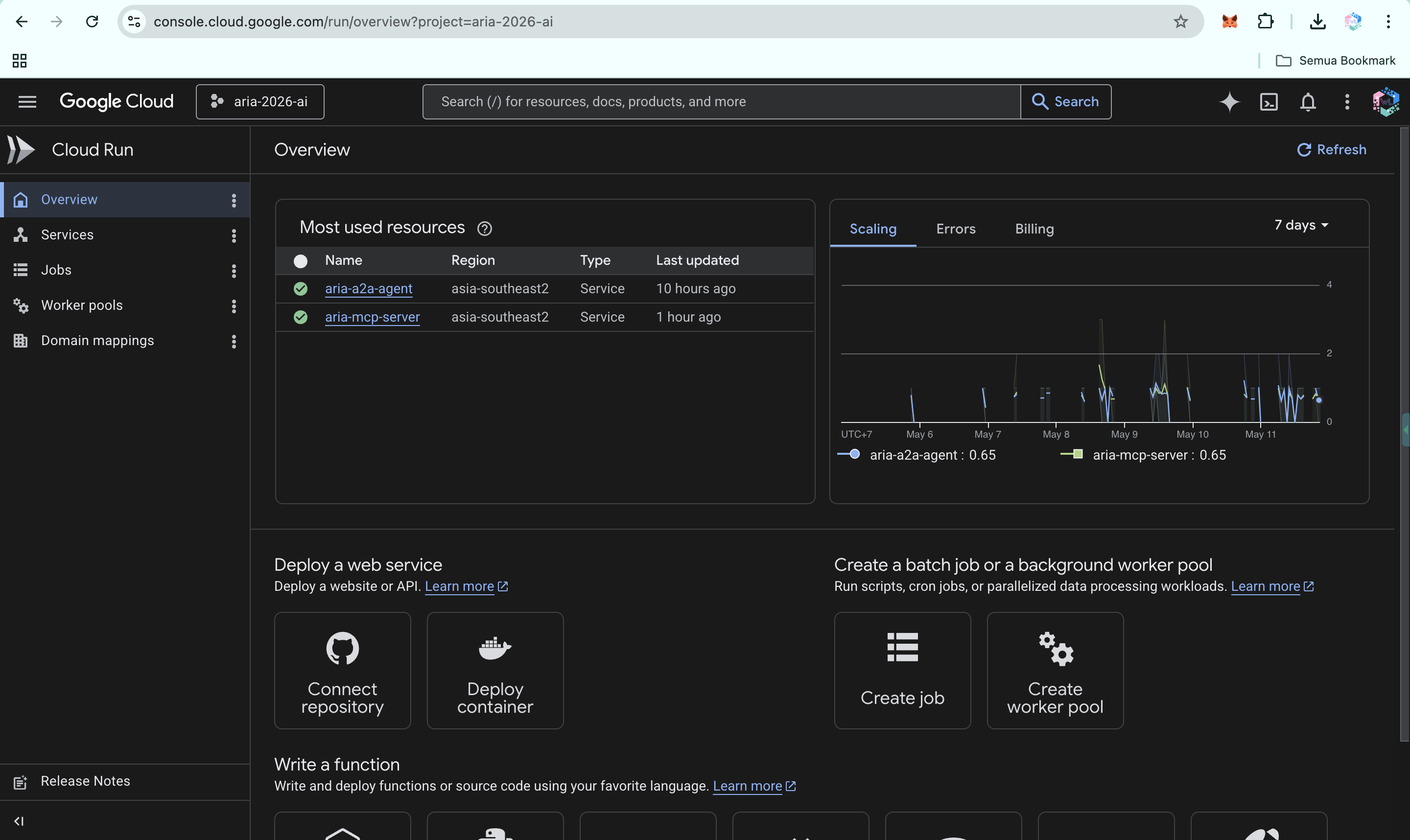
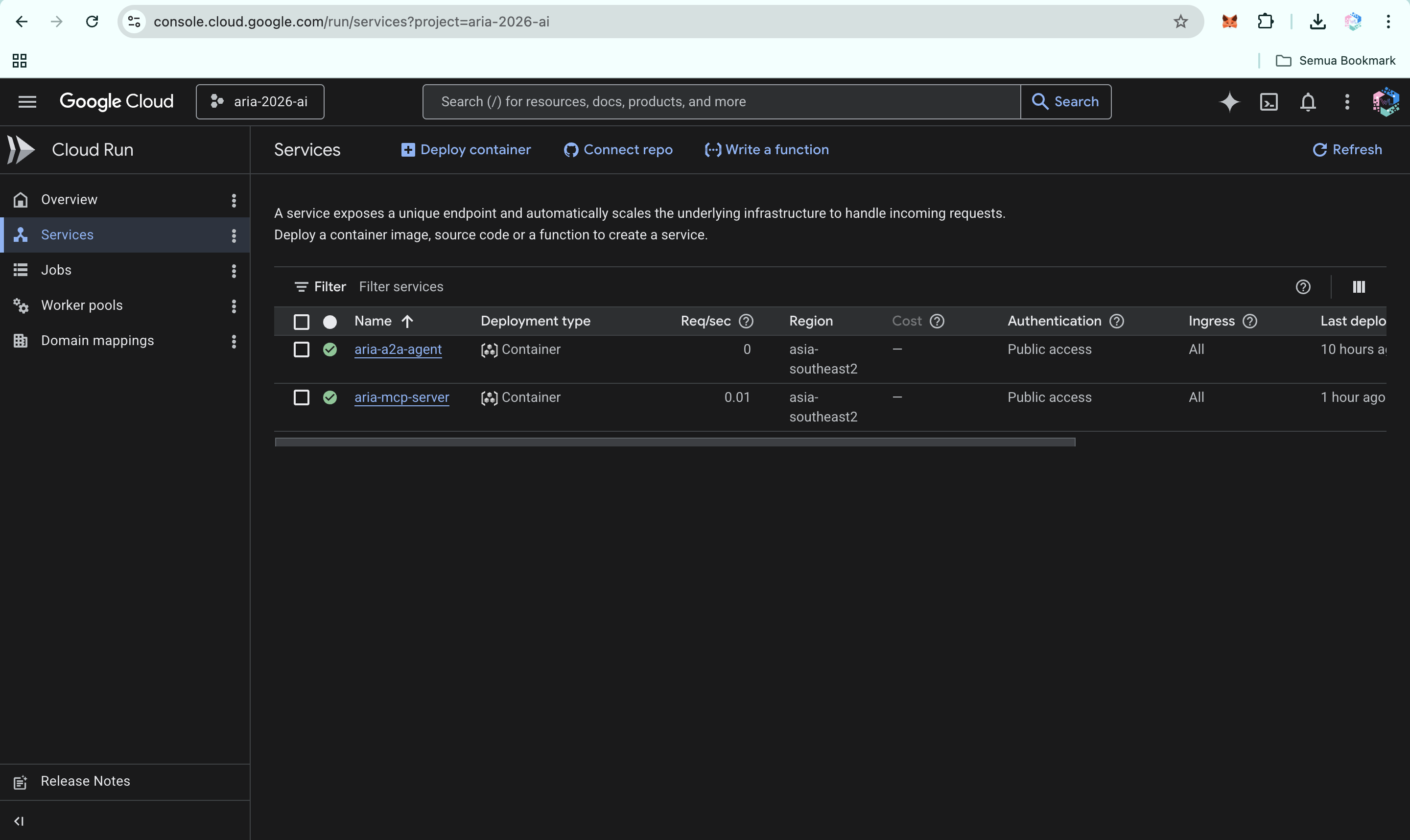
ARIA live on Google Cloud Run: A2A agent and MCP server in asia-southeast2, fully operational for multi-agent clinical workflows.
-
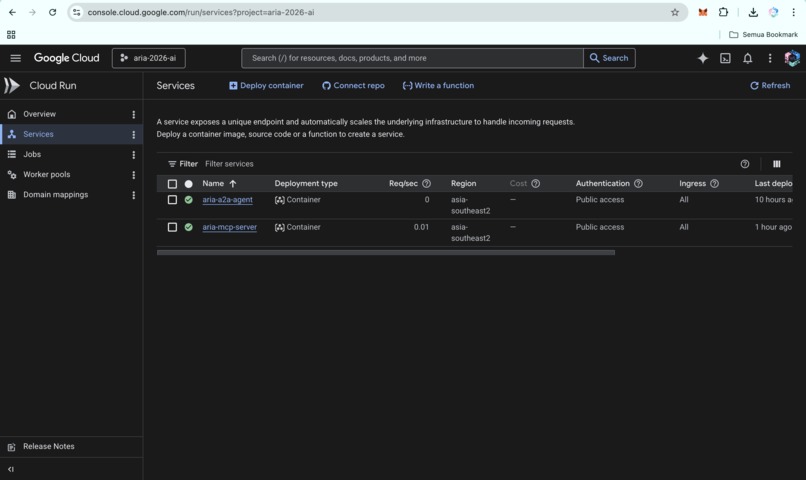
ARIA Cloud Run services: A2A agent and MCP server running in asia-southeast2, fully deployed and ready for clinical workflows.
-
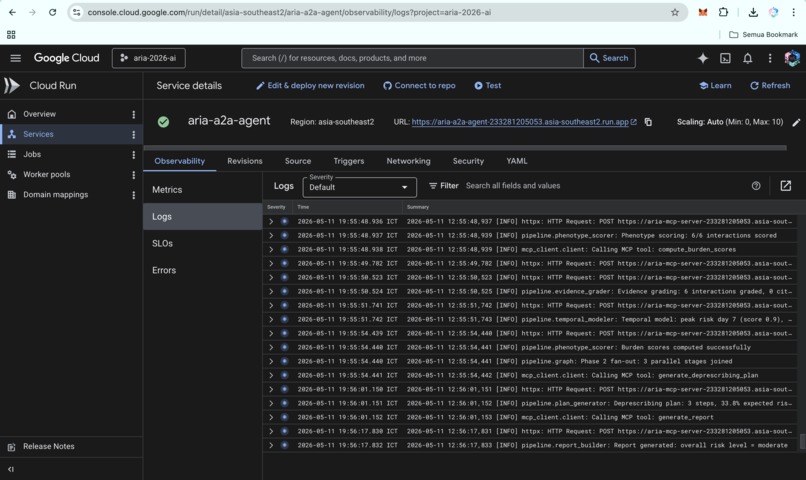
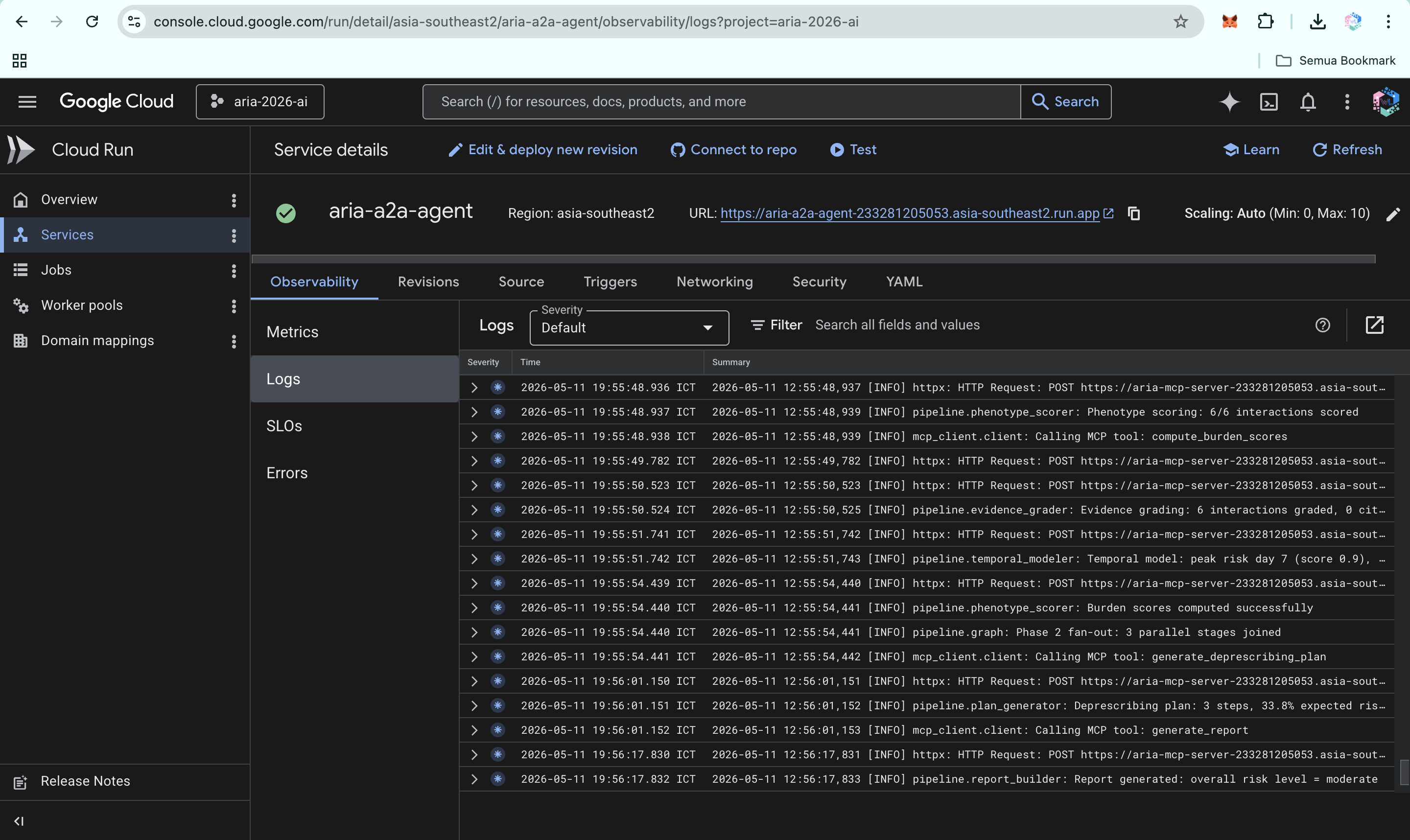
ARIA A2A agent logs on Cloud Run, showing live processing of requests and successful execution of the clinical reasoning pipeline.
