-
-
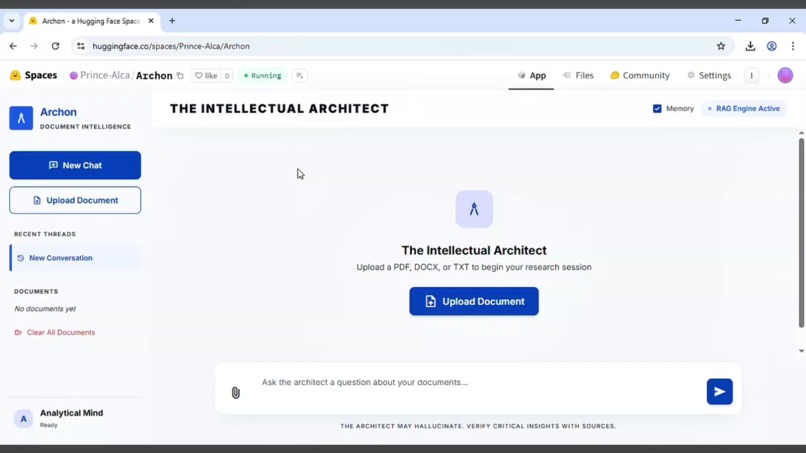
Archon Interface
Inspiration
I’ve always found that the bottleneck in research isn't a lack of information—it's the time spent manually digging through 30-page PDFs to find one specific data point. I wanted to build a tool that turns "reading" into a "conversation," allowing researchers and students to extract insights from dense documents in seconds rather than hours.
What it does
Archon is a document intelligence system that uses a RAG (Retrieval-Augmented Generation) pipeline to "read" and index uploaded PDFs. Unlike standard AI chatbots that might hallucinate, Archon strictly uses the provided document as its single source of truth. It provides: -Instant Summarization: Automatic insights as soon as a file is uploaded. -Citations & Sources: Every answer includes the specific text chunks and relevance scores used to generate it. -Conversation History: A persistent sidebar to track different research threads.
How we built it
The architecture is designed for speed and precision: -Frontend/Backend: Built with Flask and hosted on Hugging Face Spaces -Vector Database: ChromaDB handles the document embeddings and fast similarity searches. -LLM: Powered by LLaMA via Groq, ensuring near-instant response times. -Processing: Documents are chunked and embedded using sentence-transformers.
Challenges we ran into
One of the biggest hurdles was managing the retrieval accuracy. Initially, the model would occasionally pull irrelevant context if the chunks were too small. I had to fine-tune the chunking strategy and implement relevance scoring to ensure the AI only answered based on the most pertinent sections of the paper.
Accomplishments that we're proud of
I’m particularly proud of the latency. By leveraging Groq’s LLaMA inference, the "intelligence" feels snappy. I also managed to implement a source-citation feature that highlights exactly where the information came from, which is crucial for academic integrity.
What we learned
Building Archon taught me a lot about the nuances of RAG—specifically how critical the "retrieval" step is compared to the "generation" step. I also gained deeper experience in deploying containerized Python apps to Hugging Face.
What's next for Archon
The roadmap for Archon includes: -Multi-document querying: Comparing data across several PDFs at once. -OCR Integration: To allow the system to read scanned documents and images. -Exporting: Ability to export the Q&A thread as a research summary or bibliography.


Log in or sign up for Devpost to join the conversation.