-
-
-
-
Onboarding
-
Dashboard
-
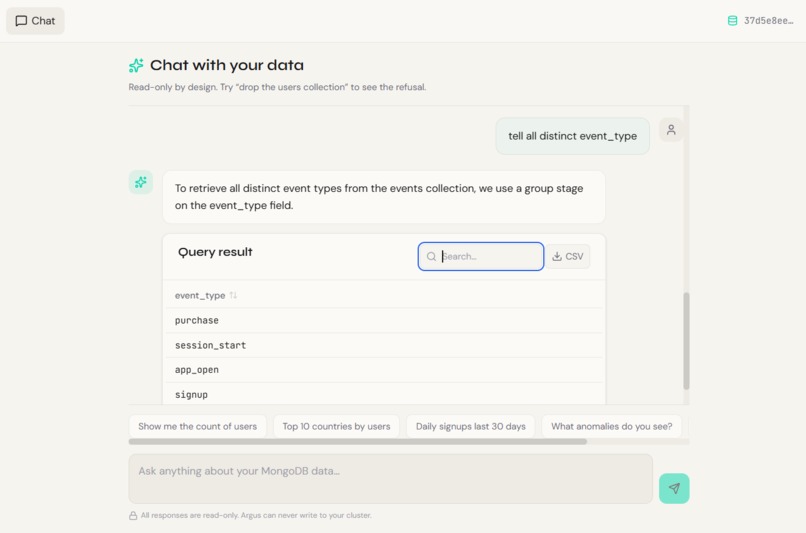
Chat
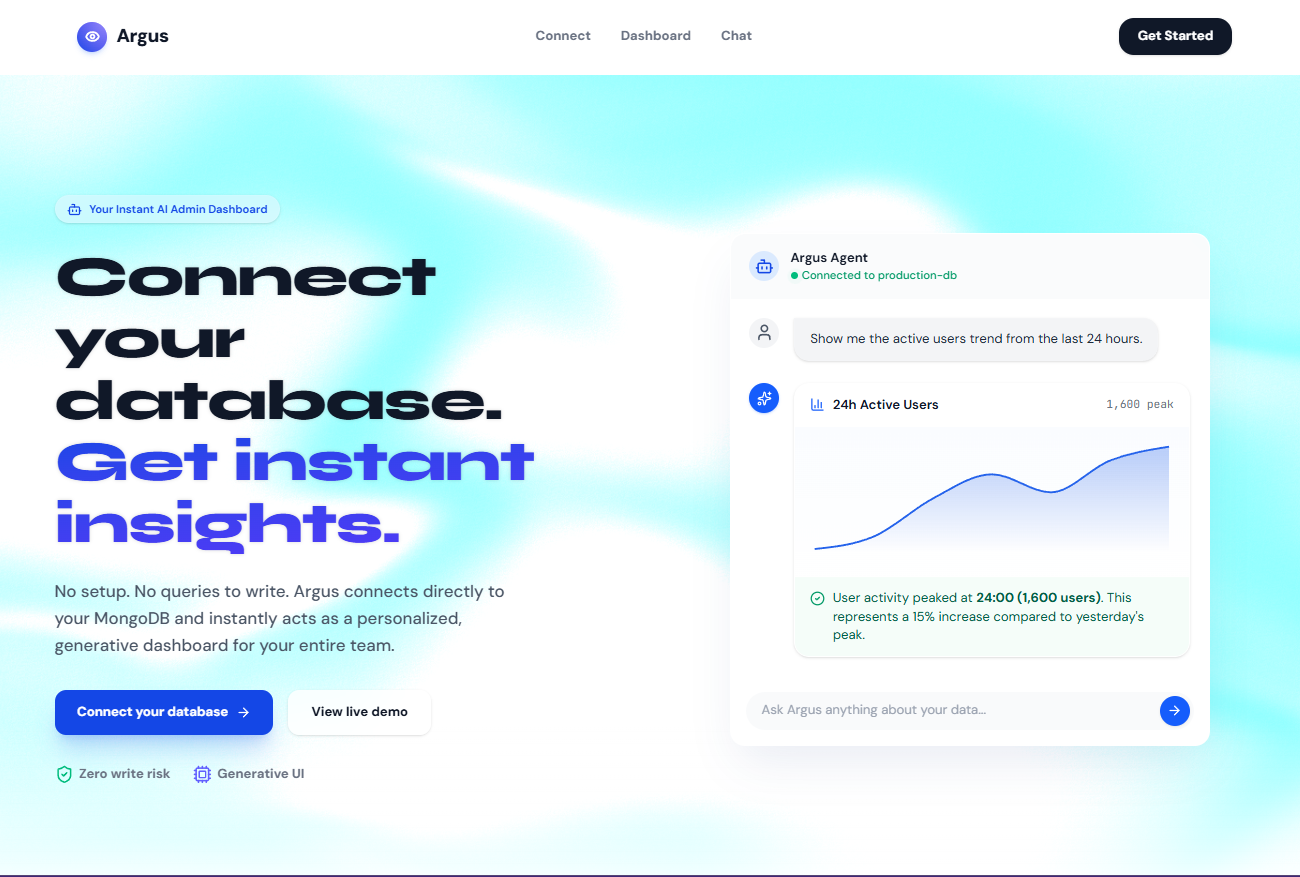
Inspiration
We’ve been manually doing one thing every day for months that should be a product. Working on our previous project, we constantly found ourselves querying our production MongoDB database to answer ad-hoc questions: "Give me stats on new users from the last 15 hours. How many completed story onboarding? What's the warmth distribution for returning users?"