-
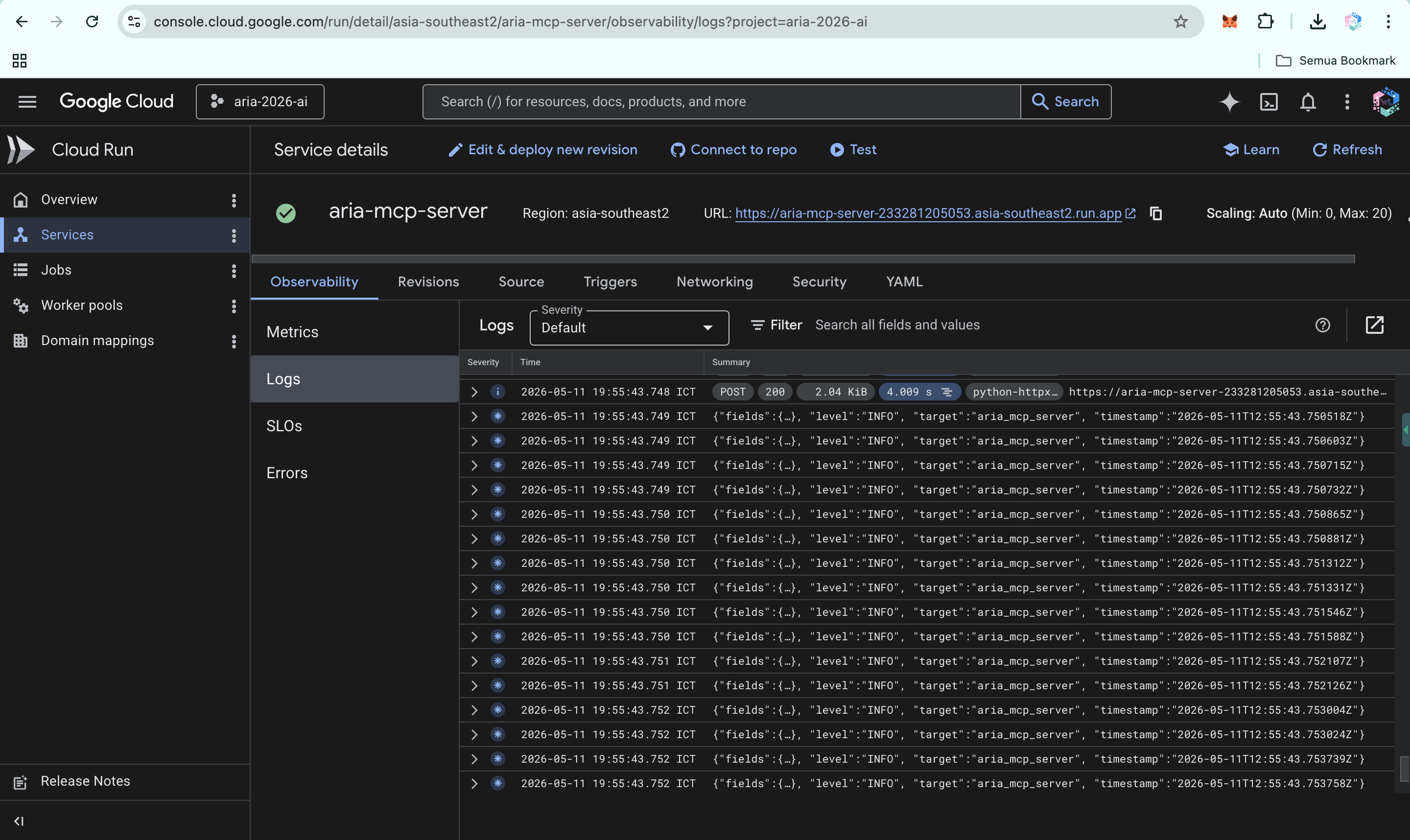
ARIA MCP server logs on Cloud Run, showing live execution of clinical reasoning pipeline and integration with public APIs.
-
https://aria-polypharmacy.vercel.app/
-
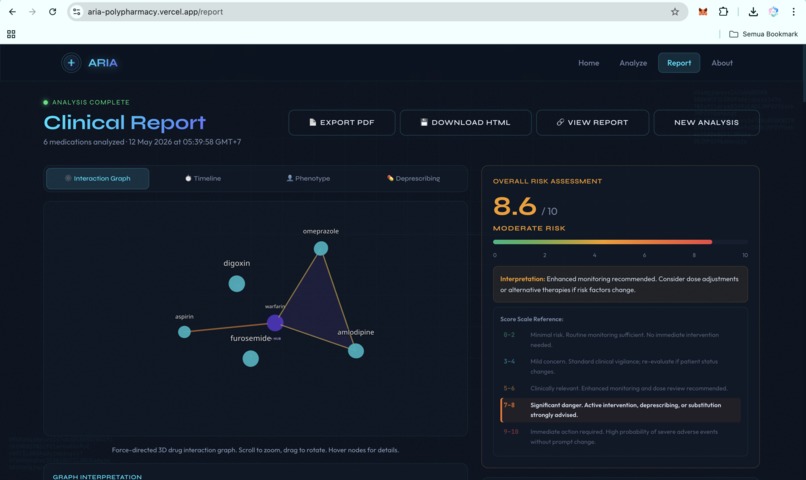
https://aria-polypharmacy.vercel.app/
-
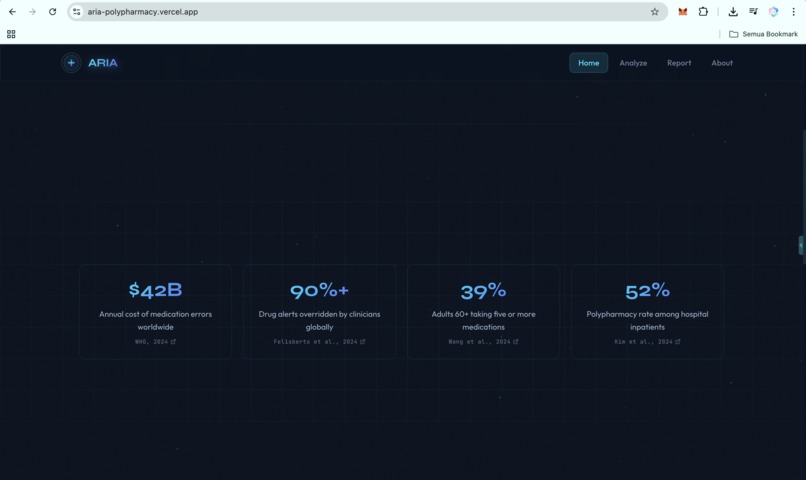
https://aria-polypharmacy.vercel.app/
-
https://aria-polypharmacy.vercel.app/
-
https://aria-polypharmacy.vercel.app/
-
https://aria-polypharmacy.vercel.app/
-
https://aria-polypharmacy.vercel.app/
-
https://aria-polypharmacy.vercel.app/
-
https://aria-polypharmacy.vercel.app/
-
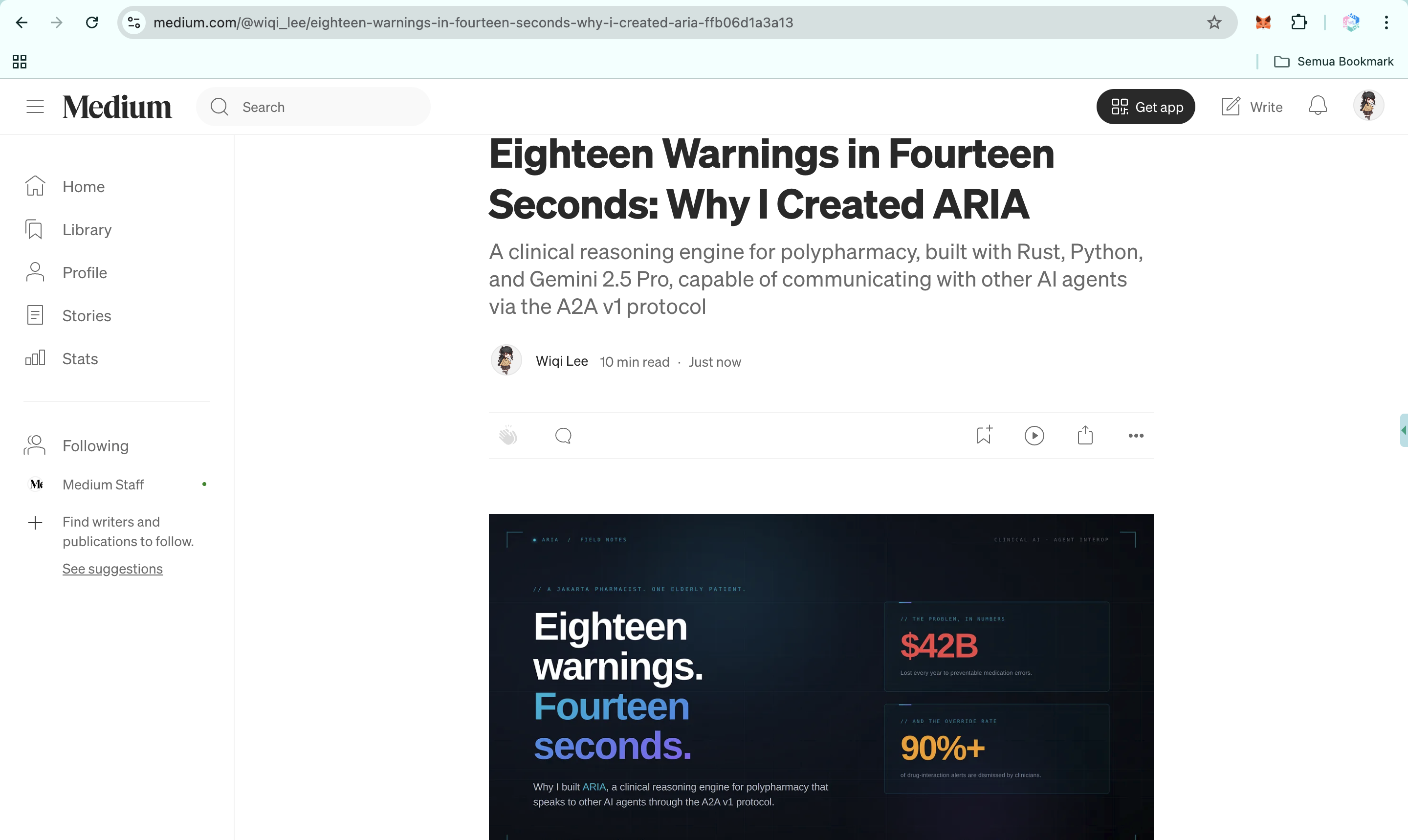
https://medium.com/@wiqi_lee/eighteen-warnings-in-fourteen-seconds-why-i-created-aria-ffb06d1a3a13
Inspiration
A pharmacist friend in Jakarta, Indonesia, once showed me her screen: eighteen drug-interaction pop-ups for one elderly patient taking twelve medications. She closed them all in fourteen seconds, without reading a single one. Not because she did not care, but because she had been trained, like clinicians everywhere, that those alerts were noise. Then she said the line that defines the problem: "If I read every alert, I would never see another patient."
