-
-
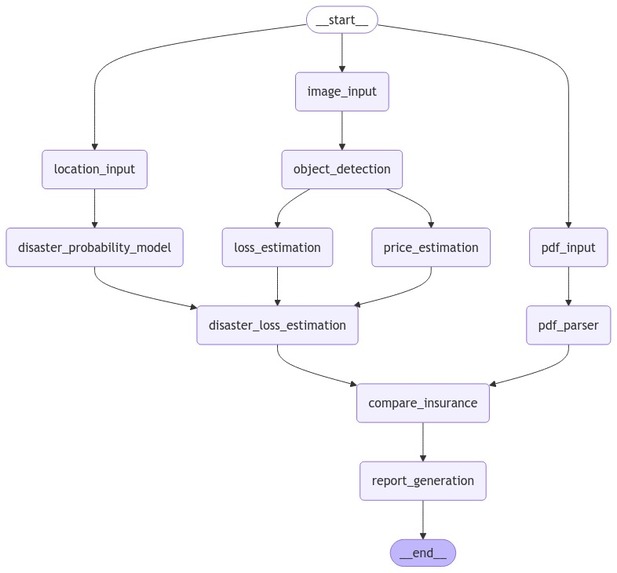
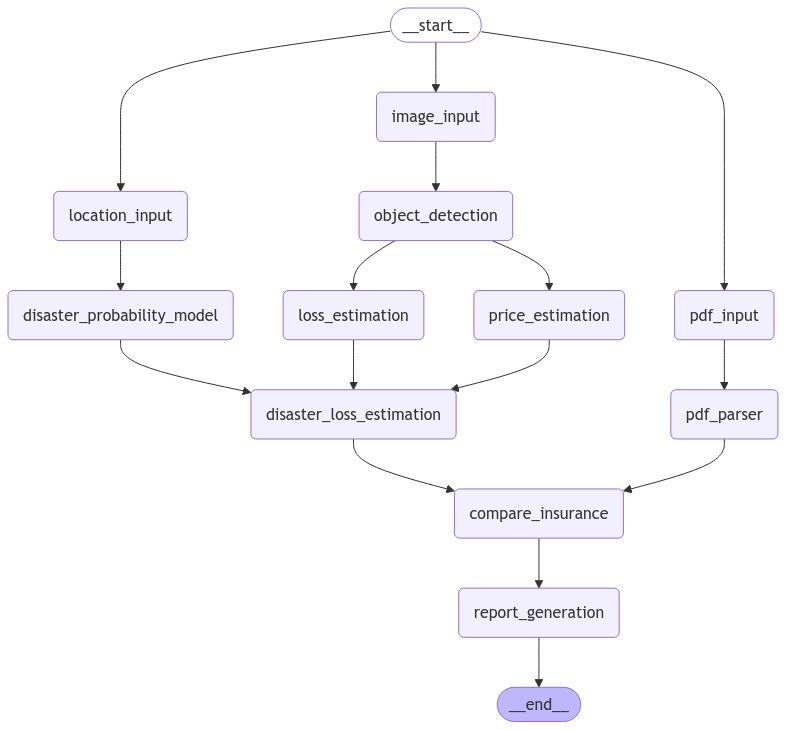
FunctionalityScheme
-
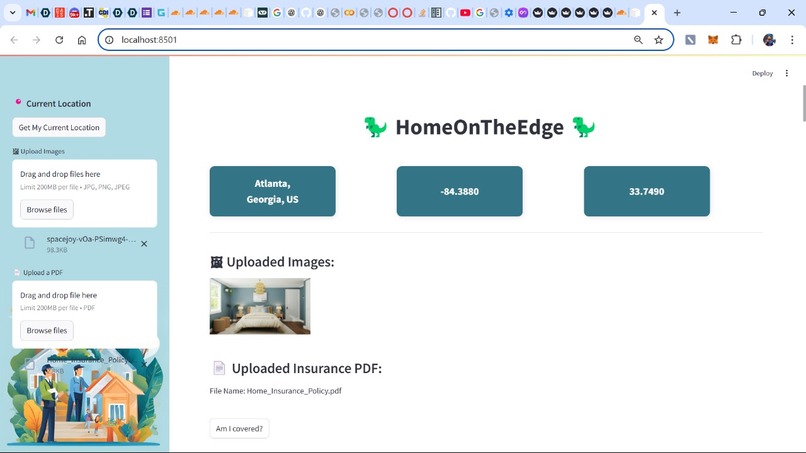
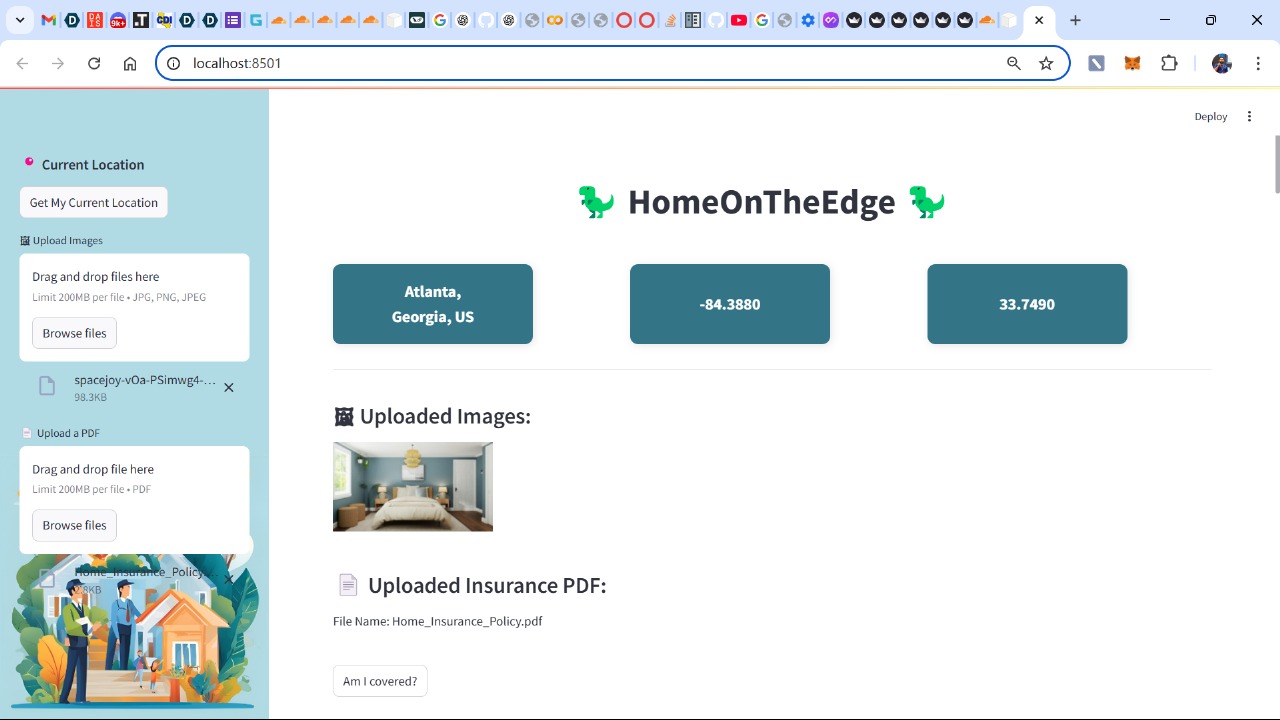
Upload document and location
