-
-
Login Window
-
Dashboard
-
Register New Case
-
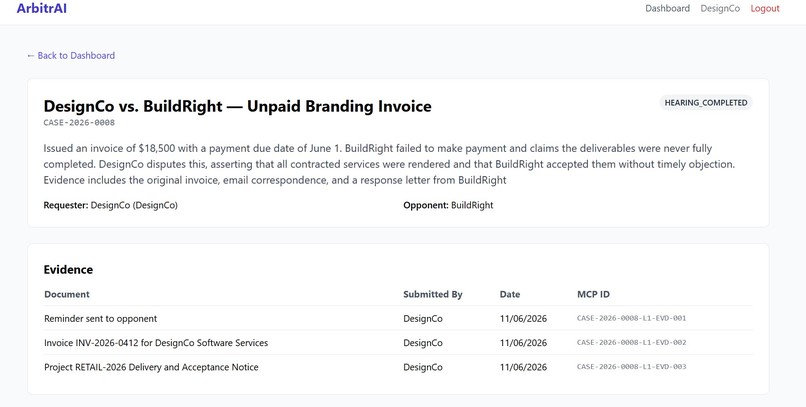
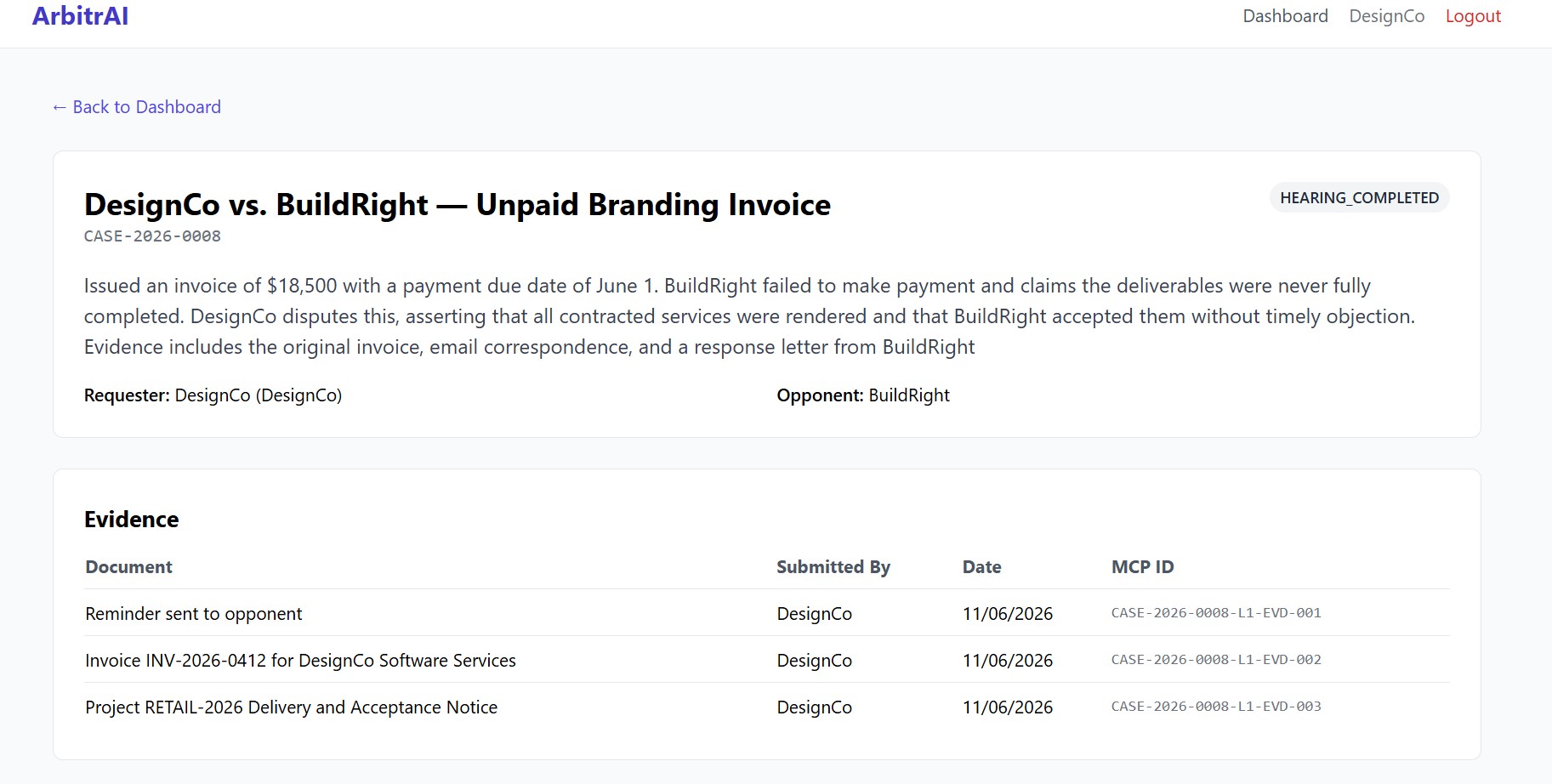
Submitted Evidences
-

Hearing
-

Desicion


ArbitrAI — Hackathon Submission
Google "Building Agents for Real-World Challenges" — MongoDB Partner Track
Inspiration
One point five billion people worldwide face an unmet civil justice need. A single commercial lawsuit costs small businesses an average of $91,000 in legal fees and takes two to three years to resolve. Yet the CPR Institute finds that 85% of disputes that reach mediation — settle.
