-
-

-
Notification pop pup
-
extension

Argus - It Never Forgets
Inspiration
We all have a Context Grave.
It's the place where important details go to die - buried under thousands of WhatsApp messages we send every week. A friend recommends a specific shop in Goa. Your sister mentions the sneakers she's been obsessing over. You make a mental note to cancel a subscription. And then the moment arrives - you're booking that flight, browsing that store, opening Netflix - and it's gone. The context is gone.
The problem isn't memory. It's retrieval at the right moment.
Every existing solution puts the burden on the user: set a reminder, write a note, tag the message. But the whole point is that you've already forgotten. You can't search for something you don't remember exists.
We wanted to build something that closed this gap without any manual input - an agent that watches what you're doing right now and connects it to what you said back then.
What it does
Argus is a proactive memory assistant that connects your WhatsApp conversation history to your live browser activity - surfacing relevant context exactly when you need it, without you asking.
When a WhatsApp message arrives, Argus automatically extracts structured events, tasks, reminders, and recommendations from it. These are stored locally in a SQLite database and indexed for fast search. Then, as you browse:
- Open a travel site? Argus checks if you discussed that destination and surfaces the recommendation from three months ago.
- Filling out an insurance form? Argus detects if the form data conflicts with something you said in chat - and offers to fix it.
- Land on Netflix? If you mentioned wanting to cancel, Argus reminds you the moment you're there.
- Ask the AI sidebar anything? A DigitalOcean Gradient ADK agent reasons over your memory vault using a multi-step tool-calling loop and returns a grounded answer.
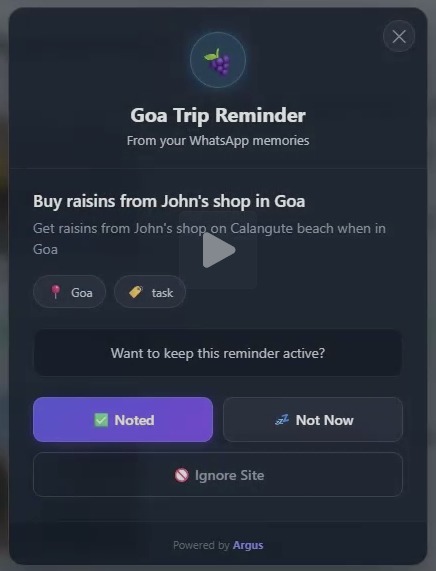
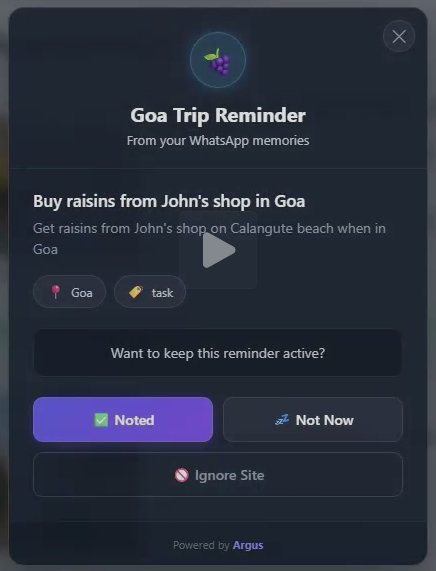
Everything runs through 8 popup types: event discovery, time-based reminders (24h/1h/15min), context reminders, conflict warnings, insight cards, snooze reminders, update confirmations, and form mismatch alerts. The AI suggests. The user remains sovereign.
How we built it
Argus is a full-stack application with four distinct layers, all built around DigitalOcean Gradient AI.
1. DigitalOcean Gradient Serverless Inference - Llama 3.3 70B
Every AI function in Argus runs through gradient.ts, which calls llama3.3-70b-instruct via Gradient's OpenAI-compatible endpoint (https://inference.do-ai.run/v1). This handles:
- Event extraction - structured JSON from raw WhatsApp messages in under 500ms
- Popup blueprint generation - crafting the exact card shown to the user including icon, body, sender attribution, and action buttons
- Relevance validation - confirming a URL actually warrants surfacing a stored event before interrupting the user
- Chat fallback - direct Llama responses when the ADK agent is unavailable
We built a custom repairJSON() function to handle Llama's tendency to wrap JSON in prose or markdown fences, with a 4-step extraction chain: direct parse → markdown fence extraction → block scanning by expected key → brace-closing repair on truncated output.
2. DigitalOcean Gradient ADK - LangGraph Agent
The AI Chat sidebar routes to a Python LangGraph agent deployed on DigitalOcean's Gradient Agent Development Kit. The agent has two tools that call back into Argus through a secured internal API:
search_events(query)- FTS5 full-text search over stored eventsget_event(id)- fetch a specific event record by ID
The agent chains these tools iteratively before synthesising a response. Unlike a single-shot prompt, it can narrow results, follow up on specific events, and reason across multiple memory items. Deployed with gradient agent deploy to agents.do-ai.run.
3. SQLite + FTS5
All events, messages, triggers, contacts, and dismissals are stored in a local SQLite database using better-sqlite3. The events table has an FTS5 virtual shadow table with porter unicode61 tokenization across title, keywords, and description. Context checks resolve in under 50ms - no round trip to any external service.
4. Chrome Extension + Evolution API
A Manifest V3 Chrome extension monitors every URL change and DOM form field. Evolution API (Baileys) bridges WhatsApp Web and forwards messages as webhooks to the Argus Express server. The full pipeline - WhatsApp message arrives, Llama extracts the event, SQLite stores it, the extension detects a matching URL, and the popup fires - runs in under 800ms end to end.
A 3-tier AI fallback system (ai-tier.ts) ensures zero downtime: if Gradient is unavailable, Argus downgrades to regex heuristics, then to an LRU response cache. The user never sees a crash.
Challenges we ran into
Llama doesn't respect response_format: json_object. Unlike GPT models, Llama 3.3 70B frequently wraps JSON in prose, adds explanatory text before or after, or returns markdown-fenced code blocks. We had to build a multi-stage JSON repair pipeline that scans every { } block in the response and selects the one containing the expected schema key. This took longer to get right than the entire initial integration.
The ADK requires Python 3.13 exactly. Not 3.12. Not 3.11. This wasn't obvious from the docs until deployment failed. Once we hit the right version, the gradient agent deploy flow was genuinely smooth - but that debugging cost us a few hours mid-sprint.