-
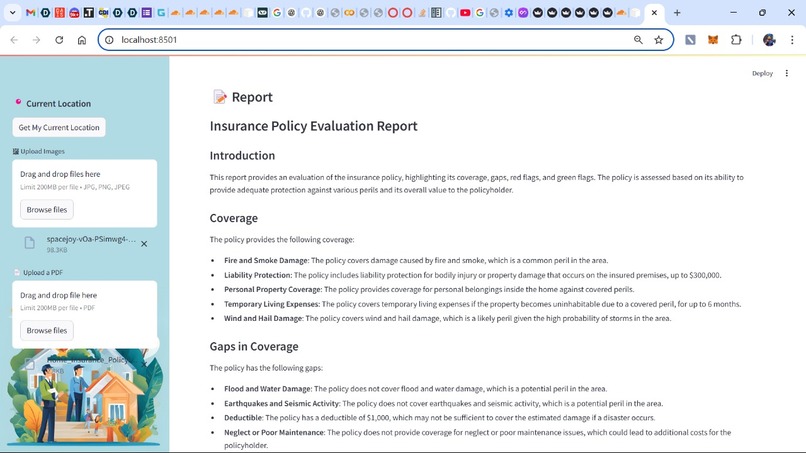
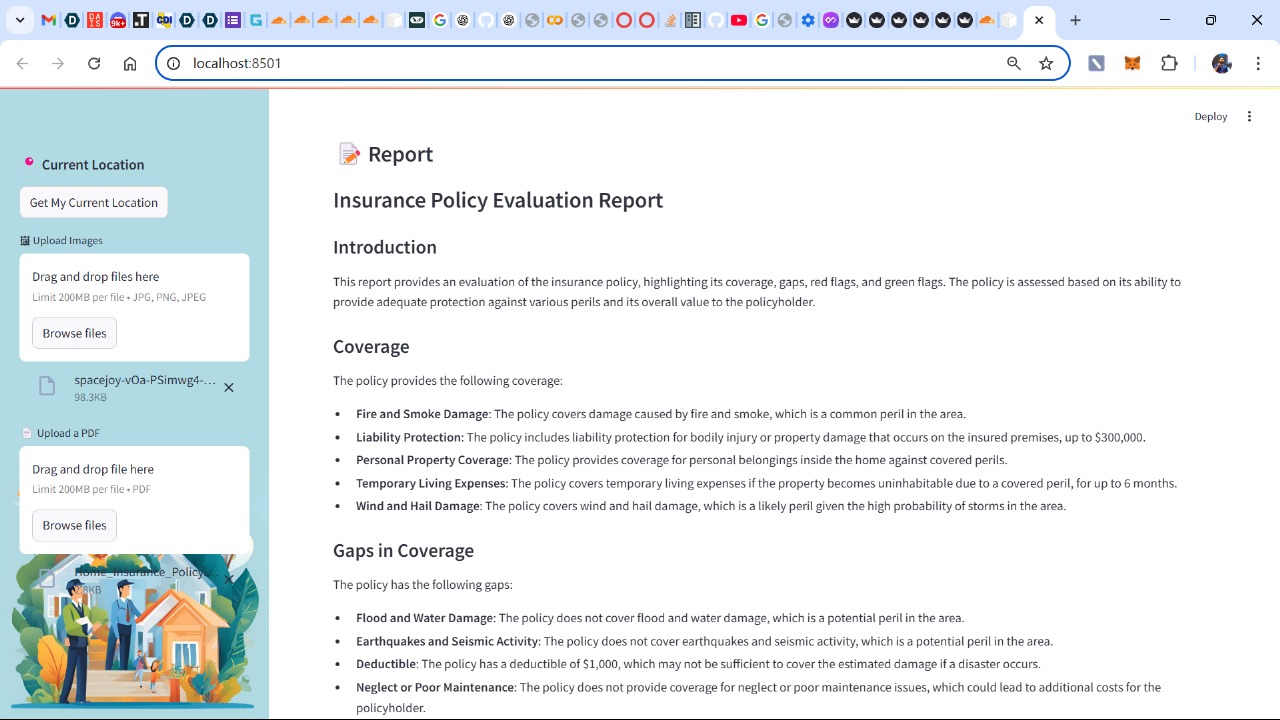
Generated Report
-
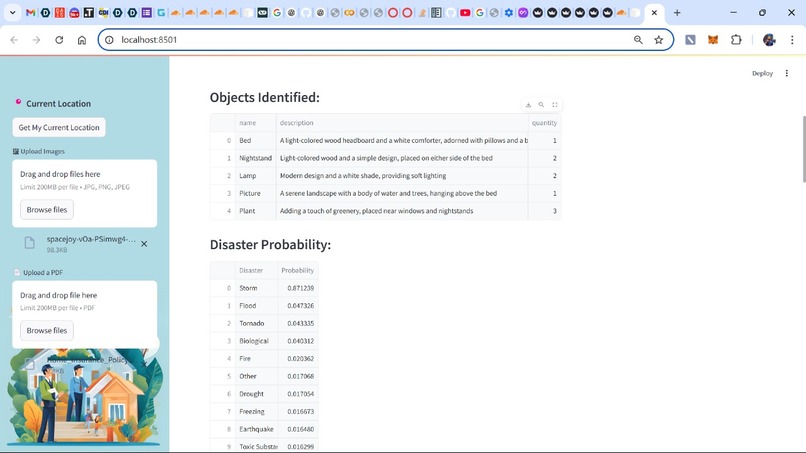
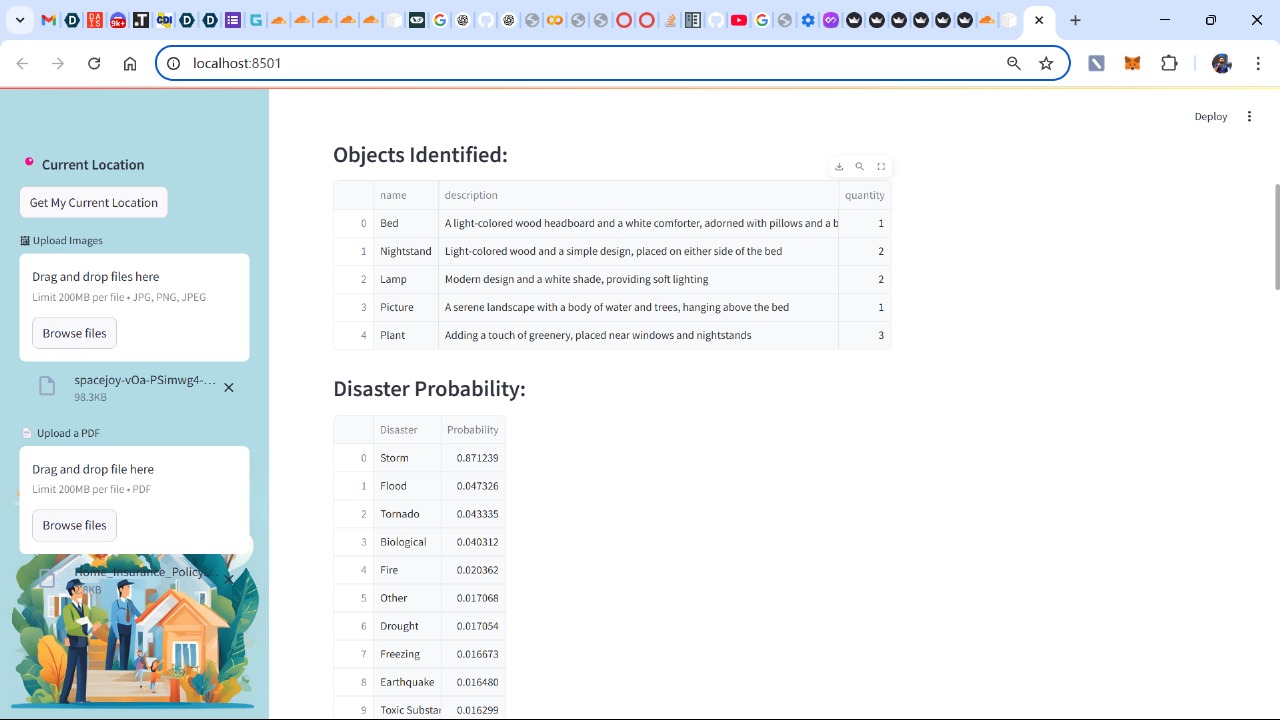
Object identification and price estimation
Inspiration
The inspiration behind our project is to simplify the insurance process for insurance companies and customers. While insurance is essential for financial protection, many people struggle to understand their policies—what is covered, how it works, and whether their coverage is sufficient. This confusion often leads to frustration, uncertainty, and even financial hardship in the event of a disaster.
