-
Archived Landing Page
-
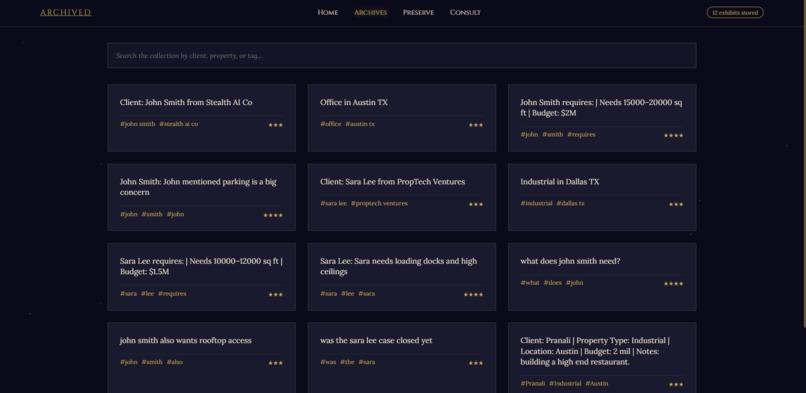
Search through archives
-
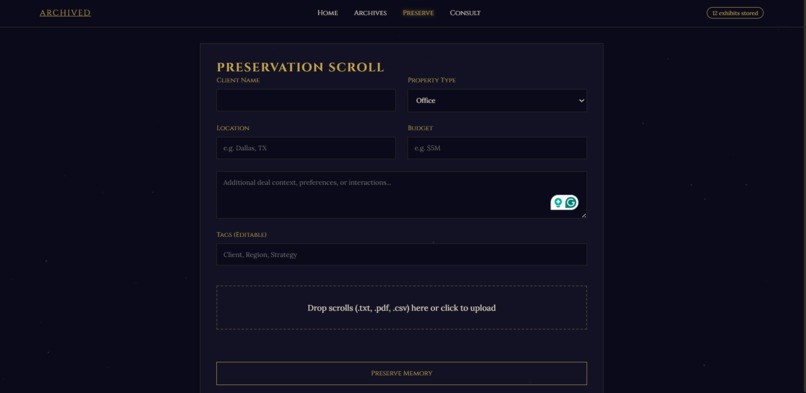
Ingest data into database
-
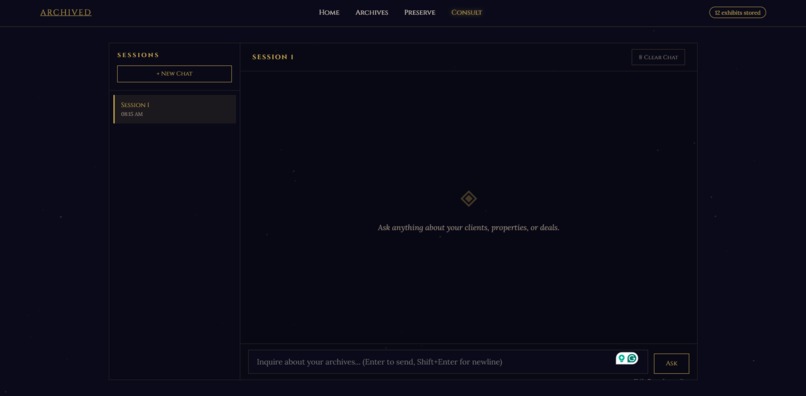
Consult with LLM
Inspiration
As frequent LLM users, we noticed a major limitation: conversations are easily forgotten. Important details from earlier interactions disappear, making it difficult to build on past context or complete complex, multi-step tasks. This became especially relevant in the context of the CBRE challenge, where maintaining long-term, structured knowledge is critical.
What it does
Archived is an AI-powered memory system designed for commercial real estate agents that preserves and recalls important information over time. Instead of losing past interactions, Archived stores them as connected pieces of information (like clients, properties, and requirements) so the AI can understand relationships, track history, and answer questions using relevant past context. In simple terms, it transforms AI from something that forgets into something that remembers.
How we built it
We built Archived using:
- a FastAPI backend
- a MongoDB database
- the Gemini API for embeddings and reasoning
At a high level:
- User inputs (forms, chat, files) are processed and stored as structured "memory nodes."
- Each node is embedded using the Gemini API to capture semantic meaning as vectors.
