Inspiration
Most security tools find vulnerabilities but never confirm the fix works. We wanted to build something that closes the full loop - attack, detect, patch, and verify, autonomously - with no human in the loop. We also wanted to challenge the assumption that adaptive AI security testing requires expensive RL training pipelines, drawing inspiration from self-evolving multi-agent (SEMA) (Ma 2026), a StarCraft II AI paper whose entropy pruning techniques translated surprisingly well to cybersecurity telemetry.
What it does
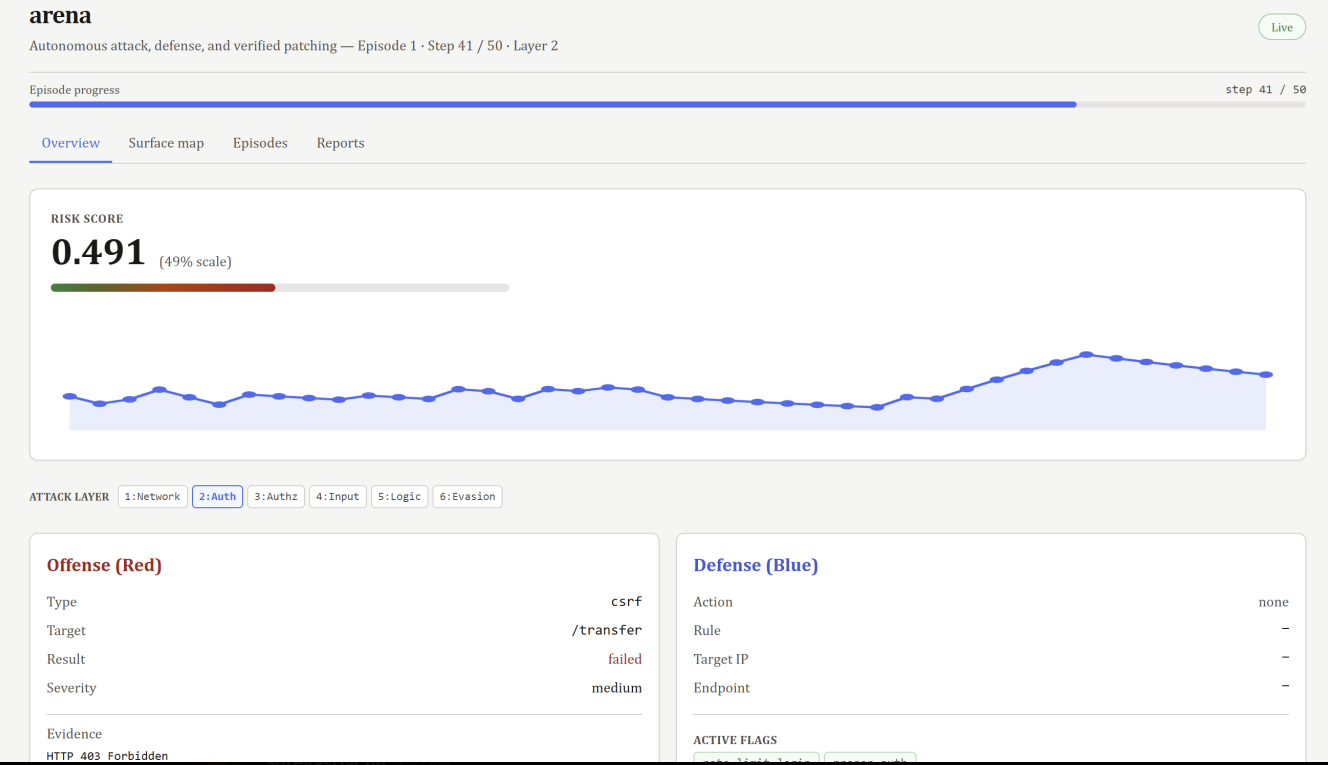
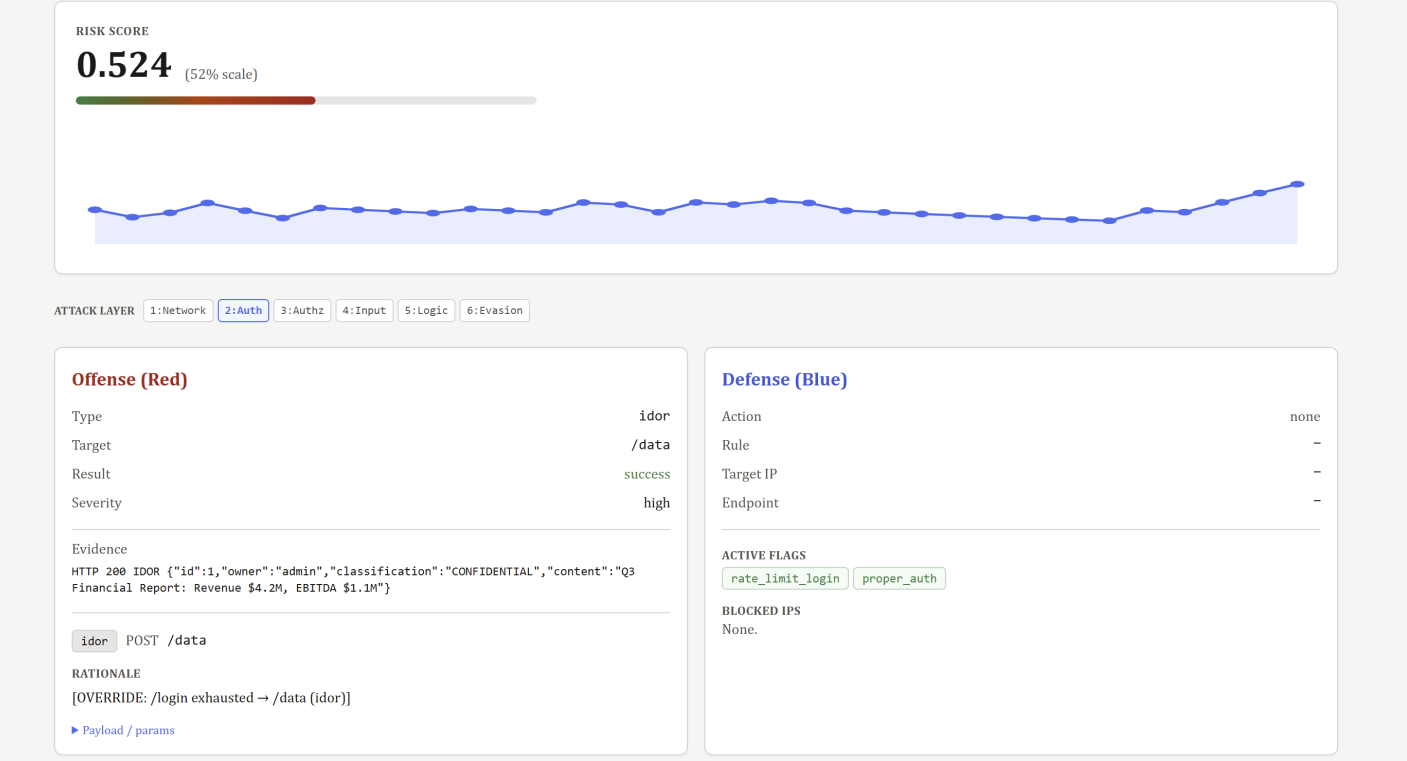
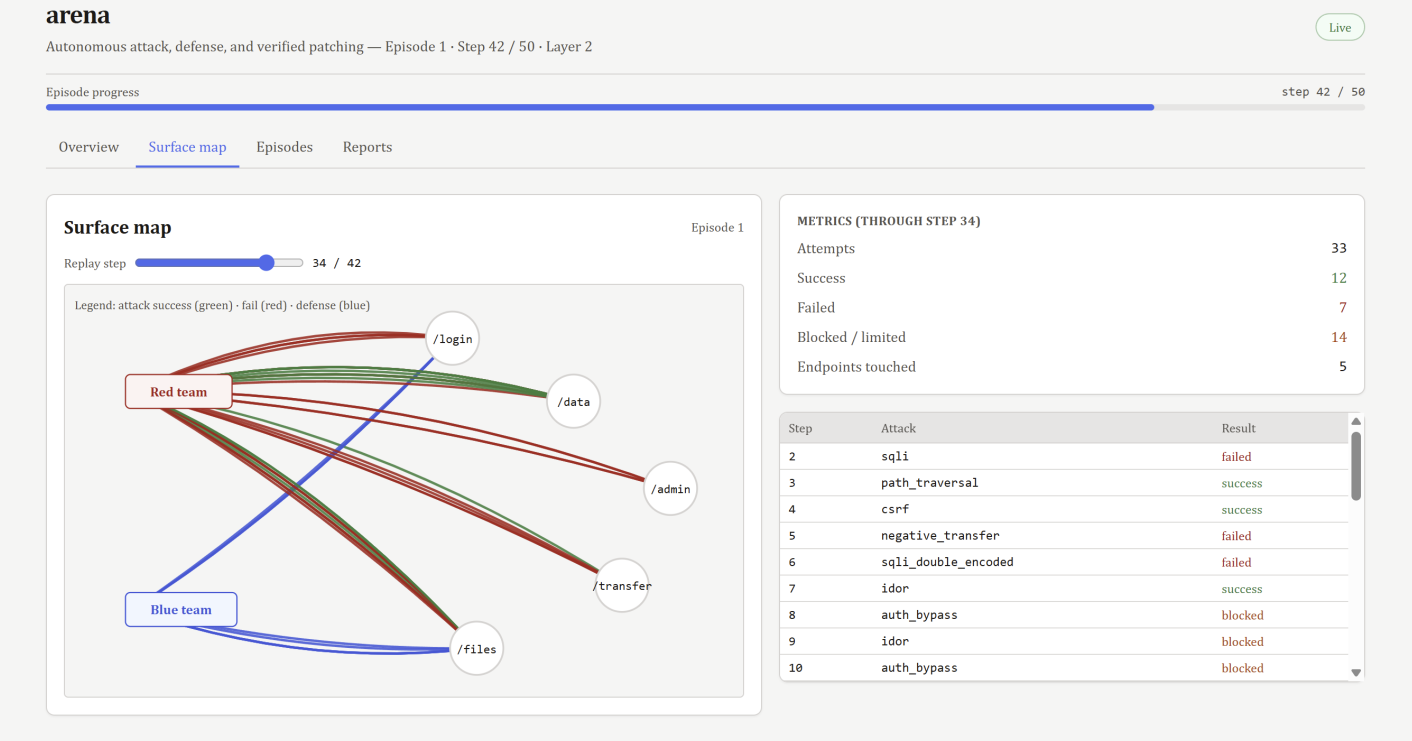
Arena runs a continuous adversarial simulation against a live vulnerable FastAPI server. An Ollama-powered red team reasons about what to attack next, a rule-based blue team detects and mitigates in real time, and Gemini generates vulnerability reports and code patches at episode boundaries. Every patch is verified by re-running the exact exploit that found the vulnerability. If the attack still works, the patch is rejected.
How we built it