The bottleneck isn't resolution. It's access. The mediation process is too slow, too expensive, and too intimidating for most small businesses to navigate alone.
We asked: what if AI could make structured, evidence-based mediation available to anyone — at a fraction of the cost and time? That question became ArbitrAI.
What it does
ArbitrAI is an AI-powered commercial dispute mediation platform. Each party gets their own AI lawyer agent that reads their evidence, builds legal arguments, and advocates for them in a structured hearing. A neutral AI mediator listens to both sides, weighs the evidence, and delivers a settlement recommendation grounded in real documents and real legal principles.
The end-to-end flow:
- Register — The claimant opens a case and invites the opposing party by email.
- Evidence Upload — Each party uploads documents (invoices, emails, contracts). Gemini Vision reads every PDF automatically — no manual transcription needed.
- Pre-Hearing Consultation — Each party chats privately with their AI lawyer to clarify their documents and build their case.
- The Hearing — An 8-step automated hearing runs:
- Mediator opens the session
- Lawyer A presents opening argument (citing uploaded evidence + legal references)
- Lawyer B presents opening argument (reads the transcript, responds accordingly)
- Lawyer A delivers rebuttal
- Lawyer B delivers rebuttal
- Mediator reviews all arguments and evidence; may ask clarifying questions directly to the human parties
- Mediator delivers settlement recommendation (with settlement range, key evidence cited, legal principles applied)
- Case status set to DECIDED — both parties notified by email
- Decision Record — The full transcript and recommendation are stored in MongoDB. Both parties can review the outcome.
Each hearing step produces real-time messages, and each spoken message is also synthesized into audio via Google Cloud Text-to-Speech.
How we built it
AI Agents — Google ADK + Gemini 3
All three agents (lawyer_a, lawyer_b, mediator) are built using the Google ADK Agent class with gemini-3-flash-preview. Each agent is given a scoped set of Python function tools and the full MongoDB MCP toolset.
Evidence access is role-scoped by design:
- Lawyer A can only access
{caseId}-L1-EVD-*documents - Lawyer B can only access
{caseId}-L2-EVD-*documents - The Mediator can only access evidence that a lawyer has explicitly presented (
presentedToMediator: true)
This enforces the same information asymmetry that exists in real mediation proceedings.
MongoDB MCP Server
The MongoDB MCP Server runs as a separate Cloud Run service and connects to MongoDB Atlas. All agents receive the MCP toolset via McpToolset (SSE / StreamableHTTP transport). Agents use MCP tools for direct data queries alongside scoped Python function tools.
Search & Retrieval
Evidence and legal references are retrievable two ways:
- Atlas Full-Text Search — keyword search over
documentContentandcontentfields - MongoDB Vector Search + Voyage AI — semantic similarity search using
voyage-3embeddings stored per document
The legal reference corpus (11 seeded documents) covers UCC provisions, Restatement of Contracts principles, breach of contract standards, and service contract law — giving the agents real legal grounding.
Hearing Orchestration
The DisputeHearingFlow class implements an 8-state machine:
INTAKE → LAWYER_A_OPENING → LAWYER_B_OPENING → LAWYER_A_REBUTTAL →
LAWYER_B_REBUTTAL → MEDIATOR_REVIEW → SETTLEMENT_RECOMMENDATION → HUMAN_REVIEW
Each step is a separate ADK Runner.run() call. State is persisted to MongoDB between steps — making the flow crash-resilient. The mediator can pause the hearing to ask a human party a direct clarifying question and resume once they respond.
Infrastructure
| Layer | Technology |
|---|---|
| Frontend | Next.js 14 (App Router, standalone), Cloud Run |
| Backend | FastAPI + Uvicorn, Cloud Run |
| Database | MongoDB Atlas (motor async driver) |
| AI agents | Google ADK, Gemini 3 Flash |
| MCP | MongoDB MCP Server, Cloud Run (SSE transport) |
| Evidence OCR | Gemini Vision (PDF extraction) |
| Search | MongoDB Atlas Text Search + Vector Search |
| Embeddings | Voyage AI (voyage-3) |
| Audio | Google Cloud Text-to-Speech |
| Gmail API | |
| Storage | Google Cloud Storage (evidence files) |
| Secrets | Google Cloud Secret Manager |
| CI/CD | GitHub Actions → Terraform → Artifact Registry → Cloud Run |
Challenges we ran into
1. Cross-origin Authorization header forwarding
The frontend needs to send a JWT Authorization header to the backend. Browser CORS rules silently drop auth headers on cross-origin 307 redirects. We tried nginx proxy, Next.js middleware proxying, and API route proxying — all failed in different ways. The fix: serve the backend URL at runtime via a /api/config endpoint, have the frontend call the backend directly with redirect_slashes=False on FastAPI.