One of the biggest challenges for insurance customers is navigating long and complex contracts. Many policyholders do not fully understand what their policy includes until they need to file a claim, at which point they may discover gaps in coverage. Our project aims to mitigate this issue by allowing customers to quickly assess their coverage and compare it to their actual risks in the context of natural disasters.
For insurance companies, risk assessment is crucial but time-consuming, requiring real-time tools for more efficient property evaluations. Our solution introduces machine learning models that assess the likelihood of natural disasters occurring at a location. This information can help insurers make more informed policy pricing and coverage decisions by giving them data on the amount of potential claims per household.
By leveraging technology, we aim to bridge the gap between policyholders and insurers, making insurance more transparent, efficient, and accessible for everyone.
What It Does
HomeOnTheEdge is a multi-agent, multi-modal graph-based solution architecture designed to simplify risk assessment and policy evaluation for both homeowners and insurance providers. It integrates machine learning, computer vision, and natural language processing (NLP) to provide real-time disaster risk predictions, financial loss estimations, and policy analysis.
Key functionalities
- Property Risk Analysis: Users upload property images, and our object detection model identifies personal property within these images and associates a cost with them using the Google search API.
- Disaster Probability Modeling: An XGBoost model evaluates the likelihood of natural disasters such as floods, earthquakes, and hurricanes at a given location based on weather features
- Loss Estimation: The system calculates potential financial losses by combining property data with disaster probability predictions.
- Policy Document Parsing: Using NLP-based extraction, the system scans PDF insurance policies, identifying coverage limits, deductibles, and exclusions based on the disaster probabilities generated earlier.
- Insurance Comparison: The system compares existing coverage with estimated risks and financial losses, highlighting coverage gaps or over-insurance.
- Comprehensive Report Generation: Users receive a detailed risk assessment report, summarizing disaster risks, financial exposure, and policy recommendations.
By automating these traditionally complex processes, HomeOnTheEdge makes insurance simpler, more transparent, and data-driven, helping homeowners make better-informed decisions.
How We Built It
Predicting Natural Disaster Risks
We trained a multi-label machine learning model to predict the probability of various disaster types, such as floods, tornadoes, and wildfires. To do this, we extracted data from a host of datasets such as the FEMA Disaster Summaries dataset as well as multiple APIs from the National Oceanic and Atmospheric Administration (NOAA). This included data such as the temperature, precipitation, latitude, longitude, month, year, etc related to past natural disasters. On preprocessing and merging these different datasets, we arrived at our final training set.
Using XGBoost, wrapped in a MultiOutputClassifier, we trained the model to recognize patterns in weather conditions that precede different types of disasters. This resulted in a AUC-ROC score of 0.9243, indicating that our classification was strong. We also had a 94.86% accuracy and an F1 score of 0.7270. Our final model outputs probabilities for multiple disaster types, providing a foundation for calculating expected losses and recommending insurance adjustments. We also tested Random Forests on the same data for a performance benchmark but found worse results.
