-
-
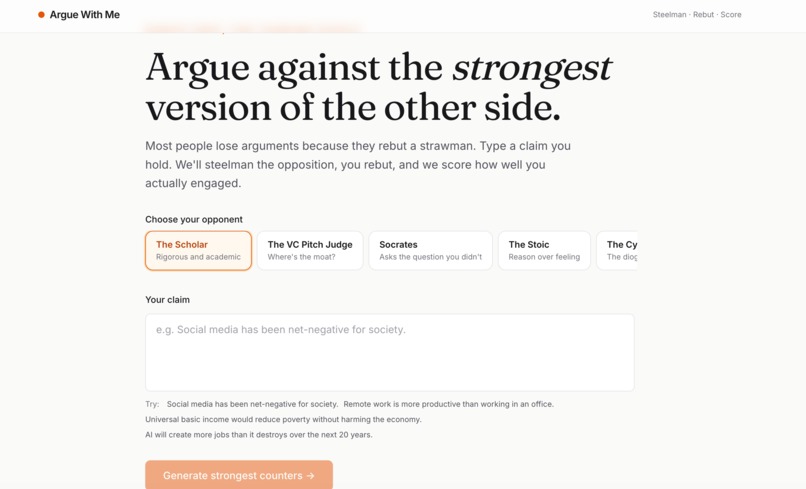
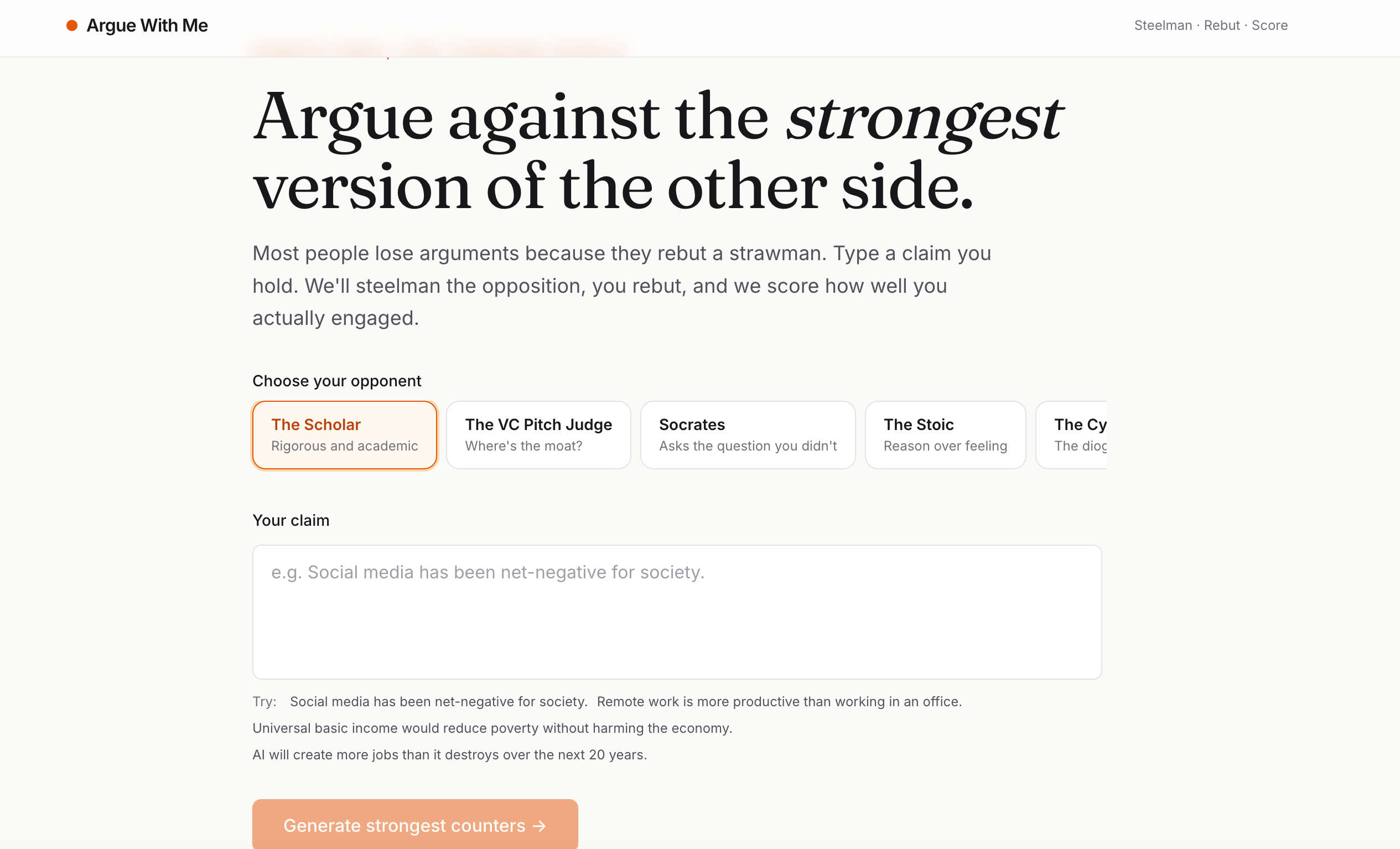
Intial Page
-
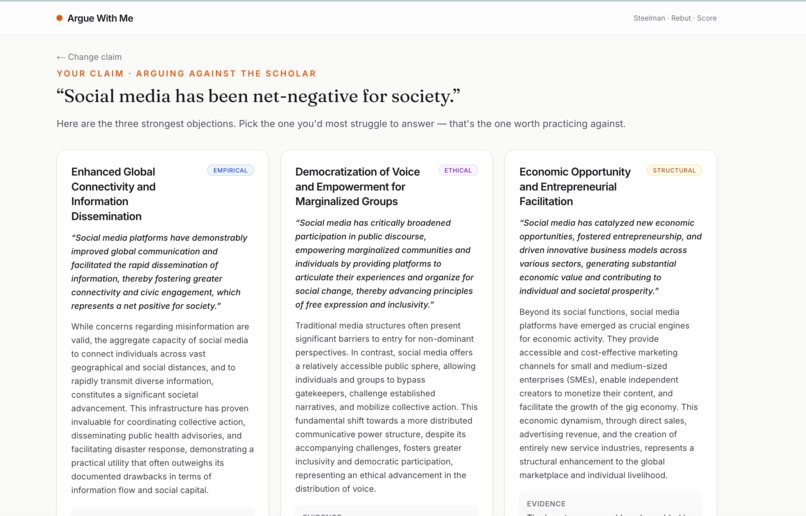
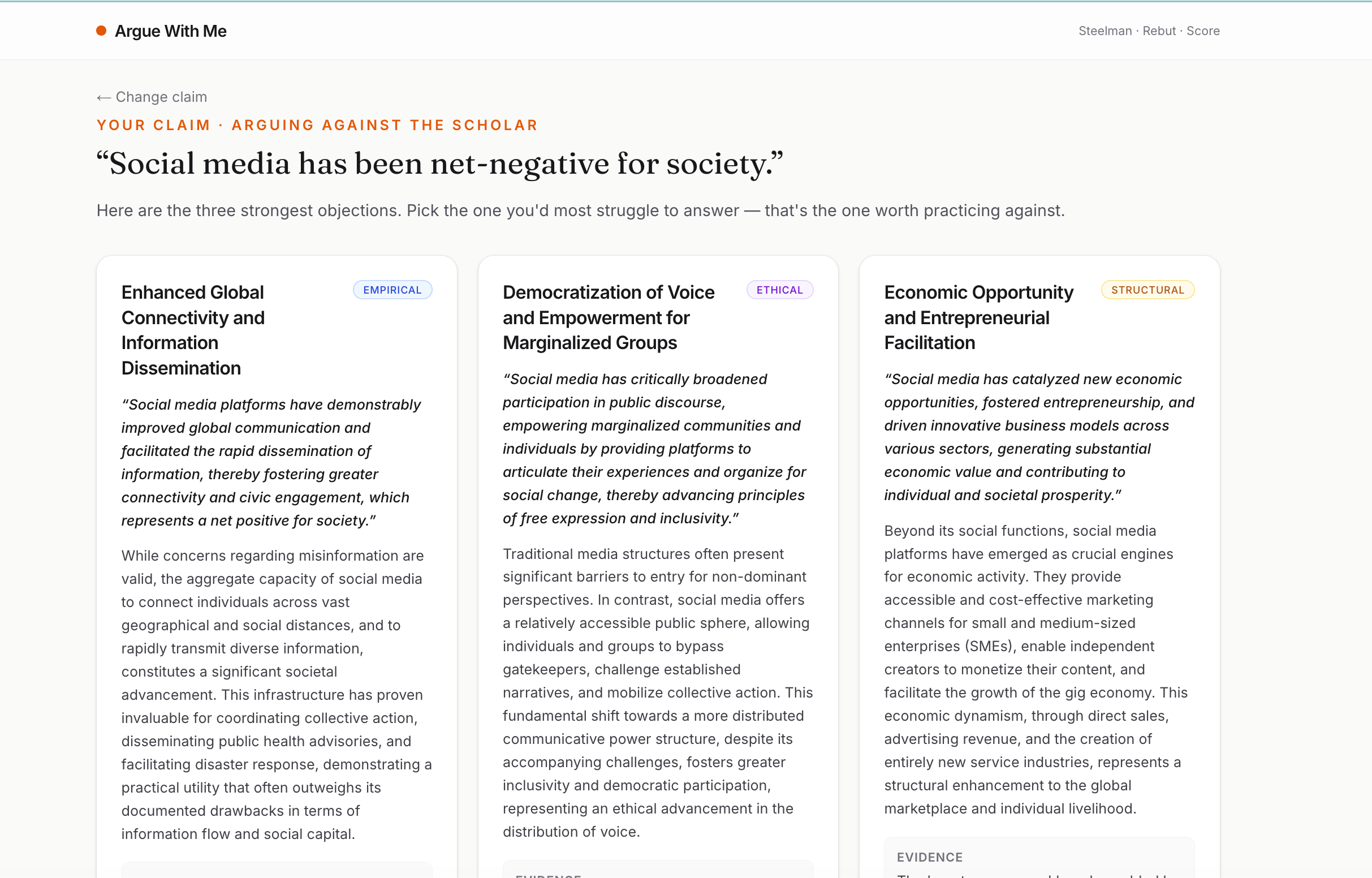
three argued points