- Nodes are connected based on a similarity metric
- When a query is made:
- relevant nodes are retrieved
- a contextual prompt is constructed
- Gemini generates a response using that structured memory Instead of sending raw conversation history, we dynamically build context based on relevance.
At the core of Archived is a 5-step AI agent pipeline that manages how information is stored, connected, and retrieved:
- Ingestion – Incoming data (user input, forms, files) is parsed and converted into structured memory nodes with metadata.
- Organization – Newly created nodes are connected to existing nodes based on semantic similarity, forming a memory graph.
- Retrieval – When a query is made, the system searches the graph to find the most relevant nodes, prioritizing recent and important information.
- Reasoning – A contextual prompt is dynamically constructed from the retrieved nodes and sent to Gemini to generate a grounded response.
- Evolution – The system updates memory by reinforcing frequently used nodes, adjusting importance, and refining connections over time.
This pipeline allows Archived to move beyond static storage and instead behave like a dynamic, evolving memory system.
What Makes Archived Unique
Archived doesn't just store memory but rather it thinks with it. Most AI tools pass raw conversation history into a context window and hope for the best, Archived runs every query through a deliberate 5-step multi-agent pipeline: Ingestion, Organization, Retrieval, Reasoning, and Evolution. Each agent has one job, does it well, and hands off cleanly to the next. Our modularity is intentional and every step is independently tuneable, meaning we can improve retrieval without touching reasoning, or swap embedding models without rebuilding the graph. The system was designed to get smarter over time, not just at demo time.
The memory graph itself is what separates us. When an agent asks "what does Client Z want?", Archived doesn't summarize recent chat; instead, it traverses a typed graph of CLIENT, PROPERTY, REQUIREMENT, INTERACTION, and DEAL nodes, identifies the seed memory, rewrites the query with that context, pulls connected nodes one hop out, and sends a grounded, sourced prompt to Gemini. The answer cites exactly which memory nodes it drew from. No hallucination. No repetition. No forgetting.
We also built for how people actually work. Nobody types structured data. They talk, they upload PDFs, they drop in CSV exports from their CRM. Archived handles all of it, chunking and classifying documents automatically so nothing slips through. And because the Evolution agent reinforces frequently retrieved nodes and decays stale ones, the system naturally surfaces what matters most right now without you ever having to manage it.
Challenges we ran into
Our biggest challenge was designing the AI agent pipeline. We knew we wanted a multi-step process to allow for modularity, but we weren’t sure where to start. After speaking with CBRE representatives, we realized it would be easier to create the pipeline if we defined a use case.
Once we defined the use case, it became much clearer:
- how to structure the data
- how to store relationships
- how the system should “learn” over time
Beyond the high-level design, we ran into more practical challenges. This was our first time integrating APIs , so getting everything to communicate correctly took trial and error. We also had to learn how to properly collaborate using Git, which led to a few merge conflicts but we resolved them slowly but surely.
While we felt confident in designing the system conceptually, we ran into many smaller syntax and semantic issues during implementation. Debugging these issues and getting all the components to work together was a major part of the development process.
Accomplishments that we're proud of
We’re proud of designing a custom data structure for memory storage and building a full 5-step agent pipeline from scratch. More importantly, we created a complete end-to-end system that actually works. Turning an initially vague idea into a functional product was a huge accomplishment. And highkey just finishing the project. We were pretty lost early on, and having something to submit is a win.
What we learned
As ECE majors, this was our first time in-depth with LLM backends. Through this experience, we learned why LLMs forget (context window limits), how prompting affects performance, and how current-day retrieval systems like RAG work. After understanding what current-day systems look like, we thought about instead of relying on static context windows, we could: dynamically construct context using structured memory. Our design and thought process was influenced by concepts we learned in our software design class (graphs, trees, efficient retrieval), and it was really cool to apply these concepts to a foreign field.
What's next for Archived
Right now Archived is purpose-built for commercial real estate. But the architecture was never meant to stay there. The same pipeline (typed nodes, graph connections, importance-weighted retrieval, modular agents ) can be pointed at any domain. The next step is multiple named archives, each with specialized memory spaces for different industries or workflows, all running on the same underlying engine. We built the foundation, but the ceiling is much higher.

Log in or sign up for Devpost to join the conversation.