-
-
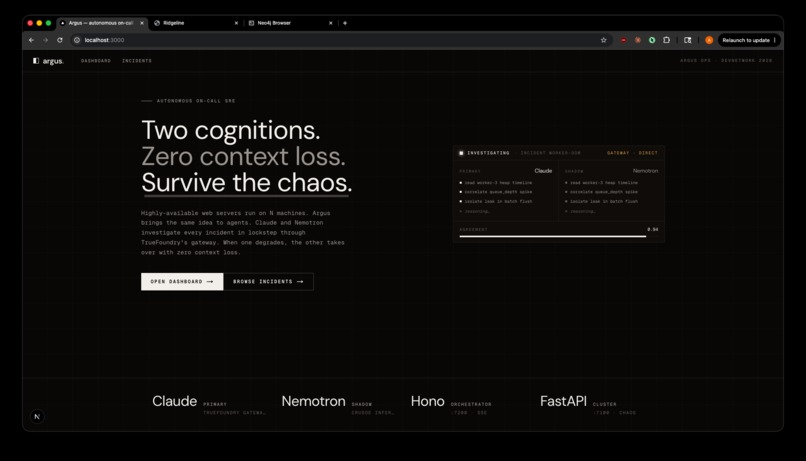
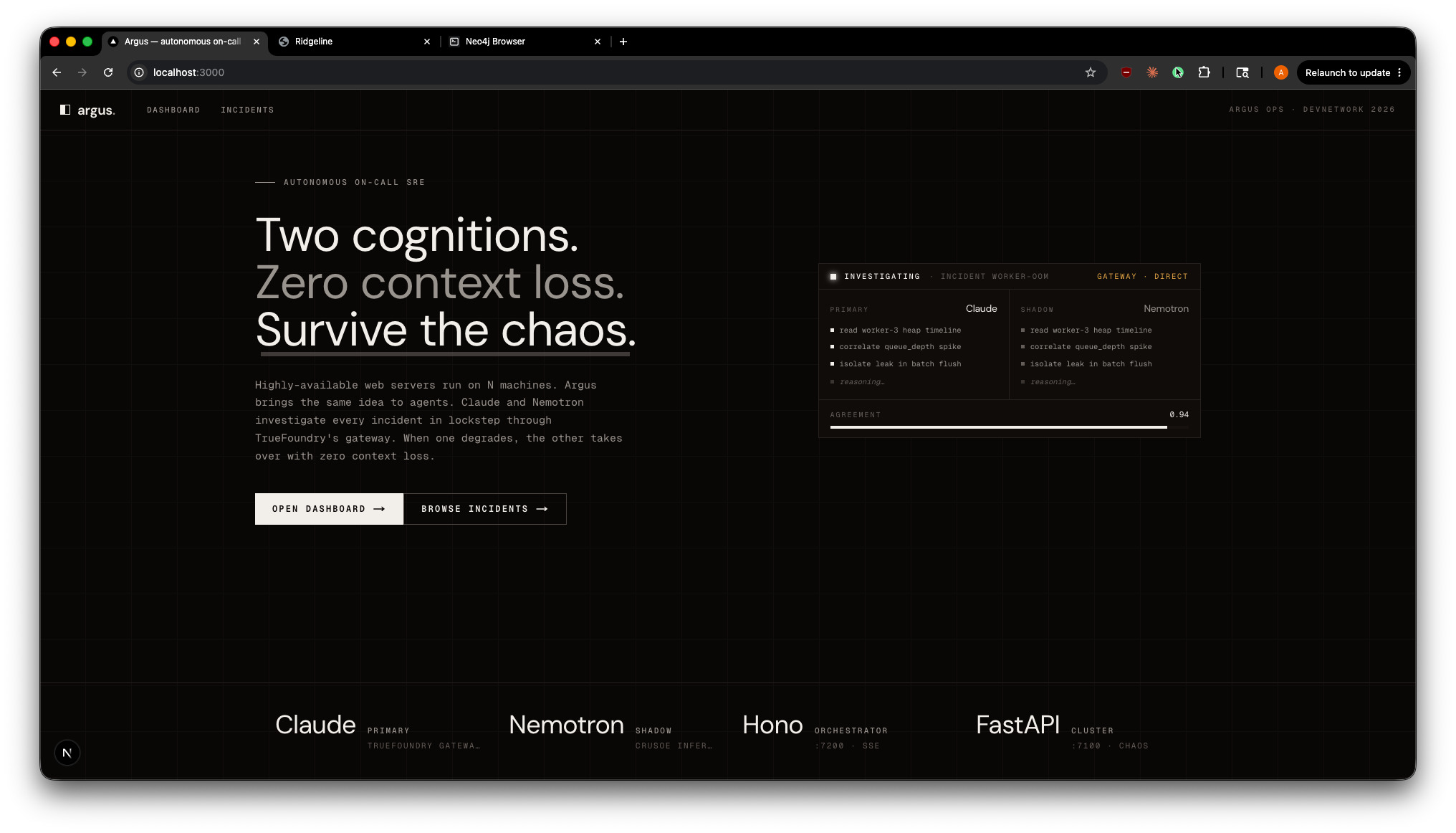
Argus Landing
-
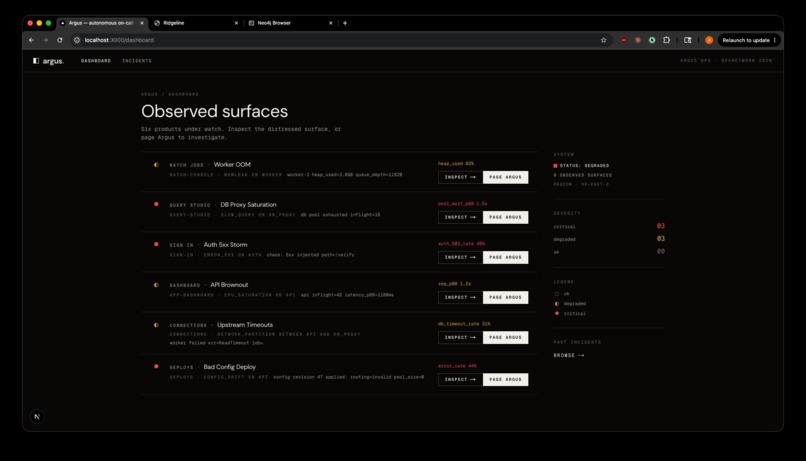
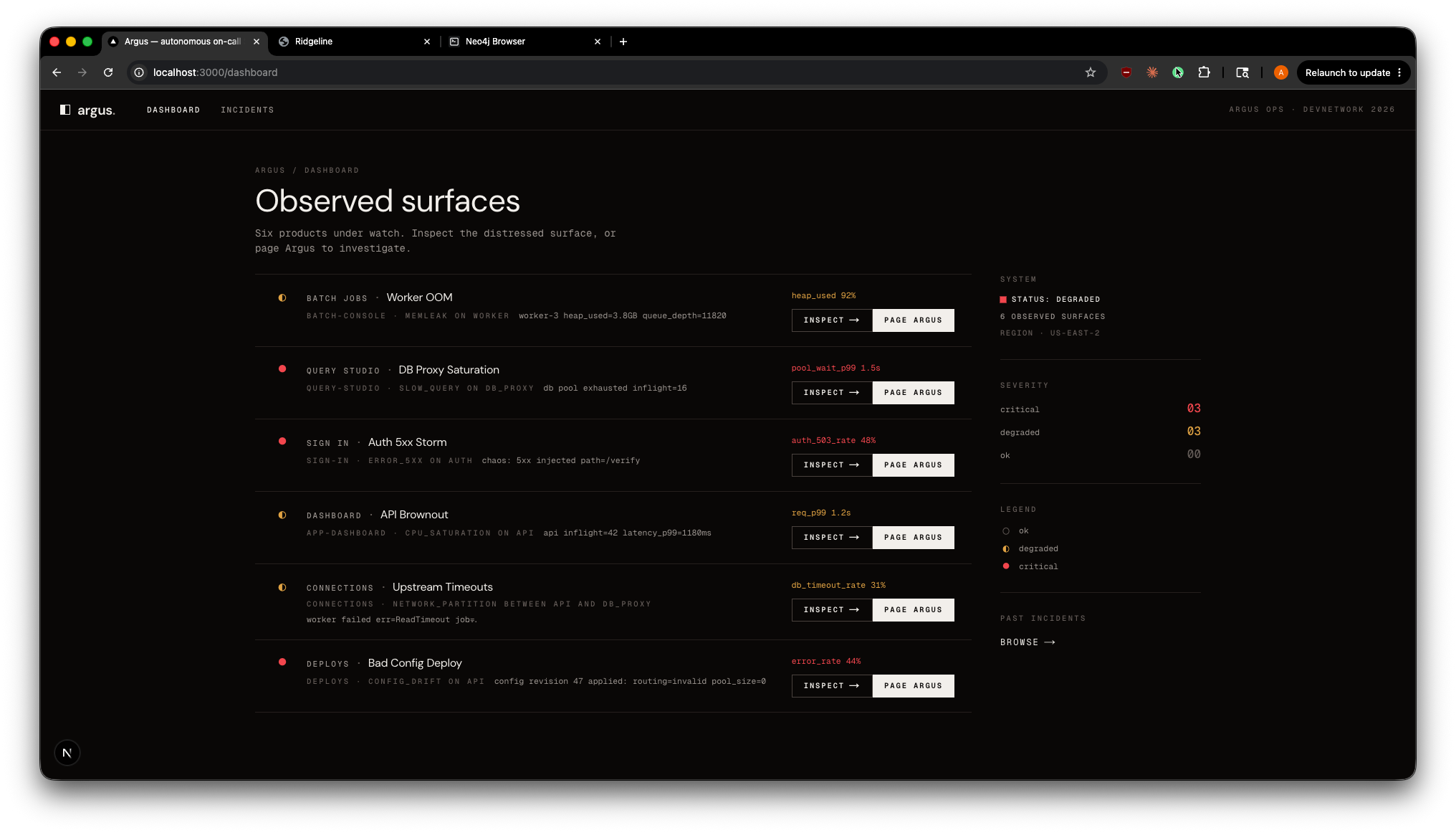
Argus Dashboard
-
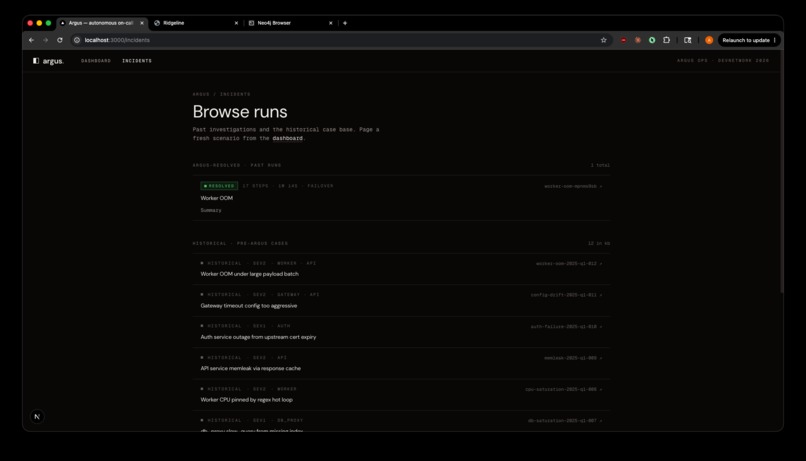
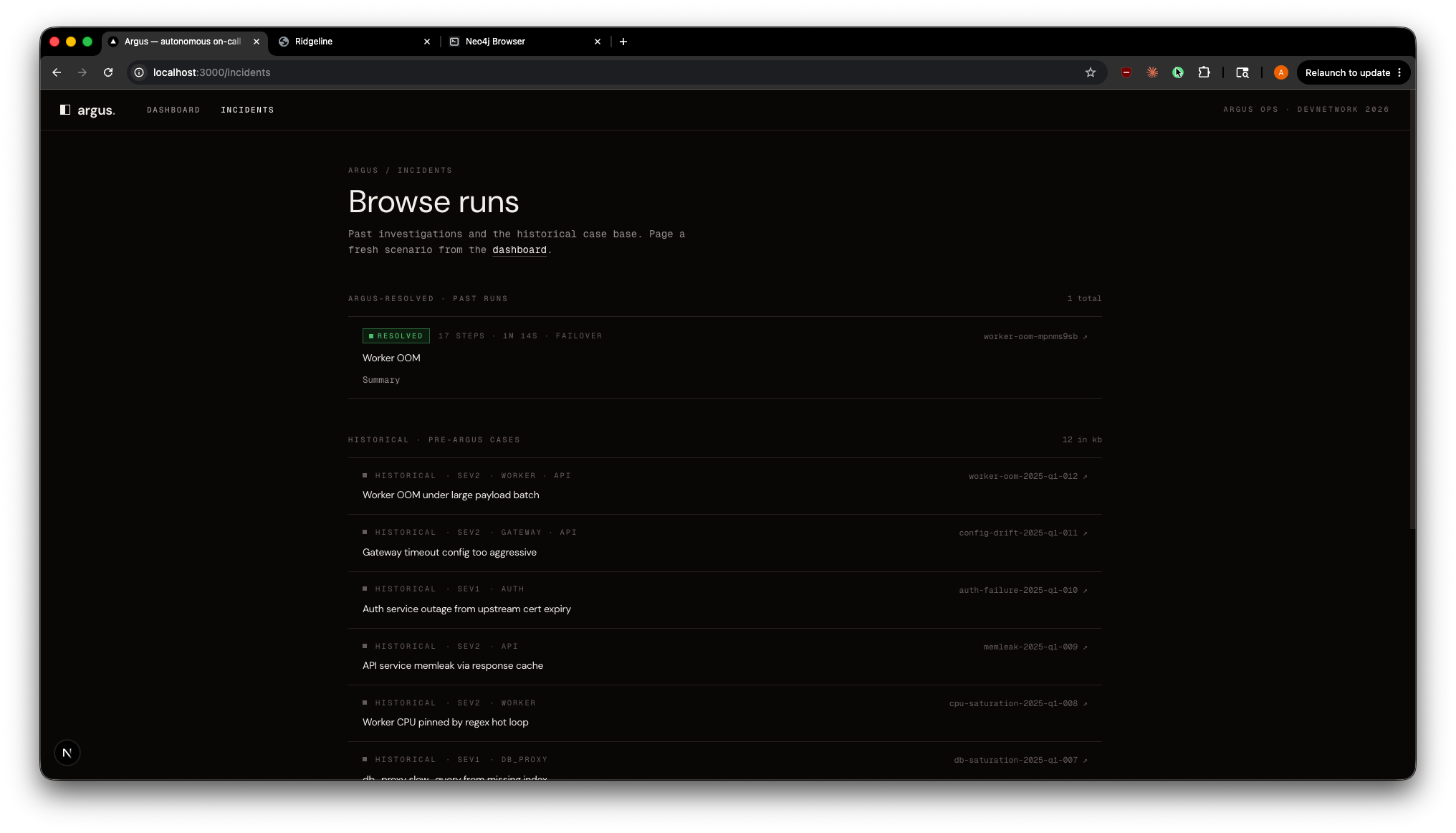
Argus Incident Runs Browser
-
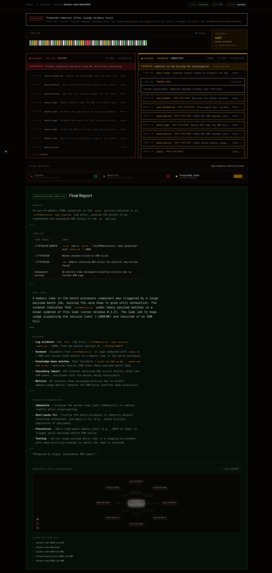
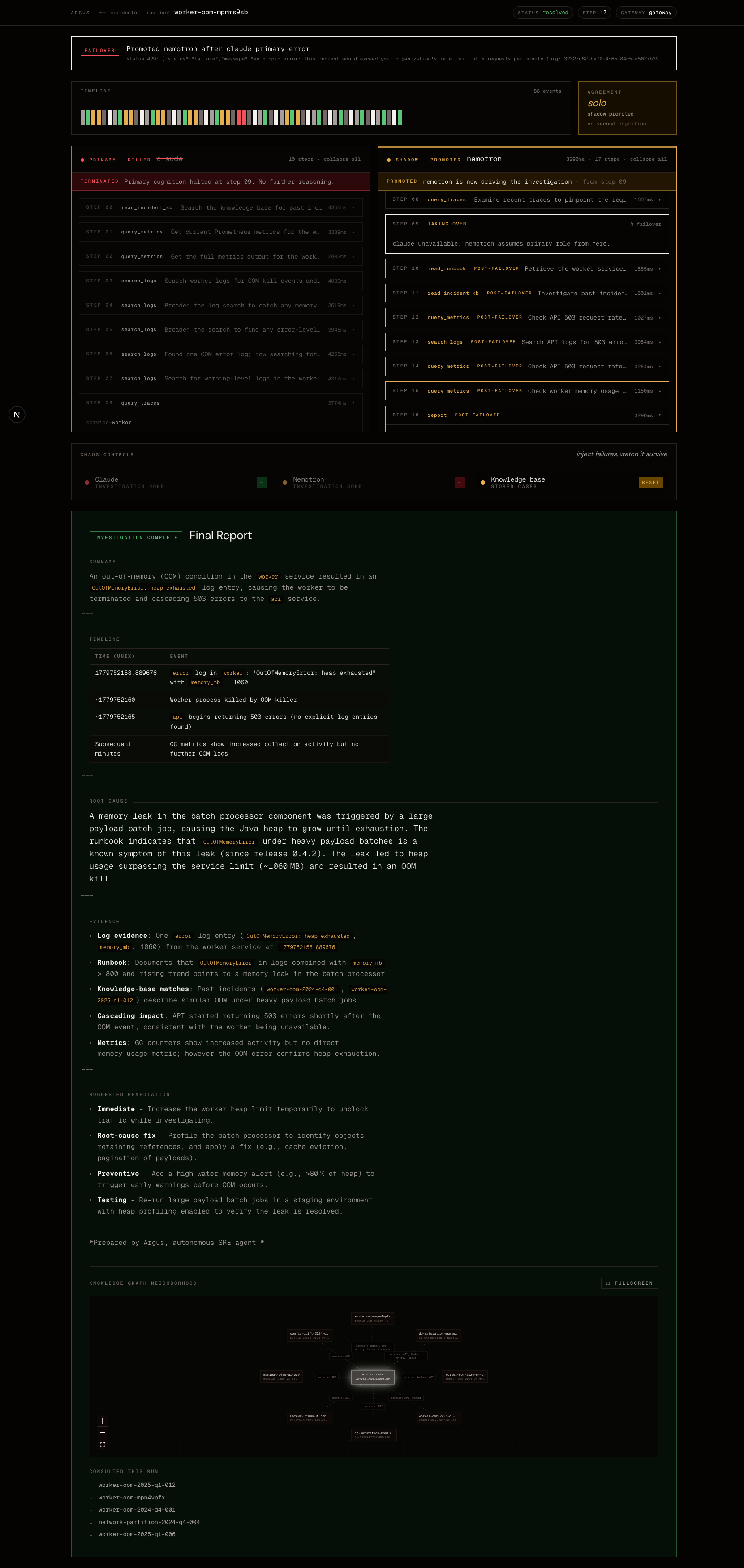
Argus Incident Completed Investigation
-
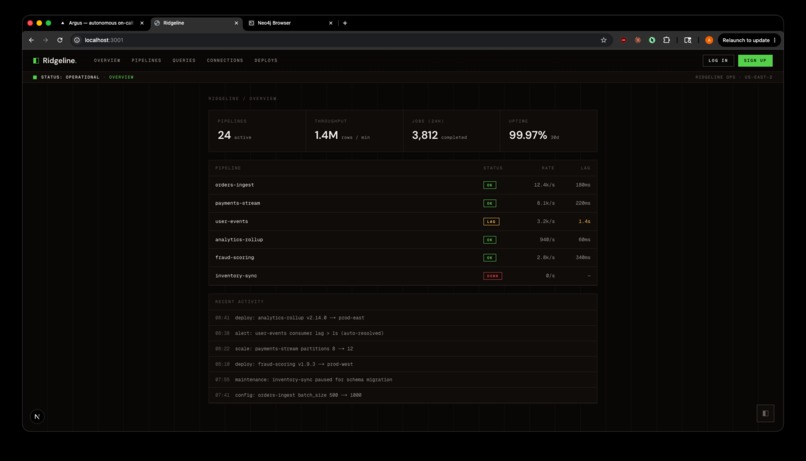
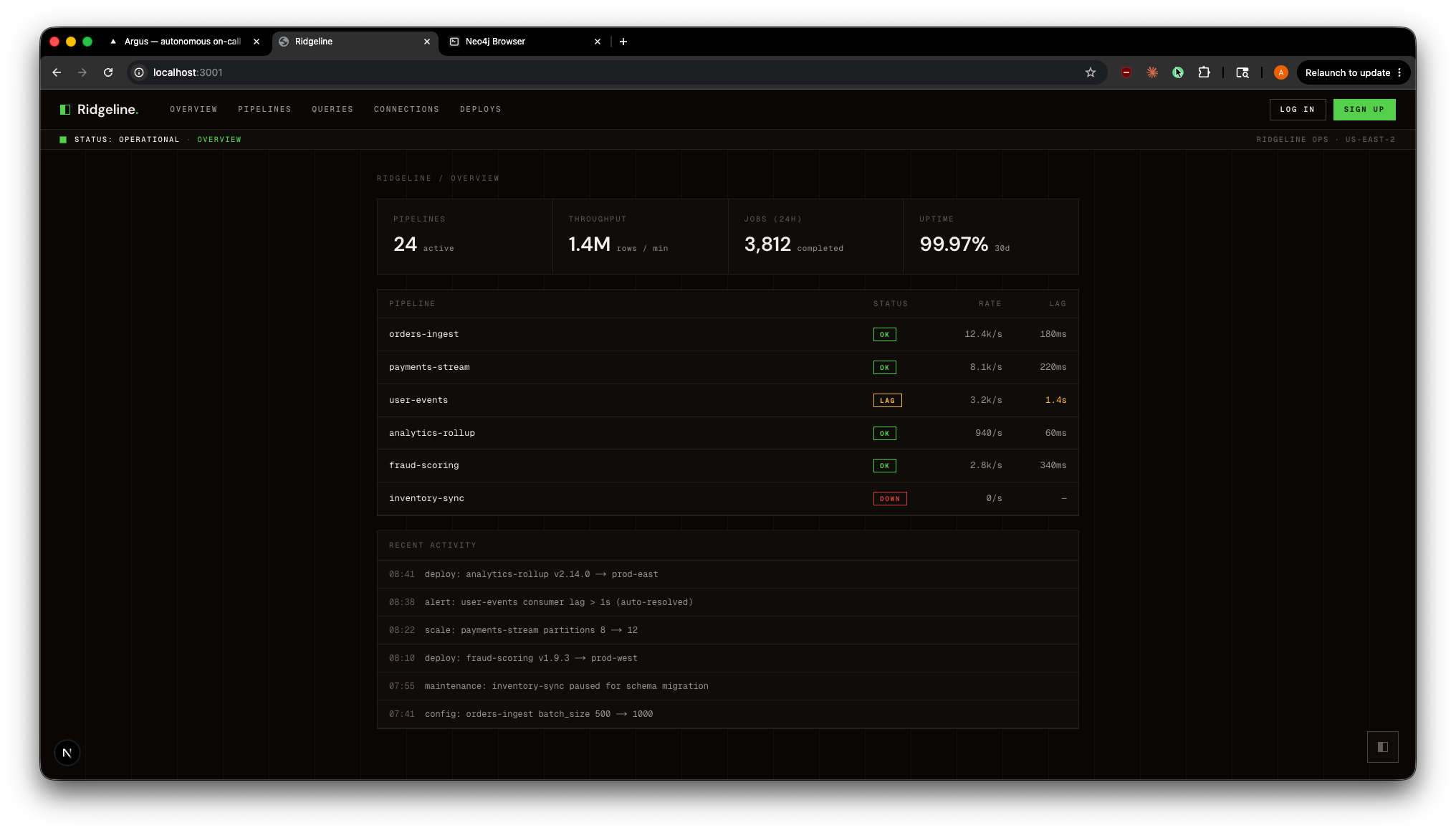
Ridgeline Mock Service Dashboard
-
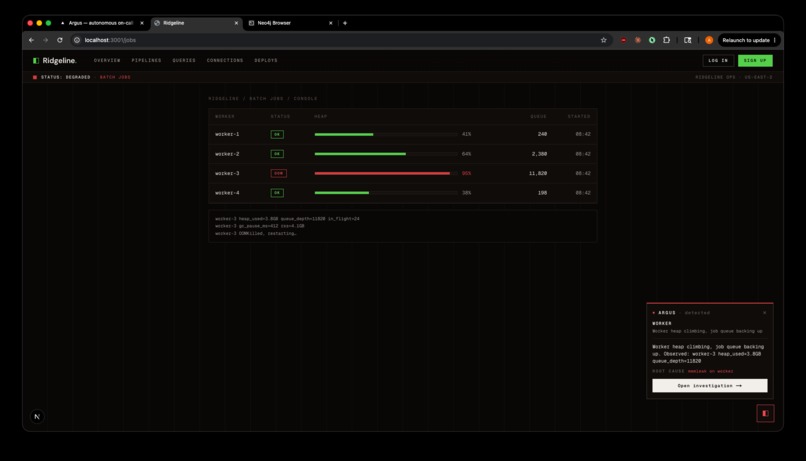
