-
-

Login Page
-
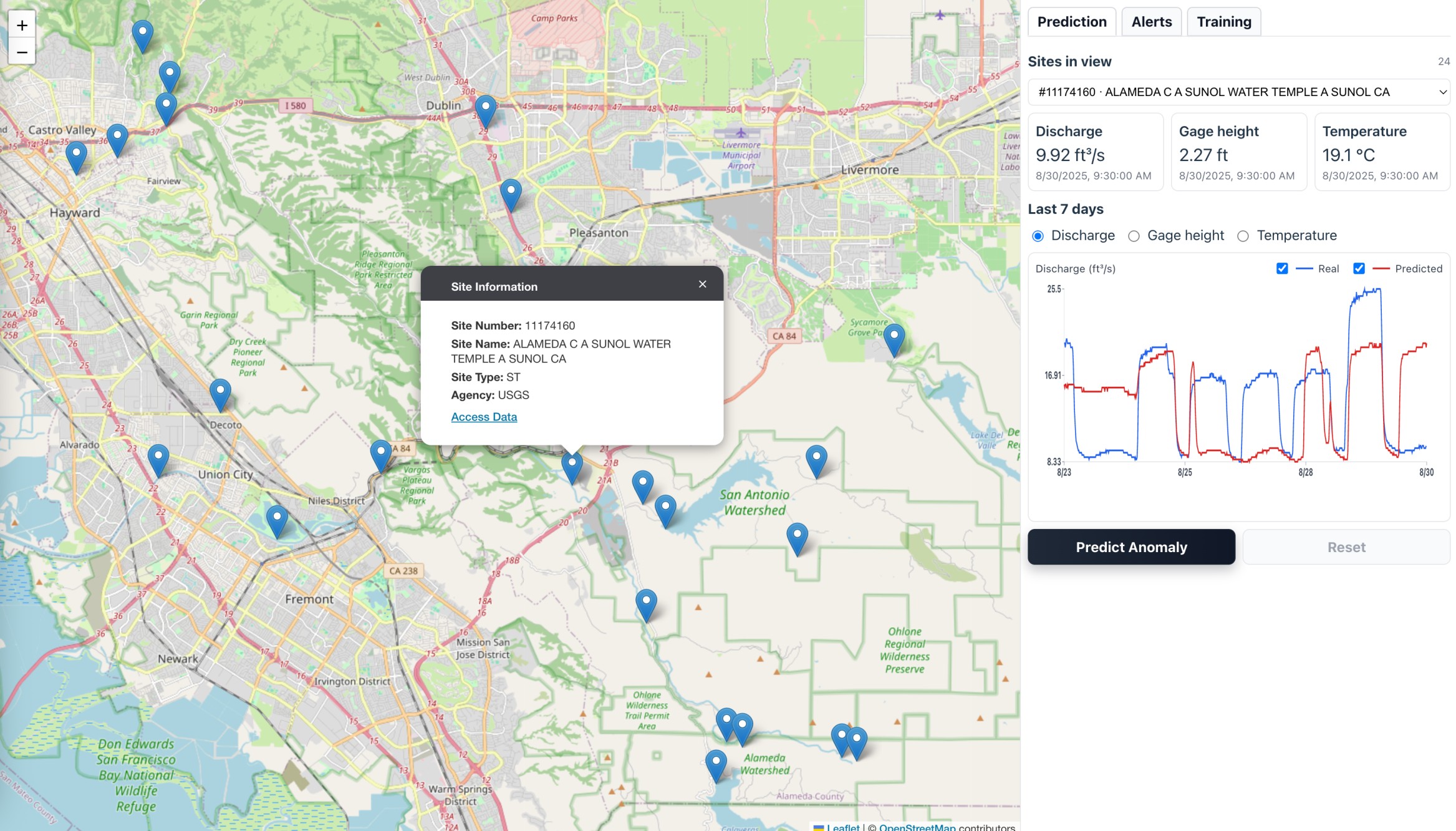
Interactive Map
-
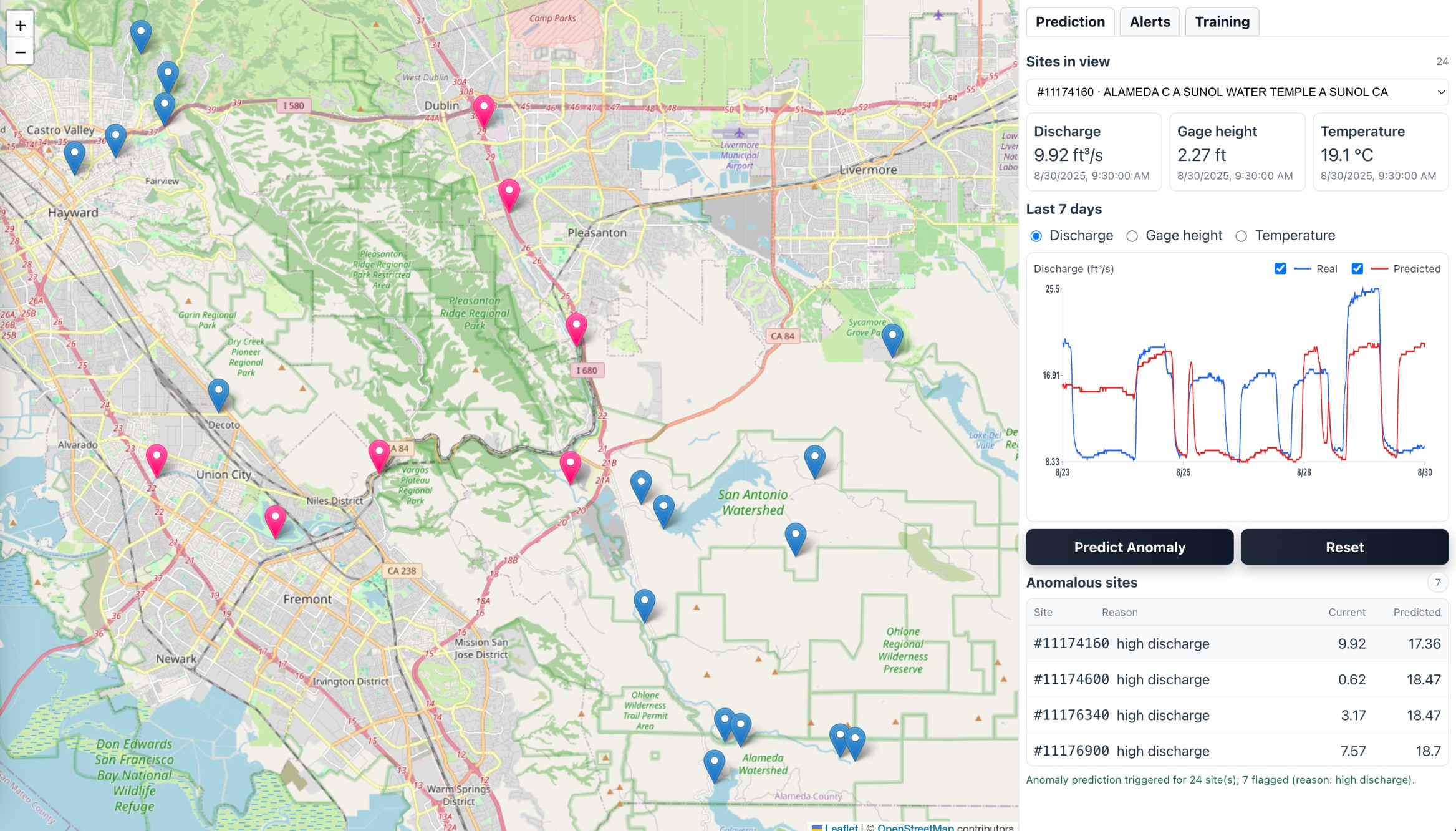
Predict Anomaly
-
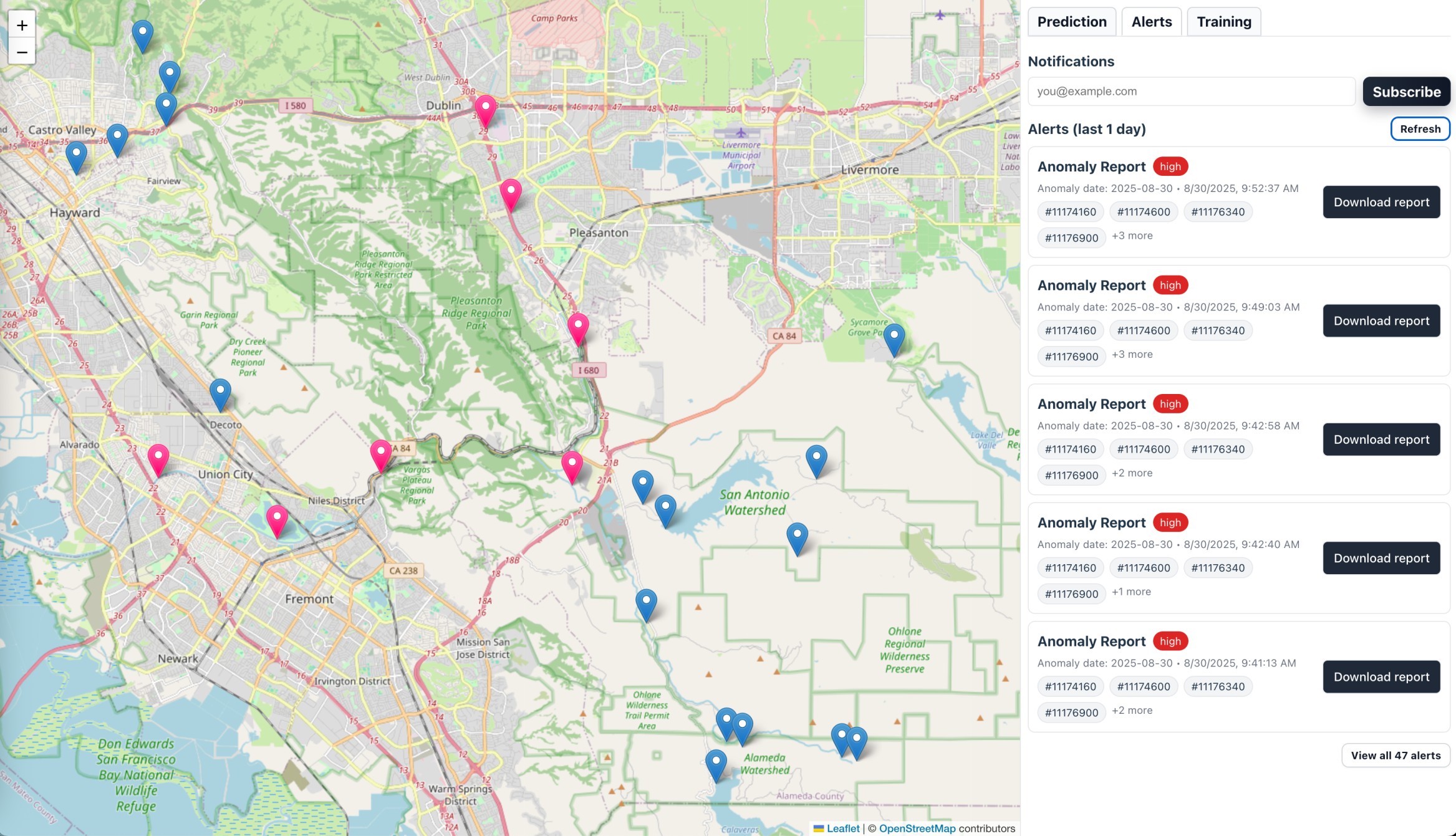
Alert
-
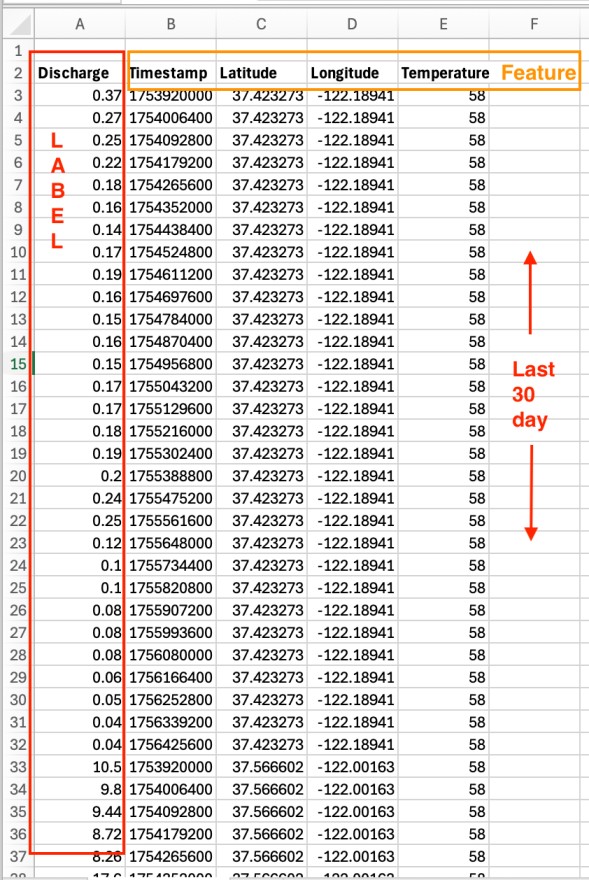
Preprocessed Data (model input)
-
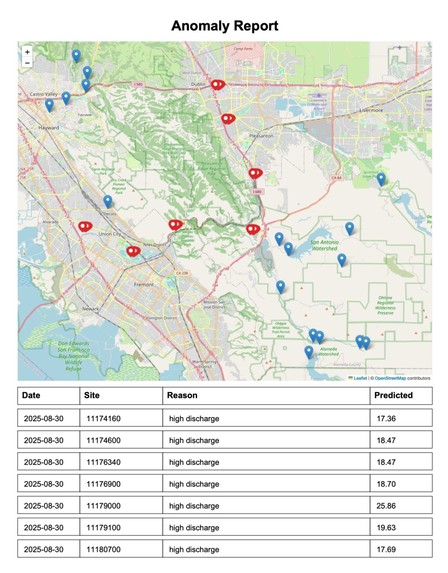
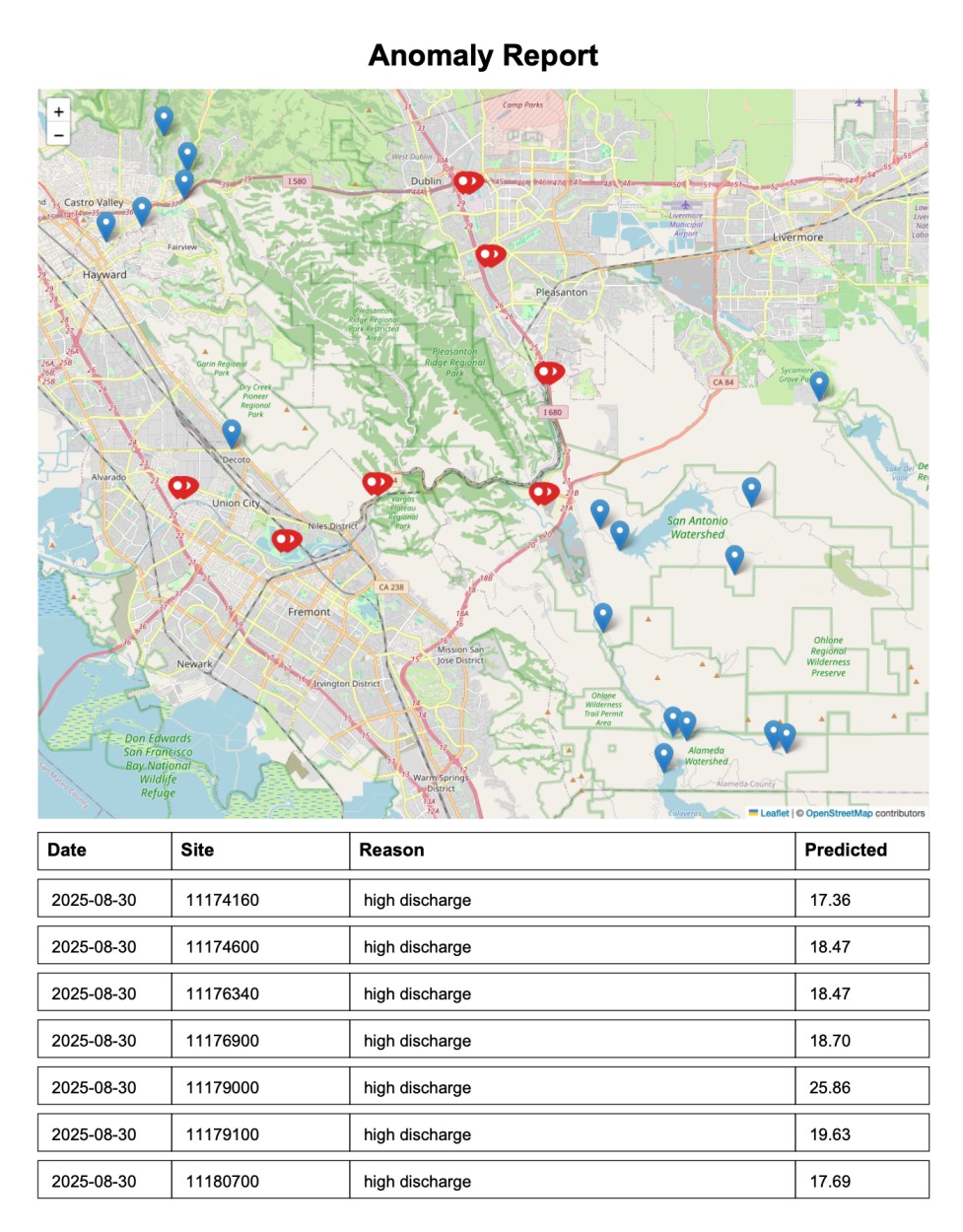
Anomaly Report
-
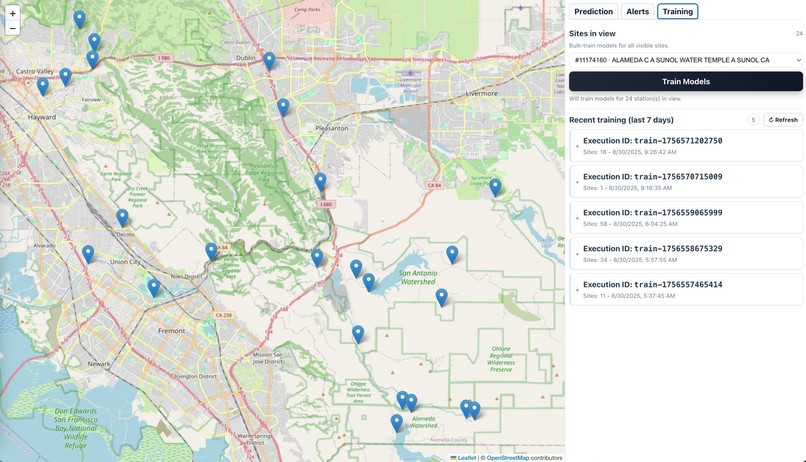
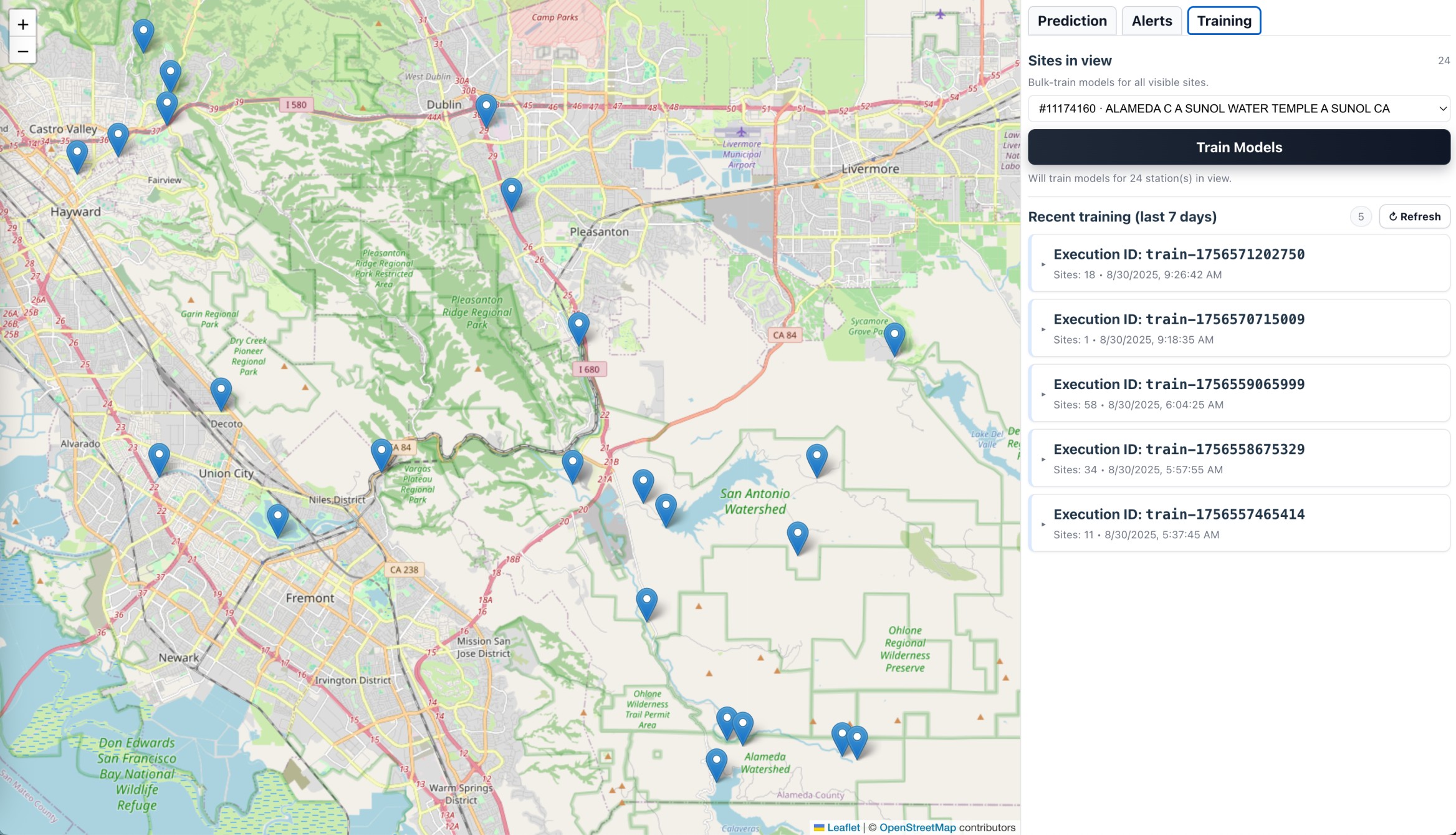
Model Training
-
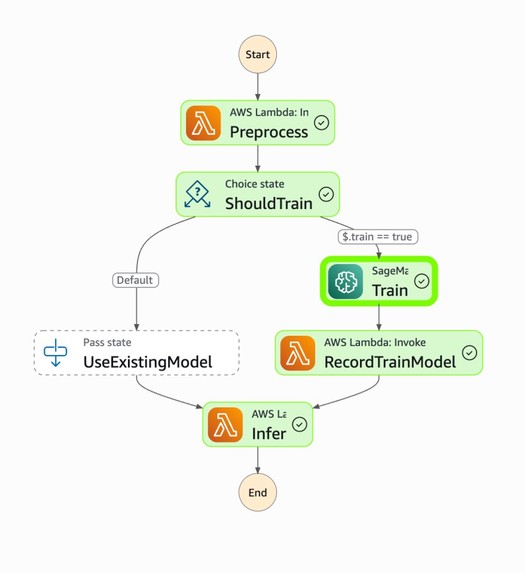
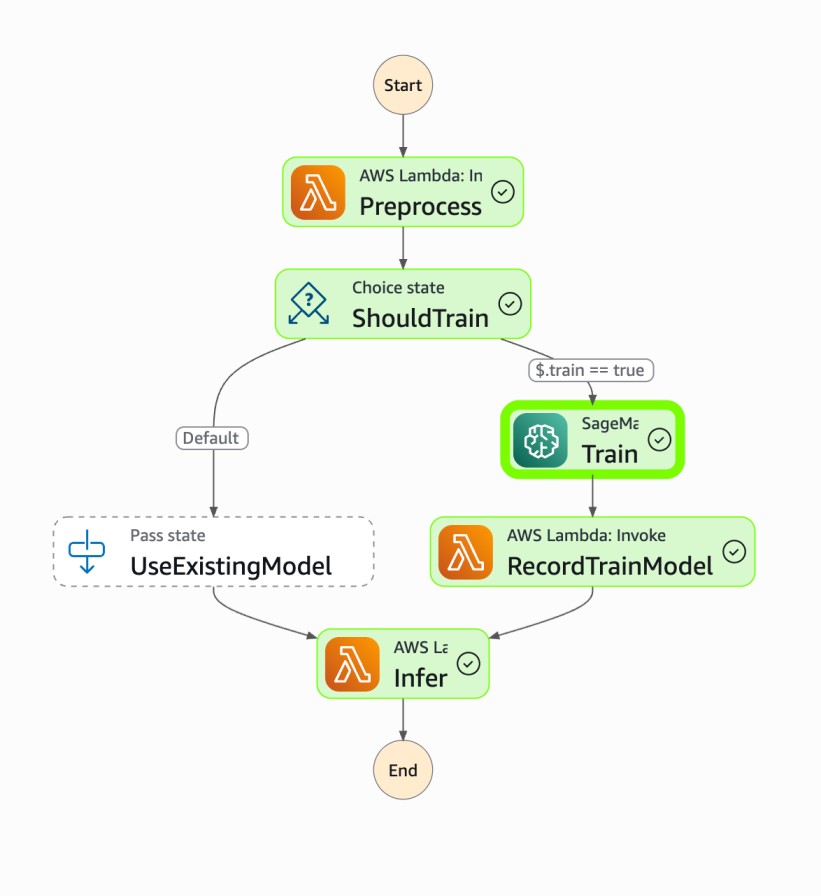
Step Function for Training model
-
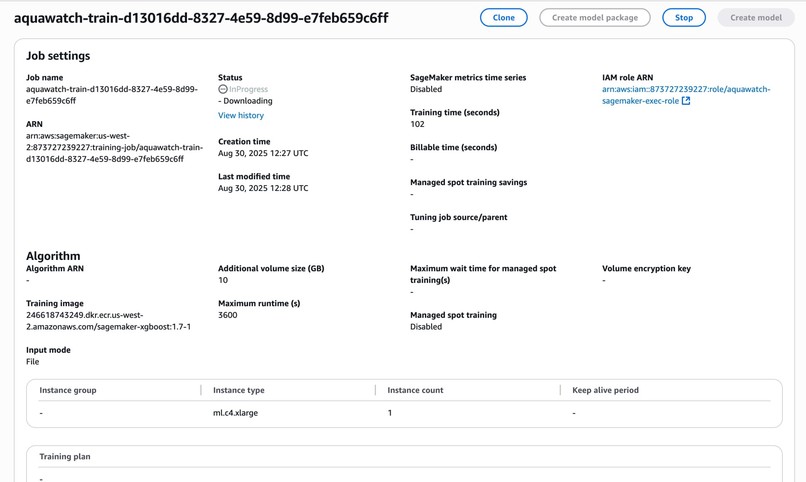
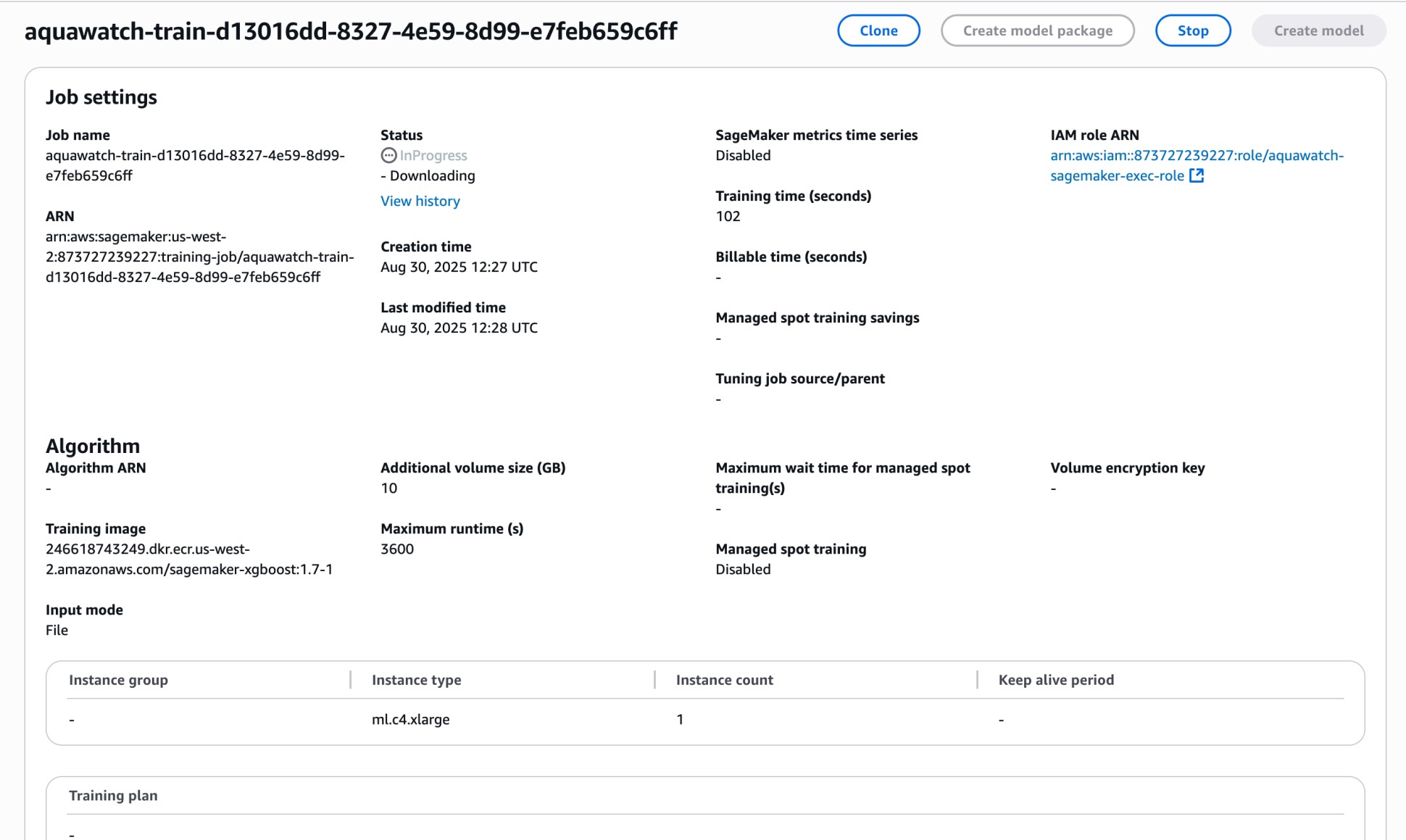
SageMaker Training Job
-
