-
-

Image we took through our phone of a plastic bottle to test
-

Image we took through our phone of a plastic bag to test
-
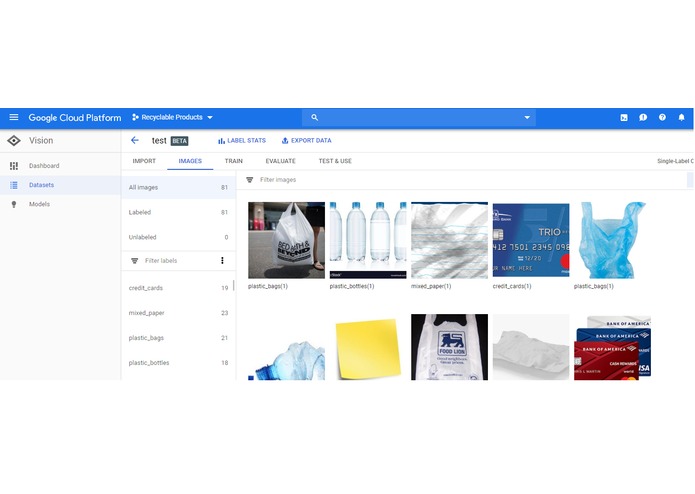
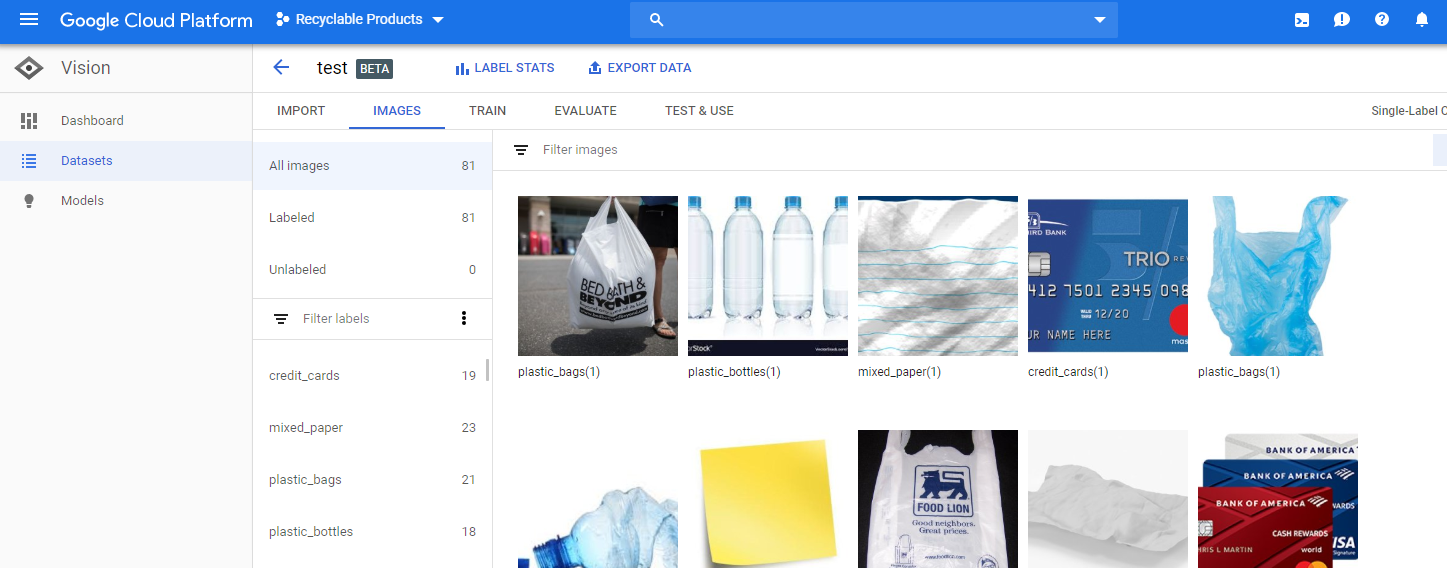
Screenshot of GCP dataset