In the end, our model isn’t just a technical accomplishment; it’s a tool that can cater to a wide range of applications, insurance loss prediction being only one of them. Our hope is that such data can also be used standalone for various different analytics processes and for generating insights.
Integrating Multimodal Models for Risk and Object Assessment
Now, we needed to extract key details from insurance policy documents, which presented a significant challenge due to the diverse formats of PDFs. The initial methodology proposed by Amazon Q relied on a structured approach using regular expressions to extract specific details. However, as we tested this method across different PDFs, it became clear that regex-based extraction was too rigid—small variations in formatting caused extraction failures, requiring constant manual adjustments.
After extensive debugging, we decided to incorporate multiple machine-learning models to analyze household risk. Our system now takes several user inputs—location, house images, and insurance policy details—and processes them using a combination of deep learning and statistical models.
Images of the household are analyzed using "@cf/meta/llama-3.2-11b-vision-instruct" , a multimodal visual model, which detects objects and estimates their values ("@cf/meta/llama-3-8b-instruct-awq"). Meanwhile, a separate llama-3 model instance ("@cf/meta/llama-3.3-70b-instruct-fp8-fast") assesses potential financial losses in disasters by considering the type and distribution of objects within the house. We integrated external disaster probability datasets, allowing us to evaluate risks based on historical data for specific regions.
By combining disaster probabilities, estimated object values, and expected financial losses, the system calculates a total estimated loss value for a given home using "@cf/meta/llama-3.1-70b-instruct". This is then compared against the insurance policy details to determine whether the coverage is sufficient, highlighting potential gaps in protection.
Developing an Interactive and Transparent User Interface
Finally, to make the system accessible and user-friendly, we designed an intuitive web application using Streamlit. The interface allows users to seamlessly upload their insurance documents, input their location, and submit house images for evaluation. Transparency was a key consideration, ensuring users could understand how the system arrived at its recommendations.
The UI presents disaster risk assessments in a structured, easy-to-read format, breaking down probability estimates, object valuations, and coverage gaps. A detailed table displays the items within the household, their potential risks, and their estimated values, making the analysis both informative and actionable. Finally, we generate a set of observations - including coverage, gaps, red flags, and green flags, and create a policy evaluation report.
Challenges We Ran Into
During development, we encountered several challenges, including:
- Integrating Multiple LLMs: Merging different large language models (LLMs) into a cohesive system was complex, requiring extensive fine-tuning and compatibility adjustments.
- Weather Data Issues: Finding reliable weather data was challenging, and inconsistencies in the API impacted the number of features we could use.
- Parsing Policy Documents: Extracting meaningful insights from unstructured insurance policy text was difficult due to the lack of training data.
- Limited Resources: We faced issues with not having enough food and lacking a marker for desk writing, which slowed down brainstorming sessions.
Despite these obstacles, we tackled each challenge through iterative improvements, debugging, and testing, ensuring our system functioned effectively.
Accomplishments That We're Proud Of
- Successfully integrating multiple AI models (computer vision, NLP, and predictive analytics) into a cohesive system.
- Building an intuitive and user-friendly interface for customers and insurance companies.
- Developing a disaster probability model that provides real-time risk predictions.
- Automating policy suggestions, making insurance analysis faster and more accessible.
What's Next for HomeOnTheEdge
Moving forward, we plan to:
- Expand disaster prediction capabilities by incorporating more granular climate data with paid API services
- Enhance policy parsing to extract finer details about exclusions and deductibles. Incorporate a threshold for minimum policy cost based on state laws
- Develop a mobile-friendly application to make our tool more accessible.
- Partner with insurance companies to integrate our technology into their risk assessment workflows.
Built With
- amazon-q
- amazon-web-services
- classifier
- cloudflare
- fema
- github
- graphllm
- json
- llama
- llm
- noaa-api
- ocr
- opencv
- python
- regexlib
- scikit-learn
- streamlit
- xgboost



Log in or sign up for Devpost to join the conversation.