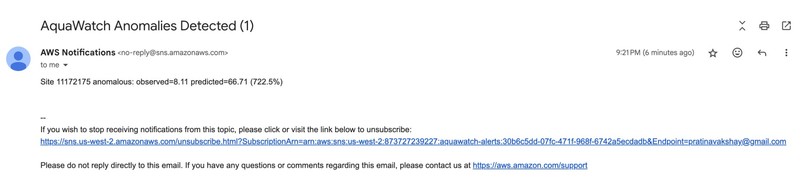
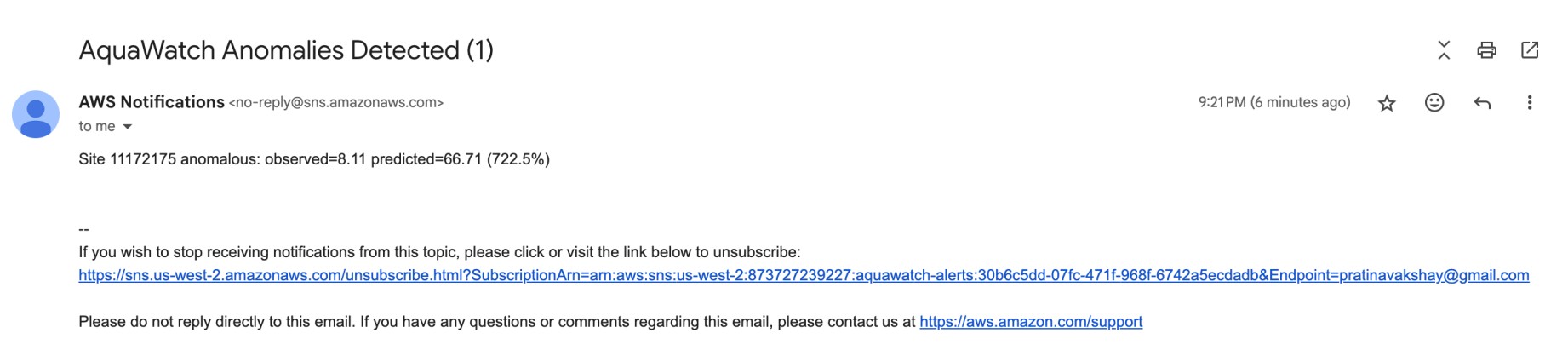
Anomaly Email Notifications

Inspiration
Over 2 billion people live in water-stressed areas (UN Water). Pollution, climate change, and urbanization are making water resources harder to manage. Early detection of anomalies (pollution spikes, abnormal flow, low oxygen) can prevent ecological damage and protect human health.
We now have thousands of sensors (USGS water stations, NOAA rainfall, IoT gauges) plus satellite imagery streaming in real-time. The challenge is that this data is siloed and underused. AquaWatch flips this around — using serverless + ML to turn raw feeds into predictive intelligence.