To solve this, we built a static digest endpoint that dropped summaries into Slack. But every new question required editing Python, adding fields to a Pydantic model, modifying the formatter, and redeploying. The insight was hiding right there in our rich MongoDB schema, but the endpoint shape couldn't reach it dynamically.
We realized what we actually wanted didn't exist yet: an agent that reads a MongoDB database, decides what's interesting without being prompted, renders interactive cards we can drill into, and re-runs itself on a schedule. That pain point gave birth to Argus.
What it does
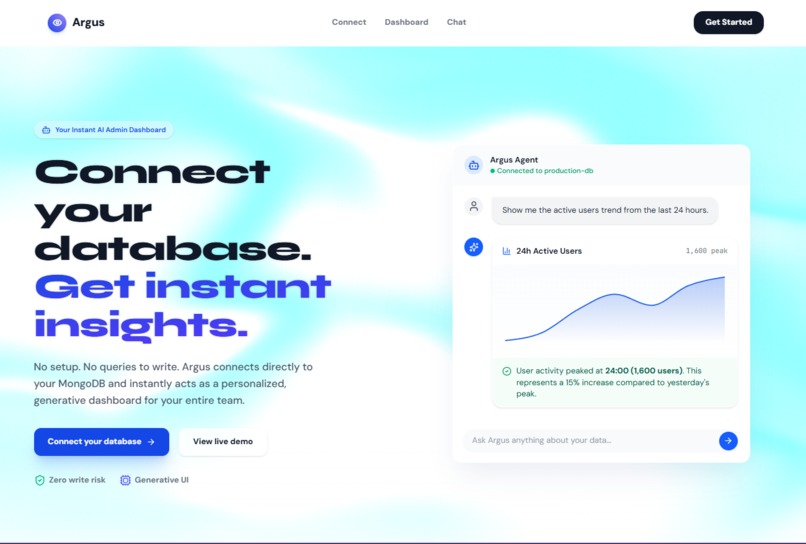
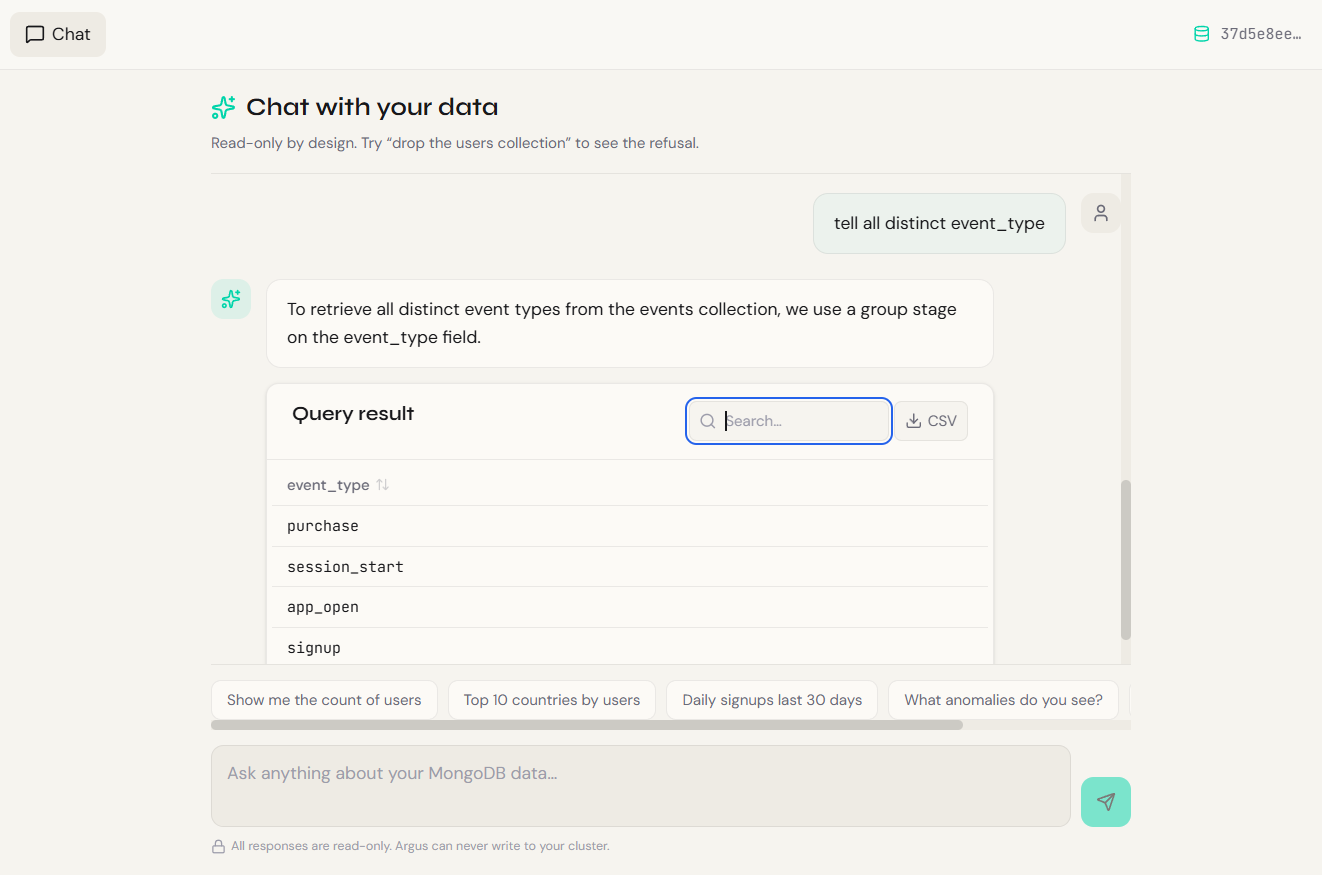
Argus is an agentic analyst for MongoDB Atlas. It turns any MongoDB connection string into an interactive, generative board and a natural-language chat interface.