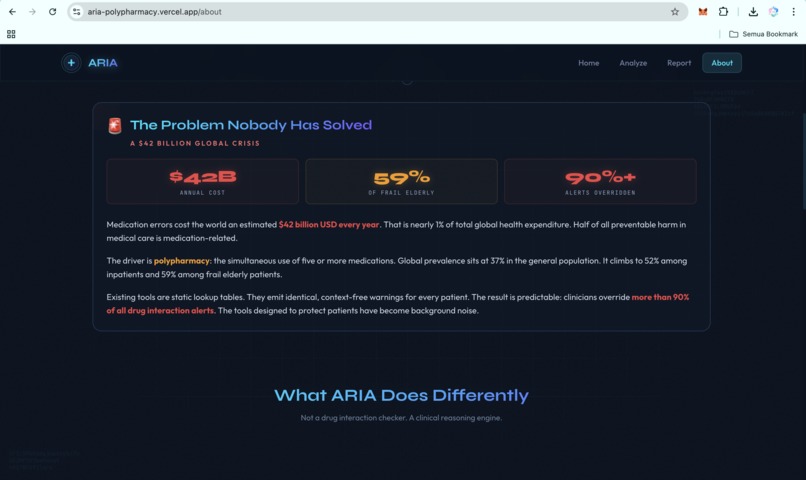
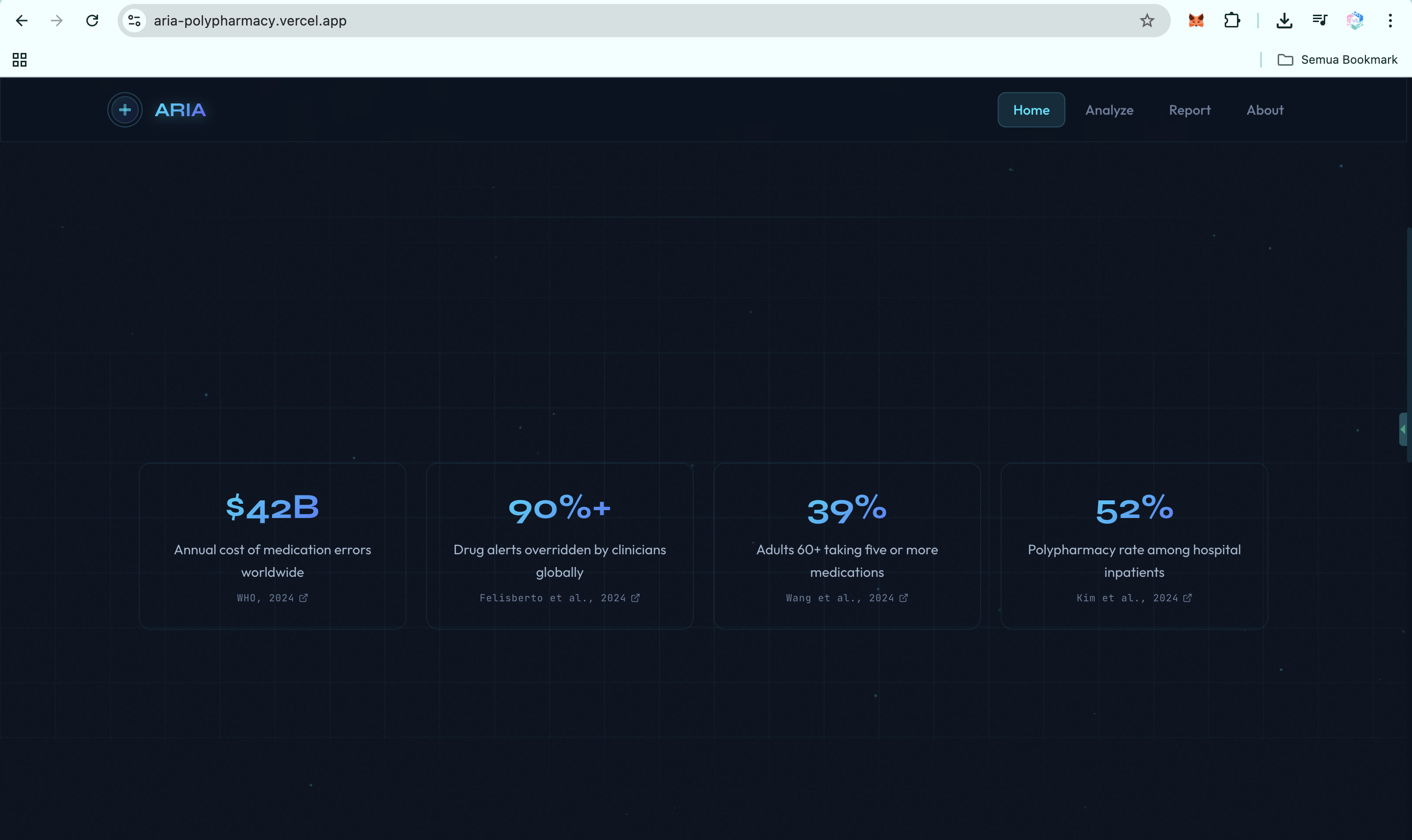
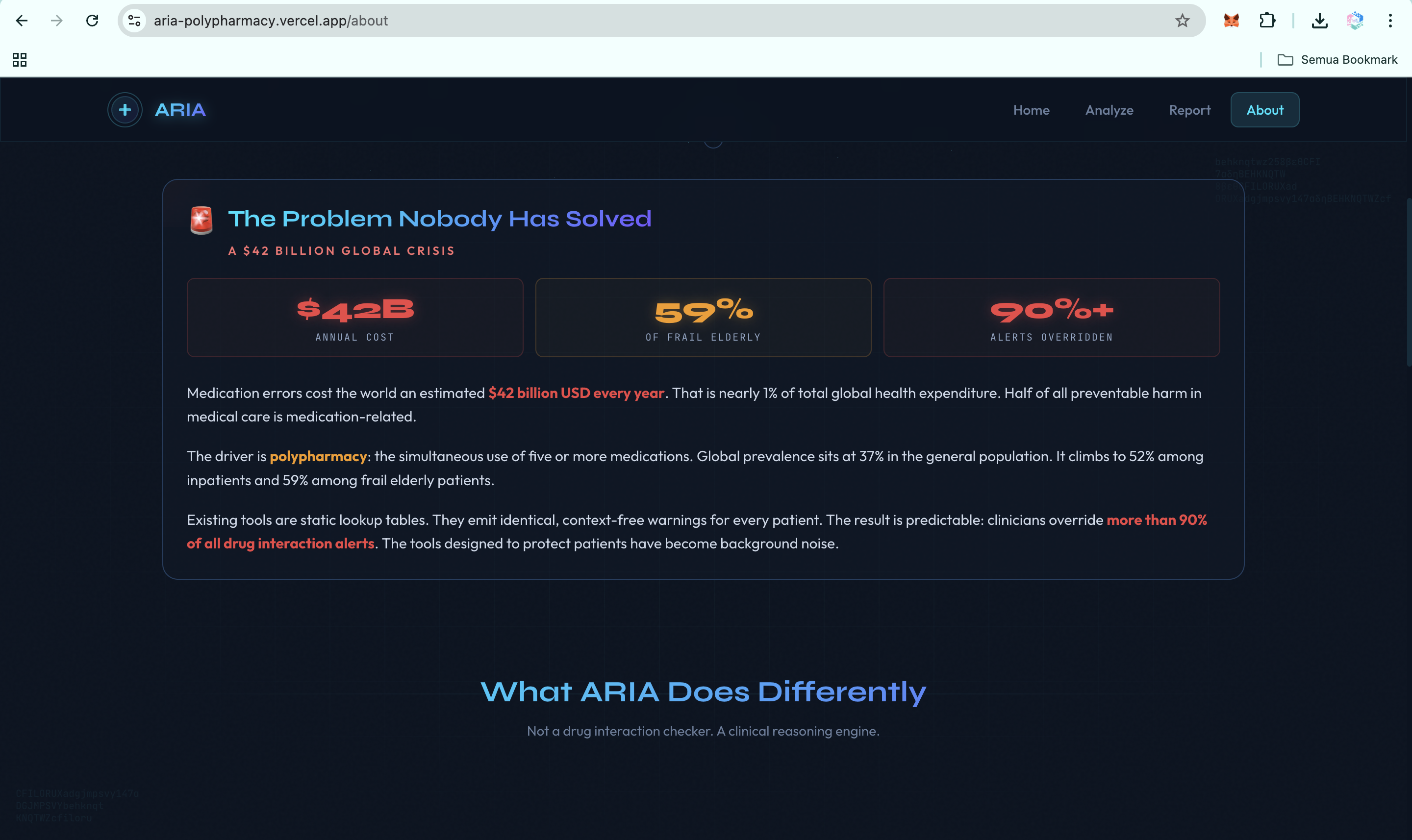
That is the failure mode. The WHO 2024 report on the global burden of preventable medication harm estimates the global cost of medication errors at $42 billion per year, with low- and middle-income countries losing twice as many healthy life years as high-income countries. A 2025 PLOS One systematic review places Africa and Southeast Asia among the regions most affected by preventable medication harm. Clinicians override more than 90% of drug-interaction alerts because most alerts arrive as noise.
Yet the tools clinicians rely on are still mostly static lookup tables. They flag pairs of drugs. They do not understand patient context. They do not explain mechanisms. They do not prioritize what matters first.
ARIA began with one question:
What if a drug-interaction tool could actually reason about the patient in front of it?