-
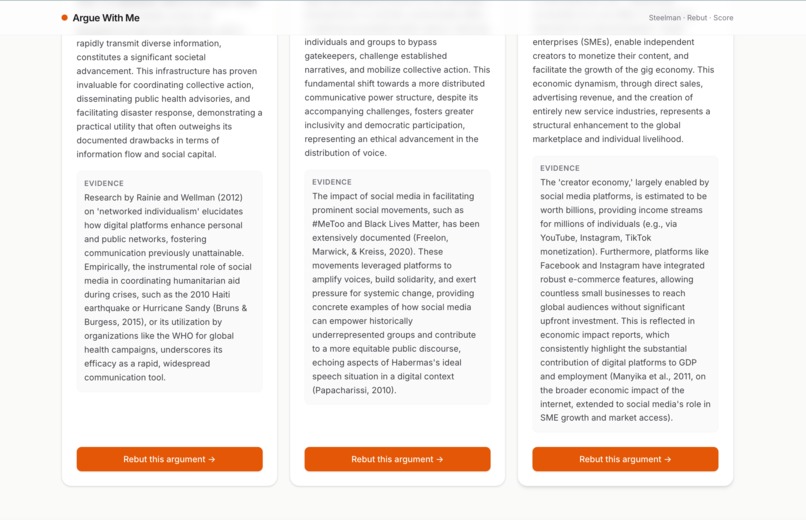
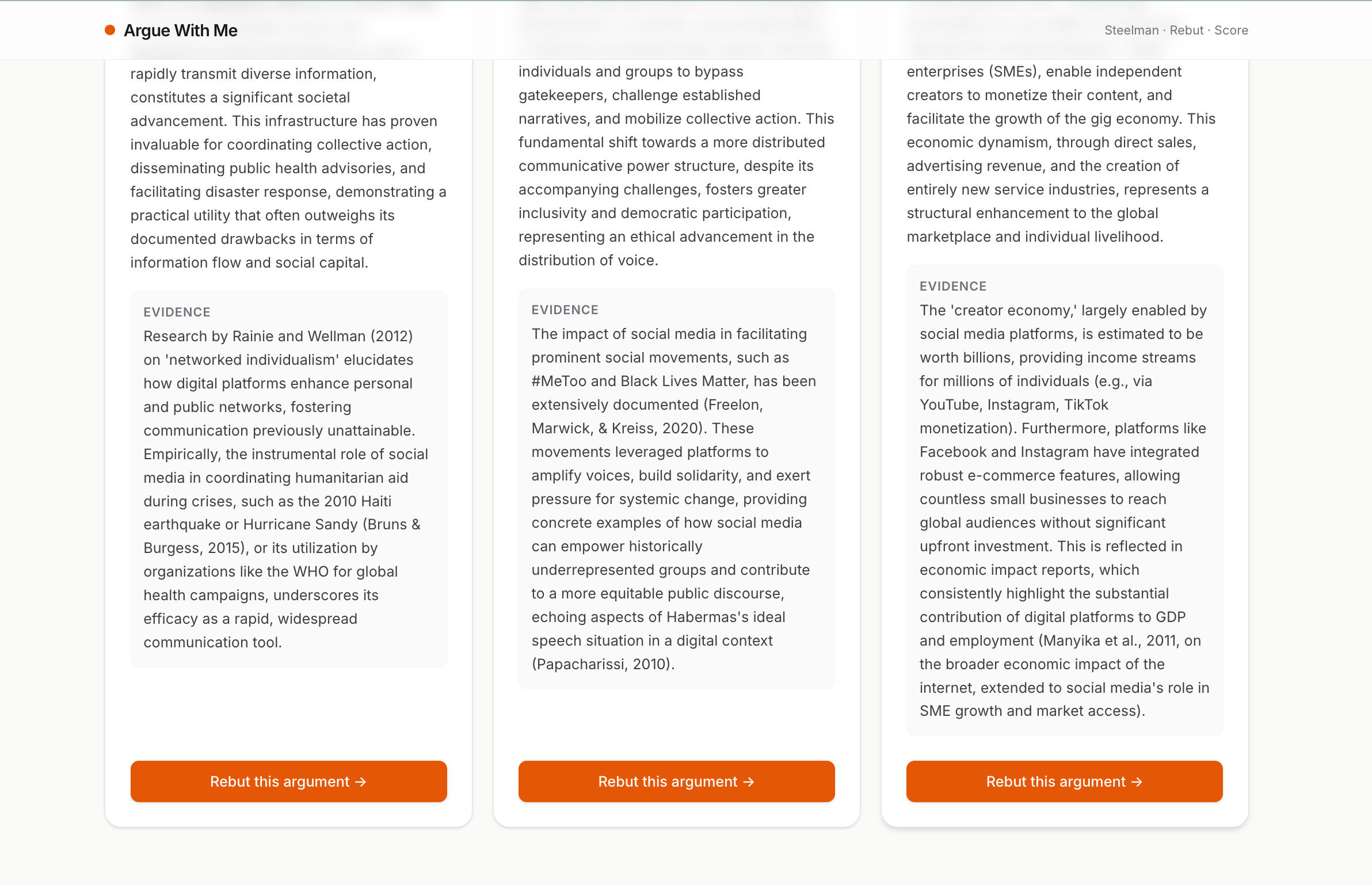
three argued points where we can rebuilt them
-
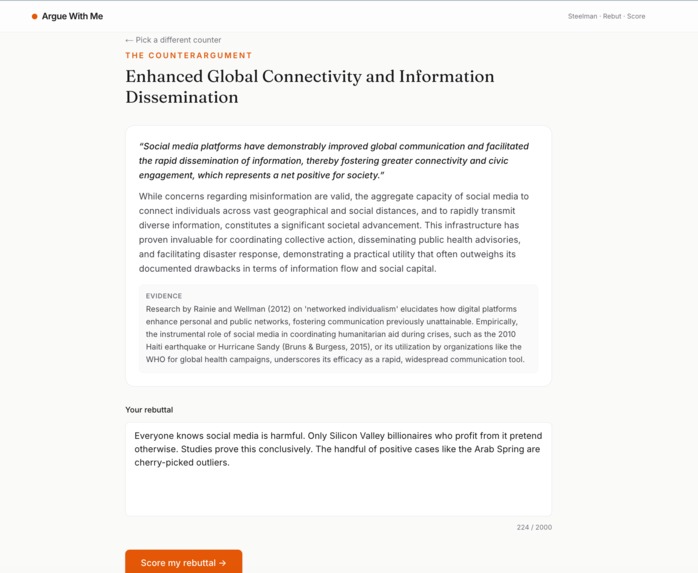