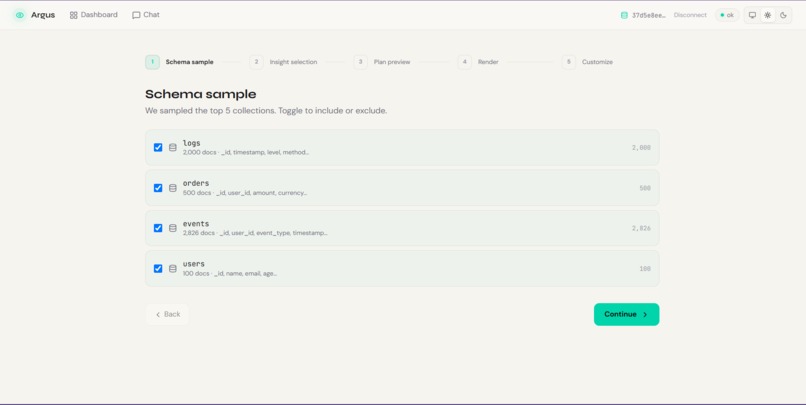
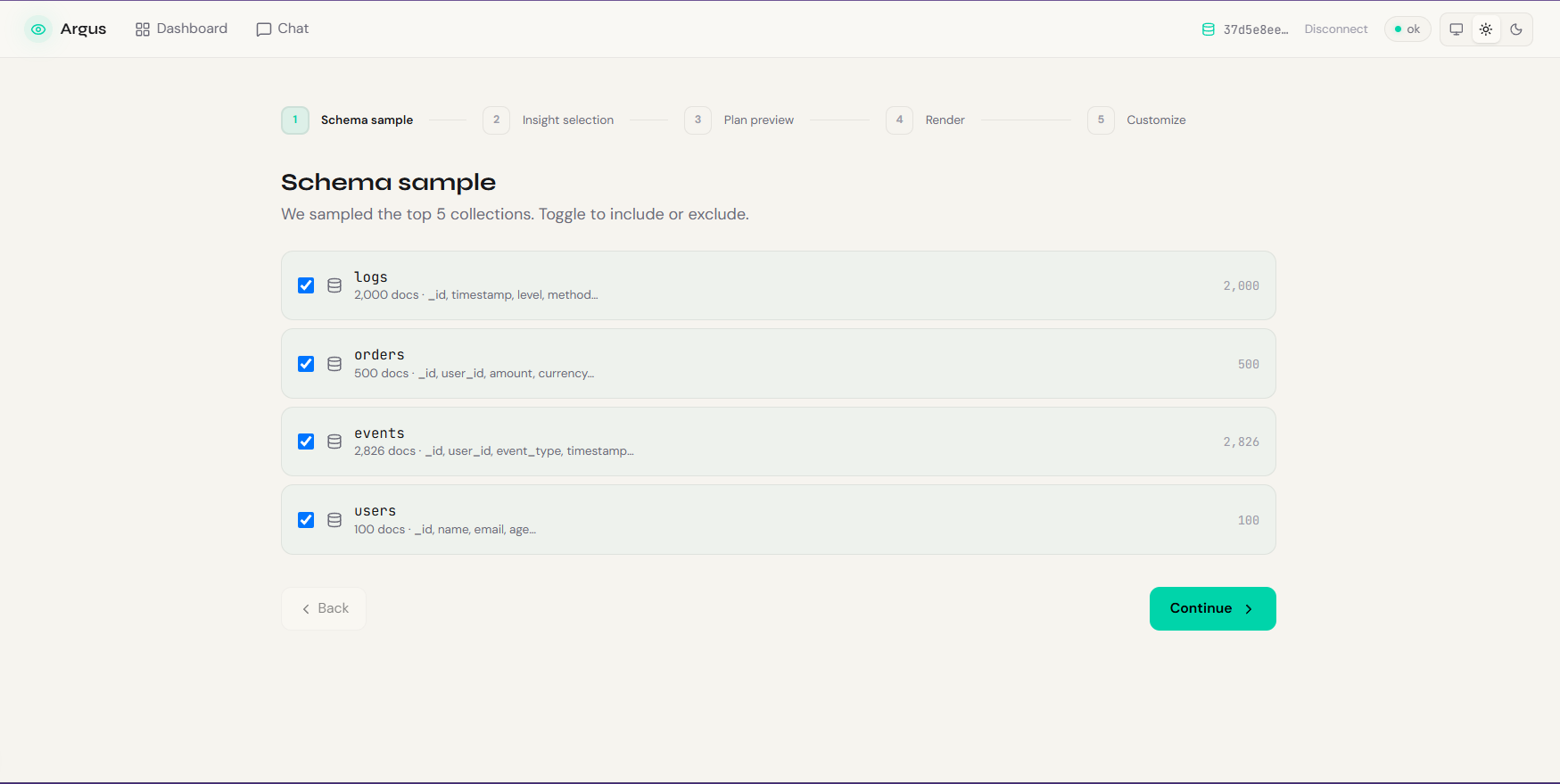
You simply connect your database—even a $\$0$/month free-tier Atlas cluster—and Argus goes to work. The agent samples your schema, probes for hidden fields, and automatically generates candidate insights without needing a predefined event taxonomy or a relational warehouse semantic layer.
