-
-
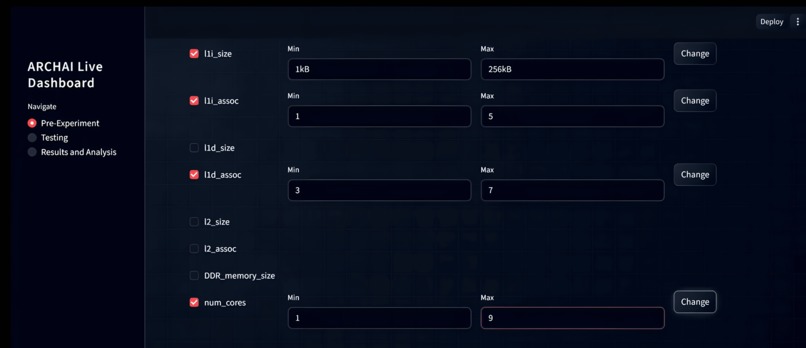
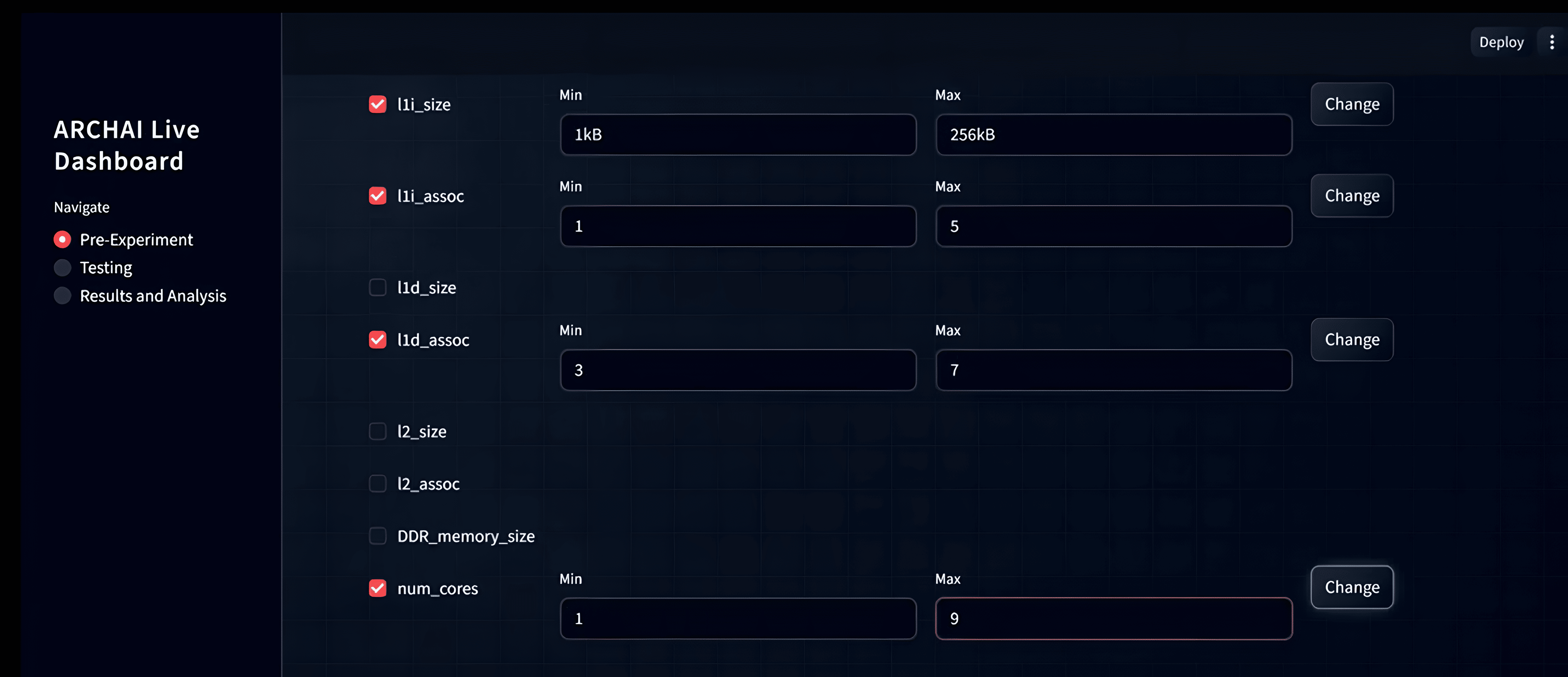
Streamlit front-end where the user can specify ranges to vary parameters, like cache size, associativity, and number of virtual cores.