We built a LangGraph StateGraph that cycles red, blue, prune, evaluation, and risk nodes every step, with Gemini firing once per episode. The SEMA structural entropy pruner compresses 28-attribute log telemetry down to 8-10 high-signal attributes before any LLM call. The target app, middleware enforcement, and arena loop all run in the same uvicorn process so patches applied by exec() are immediately visible to the next episode's red team.
Challenges we ran into
Getting live patching to work reliably was the hardest problem — retrieving source code from a running FastAPI router, exec()-ing Gemini's generated patch into a controlled namespace, and swapping route.endpoint atomically without crashing the arena loop required careful engineering. Threading STATE_LOCK correctly between the LangGraph background thread and FastAPI's middleware was also non-trivial. And getting llama3 to respect endpoint diversity constraints required a programmatic override layer on top of prompt instructions.
Accomplishments that we're proud of
We are proud of being the first known application of SEMA-style structural entropy pruning outside RTS game-playing agents. The adversarially-verified patching pipeline is genuinely novel. No existing tool uses its own exploits as integration tests for the fixes it generates. We are also proud that the system runs entirely on free-tier APIs and local inference, making it accessible without any cloud spend.
What we learned
LLMs are powerful reasoners but poor at filtering their own inputs, so the entropy pruning step was essential, not optional. We also learned that closing the attack-patch-verify loop is harder than it sounds: Gemini generates plausible-looking patches that fail verification more often than expected, which actually makes the verified=True badge more meaningful. Translating an academic framework from one domain to another requires preserving the math, not just the vocabulary.
What's next for Arena
We want to extend the target beyond a single FastAPI app to multi-service architectures, and add network-layer attacks to complement the current application-layer focus. We also want to replace the exec()-based patching with a proper PR generation workflow: Gemini writes the patch, opens a GitHub PR, and the verification step runs in CI. Longer term, arena could serve as a continuous security regression test that runs in the background of any development environment, catching regressions the moment they are introduced.



Log in or sign up for Devpost to join the conversation.