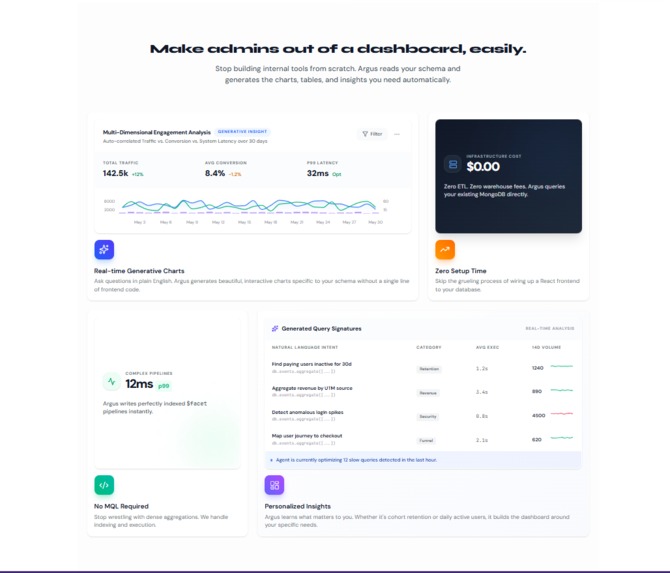
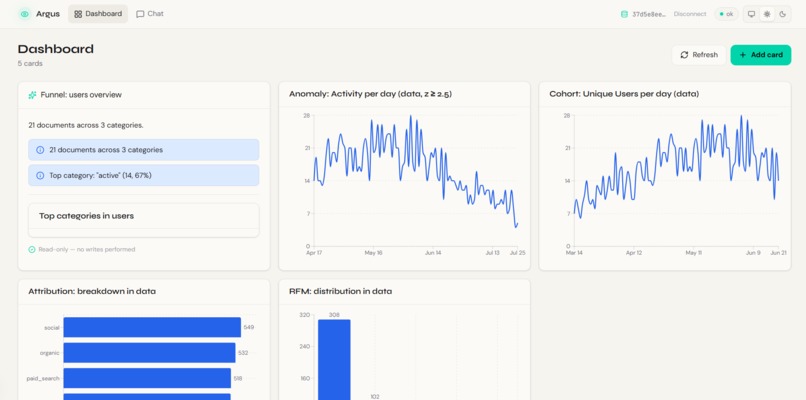
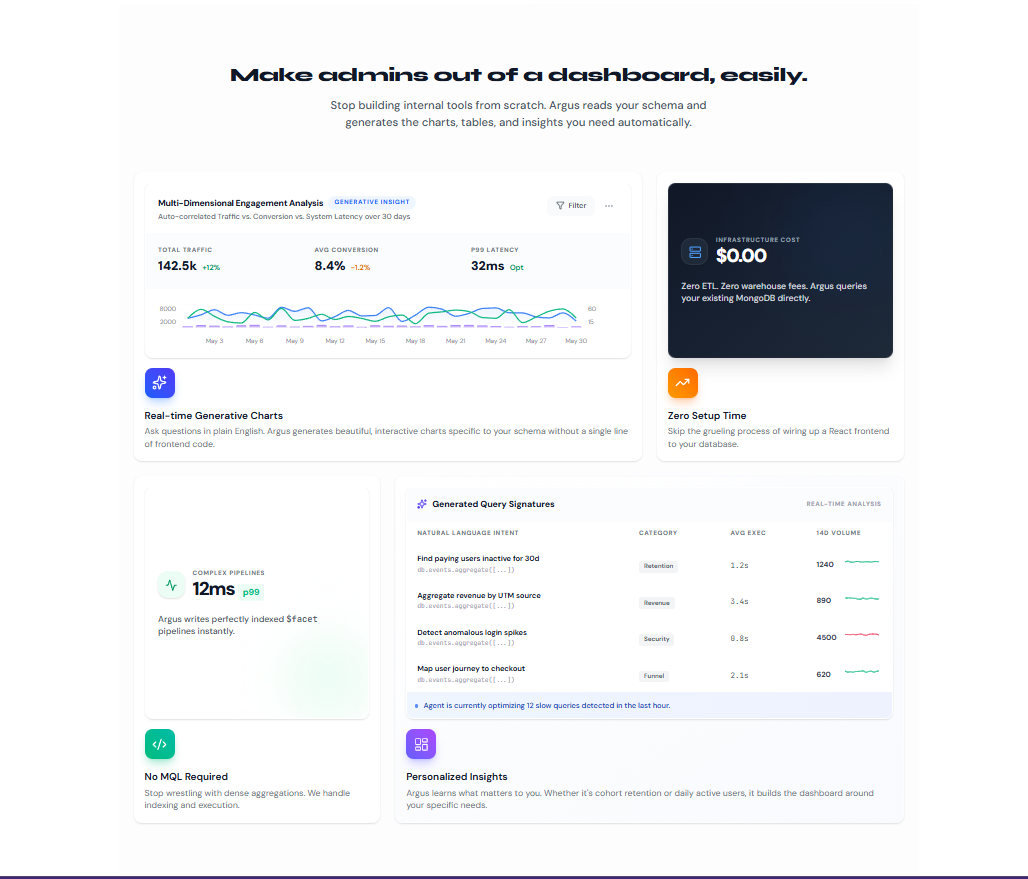
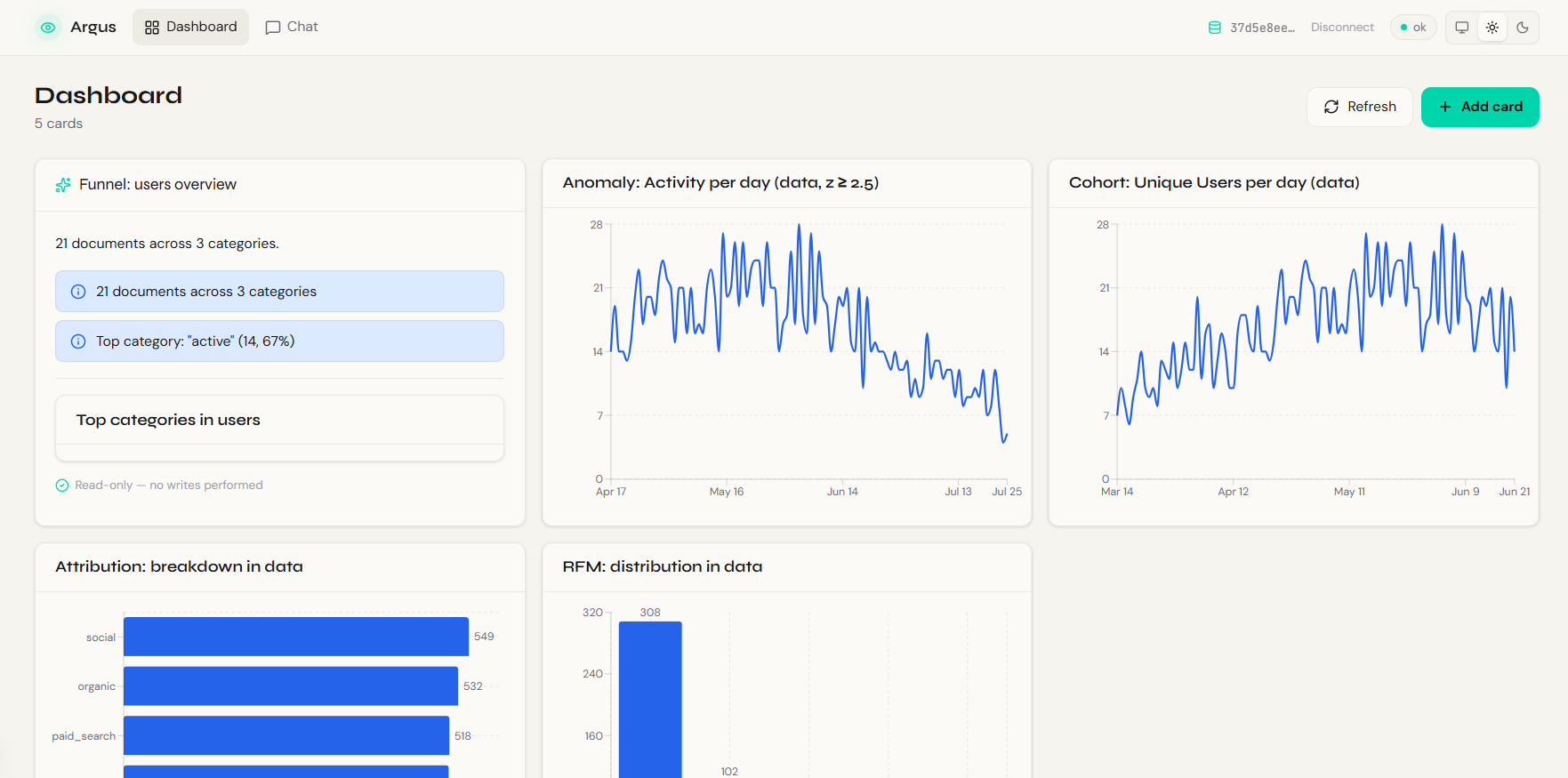
Once initialized, it surfaces its findings through 5 powerful insight modules:
- Funnel: Conversion rates between top events (using
$group,$facet). - Cohort: Weekly retention matrices with cliff detection.
- RFM: Recency-Frequency-Monetary segmentation plotted on a $5 \times 5$ grid.
