-
-
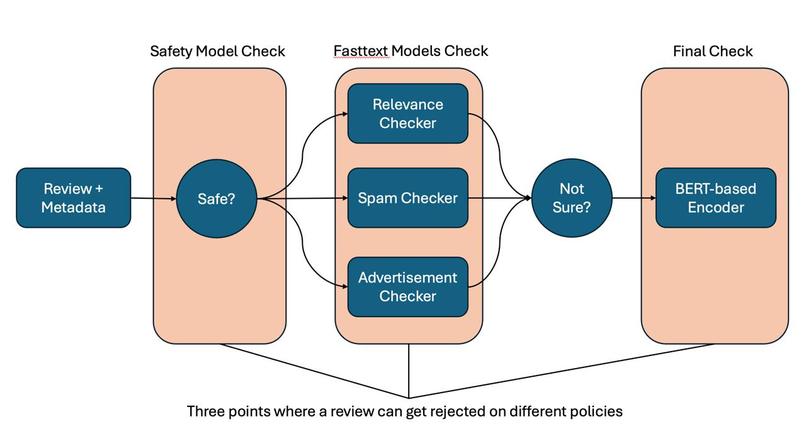
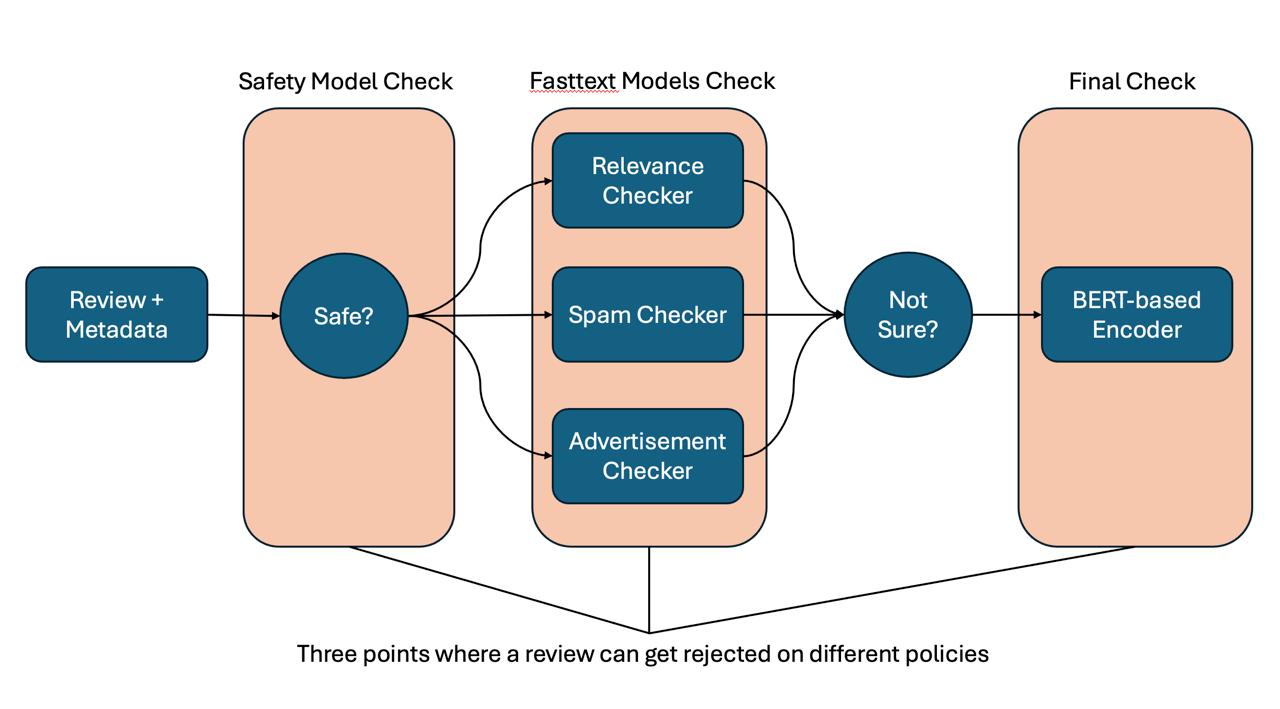
Flowchart for our Pipeline
Problem Statement
The problem we address is the widespread presence of unsafe, irrelevant, and low-quality content in Google Maps reviews. Such content reduces the reliability of reviews for users and can unfairly harm businesses. Our task is to automatically detect and flag these low-quality reviews based on their text content and associated business metadata.