Inspiration
This past week, Swiss astrophysicist Michael Mayor was awarded the Nobel Prize for his discovery of an exoplanet orbiting a solar-type star. In an interview after receiving this prestigious award, he said, "We must take care of our planet, it is very beautiful and still absolutely livable." His words inspired us to take care of our planet through technology by making it easier for people to access information on what items should be recycled and what items should not be. There were many times when we would walk out of, let's say a cafeteria after a meal, and couldn't discern between what items are recyclable. Therefore, we would toss everything in the trash so that nothing already in the recycling bin would get tainted. Through A.R.A., we hope to alleviate the confusion behind recycling.
What it does
A.R.A. allows a client to upload a picture of an item (such as a picture taken from a phone), and it will return with a response stating what that item is and whether or not it can be recycled.
How we built it
Using a python script, we first scrapped the HTML of https://www.orangecountync.gov/151/Accepted-Materials-List and created a YAML file discerning between what items can be recycled and what items cannot be. Each county has different recycling guidelines, so we decided to focus on Orange County. We then used one of Google Cloud's beta service called VisionML- Image Classification, which allowed us to upload dozens of pictures of both recyclable and non-recyclable objects and give them labels of what the object in the picture describes. Each label we created corresponded to the items in the YAML file. We attempted to add as many pictures as we could to expand our dataset because larger data would give us more accurate results. Google's VisionML randomly split each label into training, validating, and testing data. After a few hours of training, our model was complete and ready for use. Using a different python script, we then used Google Cloud's API to upload a picture on to the model in the Cloud, have it determine what type of item it is (plastic bottle, credit card, etc.) with how much certainty, and return a duple of image classification and confidence level. The same python program also compared the returned item type from the API with the parsed YAML file values and outputted whether or not the item in the picture can be recycled. A shell script was necessary to pass in environmental variables such as the credentials for the Google Cloud service as well as paths to the pictures to the python scripts. We created a user friendly interface for the front end but we had trouble connecting it to the rest of the program. We needed to host two servers (one for hosting a PHP file and one for hosting a database) on local host and it would work like this: 1) User uploads an image to the interface 2) Image gets sent to the server hosting the PHP file 3) Image gets sent from that server to the server hosting a database 4) We can grab the image from the database which would be the entrypoint to the python scripts we have created
Challenges we ran into
1) This is specific to Orange County for now. However, this program can accommodate more counties as long as a YAML file can be generated in the same format that is given in our project. This can either be done through a scrapper (as we have done), or through a manually created YAML file. 2) Because the Google Cloud service we used (VisionML) is still in its beta stage, there weren't that much information in general. Figuring out how to use the API and the necessary credentials took a good amount of time. Also, we don't have that many different items or pictures in the Google Cloud right now, but this can simply be fixed by adding more items. Google recommended 100 pictures per item for the machine to train on but we were successful with just a couple dozens of pictures per item. However, more pictures correlate to more accuracy. So, by increasing the number of pictures per type of object and the number of different objects, we can make A.R.A. even more accurate.
Accomplishments that we're proud of
1) We were able to create a working model of A.R.A. within the time constraint. 2) We were able to utilize a beta tool offered by Google and implement machine learning 3) Potential of growth of A.R.A. 4) Green objective for developing A.R.A.
What we learned
We learned that machine learning capabilities has reached beyond our expectations. The speed at which the machine on the cloud was able to go through the images we provided was incredible. To be honest, we also gained more insight on what can or cannot be recycled as well as the fact that the rules vary from county to county. Lastly, we learned more about APIs functionality with credentials.
What's next for A.R.A. (Automated Recycling Application)
We hope to keep developing/refining this program and maybe even put it as an open source project for others to contribute. People can add pictures on the machine or create push requests on the source code to make the usability more friendly or else.
Built With
- api
- bash
- beautiful-soup
- css
- google-cloud-visionml
- html
- javascript
- python
- requests
- shell




Log in or sign up for Devpost to join the conversation.