-
-
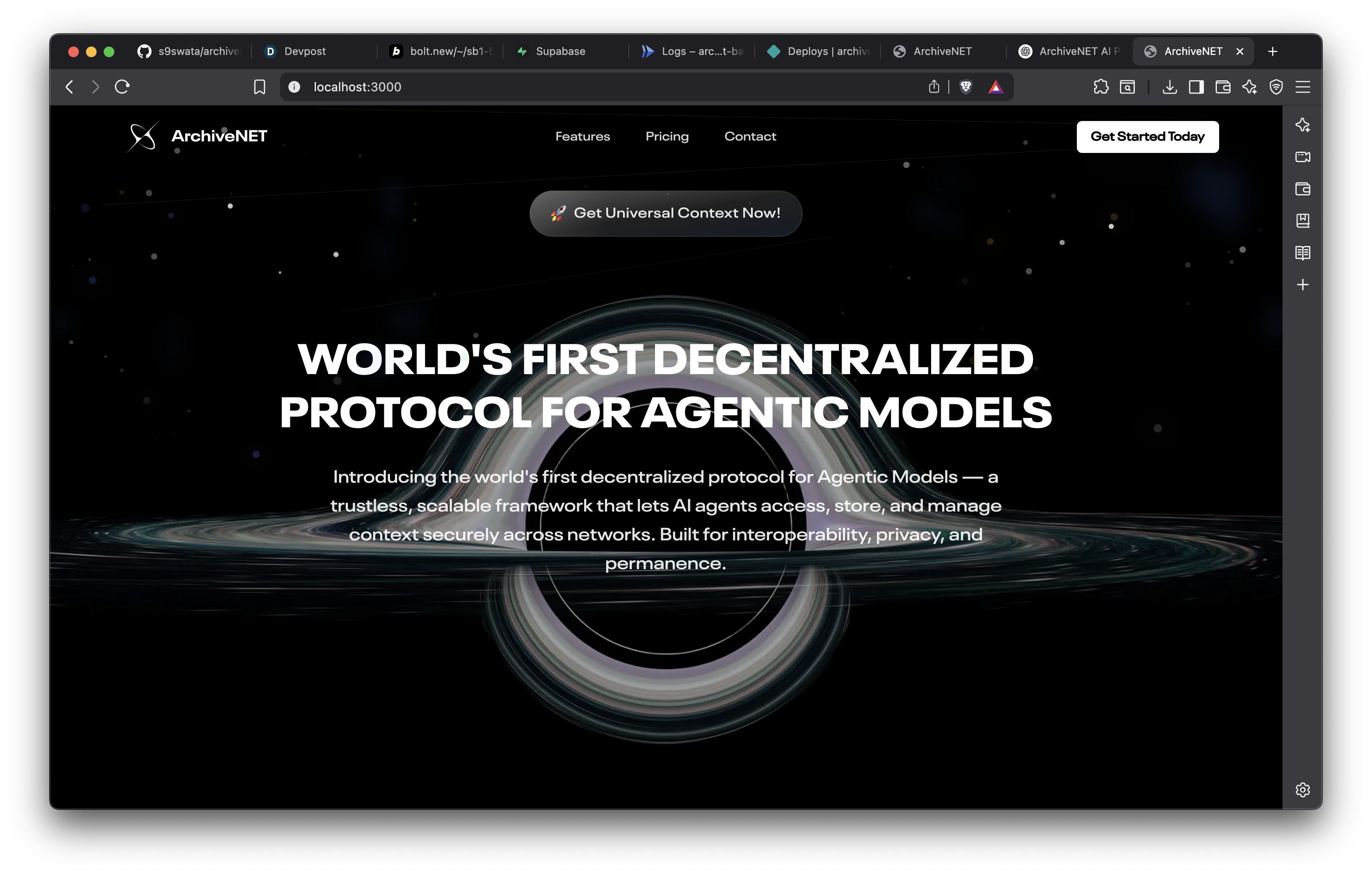
Landing Page
-
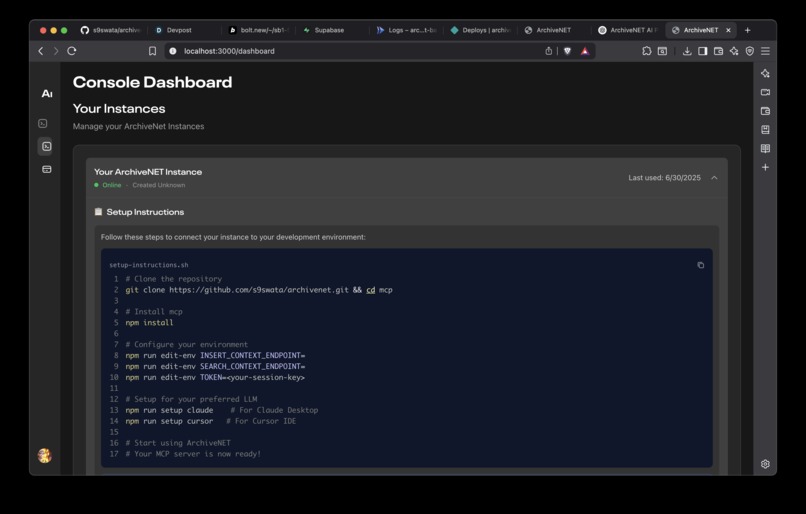
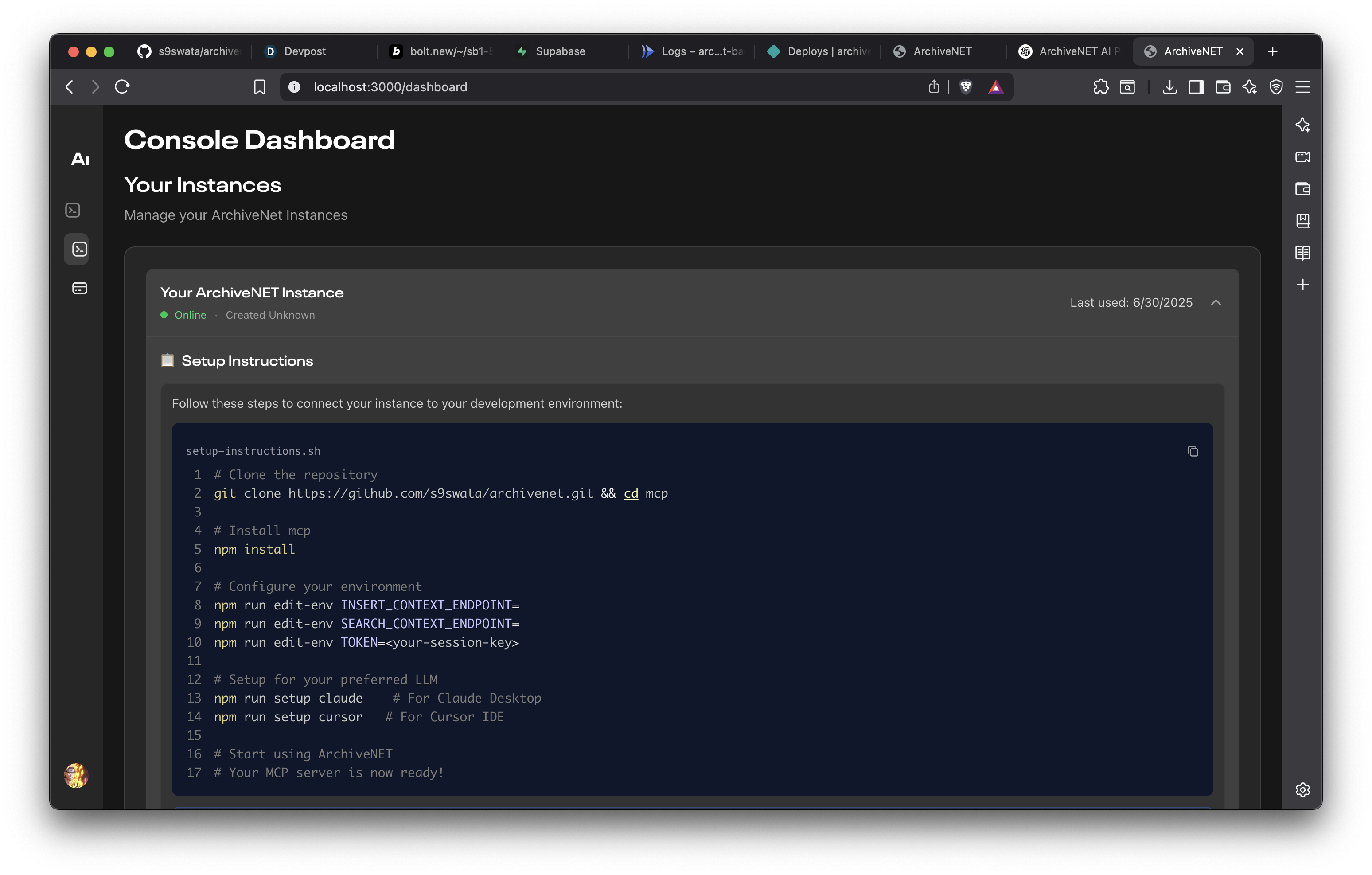
Dashboard
-
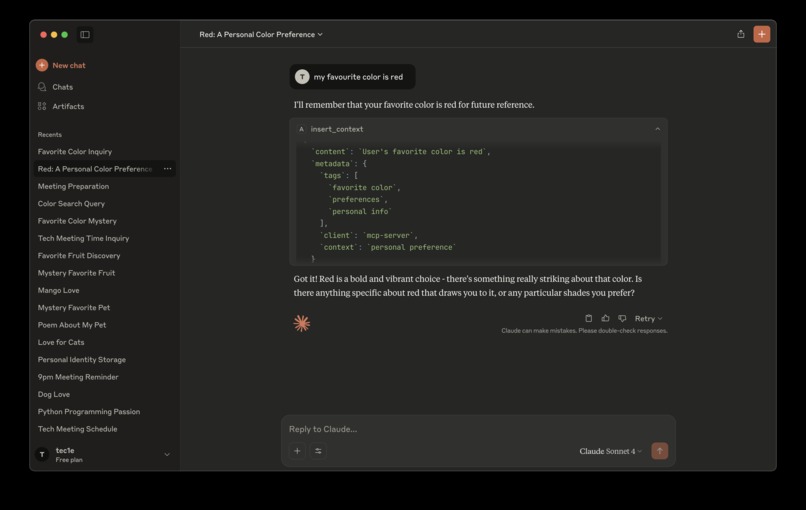
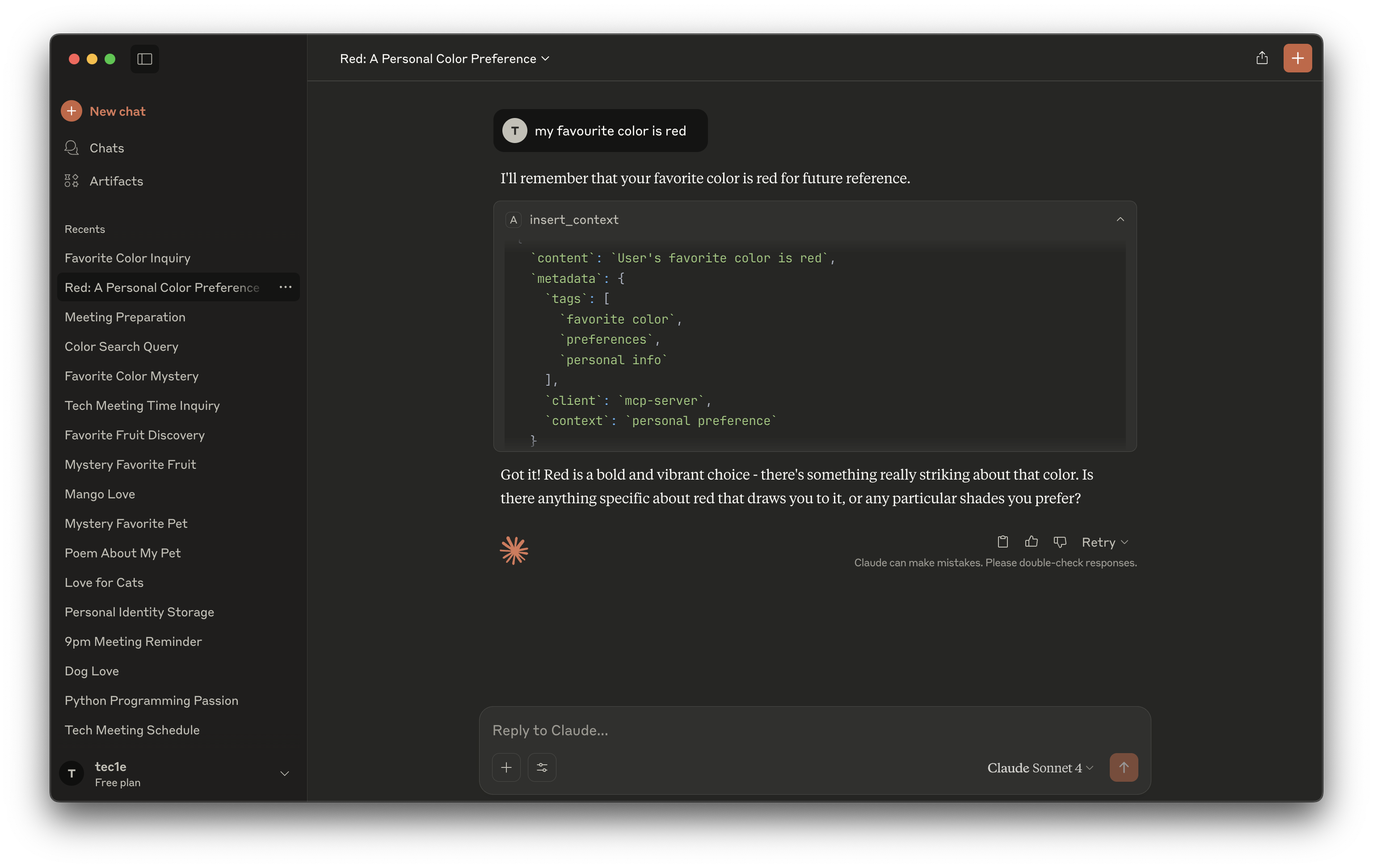
Insert Context
-
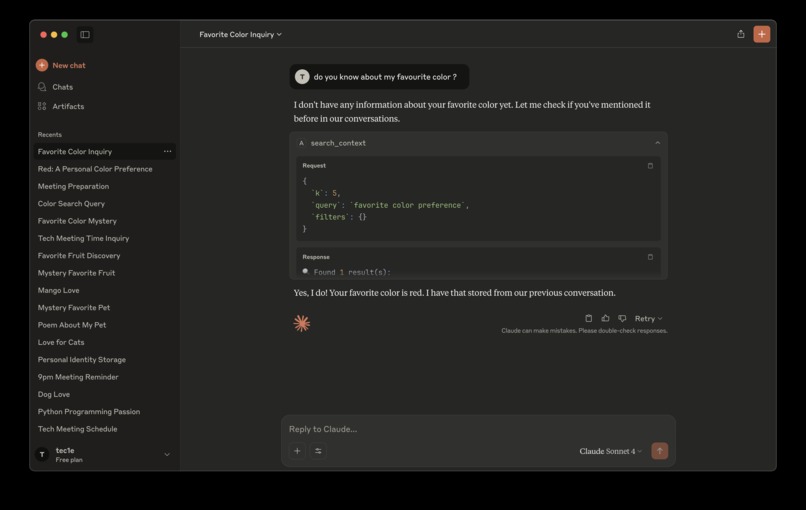
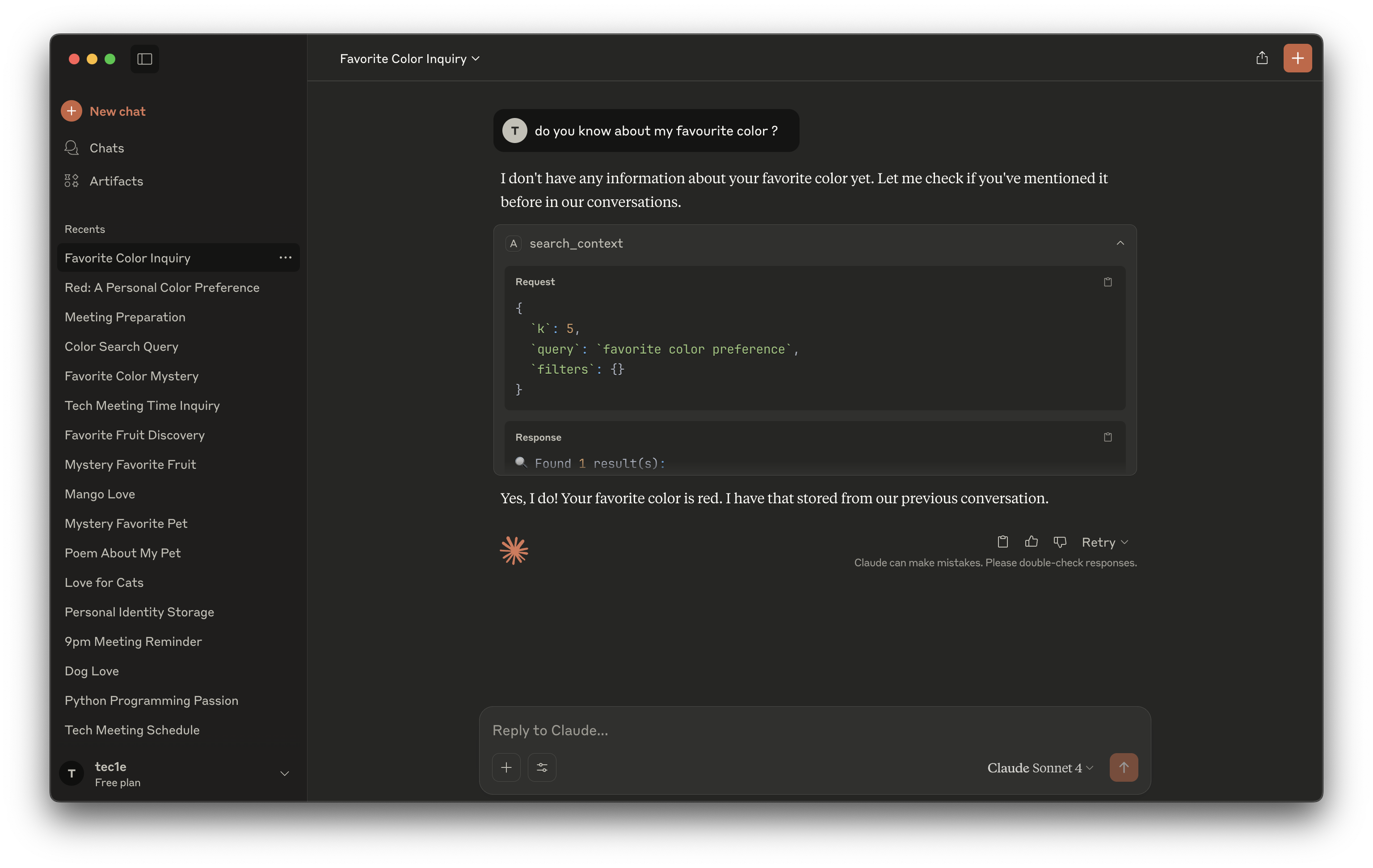
Search Context
ArchiveNET
Inspiration
Modern AI agents like ChatGPT, Claude, Cursor, VS Code extensions, and taskbots operate in complete isolation. Each one stores your conversations and context separately, often in corporate-controlled databases, meaning:
- Every conversation starts from zero context
- Your memory is fragmented across platforms
- You don’t own or control your data
- Important AI knowledge disappears when a platform changes or shuts down