What it does
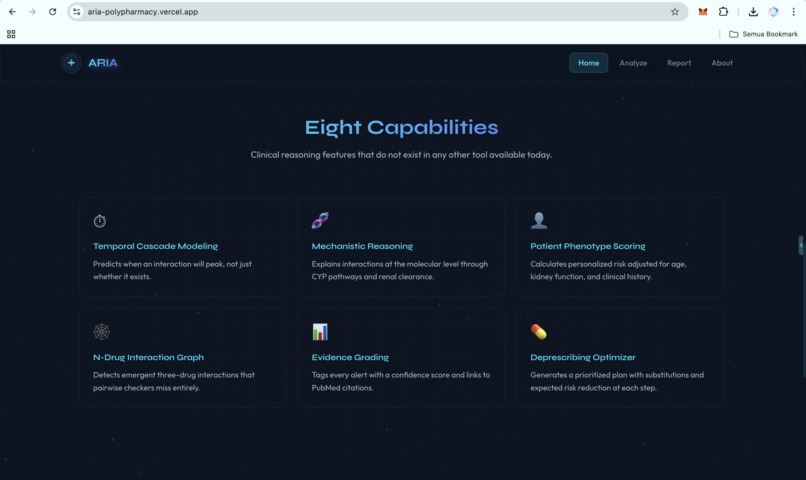
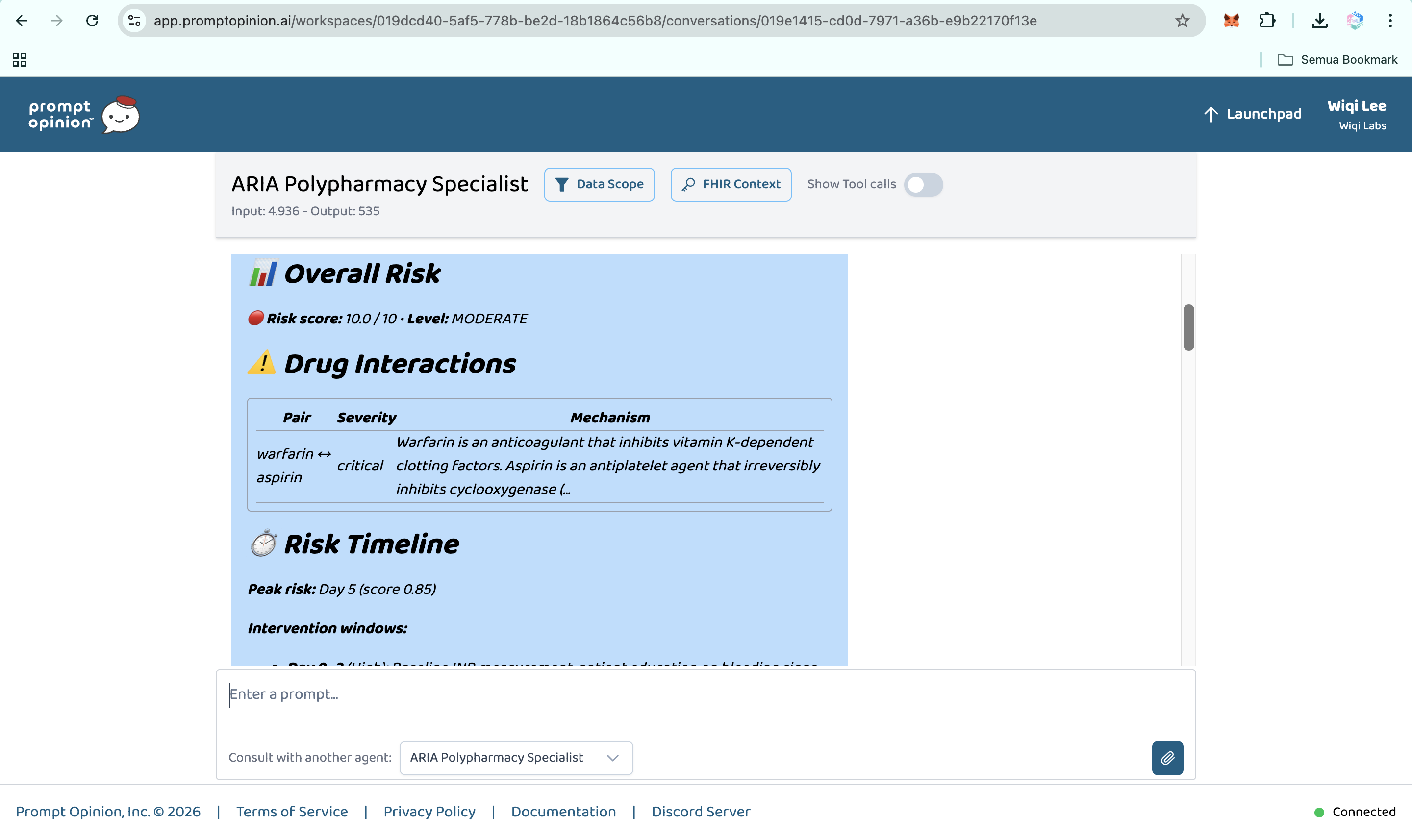
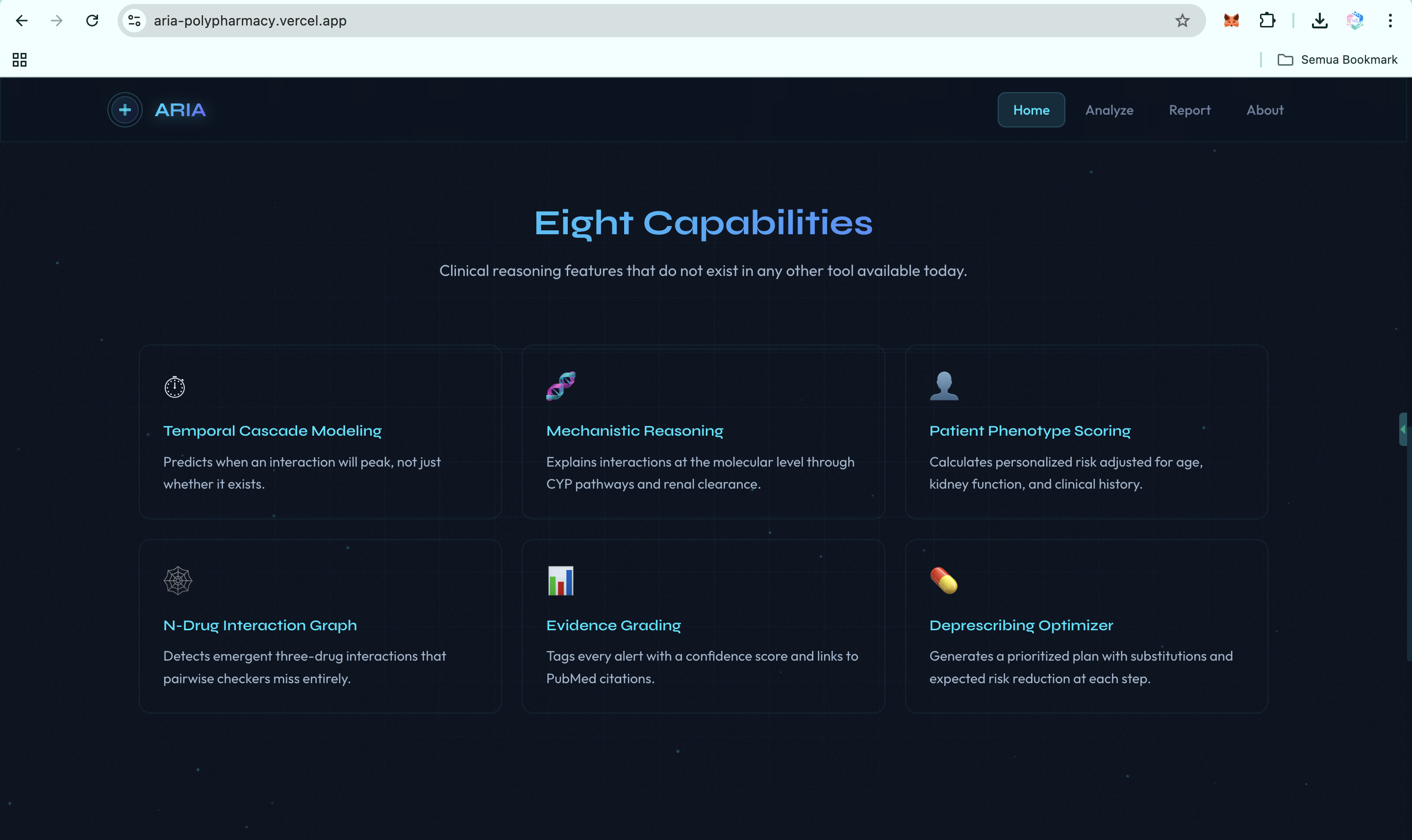
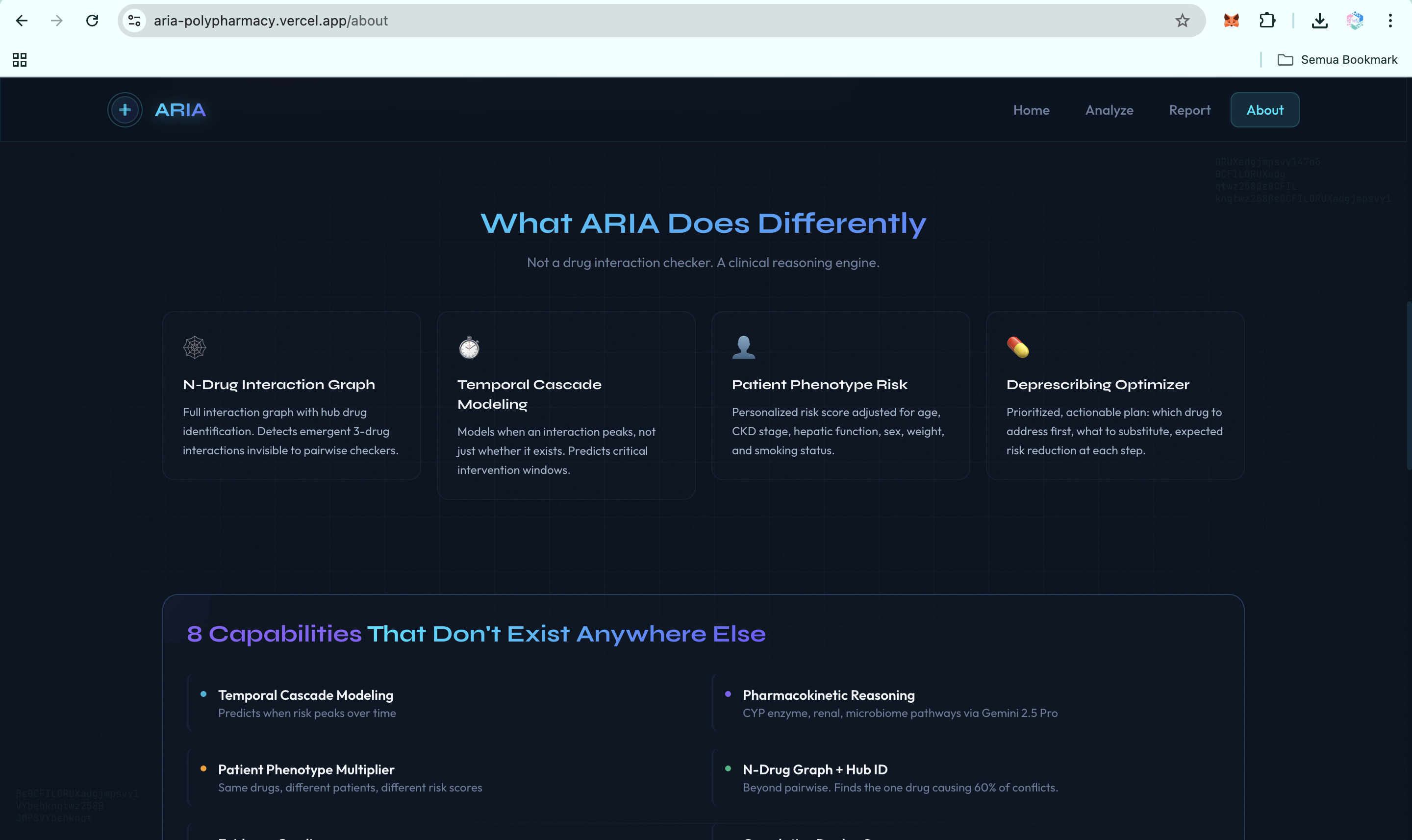
ARIA is a clinical reasoning engine for polypharmacy. It is not just a drug-interaction checker. It is a hybrid AI agent system that takes a medication list and patient context, then produces a structured clinical report with ten capabilities that existing tools do not deliver in one integrated workflow:
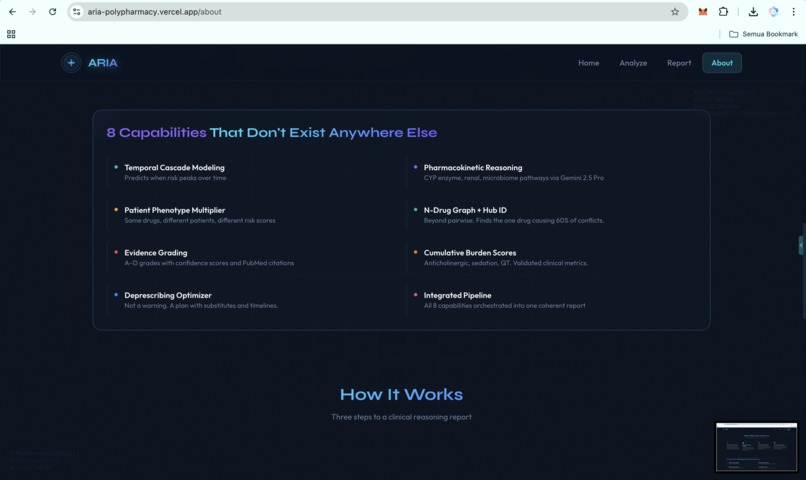
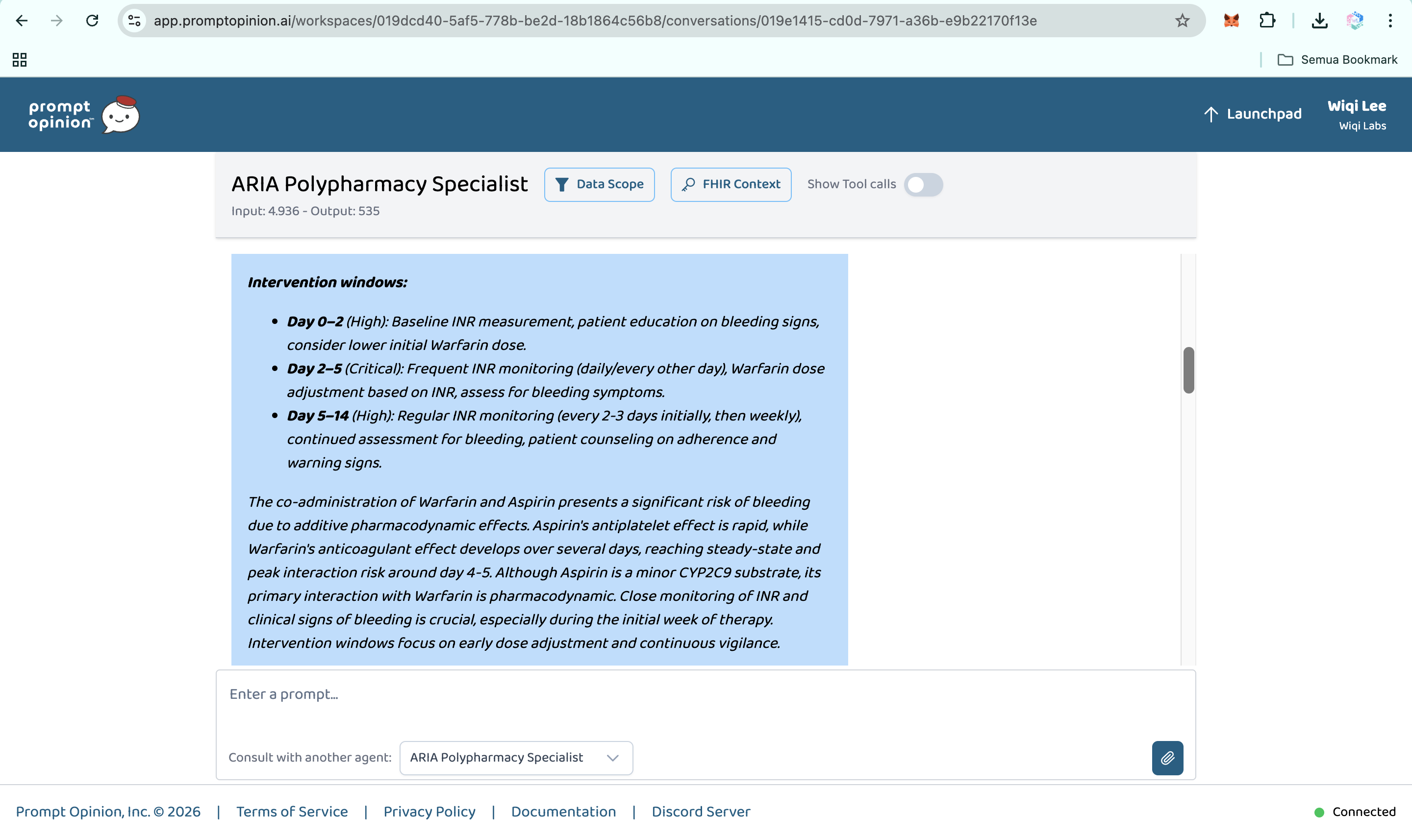
- Temporal cascade modeling. ARIA predicts when an interaction is likely to peak on the clinical timeline, not just whether it exists.