- Attribution: First-touch attribution mapping.
- Anomaly: Change-point detection using Z-scores ($z = \frac{x - \mu}{\sigma}$) against a trailing 28-day mean.
Instead of returning a wall of text, Argus uses Generative UI to emit Zod-typed component descriptions, instantly building you a beautiful, drillable dashboard of insight cards.
How we built it
We built Argus as a 3-tier architecture designed around the Google Cloud Agent Builder ecosystem and MongoDB:
- Frontend: We used Next.js 15 and React 19, leaning heavily on the Tambo React SDK to power the generative UI cards and interactive boards. Hosted on Vercel.
- Agent Backend: A Python 3.12 FastAPI service hosted on Google Cloud Run. We used the Google ADK (Agent Development Kit), relying on Gemini 3.1 Pro for complex insight planning and Gemini 3 Flash for fast tool-routing loops.
- Database Integration: We integrated the MongoDB MCP server (
mongodb-mcp-server) as a local sidecar via the ADK'sMcpToolset. - State & Memory: While the user's data remains safely in their own cluster, we utilize our own MongoDB Atlas M0 cluster with Atlas Vector Search to memoize inferred schemas, store insight history, and match similar user questions using Gemini embeddings (
gemini-embedding-001).
Challenges we ran into
Schema to Insight Prioritization: When an agent can ask your database anything, how does it know what to prioritize? We had to implement an insight-scoring algorithm similar to MDSF, ranking candidate insights based on an equation of $\text{Score} = \text{Novelty} \times \text{Magnitude} \times \text{UserWeight}$.
Write Protection & Multi-Tenancy: Asking users to paste their connection string is high-stakes. We had to treat this like a banking app. We implemented three strict layers of write protection:
- Spawning a unique MCP subprocess per user request configured with the
--readOnlyflag (which outright removes write tools from the LLM's context). - Enforcing a read-only MongoDB user during the onboarding flow.
- Building a custom
argus-result-set-guardthat intercepts planner logic to explicitly block dangerous aggregation operators like$outand$merge.
The Limits of Schema Inference:
The standard MCP server samples $\sim 100$ documents to infer schema. In rich collections, a $100$-doc sample has a high probability of missing critical but rare fields (like subscription.canceled_at). We had to teach our agent to not just trust the initial sample, but to actively probe the database with targeted {$exists: true} aggregations to map out the actual shape of the data.
Accomplishments that we're proud of
- Truly Schema-Blind Auto-Insights: Argus doesn’t require a meticulously instrumented product taxonomy. It looks at your raw BSON documents and figures out what matters.
- Generative UI Paradigm: Escaping the "chatbot text wall." Watching the agent dynamically construct custom Next.js components on the fly feels like magic and makes the data instantly actionable.
- Zero-Compromise Security: Proving that we can run an agent against production user databases safely, efficiently, and effectively on a free tier.
What we learned
- MCP is a superpower: The Model Context Protocol, combined with the Google ADK, drastically reduced the plumbing we had to build. It allowed us to focus all our energy on the UX and insight logic.
- Generative UI is the future of data tools: Giving the LLM control over the UI components (rather than trying to shoehorn LLM outputs into fixed templates) is the only way to handle the infinite variability of raw database schemas.
- Complex MQL takes guardrails: Generating complex MongoDB Aggregation Pipelines (involving
$bucket,$densify, and$setWindowFields) requires careful agentic planning, multi-step validation, and an iterative error-correction loop.
What's next for Argus: The Agentic Analyst for MongoDB Atlas
Our V2 roadmap is focused on making Argus even more proactive:
- Advanced Attribution: Upgrading our attribution module to use Markov chains and Shapley value-based models to better evaluate multi-touch user journeys.
- Real-Time Signals: Moving beyond polled MCP queries by integrating MongoDB Atlas Stream Processing and change streams natively. We want Argus to surface real-time behavioral signal cards (like
high-intentorexit-risk) the second the data changes. - Memorystore Integration: Adding Memorystore for Redis for ultra-fast session state management.
- Expanded Gen-UI Catalog: Adding support for multi-dimensional data storytelling and complex nested visualizations.
Built With
- docker
- gemini
- google-cloud
- google-cloud-agent-builder
- google-cloud-scheduler
- mcp
- mongodb
- mongodb-atlas
- pydantic
- python
- react
- recharts
- tambo-sdk
- typescript
- vercel
Log in or sign up for Devpost to join the conversation.