Floods, droughts, and contamination events are often detected too late. For example, floods in India (2021) and drought in California highlight how slow monitoring systems failed communities. AquaWatch enables proactive alerts instead of reactive reports.
Instead of “just dashboards,” it gives: Predictive anomaly detection, Blast-radius view (map-based selection to see at-risk areas). Interactive decision support for communities, scientists, and policymakers.
What it does
1) Collects Data 📡
- Streams real-time water station data (flow, temperature, gage height, etc.) from sources like USGS Water Services.
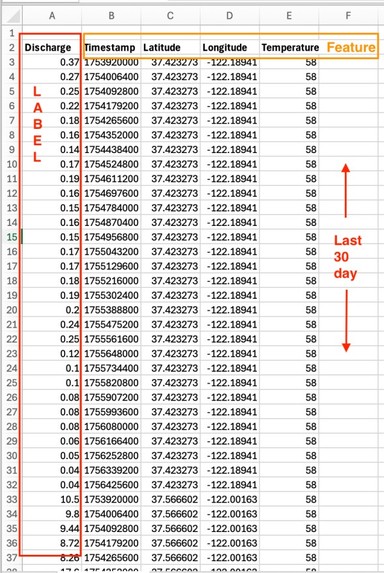
2) Preprocesses & Normalizes 🧹