Migrating from Elasticsearch to SQLite mid-project. The original Argus used Elasticsearch Serverless with 768-dim vector embeddings. Moving to SQLite meant rethinking the entire search architecture. The solution - FTS5 keyword search feeding a Llama re-ranking pass - ended up being faster and more reliable than the original kNN pipeline. But it required rewriting elastic.ts entirely into a new db.ts, redesigning the schema to use SQLite AUTOINCREMENT instead of Elasticsearch's in-memory counters, and validating that FTS5's BM25 ranking was sufficient for Argus's short-text use case (it is).
Keeping the Chrome extension zero-touch. The extension must not require the user to click anything. The context-check has to fire, retrieve relevant events, rank them, and decide whether to show a popup - all in the background, fast enough that the popup appears before the user has finished reading the page. Getting the timing right required careful tuning of the FTS5 query sanitization and the Llama re-ranking prompt.
Accomplishments that we're proud of
The form mismatch detector. When a user fills in "2022 Honda" on an insurance form but their WhatsApp chats say they own a 2018 - Argus catches it, shows a "Hold on" popup, and offers a one-tap auto-fill fix. This feature alone has real financial impact for users. It works purely from conversation history, with no structured data input.
Zero-downtime AI via 3-tier fallback. The withFallback() wrapper in ai-tier.ts means Argus keeps working even when Gradient is rate-limited or unreachable. Tier 1 → Llama. Tier 2 → regex heuristics. Tier 3 → LRU cache. The user never sees a failure - just a slightly less intelligent response.
Sub-50ms context checks. SQLite FTS5 with porter unicode61 tokenization resolves context-check queries faster than any cloud database could. The entire pipeline from URL change to popup render runs in under 800ms on a local machine.
Clean DigitalOcean Gradient integration. Two distinct Gradient products - Serverless Inference for real-time extraction and the ADK for the agentic chat layer - with a shared authentication model and single-provider billing. The architecture feels like what Gradient was designed for.
The deadline popup. We built the final demo moment - Argus popping up with "Submission deadline: 10 minutes remaining" - using Argus's own event system. It reminded us of its own demo deadline. That felt right.
What we learned
Agentic tool-calling is qualitatively different from prompt stuffing. The Gradient ADK agent doesn't just answer from a fixed snapshot of events embedded in a prompt. It decides what to search, calls the tool, reads the result, decides if it needs more, and iterates. Watching it chain three tool calls to answer "What did Rahul say about Goa?" - narrowing from 20 results to 1 specific event - was the moment the architecture clicked. That's not retrieval. That's reasoning.
Reliability engineering is the real AI engineering. Llama going down at 2am during a hackathon sprint is not a hypothetical. The fallback tier system wasn't a nice-to-have - it was what kept the project testable during outages. Production AI isn't about the model. It's about what happens when the model fails.
SQLite is underrated for AI applications. We expected to miss Elasticsearch. We didn't. FTS5 with BM25 ranking and a Llama re-ranking pass on the top-20 candidates gives results that are indistinguishable from the old kNN pipeline for our use case - and with zero infrastructure, zero latency, and zero embedding cost.
Context, not content, is the hard problem. WhatsApp messages are messy, conversational, multilingual, and full of noise. Extracting structured events from them with high precision - low false positives especially, because a bad popup is worse than no popup - required careful prompt engineering and calibrating the confidence threshold. Getting the AI to stay quiet when uncertain was harder than getting it to speak when confident.
What's next for Argus - It never forgets
Multi-platform memory. WhatsApp is the starting point, but the Context Grave exists across platforms. Telegram, iMessage, email threads, Slack - every channel where people make commitments they later forget. Argus's pipeline is message-source-agnostic. Expanding to new sources is a data connector, not an architectural change.
Vision-based context detection. Right now, Argus reads URLs and form field values. The next step is reading the screen - using multimodal inference to detect visual context (a product image, a menu, a booking form) and cross-reference it against conversation memory. DigitalOcean's GPU Droplets make local multimodal inference viable without cloud API costs.
Collaborative memory. Shared events across a household or team - where a commitment one person made shows up for the person who needs to act on it. The data model already supports sender_name attribution; routing shared context is the next feature.
Privacy-preserving on-device mode. Everything in Argus already runs locally - the SQLite database, the Chrome extension, the Node.js server. The only external calls are to Gradient Inference. A fully on-device mode, using a smaller model on a local GPU Droplet or even the user's machine, is achievable without a complete rewrite.
The goal is simple: a world where no one ever has to say "I forgot you mentioned that."
Built With
- digitalocean
- gradient-ai
- typescript

Log in or sign up for Devpost to join the conversation.