- Pharmacokinetic mechanistic reasoning. ARIA explains why an interaction is dangerous at the molecular level, including CYP competition, renal clearance, protein binding, and gut microbiome effects.
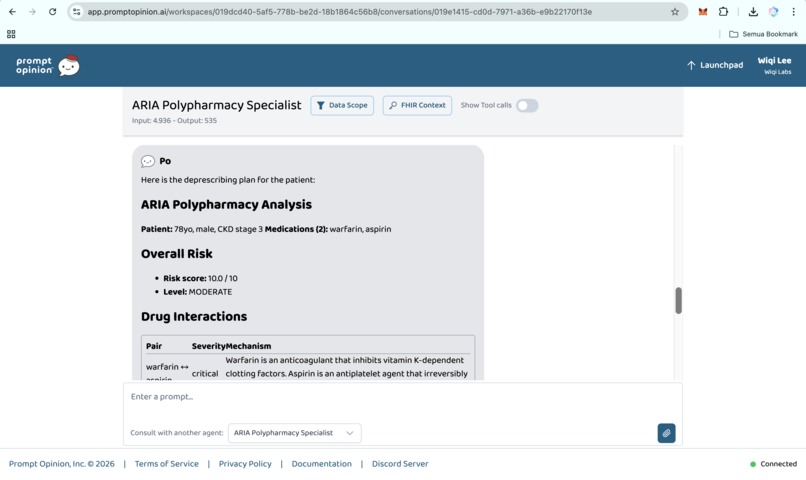
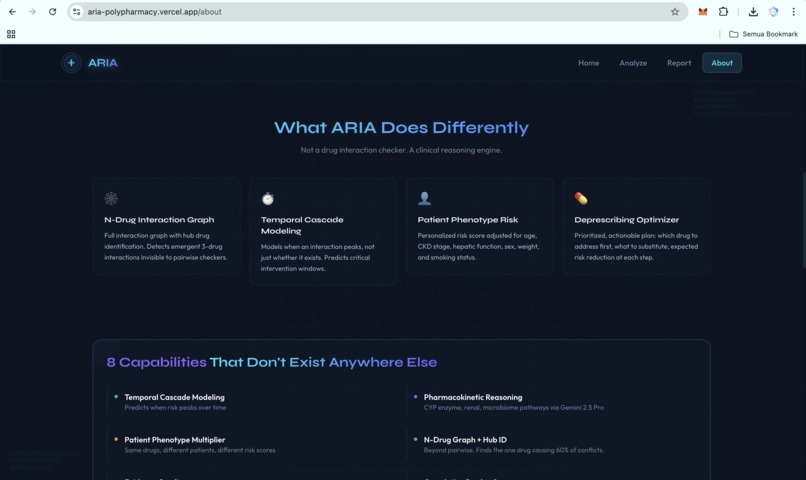
- Patient phenotype risk scoring. The same drug combination may be low risk in a healthy 35-year-old but critical in a 72-year-old with CKD stage 3. ARIA calculates that patient-specific delta.
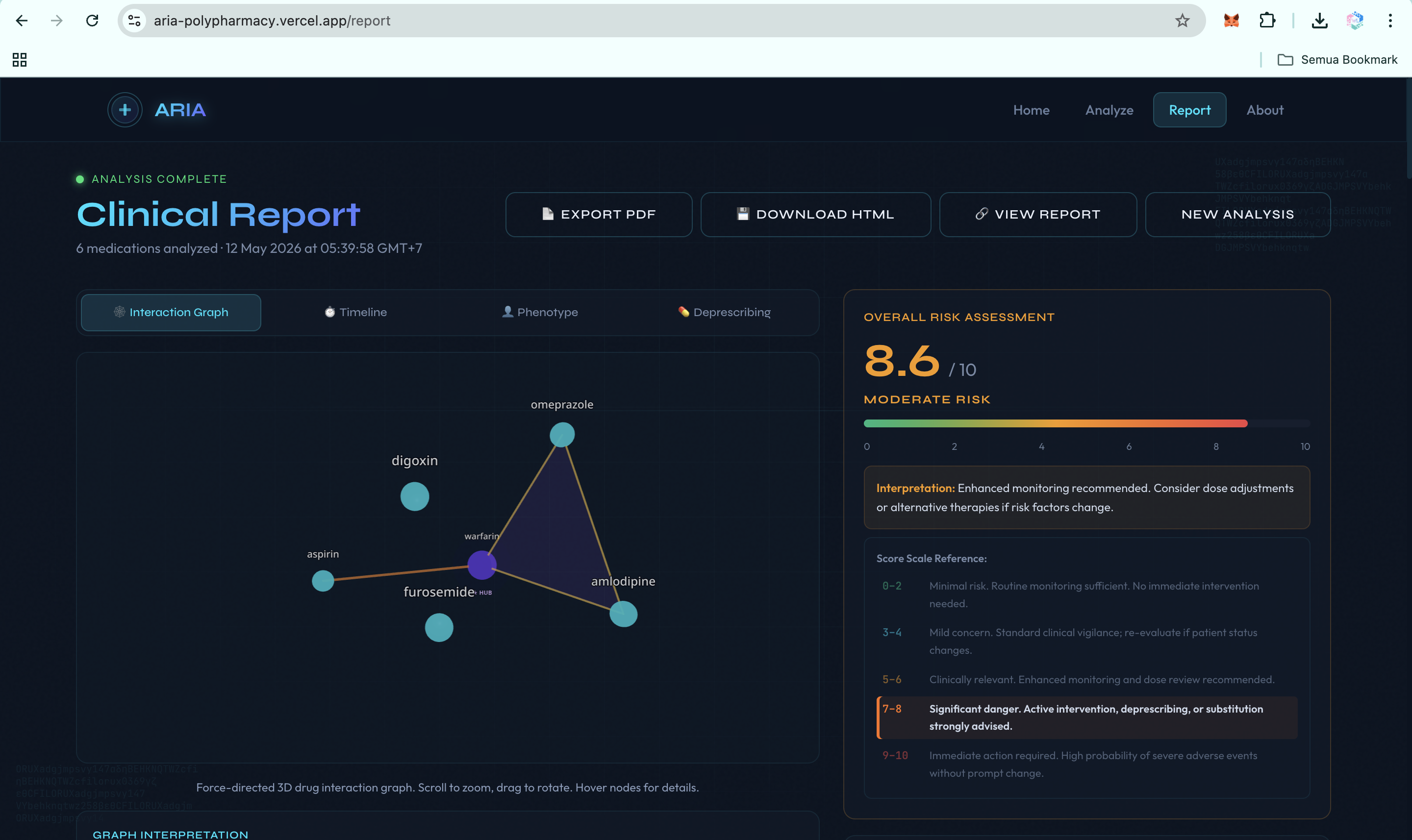
- N-drug interaction graph. ARIA detects emergent three-drug and multi-drug interactions that pairwise checkers miss, then identifies the hub drug causing the largest share of conflicts.