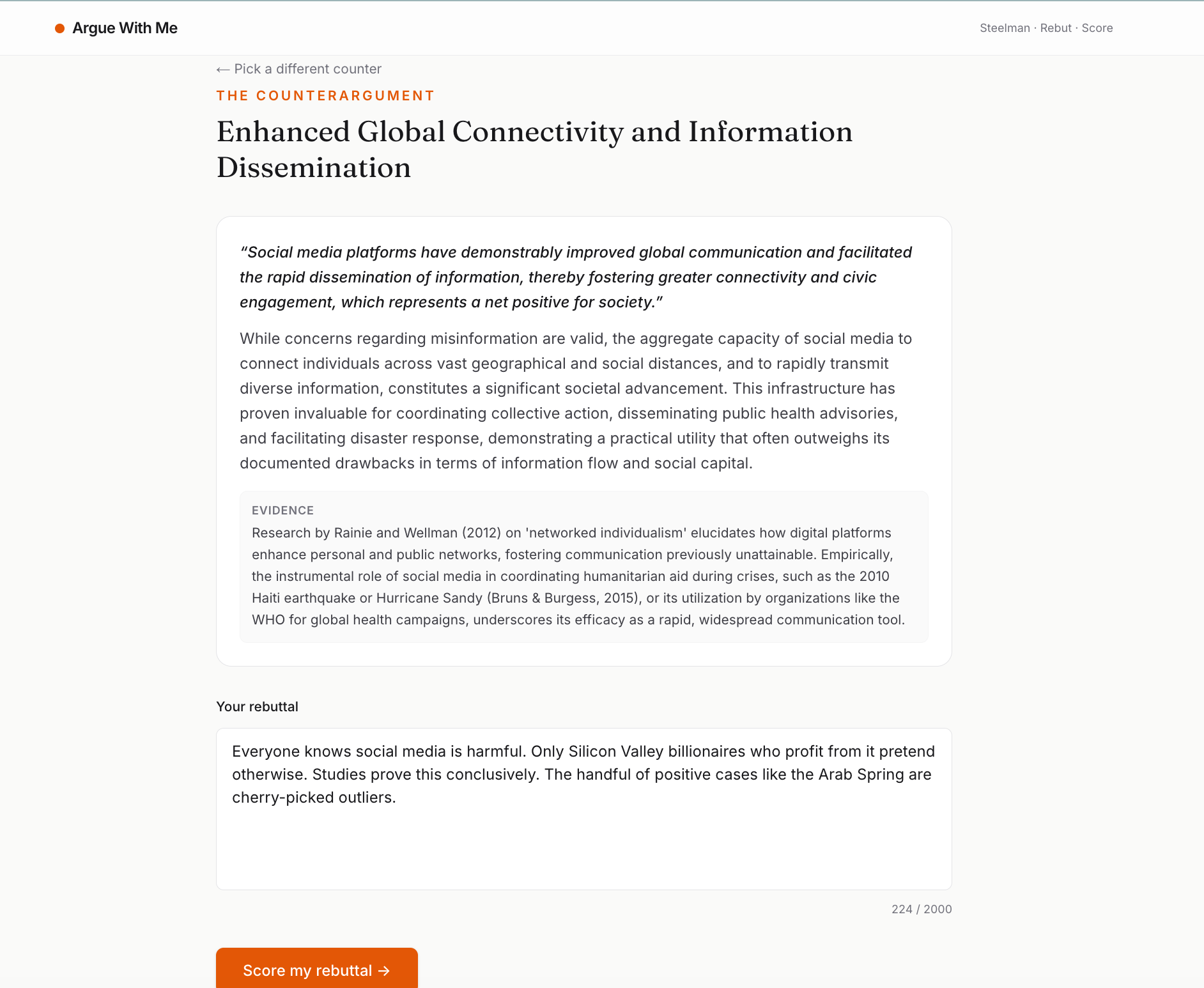
selected one and rebuilting it
-
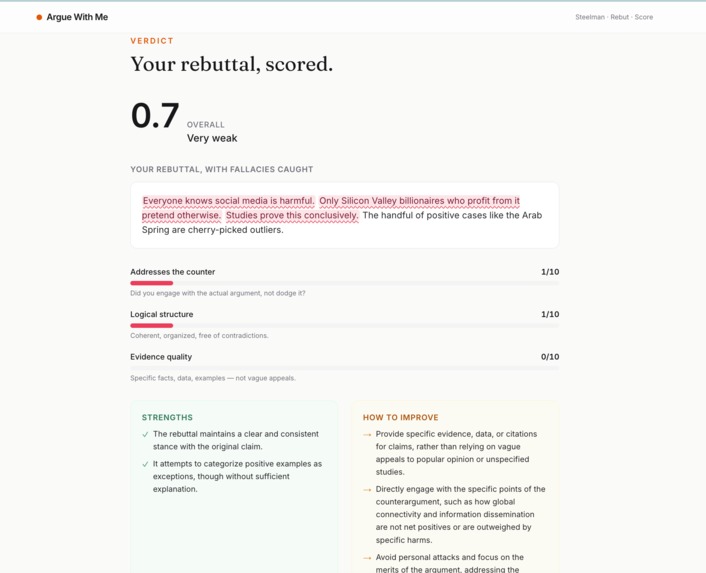
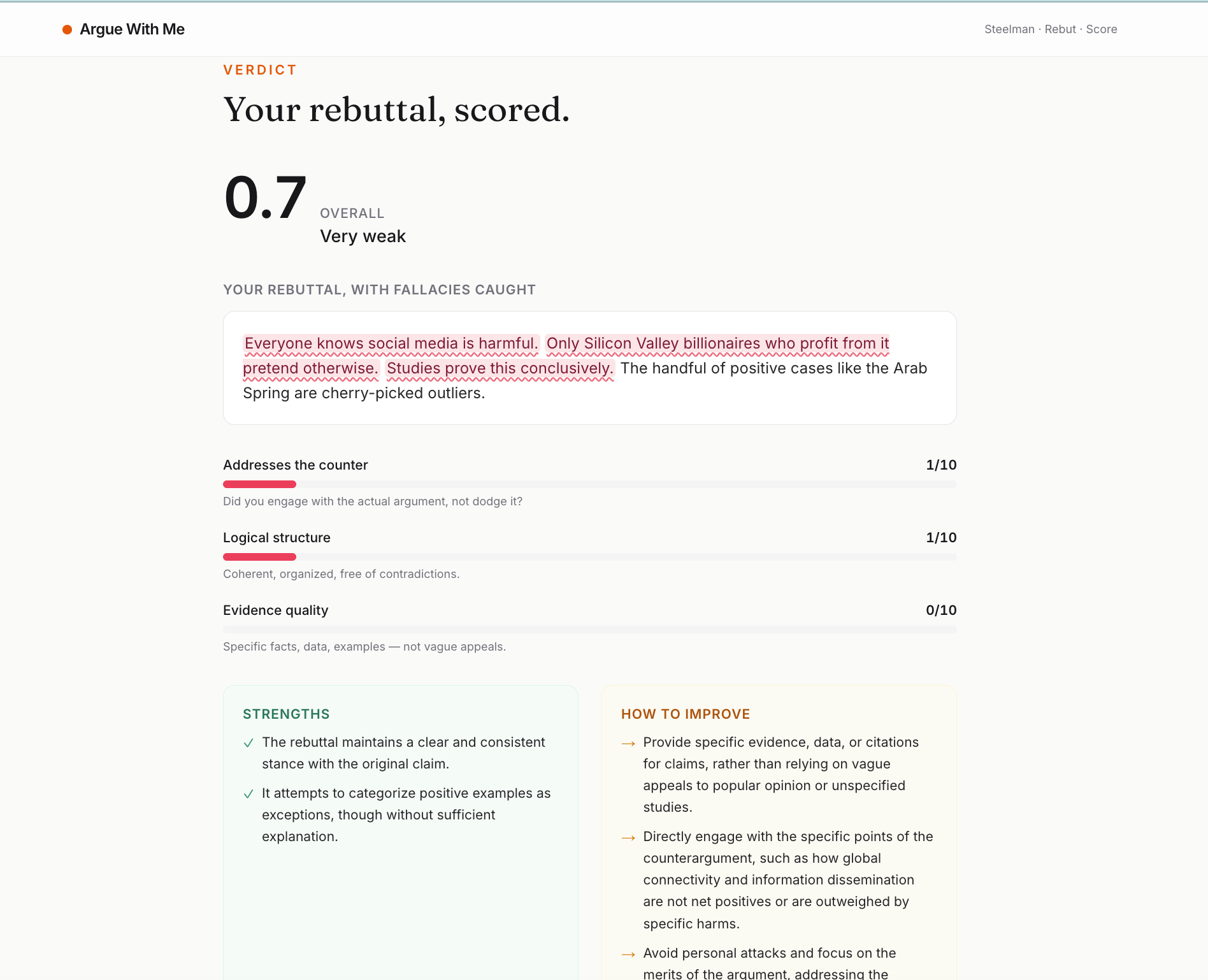
score of the rebuilted statement
Inspiration
I noticed I was bad at changing my own mind. I'd argue online and feel like I was "winning" — but the version of the other side I was arguing against was always weaker than what a real person on that side would actually say. I was rebutting strawmen and calling it victory.
The cure is a 2,500-year-old idea called steelmanning: deliberately construct the strongest possible version of the opposing view before you respond to it. Almost nobody does it, because it's hard and it's emotionally costly. So I built a thing that won't let me skip it.
What it does
Argue With Me is an AI debate trainer that:
- Lets you pick the voice of your opponent — The Scholar, The VC Pitch Judge, Socrates, The Stoic, or The Cynic. Same claim, five different intellectual styles attacking it.