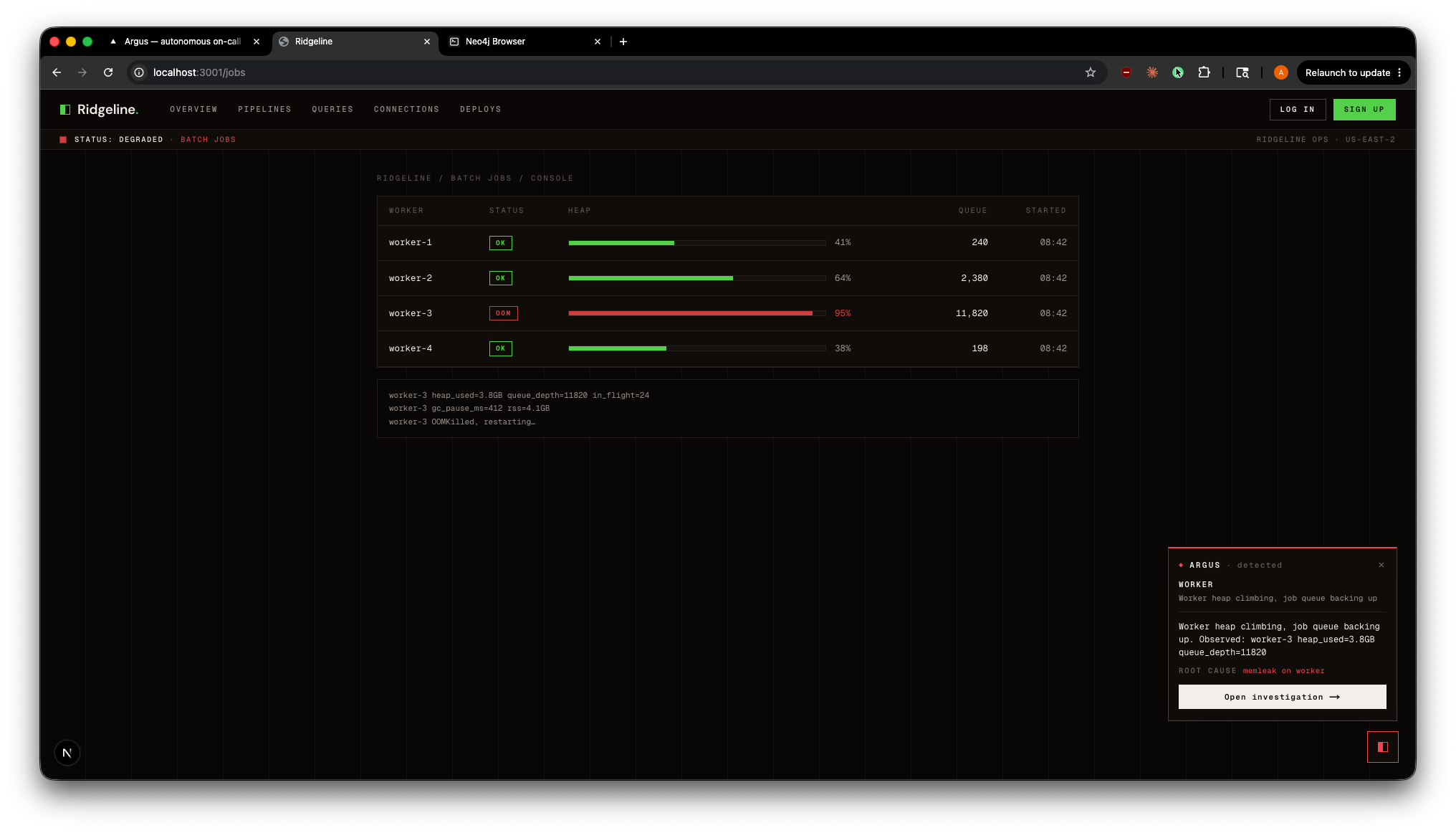
Ridgeline Batch Jobs Incident + Argus Initial Diagnosis
-
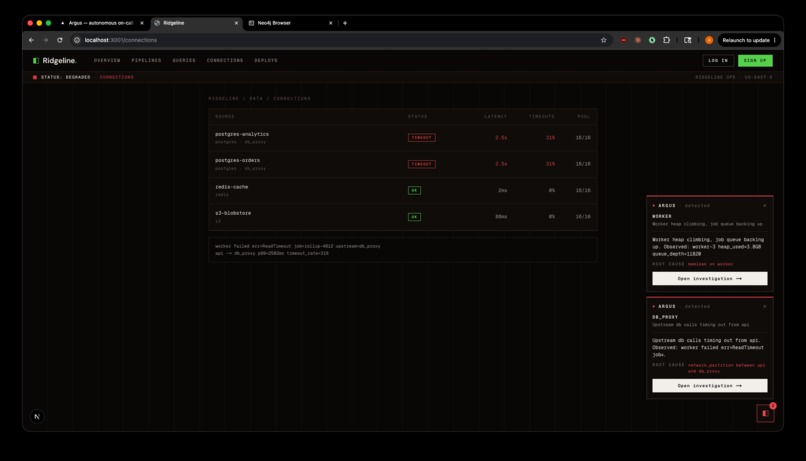
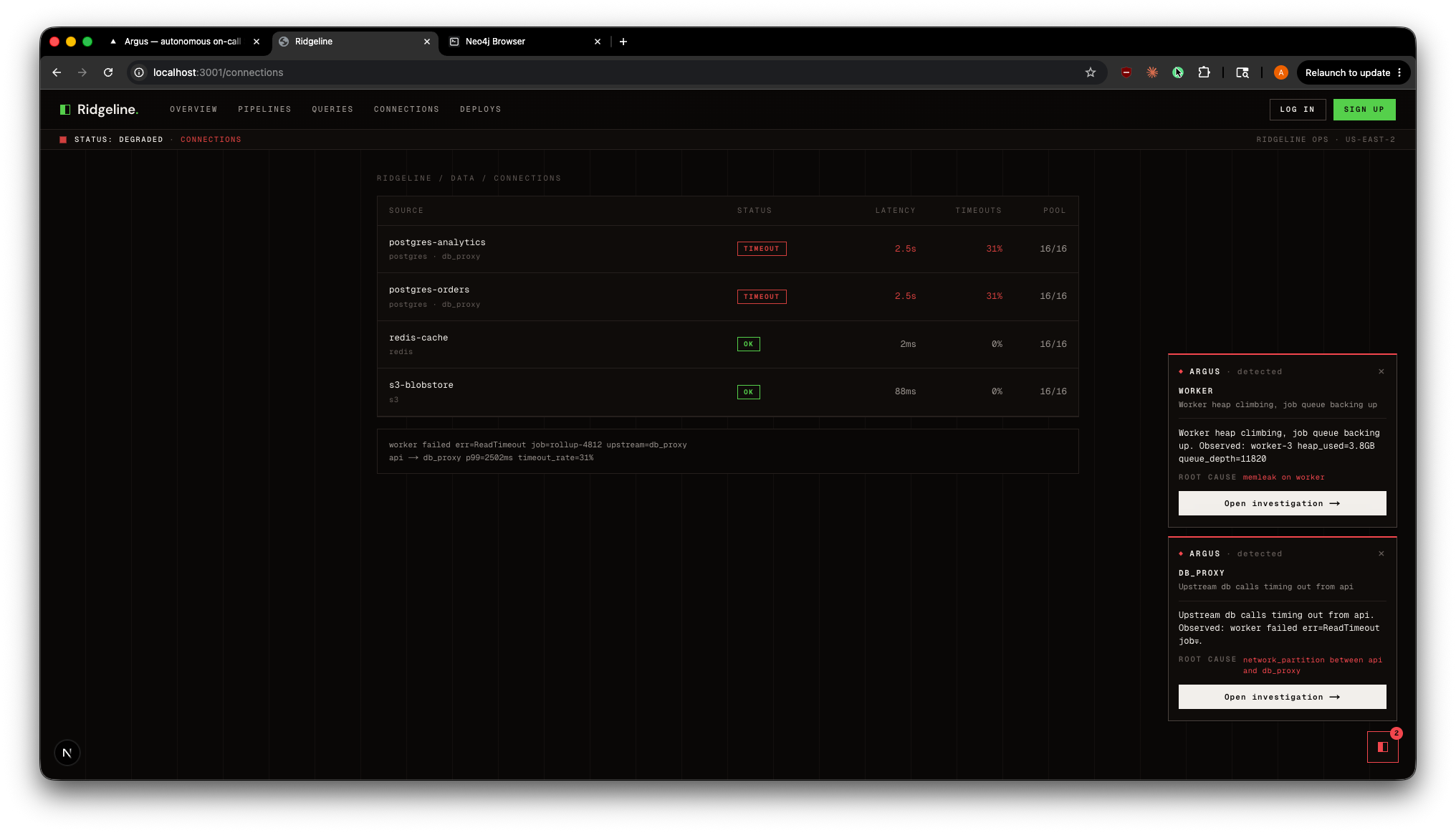
Ridgeline DB Connection Incident + Stacked Argus Diagnoses
-
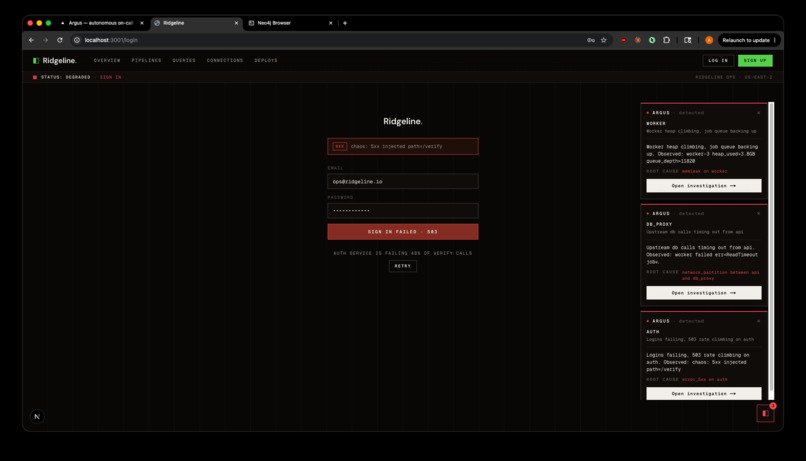
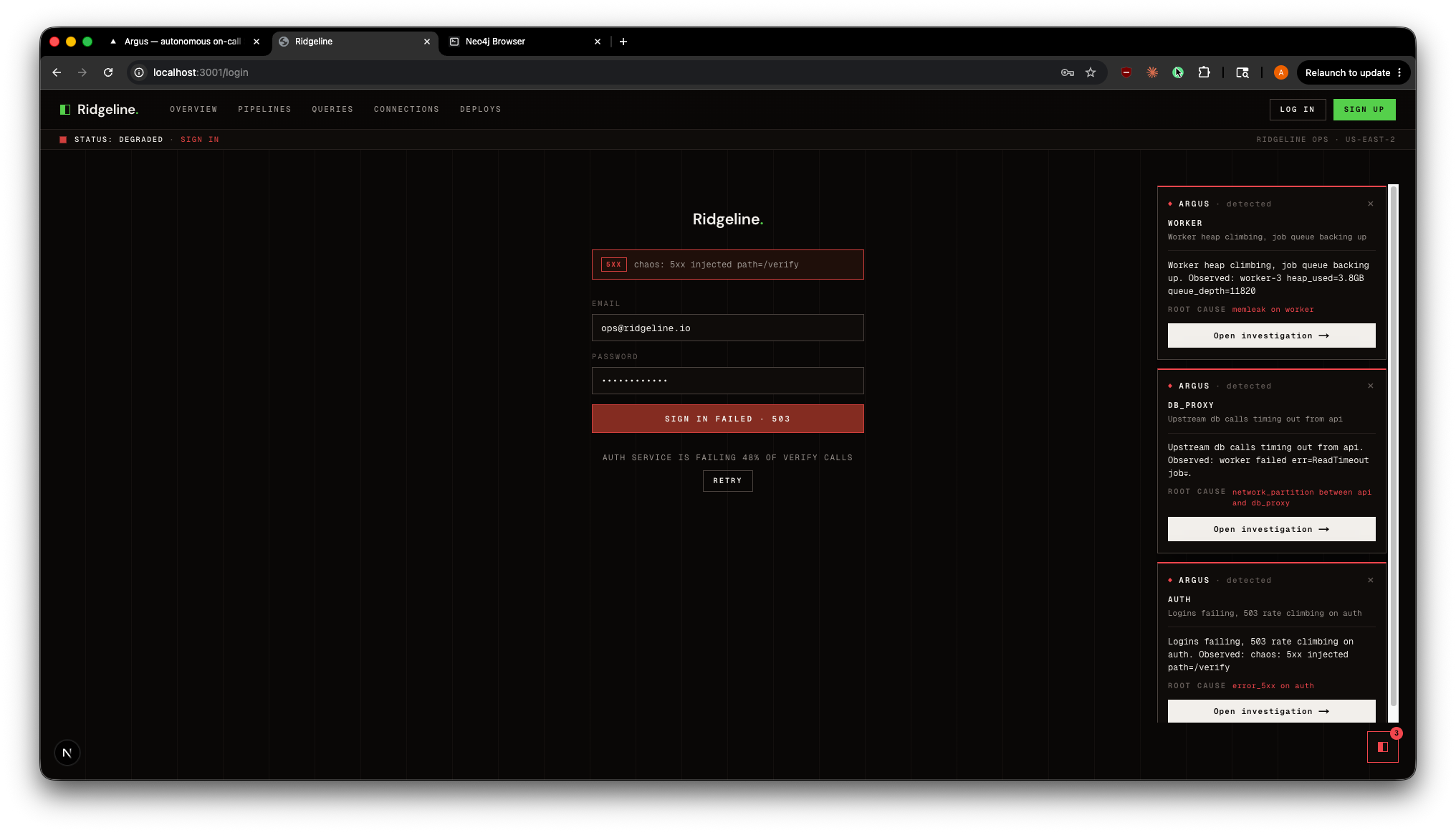
Ridgeline Auth Incident + Stacked Argus Diagnoses
Inspiration
Every team building agents hits this pain the moment they go to production: the LLM blinks, the agent dies (I dealt with this late night on May 26th when Claude's Opus 4.7 and Haiku models had a partial