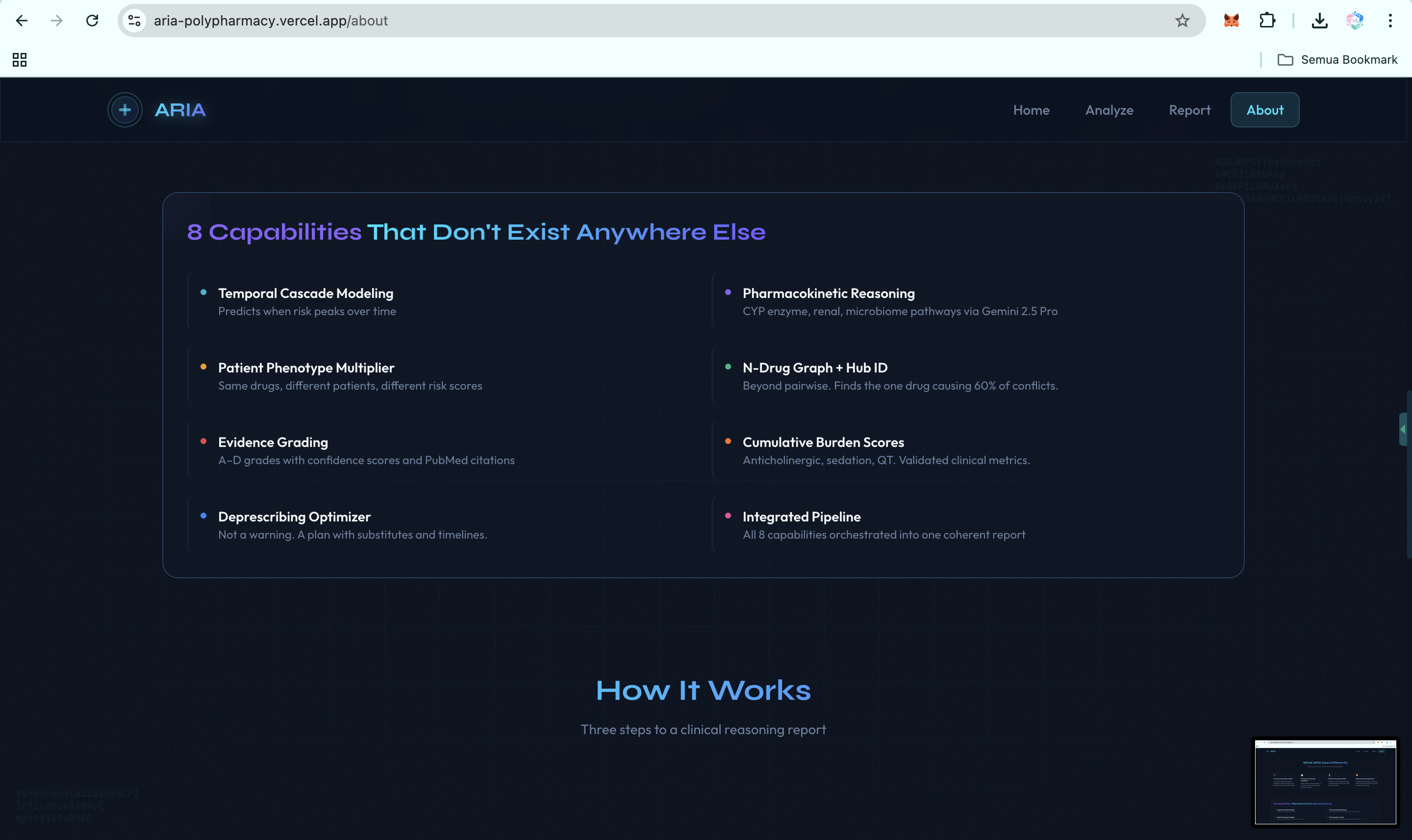
- Evidence grading. Every alert is tagged with an A to D evidence grade, a confidence score, and PubMed-linked citations, so clinicians can triage by evidence quality.
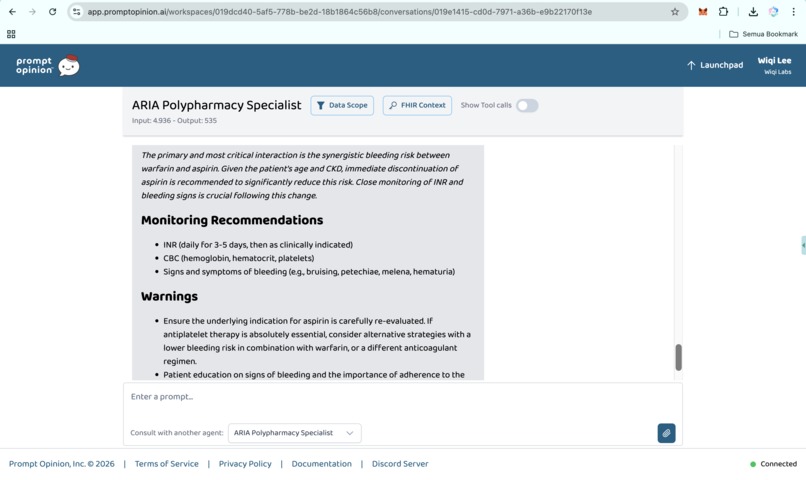
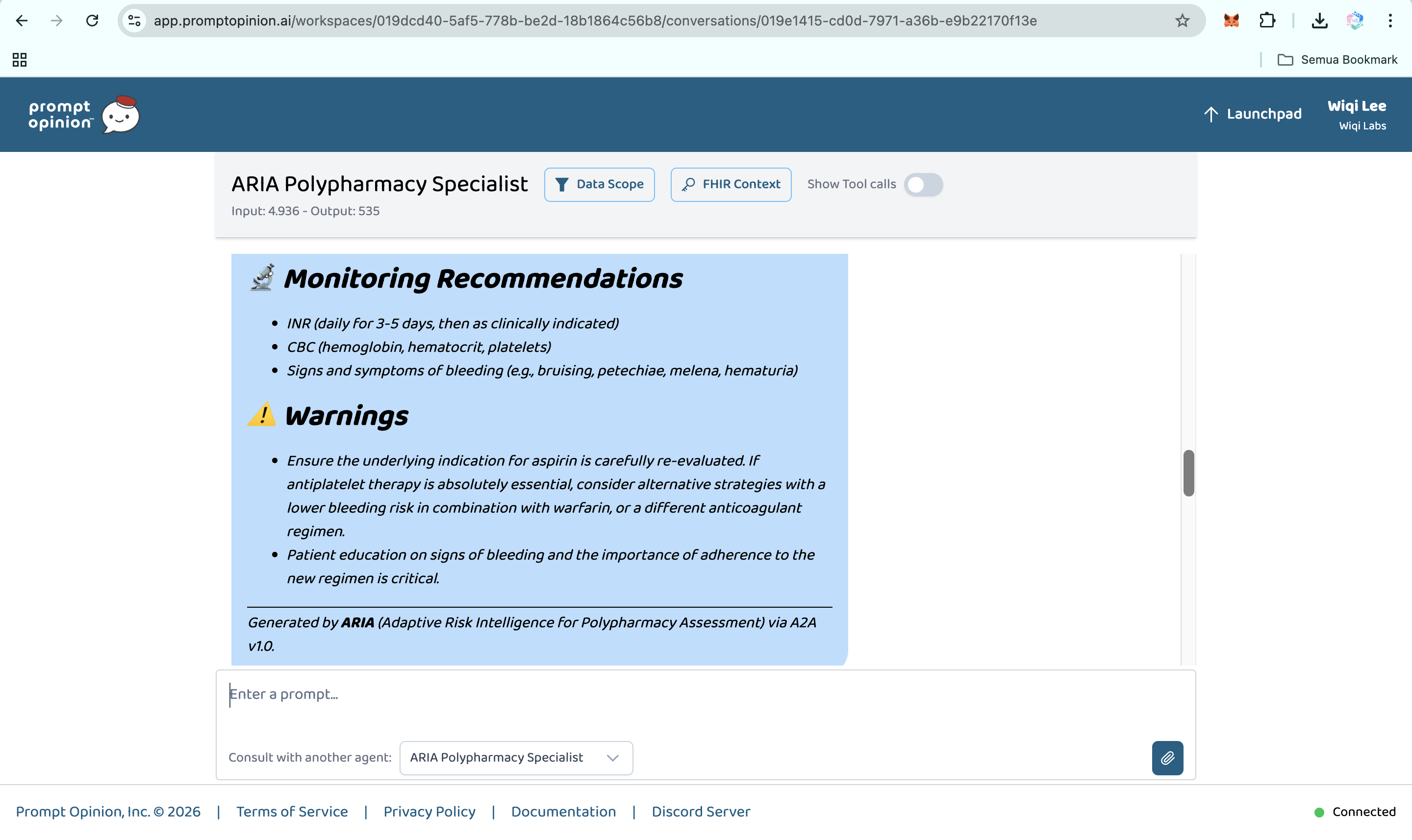
- Cumulative burden scores. ARIA computes anticholinergic burden, sedation load, and QT prolongation risk across the full medication regimen.
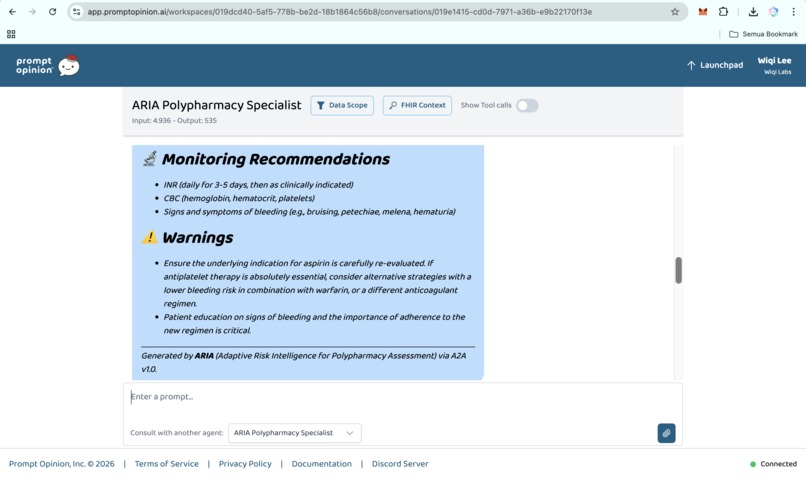
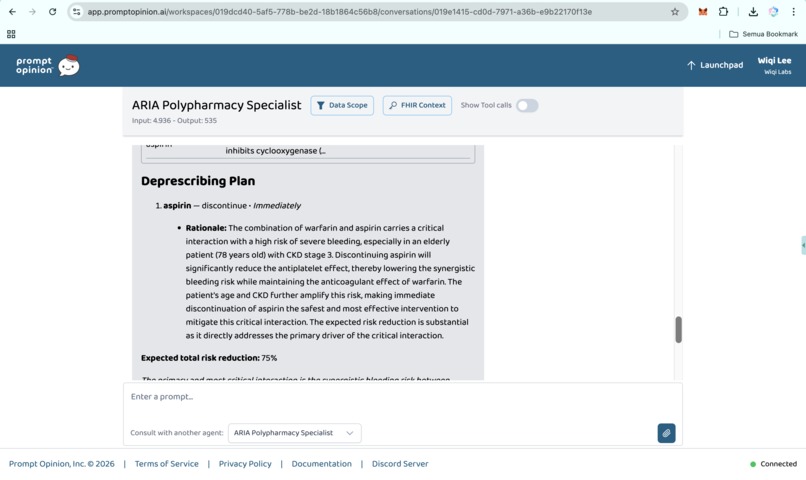
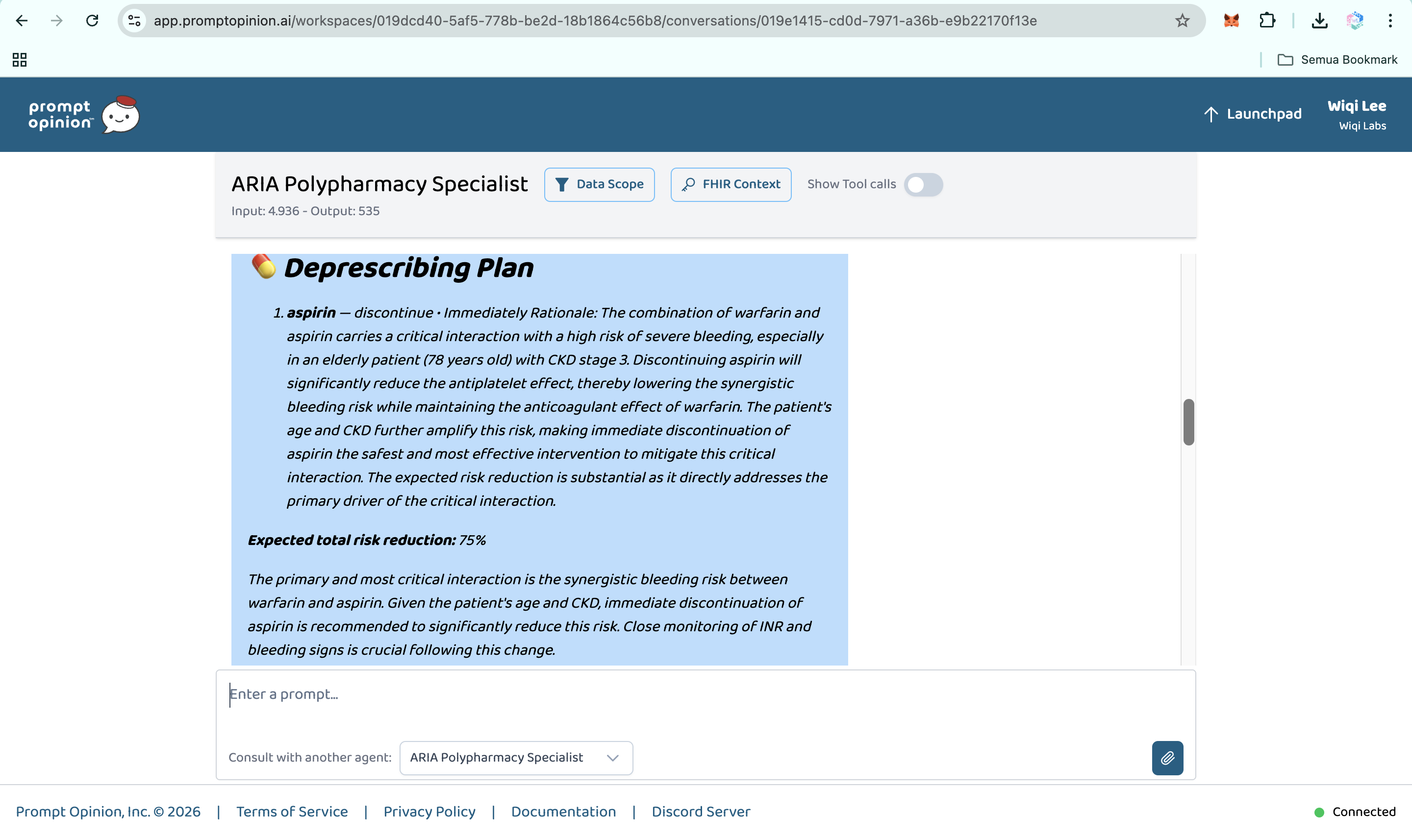
- Deprescribing optimizer. ARIA generates a prioritized plan: which drug to address first, what to substitute, what labs to monitor, and the expected risk reduction at each step.