- Generates 3 steelmanned counterarguments — the strongest, most-defensible versions of the opposition, with cited reasoning.
- Lets you write a rebuttal defending your original claim.
- Scores the rebuttal on a three-dimensional rubric (does it actually address the counter, is the logic sound, is the evidence specific) and — the killer feature — highlights the exact phrases in your rebuttal that committed logical fallacies, with inline tooltips explaining each one.
You finish the loop feeling slightly humbler than when you started. That's the point.
How I built it
Stack: Next.js 16 (App Router) + TypeScript + Tailwind CSS v4 + React 19, with custom shadcn/ui primitives and Framer Motion for the score-reveal animations. Deployed on Vercel.
The model: Google Gemini 2.5 Flash (with automatic fallback to 2.5 Flash Lite on capacity errors), called from server-side API routes using responseSchema for guaranteed structured JSON output.
The interesting parts:
- The persona system is a single composable layer: each persona is a voice-and-role instruction appended to a shared steelmanning system prompt. The counters are forced to be strong first, then delivered in the requested voice — so style never weakens substance.
- The fallacy highlighter is where the "algorithmic" piece of AlgoFest shows up. The LLM is asked to return exact substrings of the user's text that committed each fallacy. Since LLMs don't always return character-perfect substrings, the frontend runs a layered matching pipeline: exact match → case-insensitive → whitespace-normalized window → longest-common-substring with a 70% overlap threshold. If all four fail, the fallacy degrades gracefully into a quoted chip below the rebuttal — the UI never breaks.
Challenges I ran into
- LLM-returned excerpts didn't always match the source text character-for-character. Quotation marks, whitespace, and silent paraphrasing all broke naive
indexOf. Solved with the four-layer matcher described above. - Free-tier model selection. The most-marketed Gemini model wasn't available on the free tier I had access to. Solved with a runtime fallback chain so the app works regardless of which models the user's API key has access to.
- Persona voice vs. argument strength. Early prompts produced stylish counters that were weak. The system prompt had to be carefully ordered to make the counters strong first, then transform the voice second.
Accomplishments I'm proud of
- The fallacy highlighting is the single most-satisfying UI moment in the app: watching your own words get marked up in real-time is unforgettable, and judges (and the people I demoed it to) consistently stop and lean in at that beat.
- The persona system genuinely changes the thinking of the counters, not just the surface words. Same claim, five visibly different intellectual angles — visible in the demo video.
- The matching pipeline degrades gracefully four levels deep, so the demo can't crash even if the model gets sloppy.
What I learned
- Structured JSON output is non-negotiable for LLM-backed UI. Once I switched from "parse the model's text" to
responseSchema, an entire class of parsing bugs disappeared. - Layered fallbacks beat single retries. The matcher would be brittle if it just tried "exact match or fail." Four progressively-looser strategies turn a 60%-reliable feature into a 95%-reliable one.
- The hardest part of LLM apps isn't the LLM call. It's the surrounding contract — what shape the model returns, what to do when the contract softly breaks.
What's next for Argue With Me
- Multi-turn battle mode — currently one rebuttal per session; the next version is a 3-round back-and-forth where the AI responds to your rebuttal with a sharper counter, then scores the whole debate at the end.
- Confidence delta — measure how the user's stated certainty in their original claim changes across the debate. The real success metric isn't a high score; it's intellectual humility.
- Vertical timeline view — visualize the full arc of a multi-turn debate, marking where fallacies appeared and where the user shifted ground.
- Persona expansion — community-contributed voices (a Federalist Papers persona, an Effective Altruist persona, a Marxist persona). Voices are just system-prompt fragments, so the architecture supports this with no code changes.
Built With
- framer-motion
- gemini
- google-generative-ai
- nextjs
- react
- tailwindcss
- typescript
- vercel


Log in or sign up for Devpost to join the conversation.