-
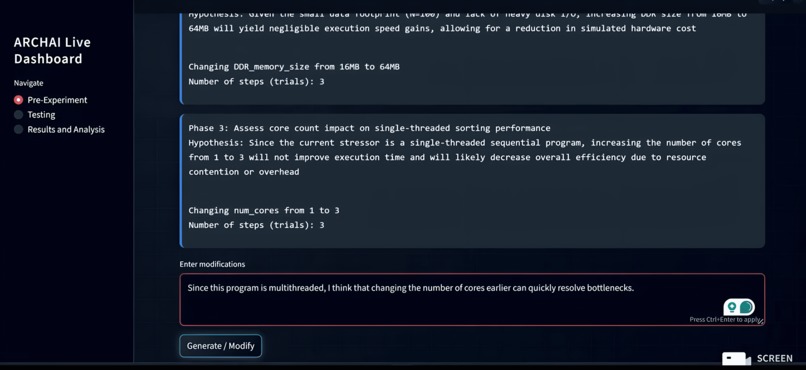
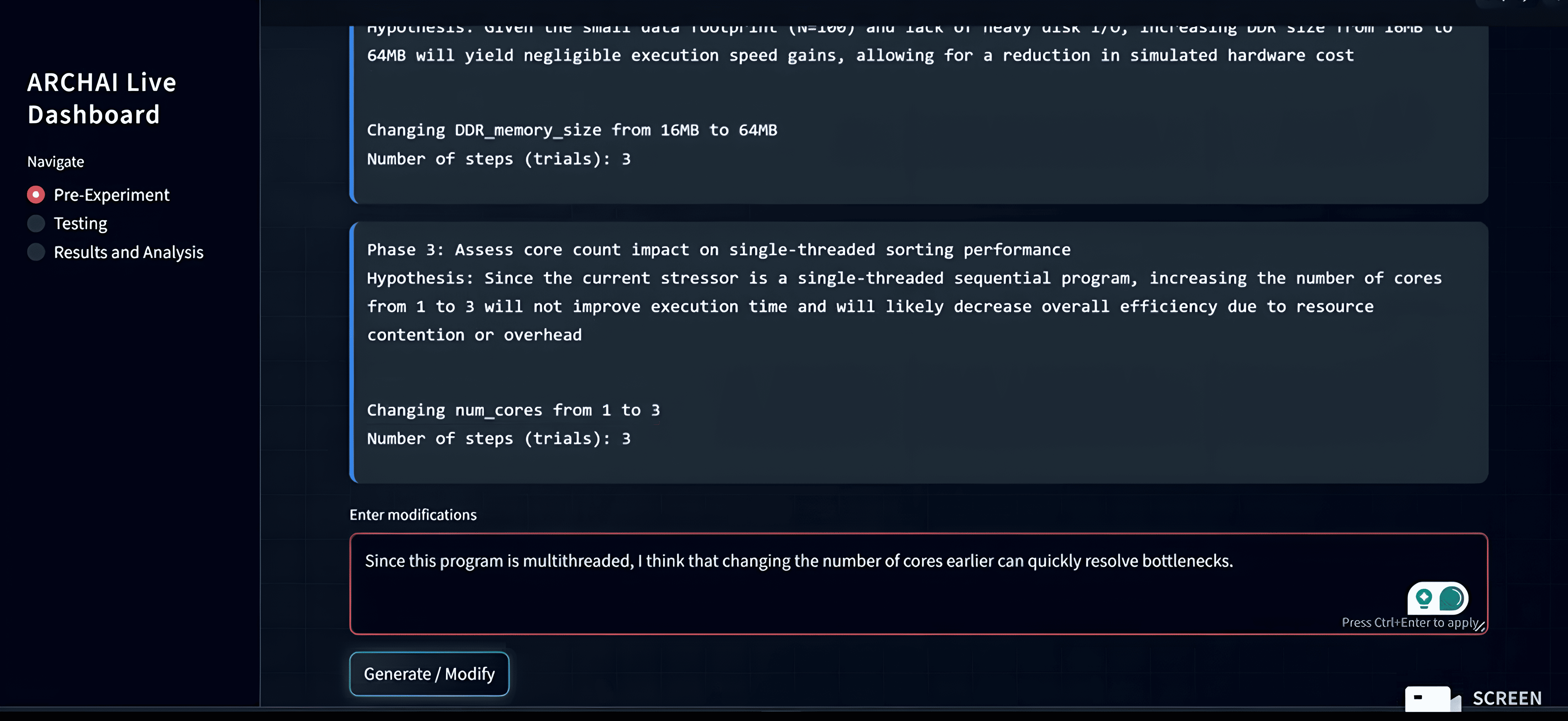
An experimental outline generated by Gemini 3, structured into phases that tackle smaller subgoals. The human researcher can prompt changes.