- Cleans raw readings (handles missing values, outliers)
- Generates features (lagged flows, rainfall history, seasonal trends)
- Labels anomalies (e.g., sudden flow drop = drought risk, turbidity spike = contamination)
3) Trains Predictive Models 🤖
- Uses Amazon SageMaker ML pipelines to train models per station/region
- Forecasts ahead (flow levels, water stress, anomaly likelihood)
- Can adaptively retrain as new data arrives
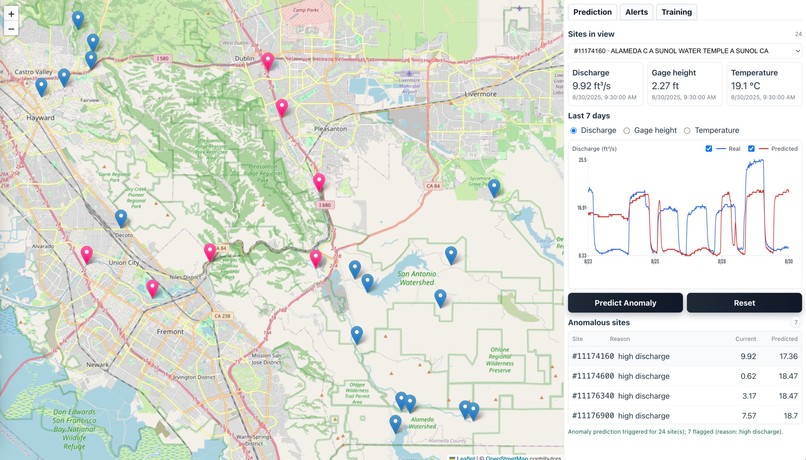
4) Predicts & Detects Anomalies 🔎
- Runs inference via serverless API (AWS Lambda + SageMaker endpoint)
- Predicts expected patterns vs. observed signals
- Flags anomalies (e.g., flood risk, pollution event)
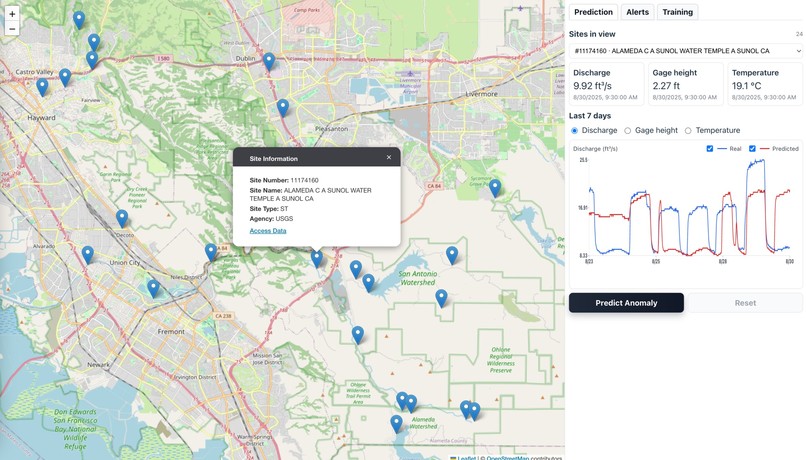