What it does
ARC was designed to be a (relatively) lightweight and efficient automated review checker, which evaluates reviews upon submission, on the basis of safety and quality. We decided to add safety checks on top of the policies recommended in the problem statement as we feared the potential of review platforms, not just Google Maps, from becoming toxic places were users and businesses do not feel safe.
Therefore, at each stage of our machine learning pipeline, we check for safety to ensure our quality checks are as robust as possible.
The inference pipeline classifies reviews into the following low-quality categories:
- Advertisement – reviews that promote other businesses, include discounts/codes, or list unrelated contact info.
- Irrelevant – off-topic posts (personal stories, hobbies, news, etc.) with no link to the business.
- Toxic Rant – hostile, abusive, or threatening language toward staff, management or other users.
- Non-Visitor Rant – second-hand complaints (“I heard…”, “someone told me…”) lacking firsthand experience.
Features and Functionality
- Automatic detection of spam, irrelevant, and toxic reviews.
- Metadata integration (shop description, category, name) to provide richer context for classification.
- Multi-label classification so reviews can trigger multiple categories if applicable.
- Real-time inference pipeline that flags reviews at submission time.
- Improved trust in location-based review platforms by ensuring only relevant, high-quality content remains visible.
How we built it
We developed this project in Python, and structured the pipeline in 3 main stages: an initial safety check using Logistic Regression, a multi-policy check using multiple fastText heads, and a final stage BERT encoder, which was fine-tuned using Supervised Fine-Tuning (SFT), ensuring efficiency through adjusting LoRA weights.
As a single review passes through these pipeline stages, failure at any one of them would result in the review being rejected, and as a consequence, not posted. By passing the review through the pipeline sequentially and in order of increasing time and cost complexity, we save on resources. For example, if a review does not pass at the initial safety check, it never makes it to the fastText heads.
In this way, we can also be reasonably assured that if a review makes it past minimally the initial safety check and the fastText heads, it is probably acceptable. If fastText cannot come to a more definitive conclusion, then our BERT encoder steps in to do a more robust check.
Challenges we ran into
The biggest challenge was obtaining quality data. We had to pool lots of data from various source and generate labelled examples to assist with training, which meant more cleaning, more preprocessing, more pandas.
Accomplishments that we're proud of
- Model performance: while there is no concrete metric for review "quality", we did our own manual experimentation with the pipeline (see more in the example video), and we are quite happy with how robust the pipeline is.
- Speed: we are very happy with how we were able to keep the overall model pipeline lightweight and fast on inference, which is key to ensuring that the user experience is smooth and enjoyable. No one wants to wait a long time for their review to get accepted and posted online.
What we learned
- Finding quality data is difficult, and synthetic data generation needs to be done carefully, with curated prompts and prompt engineering techniques like few-shot, chain-of-thought, etc. The biggest problem with synthetic data is that it often creates very recognisable patterns.
- Model performance on reviews that are "on the boundary": the pipeline still somtimes struggles on texts that could be rude but aren't. In addition, labelling is very difficult to get right, the current high metrics we have are likely due to the imbalance for each class, which we have tried to account for as much as possible. Our models get rewarded for being conservative in predictions.
What's next for ARC - Automated Review Checking with Machine Learning
We plan to do a deeper dive into how we can improve the model's robustness to ambiguous reviews, and perhaps to integrate it with external APIs like the Google Maps API, allowing us to process real reviews in real-time.
Development Tools
- Visual Studio Code
- Neovim
Assets and Datasets
- Google Local Reviews dataset (New York State)
- Twitter Toxic Comments Dataset
- Toxigen Dataset (please see links in our repo’s main README for the citations and links)
Built With
- bert
- fastapi
- fasttext
- gemini
- huggingface
- openai
- pandas
- peft
- python
- pytorch
- scikit-learn
- streamlit










Log in or sign up for Devpost to join the conversation.