-
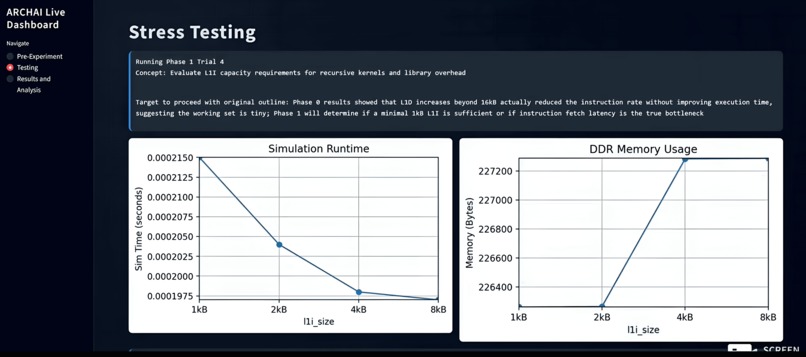
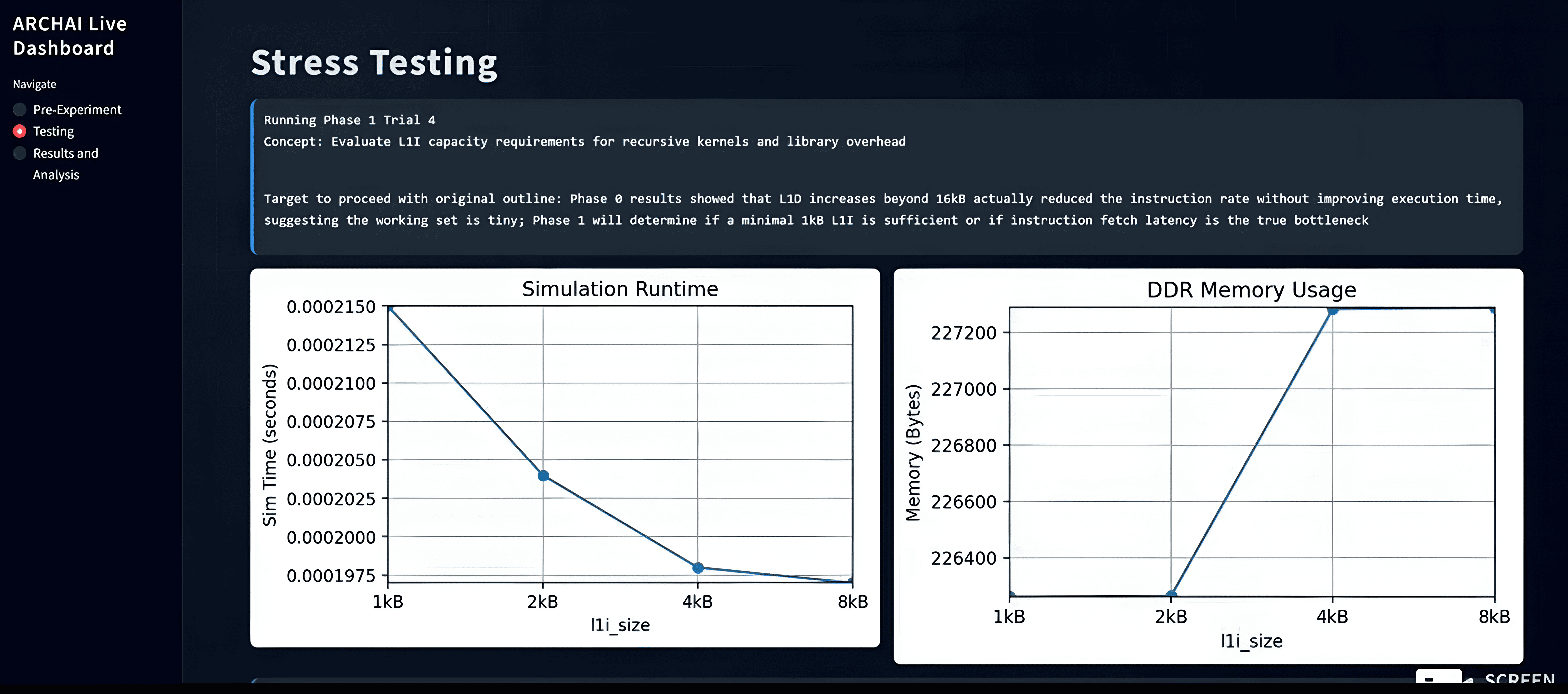
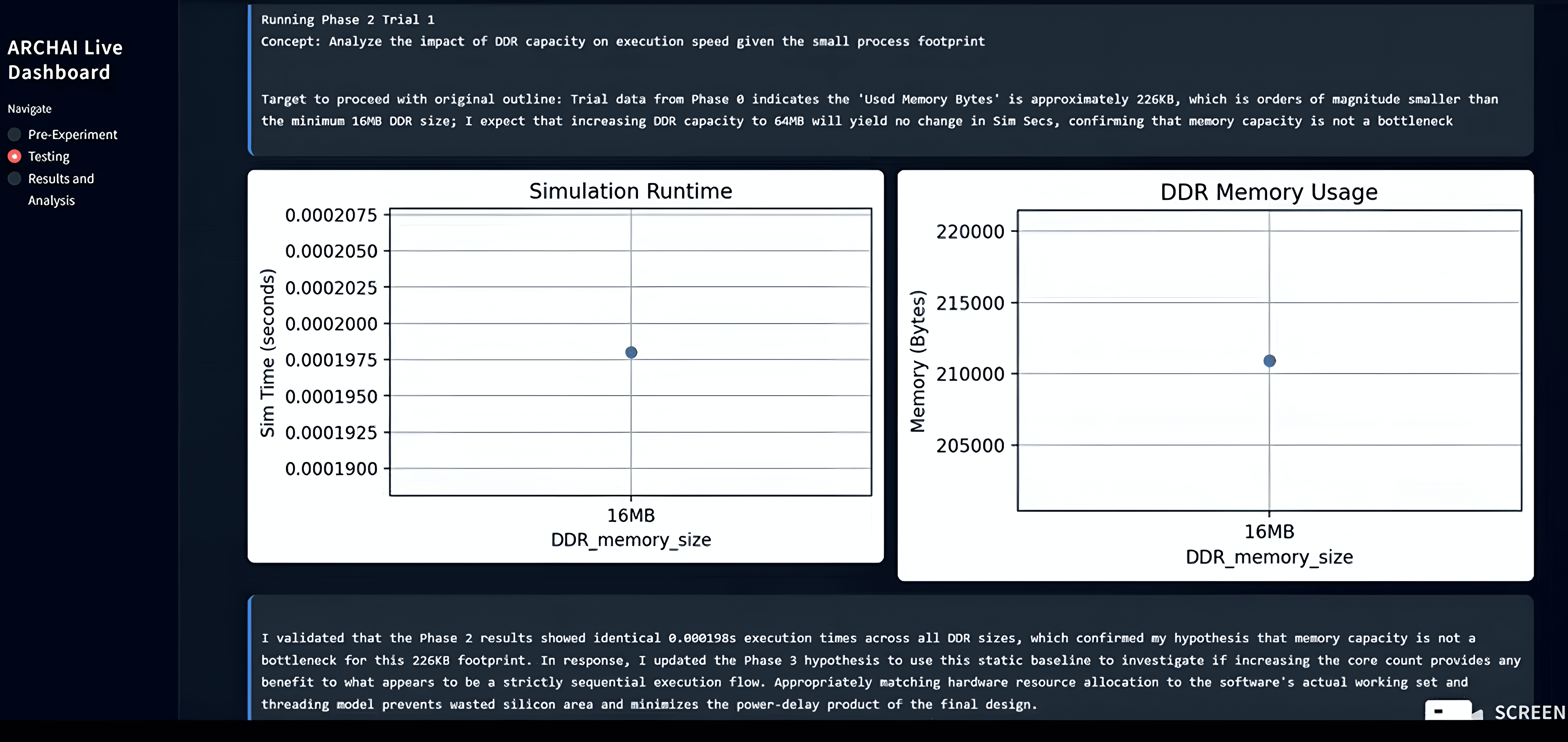
Testing involves running trials through Gemini 3 Flash's function calling. Metrics like execution speed and memory are plotted in real-time
-
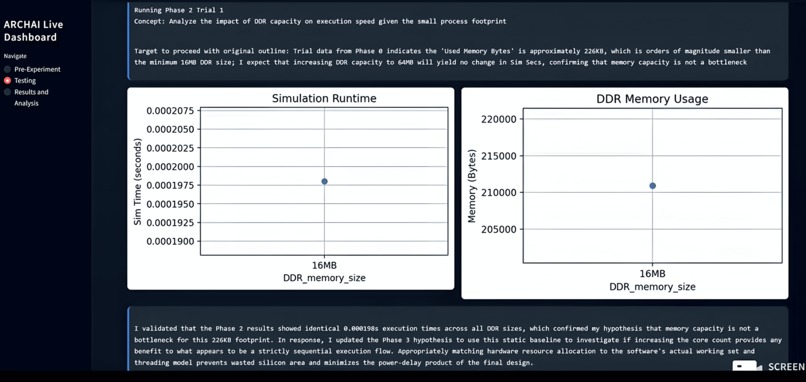
Trial results are extracted from log documents and Gemini 3 evaluates its hypothesis validity, dynamically making outline changes.