outage). Existing answers are retry loops, fundamentally single-cognition and fundamentally exposed. And when the incident is over, the knowledge dies with the chat log. No one learns.
What it does
Argus is an autonomous on-call SRE agent that investigates live incidents while surviving the infrastructure chaos it is responding to.
Three core capabilities:
Dual-cognition resilience. Two LLMs (Claude as the primary, Nemotron-on-Crusoe as the shadow) execute the investigation in lockstep through TrueFoundry's AI Gateway. When the primary degrades, the shadow takes over with zero context loss. When they disagree, that disagreement is itself a hallucination signal.
Incident Knowledge Base. Every resolved investigation is ingested into a bi-temporal knowledge graph (Neo4j + Graphiti). On the next incident, Argus retrieves past cases sharing services, symptoms, or root causes, then verifies them against live signals before trusting them. The graph compounds: resolve, ingest, retrieve, resolve smarter.
Ridgeline integration. A standalone product simulation (Ridgeline, a fictional data-pipeline platform) where ordinary user actions trigger realistic faults. An embedded Argus launcher detects the fault and streams in a live first-pass triage (a Claude Haiku call through the gateway), then deep-links into the full investigation view. Every one of the six scenarios has its own Ridgeline surface, and faults across surfaces stack as independent alerts. The operator never leaves their product context.
How we built it
- Next.js 16 App Router: Argus investigation view (:3000) + Ridgeline product simulation (:3001), visually and brand-distinct.
- Node.js orchestrator (Hono) managing dual-cognition conductor, incident lifecycle, chaos injection, KB ingest, and triage endpoints.
- TrueFoundry AI Gateway for provider routing + automatic direct-mode fallback when the Gateway itself fails.
- Crusoe Cloud Managed Inference hosts Nemotron as the shadow cognition.
- MCP servers wrap our (mock) observability stack: logs / metrics / traces / runbook / incident-kb. Each is wrapped with retry + circuit breaker + synthetic-response fallback.
- Incident Knowledge Base built on Python FastAPI, backed by Neo4j + Graphiti. Ontology: incidents → services → root causes → remediations, with bi-temporal edges. Graphiti's entity extraction + rerank run on Crusoe-hosted Nemotron Nano — the same model family as the shadow cognition — paced through a shared token-bucket limiter so live ingest stays well under provider RPM. Per-incident ingest state (queued / running / done / failed, extraction-call counter) is tracked via a
contextvars.ContextVarhook on the rate-limited LLM client and surfaced through an admin/admin/ingest/status/{id}endpoint so the UI can render a live counter while Graphiti is writing. MCP tool for agent retrieval, admin API for ingest/seed/reset. - Python FastAPI mock service cluster (api / worker / db_proxy / auth) with chaos injection endpoints.