2. MCP transport evolution
The Google ADK MCP transport API changed between releases — SseServerParams was replaced by StreamableHTTPConnectionParams. Debugging this required reading ADK source to understand what transport class the new SDK expected.
3. Cloud Run CPU throttling during long-running agent chains
Cloud Run throttles CPU between HTTP requests. A multi-step hearing that chains agent calls in background tasks loses CPU between steps and stalls. We solved this by moving to a single run_full_hearing coroutine that runs all steps sequentially in one long-lived async task, using adaptive per-step delays based on output length.
4. Mediator information isolation
Ensuring the mediator could only see what lawyers formally presented — not the full evidence pool — required careful access control at the tool level and separate presentedToMediator flag management per document.
5. ADK rate limit handling
Gemini API rate limits (RESOURCE_EXHAUSTED / HTTP 429) would silently fail steps. We added per-step retry logic with exponential backoff (up to 4 retries, 20s × attempt for rate limit errors) so hearings survive transient quota bursts.
Accomplishments that we're proud of
True multi-agent adversarial debate — Lawyer A and Lawyer B genuinely read each other's arguments via the transcript and respond to them. The mediator reads all of it before deliberating. This isn't a single-agent chatbot with personas; it's three independent ADK
Agentinstances with isolated session contexts.Evidence-grounded reasoning — Agents cite specific document IDs and passages from uploaded evidence. The mediator's settlement recommendation references actual uploaded documents, not hallucinated facts.
Dual-mode search — Both keyword (Atlas Full-Text) and semantic (Vector Search + Voyage AI) retrieval work side by side. Agents pick the right tool for the query.
PDF vision extraction — Uploading an invoice PDF triggers Gemini Vision to extract every line item, date, and amount. Parties never need to manually transcribe documents.
Full GCP production deployment — The entire stack — frontend, backend, MCP server — runs on Cloud Run with Terraform-managed infrastructure and GitHub Actions CI/CD. This is not a localhost demo.
Graceful degradation — If the MCP server is down, the hearing continues using direct Python function tools. The platform never hard-fails on a single dependency.
What we learned
Google ADK's
Agentclass is genuinely powerful for building constrained, tool-using agents. The ability to mix MCP tools and Python function tools in the same agent's tool list made the evidence access model clean to implement.Information asymmetry in multi-agent systems must be enforced at the data layer, not the prompt layer. Telling an agent "don't look at the other party's evidence" is insufficient — the tool itself must scope the query.
Cloud Run is not a background job runner. Tasks that outlive an HTTP request need to be structured as a single long-running coroutine or offloaded to Cloud Tasks. We learned this the hard way with stalled hearing steps.
MongoDB Atlas Search and Vector Search complement each other well. Full-text search is fast and deterministic for known terms; vector search catches conceptually related evidence that shares no keywords. Combining both gave the agents a more complete retrieval picture.
MCP as a service boundary — Running the MongoDB MCP Server as a separate Cloud Run service lets any agent (or any future external tool) query the data layer without bespoke integrations. It's a clean separation of concerns.
What's next for ArbitrAI
Formal document generation — Auto-generate a signed settlement agreement PDF that both parties can download and countersign.
Multi-case arbitration panels — Allow a human arbitration panel to review the AI recommendation before it becomes binding, blending AI efficiency with human oversight.
Industry-specific legal corpora — Seed domain-specific legal references (employment law, IP, real estate) so the mediator can be specialized per dispute type.
Stripe integration for settlement payment — Once a settlement amount is agreed, initiate payment directly from the platform.
Voice hearings — Use ElevenLabs or Google TTS to narrate each step live, creating an immersive audio hearing experience rather than a text transcript.
Voyage AI embeddings at upload time — Currently embeddings are optional. Making them mandatory at evidence upload time would make semantic search always available, improving mediator evidence retrieval accuracy.
Analytics dashboard — Track settlement rates, average dispute amounts, time-to-resolution, and mediator confidence scores across all cases.
Built on Gemini 3, Google ADK, and MongoDB Atlas. Deployed on Google Cloud.
Built With
- docker
- fastapi
- gemini-3-flash
- gemini-vision
- github-actions
- gmail-api
- google-adk
- google-cloud
- google-cloud-run
- google-cloud-secret-manager
- google-cloud-tasks
- google-cloud-text-to-speech
- jwt
- mongodb-atlas
- mongodb-atlas-full-text-search
- mongodb-atlas-vector-search
- mongodb-mcp-server
- next.js
- python
- tailwind-css
- terraform
- typescript
- voyage-ai

Log in or sign up for Devpost to join the conversation.