-

A full markdown report generated by Gemini 3 Flash model shows an analysis of bottlenecks, and suggests ideas for extending the experiment.
-
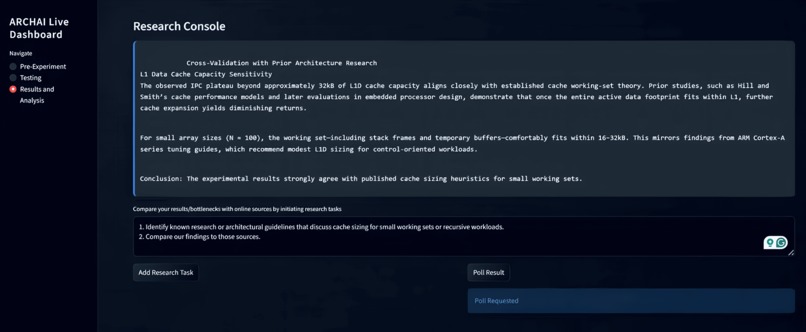
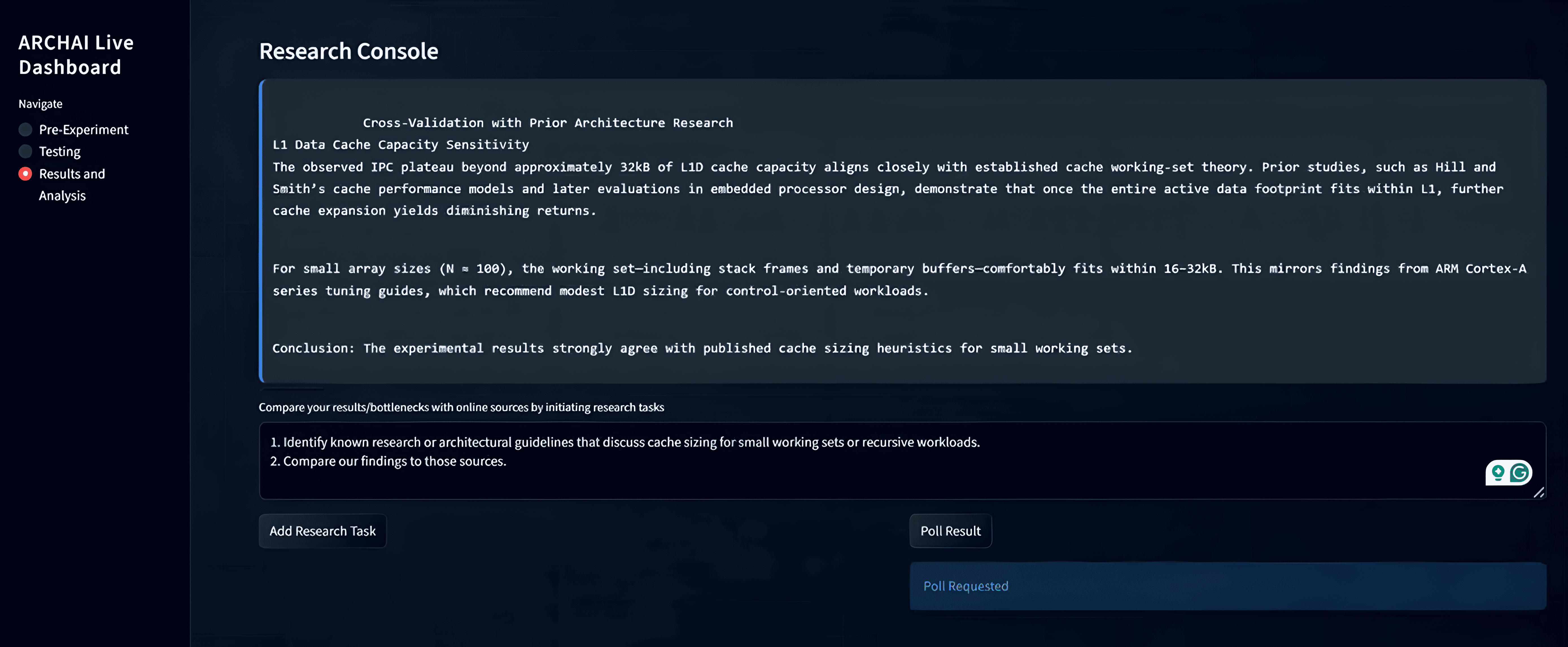
The Deep Research model can search for relevant, technical, online sources to compare the conclusions of the experiment in broader context.

Gemini 3 Features
ARCHAI leverages multiple Gemini 3 capabilities to autonomously orchestrate pre-silicon computer architecture exploration using the gem5 simulator. Gemini 3 Flash is used as the core reasoning engine to decompose a high-level optimization objective into a structured outline of experimental phases, each with a clear subgoal, a testable performance hypothesis, and a focused set of microarchitectural parameters to explore. Rather than performing static parameter sweeps, Gemini generates logically motivated hypotheses and evaluates them by extracting and analyzing performance metrics directly from gem5 log outputs after each trial.
The system uses Gemini’s structured output capabilities to emit machine-readable JSON updates that modify architectural parameters, experiment configurations, and phase progression. Through function calling, Gemini directly triggers compilation of C stressor programs, launches gem5 simulations, and collects statistics such as simulation time and memory usage. After each phase, Gemini compares observed results against its hypothesis, determines whether the hypothesis was satisfied, and dynamically refines subsequent phases based on empirical evidence.
ARCHAI also integrates natural-language intervention, allowing a human researcher to prompt Gemini during runtime to modify the experiment outline, reorder phases, or pursue observed trends—while Gemini explains its reasoning behind each change. Model embeddings are stored and reloaded to preserve experimental context across long-running sessions. Finally, Gemini’s Deep Research model enables long-form research tasks that compare simulation findings against existing online, academic sources, grounding results in prior work and strengthening architectural conclusions.