- Ridgeline app with 4 surfaces (Overview dashboard, Sign In, Query Studio, Batch Jobs), each with an embedded fault trigger and Argus launcher overlay.
- Production deployment on Vercel + a single DigitalOcean Droplet. Both Next.js apps deploy to Vercel via GitHub auto-deploys with Root Directory overrides for the pnpm workspace. The Hono orchestrator, KB, FastAPI cluster, Neo4j (with APOC), and Caddy run together in
docker-compose.prod.ymlon the Droplet — Caddy fronts everything with auto-provisioned Let's Encrypt TLS, and the orchestrator stays internal-only behind it.
Challenges we ran into
- Shadow execution at scale: keeping two LLM streams synchronized while only executing one set of tool calls.
- Detecting "brownout" (slow but not failed) without an embedding model. We ended up using token-set similarity as a pragmatic surrogate.
- Mid-flight failover. Initially a kill-provider chaos action only blocked the next call, so the current step still finished on the dying provider. We added an
AbortControllerper in-flight chat call inside the gateway, andsetProviderBlockednow aborts the controllers — failover takes effect mid-step, the way it would in a real outage. - Knowledge graph ingest: Graphiti's entity extraction needs a high-throughput LLM, and we tried four. Gemini (20 RPM) and Groq (12k TPM under Graphiti's ~18k prompt) were rate-limited unusably. NVIDIA NIM (llama-3.3-70b) worked for seed ingest but its 40 RPM ceiling couldn't carry a live incident's ~100-call extraction burst even after we added a token-bucket limiter, retry-stripping, and a compact-payload rewrite. We finally moved extraction and reranking to Crusoe Cloud Managed Inference running NVIDIA Nemotron-3-Nano-Omni-Reasoning — the same model family already hosting the shadow cognition — and live ingest now completes in seconds.
- Two-brand visual design: Argus (cool violet, serif italic) and Ridgeline (warm green, monospace) needed to be instantly distinguishable side-by-side while both looking like real products.
- Cross-host production deploy: getting a pnpm monorepo onto Vercel + Docker on a 2GB Droplet meant aligning Vercel's pnpm version with the lockfile, baking workspace-wide installs into per-app builds via Vercel "include files outside" + custom build commands, terminating TLS with Caddy + sslip.io to avoid buying a domain, and turning on Neo4j's APOC plugin so
case_graph.pycould resolveapoc.path.subgraphAll.
Accomplishments that we're proud of
- Live demo: kill Claude mid-investigation. The in-flight call cancels, Nemotron carries the reasoning, the timeline picks up at the next step. Zero rebuild.
- Live demo: sever TrueFoundry Gateway. Direct-mode kicks in. Investigation completes.
- Dual cognition is a feature, not just a fallback. It's a built-in hallucination detector.
- Live demo: trigger a fault from inside a product UI. Argus detects it, triages with AI, and opens a full investigation without the operator ever leaving context.
- The knowledge graph compounds: each resolved incident makes the next investigation smarter. No human curation required.
- Six distinct incident scenarios across four services, each with a branded product surface.
What we learned
Active-active beats active-passive for agents. Running two cognitions in lockstep costs more tokens, but it pays for itself the first time the primary fails. Retry loops restart from scratch; a warm shadow picks up mid-thought. For production agents, redundancy isn't overhead, it's table stakes.
The Gateway abstraction earns its complexity the moment chaos hits. When everything is healthy, a gateway looks like an unnecessary middleman. The moment you need to reroute between providers, fall back to direct API calls, or inject chaos for testing, it becomes the single control point that makes all of that possible without touching application code.
A knowledge base that ingests its own outputs creates a genuine learning loop. We expected the KB to be a nice-to-have. It turned out to be the agent's strongest reasoning aid. When Argus retrieves three prior incidents with the same service and a similar symptom, it converges on the root cause faster and with higher confidence. Each resolved incident makes the next one smarter, with no human curating a knowledge base. (Bonus coherence: the Crusoe-hosted Nemotron Nano that drives the shadow cognition also writes the graph — one inference provider end-to-end on the open-source side.)
Product-embedded AI triggers are the right UX for on-call operators. Dashboards and chatbots require a context switch. The operator is already staring at the broken thing. Embedding the trigger directly in the product surface (a failed sign-in, a saturated query, a climbing heap bar) means detection and response start from the same screen.
What's next for Argus
Real observability integration. Replace the mock service cluster with MCP servers that connect to real observability platforms (Sentry, Datadog, PagerDuty). The chaos injection endpoints become unnecessary because the real infrastructure provides the signals. This is the single biggest step toward production readiness.
Approval-gated remediation. Right now Argus investigates and reports. The next step is letting it propose remediation actions (restart a pod, roll back a deploy, scale a pool) that the operator can approve with one click. The dual-cognition architecture already provides a natural approval gate: if both cognitions agree on the fix, confidence is higher.
Predictive brownout detection. Instead of waiting for a fault to fire, Argus could watch latency telemetry and flag services trending toward saturation before they hit thresholds. The KB already stores historical incident timelines, so it has the training data for "this pattern usually precedes an OOM in 10 minutes."
Graph-powered anomaly correlation. When a new incident shares a service node with 3+ past incidents in the knowledge graph, Argus should surface that pattern proactively. "This is the fourth worker-memory incident this quarter, all involving the same job type" is the kind of insight that turns incident response into incident prevention.
Built With
- caddy
- claude
- crusoe-cloud-managed-inference
- digitalocean
- digitalocean-droplet
- docker
- fastapi
- graphiti
- hono
- mcp
- nemotron
- neo4j
- next.js-16
- nvidia-nim
- python
- react-19
- sentence-transformers
- tailwind-css
- truefoundry-ai-gateway
- typescript
- vercel





Log in or sign up for Devpost to join the conversation.