- End-to-end agent pipeline. All reasoning steps run in one A2A invocation, not as disconnected tools or manual lookups.
- Exportable clinical reports. ARIA produces an interactive 3D web report, a downloadable HTML version, and PDF export, with WIB Jakarta, Indonesia timestamps for Southeast Asian clinical workflows.
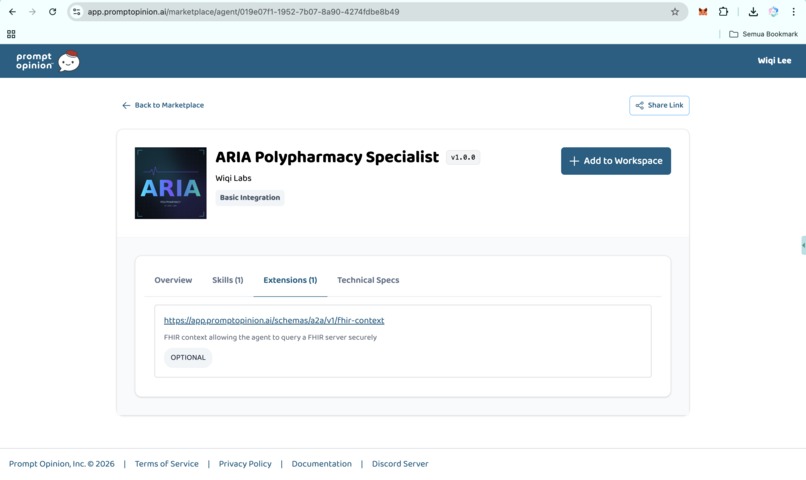
- FHIR-native ingestion via SHARP. ARIA can read active medications directly from any FHIR R4 EHR. Patient context and bearer tokens propagate through SHARP Extension Specs headers when running inside Prompt Opinion, with no manual entry and no per-EHR integration.
Clinicians can use ARIA through the public web app, any A2A v1.0 client, or as a connected agent inside Prompt Opinion's multi-agent platform. All three paths use the same backend reasoning pipeline.
How ARIA is different
Most polypharmacy tools today are static lookup tables. ARIA was designed to do the work the lookup table cannot do.
| Capability | Traditional drug-interaction checker | ARIA |
|---|---|---|
| Detect a pairwise interaction | Yes | Yes |
| Adjust risk for patient phenotype (age, CKD, hepatic) | No | Yes |
| Explain the molecular mechanism in plain language | No | Yes, via Gemini 2.5 Pro |
| Detect emergent N-drug interactions (three or more drugs) | No | Yes, via graph construction |
| Project when the interaction will peak in time | No | Yes, with intervention windows |
| Grade the evidence behind each alert | No | A to D grade with PubMed citations |
| Generate a prioritized deprescribing plan with expected risk reduction | No | Yes, ranked, with monitoring labs |
| Read active medications directly from any FHIR R4 EHR | Limited or vendor-specific | Yes, vendor-neutral, per-request |
| Callable as an A2A v1 agent from other AI orchestrators | No | Yes |
The first six rows are the difference between a checker and a reasoner. The last three are the difference between a demo and a system that can land in a real hospital.
How I built it
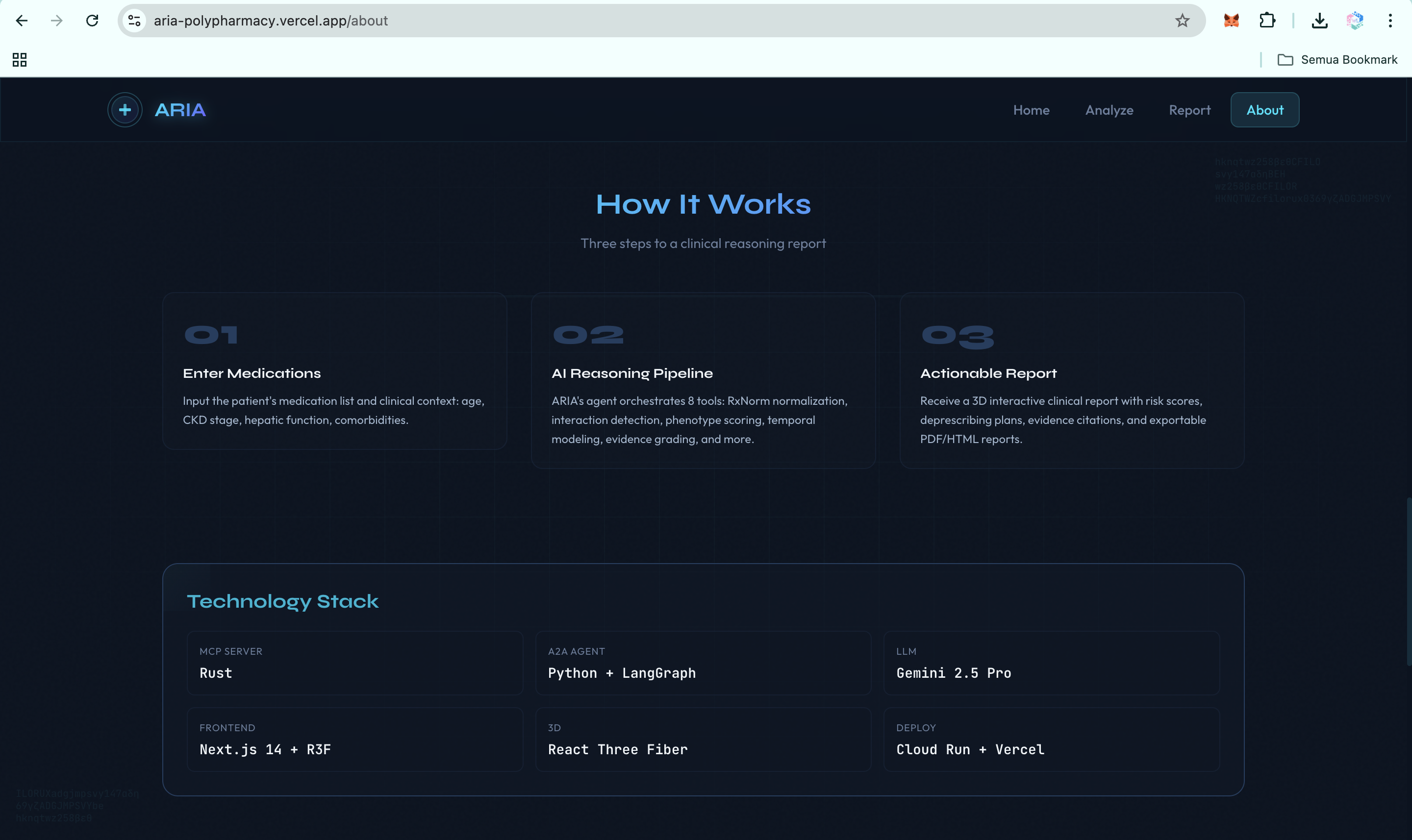
I built ARIA as a polyglot system because each layer has a different job. The architecture splits cleanly into three independently deployable services, with public, sourced data only and zero PHI anywhere in the system.
Three layers, three languages, three reasons
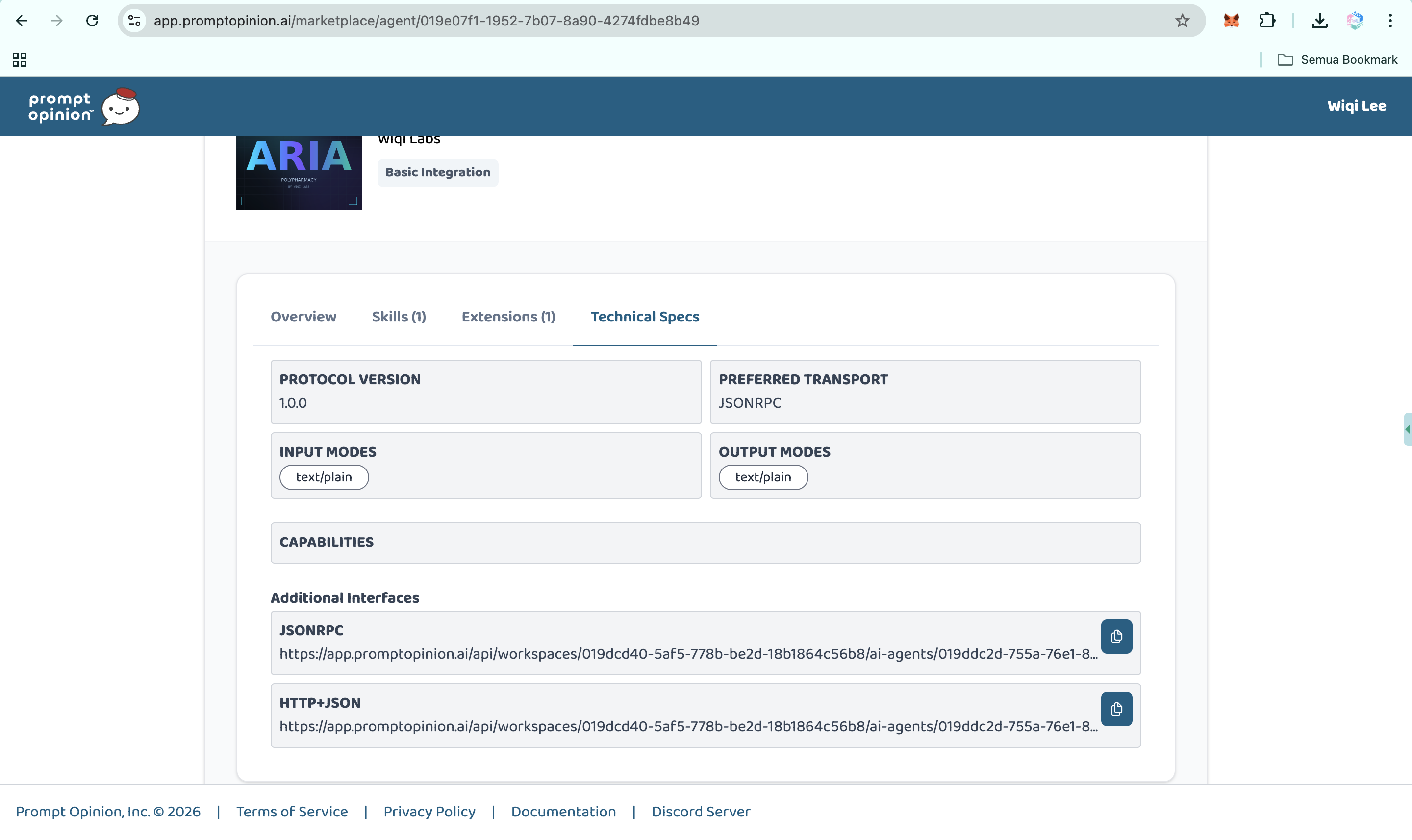
Layer 1: MCP Server in Rust. The Rust backend contains ten specialized clinical tools: check_interactions, explain_mechanism, score_risk, suggest_alternatives, build_interaction_graph, compute_burden_scores, model_temporal_cascade, generate_deprescribing_plan, generate_report, and fhir_patient_medications. The Vertex AI client supports both production GCP IAM authentication and the Google AI Studio API key path for hackathon onboarding.