Insights into Computer Architecture
Through ARCHAI’s adaptive experimentation, I gained concrete experience in how real workloads interact with microarchitectural design choices. The results demonstrated clear diminishing returns in cache capacity once the working set fit entirely within L1, while instruction cache behavior stabilized much earlier due to compact control flow. Associativity proved more impactful than raw cache size for reducing conflict misses in recursive kernels, and scaling core counts provided limited benefit for small, cache-bound workloads. These findings reinforce the importance of right-sizing architectural components rather than over-provisioning, especially in embedded and energy-constrained systems. Overall, the project highlights how workload-aware, hypothesis-driven exploration can reveal subtle performance bottlenecks that static sweeps often miss.
Challenges Faced
One major challenge was the gem5 simulator itself, which requires a long build time of roughly 30–40 minutes on AI Studio. To iterate efficiently, I containerized the environment using Docker, pre-baked the simulator into an image, and published it to GitHub Container Registry (GHCR), enabling fast, reproducible experimentation as the process now only requires 1-2 minutes.
What's Next?
Next, I plan to push ARCHAI deeper into core computer architecture research by exploring advanced mechanisms such as designing and tuning custom hardware prefetchers. Beyond microarchitectural parameter tuning, I also want to extend the framework to operate at a lower abstraction layer, integrating RTL and Verilog-level designs I’m learning in ECE at UT Austin, enabling end-to-end experimentation from hardware description to architectural evaluation.
Built With
- docker
- gem5
- gemini3
- ghcr
- streamlit
- vscode

Log in or sign up for Devpost to join the conversation.