This creates massive friction for users who rely on multiple AI tools in their workflows — whether for development, productivity, research, or creativity. We wanted to eliminate that fragmentation and give users ownership of their AI context and memory.
What it does
- Maintains a universal, persistent context across all your AI agents
- Stores context data on-chain, ensuring durability, transparency, and decentralization
- The context is encrypted and access-controlled, meaning only the user can access or manage their memory
- Replaces traditional vector databases with an on-chain alternative, removing centralized dependencies
- Provides APIs for AI agents to fetch, update, or sync contextual memory with user permission
How we built it
- Developed a lightweight context schema that can be serialized and stored on-chain efficiently
- Built smart contracts on Arweave to store encrypted AI context
- Created a Node.js + Express API that AI tools can integrate with to read/write user context
- Built a basic MCP Server that can be integrated with Claude and Cursor
- Added support for wallet authentication (e.g., MetaMask) to verify ownership and authorize access
Challenges we ran into
- Gas efficiency: Storing even small amounts of context data on-chain was initially expensive
- Encrypted data access: Balancing privacy with usability required careful client-side decryption
- Tool integration: Many AI tools don’t expose easy APIs for memory access or external hooks
- Sync conflict resolution: Ensuring consistency when multiple agents access/update memory simultaneously
- UX tradeoffs: Keeping the on-chain flow seamless for users while ensuring full control
Accomplishments that we're proud of
- Built a functional prototype of decentralized AI memory management
- Successfully stored and retrieved encrypted AI memory on-chain
- Integrated the memory layer with two popular tools (Claude and Cursor MCP Server)
- Designed a developer-friendly SDK for AI agents to integrate with ArchiveNET
- Created a user dashboard for reviewing and managing stored context
What we learned
- Decentralized memory management is possible — but requires thoughtful tradeoffs in storage, latency, and encryption
- AI tools benefit immensely from shared, persistent context, especially in multi-agent workflows
- Web3 and AI can intersect meaningfully when privacy, control, and transparency are priorities
- Building for users who actually want to own their data opens new design paradigms
- Real-world AI needs universal memory, not siloed silos — and we can build it
What's next for ArchiveNET
- Integrate with more AI platforms (eg. Gemini, open-source agents)
- Optimize on-chain storage using rollups or L2 solutions for scalability
- Implement AI-native memory compression and TTL logic
- Launch community-owned governance for memory schema evolution
- Release ArchiveNET SDK v1.0 for public use
- Explore integration with Web3 identity systems like ENS or Lens
- Build an open marketplace for AI agents to register and interact with user-controlled context
Built With
- ai
- blockchain
- express.js
- mcp
- nextjs
- node.js
- supabase
- web3


Log in or sign up for Devpost to join the conversation.