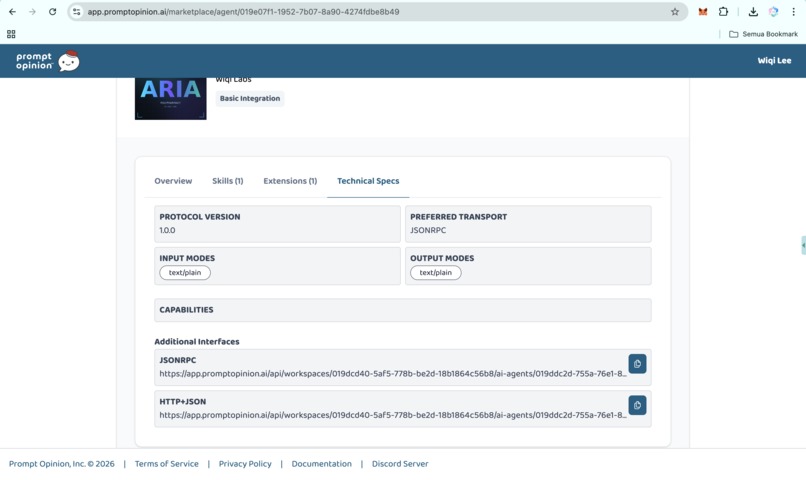
I chose Rust for the clinical reasoning backend for three reasons: predictable tail latency on a Cloud Run cold path, a memory footprint that fits comfortably in 512 MB, and no garbage-collection pauses to slow down concurrent fan-out across ten upstream APIs (OpenFDA, RxNorm, PubMed, DrugBank, Vertex AI, FHIR R4). The MCP server speaks JSON-RPC 2.0 over HTTP and exposes a /health endpoint for Cloud Run probes. It is stateless by design: no database, no on-disk cache, drug safety data is always fresh.
Layer 2: A2A Agent in Python. The orchestration layer is a FastAPI service implementing the A2A v1.0 protocol. A LangGraph workflow sequences the Rust MCP tools into one coherent clinical reasoning pipeline: intake, normalize, graph build, phenotype score, temporal model, evidence grade, deprescribing plan, report assembly. The agent exposes /a2a/v1, publishes a v1-compliant agent card at /.well-known/agent-card.json, and accepts both official method names (message/send, tasks/send) and common client variants (SendMessage, sendMessage) for cross-client compatibility.
SHARP Extension Specs middleware reads X-FHIR-Server-URL, X-FHIR-Access-Token, and X-Patient-ID from inbound requests and forwards them safely to the FHIR tool. That makes ARIA usable against any FHIR R4 endpoint without code changes.
Layer 3: Frontend in Next.js 15. The frontend runs on Vercel and includes a 3D animated landing page, patient input flow, phenotype visualization, temporal risk timeline, interaction graph, deprescribing waterfall, and one-click PDF export. The frontend talks to the same A2A backend that any external agent can call.
LLM layer. ARIA uses Gemini 2.5 Pro on Vertex AI in us-central1. The Rust client supports three authentication paths: GCP metadata server tokens in production, gcloud auth print-access-token for local development, and Google AI Studio API keys for hackathon-style integrations. The reasoning pipeline remains identical across all modes. To stay inside Prompt Opinion's 50-second blocking budget on A2A SendMessage, the agent tiers the model: Gemini 2.5 Flash for the structural and computational tools, Gemini 2.5 Pro for the three highest-stakes clinical reasoning stages (mechanism explanation, deprescribing plan, report generation).
Deployment. GitHub Actions deploys the Rust MCP server and Python A2A agent to Google Cloud Run in asia-southeast2 on every push to main. The frontend deploys automatically to Vercel. Because Cloud Run scales to zero, the full stack costs roughly $0 per month at idle.
Why Path B (A2A Agent), and not Path A (MCP Server) or manual file upload
The hackathon offered two technical paths. The choice mattered.
Why not manual file upload in Prompt Opinion. Manual upload is a UI-level integration. It forces the clinician to leave the orchestrator, format the input by hand, paste it back, and lose the agent-to-agent composition story entirely. Manual upload is for one-shot uploads, not for clinical workflows where an orchestrator agent should be able to delegate a polypharmacy question to a specialist agent and receive a structured answer it can act on.
Why not Path A (MCP Server) alone. An MCP server exposes individual tools. That is the right primitive for a low-level building block, but a polypharmacy analysis is not one tool call. It is ten tool calls sequenced into a clinical reasoning pipeline, with patient phenotype propagating through every stage. Wrapping each MCP tool as a separate Po-native agent would have leaked the orchestration into Prompt Opinion, made the system fragile to refactoring, and lost the structured clinical report.
Why Path B (A2A Agent) is the right primitive. An A2A agent is the orchestration boundary. Other agents call ARIA the way a clinician would: with a medication list and a patient context, and they get back a structured clinical report. The Rust MCP server stays a private implementation detail behind the agent. Other agents in the Prompt Opinion ecosystem never see the MCP server directly. This is exactly the layering A2A v1 was designed for.
Why I built both anyway (the hybrid). I built the Rust MCP server too, even though the marketplace integration is Path B, because the agent had to call something. The MCP server is the substrate; the A2A agent is the orchestrator. Splitting them along that line gave me three properties that mattered: independent deployment and rollback, language choice per layer, and a clean security boundary for the future (the A2A agent will own auth and rate limiting, the MCP server will stay an internal-only data plane). Path B is what Prompt Opinion sees. Path A is what makes Path B clean to operate.
Challenges I ran into
Alert fatigue is a UX problem disguised as a clinical problem. The hardest part was not detecting interactions. The hardest part was presenting them in a way clinicians would not ignore. I rebuilt the report layout four times. The final version separates risk score, mechanism, timeline, and action into distinct visual panes, each with one clear next step.
Cross-client A2A wire-format compatibility. The A2A v1.0 specification adopts ProtoJSON conventions: response objects are wrapped (result.task instead of result.kind = "task"), state enums use SCREAMING_SNAKE_CASE (TASK_STATE_COMPLETED), and parts are flat without a kind discriminator. My initial implementation followed the v0.3 wire format inside v1.0 envelopes, which Prompt Opinion's deserializer correctly rejected with "the external agent did not respond with a task". Ten days of iteration through the a2aproject/a2a-dotnet migration guide led to the fix. The agent now emits proper v1.0 ProtoJSON on the response path and accepts both v0.3 and v1.0 shapes on the request path for backward compatibility.
SHARP propagation across two languages. Passing FHIR context from FastAPI middleware through a JSON-RPC envelope into a Rust MCP tool, while ensuring bearer tokens never appeared in logs, required careful layering: presence-only logging, per-request context, normalized Bearer prefixes, and a fallback ladder so unauthenticated reviewers could still use the public HAPI FHIR sandbox.
3D rendering in a server-component environment. Next.js 15, React Three Fiber, and Vercel required strict client-only isolation with dynamic(..., { ssr: false }) and Suspense fallbacks. The hero animation alone went through eleven iterations before it felt fast, stable, and clinically appropriate.
Latency budgets and model tiering. My first pipeline ran every reasoning step through Gemini 2.5 Pro. A four-drug analysis took 80 to 110 seconds, well outside Prompt Opinion's blocking budget. Switching to a tiered model strategy (Flash for structural tools, Pro for clinical reasoning) brought the same case down to 41 to 49 seconds while preserving the depth of the three highest-stakes stages.
Accomplishments that I'm proud of
- A solo-built polyglot stack that actually ships. I built and deployed Rust, Python, TypeScript, LangGraph, Google Cloud Run, Vercel, and A2A interoperability as one working system.
- Real interoperability. ARIA can be used from a Vercel web app, a raw
curlrequest against the A2A endpoint, or an orchestrator agent inside Prompt Opinion. Same backend, same reasoning, three access paths. - Hard clinical scenarios handled with traceable reasoning. A 72-year-old female patient on warfarin, aspirin, ibuprofen, and atorvastatin produces a 9.6 of 10 CRITICAL score, a five-step deprescribing plan, and PubMed citations on every major interaction.
- Public, sourced data only. ARIA relies on RxNorm, DrugBank open data, OpenFDA, PubMed, and synthetic patient data. No PHI, no proprietary datasets, and no walled-garden APIs.
- Production-grade operations on a hackathon budget. TLS, scale-to-zero, regional deployment, GitHub Actions CI/CD, health probes, structured logging, and vendor-neutral SHARP propagation are all included without dedicated infrastructure vendors.
What I learned
I learned that clinical AI is a calibration problem before it is a model problem. A confident 9.6 of 10 score that is wrong is worse than a cautious 6.2 of 10 score that explains its uncertainty.
I learned that A2A interoperability means being forgiving in what you accept and strict in what you return. Different clients, judges, clinicians, and agents all expect different response shapes, but Markdown turned out to be the most reliable common language.
Most importantly, I learned that separating MCP tools from agent orchestration was the right architectural decision. It allowed me to add new clinical reasoning capabilities without rewriting the agent, and it turned ARIA from a demo into a system that can keep growing.
What's next for ARIA
- EHR pilot deployments in two Southeast Asian hospital networks, starting with geriatrics and deprescribing on admission.
- Streaming A2A responses so Prompt Opinion can show the report progressively as each reasoning step completes.
- Pharmacist-in-the-loop annotation to capture clinician overrides as labeled feedback and close the alert-fatigue loop.
- Expanded SHARP support for multi-tenant deployments where one ARIA instance can serve multiple FHIR endpoints routed by
X-FHIR-Server-URL. - Vernacular patient summaries in Bahasa Indonesia, Vietnamese, and Thai, because many medication-safety failures in LMICs happen at the handover and comprehension layer.
Read the full story
A longer write-up on why I built ARIA, the ten-day A2A v1 wire-format debug, the FHIR integration design, and what I would do differently is on Medium:
ARIA. Adaptive Risk Intelligence for Polypharmacy Assessment. Marketplace, web, raw protocol. One backend. Three surfaces. Polypharmacy is not unsolvable. The tools just have to stop shouting and start reasoning. ARIA is built to do exactly that.
Built With
- a2a
- cloud-run
- docker
- drugbank
- fastapi
- fhir
- fhir-r4
- framer-motion
- gemini-2.5-pro
- github-actions
- google-cloud
- hapi-fhir
- jsonrpc
- langgraph
- mcp
- mermaid
- nextjs
- prompt-opinion
- pubmed
- python
- react-three-fiber
- rust
- rxnorm
- sharp
- smart-on-fhir
- tailwindcss
- three.js
- typescript
- vercel
- vertex-ai









Log in or sign up for Devpost to join the conversation.