5) Visualizes in Dashboard 🗺️
- Interactive map of stations → select a station
- See station details, real-time curves, and corresponding prediction
- Dashboard shows anomalies and trends
How we built it
1) Data Ingestion Layer 🚰
- Sources:
- USGS Water Services API → river/stream flow, water level, quality
- NOAA Weather API → rainfall, temperature, drought indices
- Tech:
- AWS Lambda jobs scheduled (Amazon EventBridge cron) to pull data
- Stored in Amazon S3 (raw bucket)
2) Preprocessing Layer 🧪
- Goal: Clean + prepare data for ML
- Steps:
- Handle missing values, normalize units
- Create features (flow discharge, temperature)
- Label anomalies (spikes, drops, abnormal patterns)
- Tech:
- AWS Lambda + AWS Step Functions orchestrate ETL
- Processed outputs stored in Amazon S3 (processed bucket) as CSV/Parquet.
3) Model Training 🎯
- Approach:
- Uses multi-station models
- Uses time-series forecasting (XGBoost)
- Tech:
- Amazon SageMaker Training Job launched with custom
train.py. - Trained model artifact stored in Amazon S3 (models bucket).
- Amazon SageMaker Training Job launched with custom
4) Model Hosting & Inference 🚀
- Hosting:
- Deploy trained model to SageMaker Endpoint
- Inference Flow:
- UI/API sends
station_id+ recent features - SageMaker returns forecast prediction along with anomaly score
- UI/API sends
- Serverless API:
- Amazon API Gateway → AWS Lambda → SageMaker Endpoint
5) Dashboard (React App) 🖥️
- Interactive Map (Leaflet / Mapbox / Deck.gl):
- Shows all stations with status indicators (normal vs anomaly)
- Station Panel:
- Displays live readings, historical trends, and predictions
- Blast-Radius Selector:
- User can select a radius → backend collects all stations → runs bulk predictions
- Alerts Dashboard:
- Highlights anomalies (flood risk, etc).
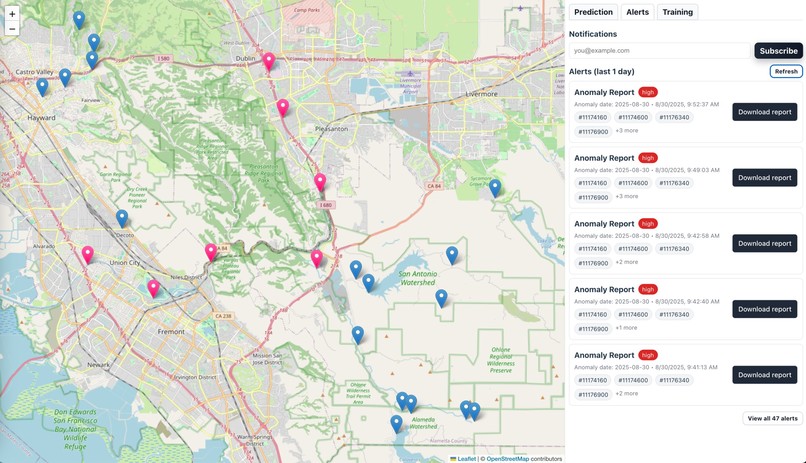
6) Alerts & Notifications 🔔
- Amazon SNS / Amazon EventBridge → trigger SMS/Slack/email alerts if anomaly probability > threshold.
Stack Recap
- Data Ingestion: AWS Lambda + Amazon EventBridge + Amazon S3
- Processing/ETL: AWS Lambda + AWS Step Functions
- Model Training: Amazon SageMaker Training Jobs
- Model Hosting: Amazon SageMaker Endpoints
- Prediction API: Amazon API Gateway + AWS Lambda → SageMaker
- UI: React + Leaflet/Mapbox
- Storage: Amazon S3 (raw, processed, models) + Amazon DynamoDB (station metadata)
Challenges we ran into
1) Heterogeneous & Incomplete Data 🧩
- Water stations don’t always report the same variables (some give flow, some turbidity, others just water level)
- Missing values, different units, and inconsistent reporting frequency made it hard to align datasets
- We had to build a robust preprocessing pipeline that normalizes features and handles gaps gracefully
2) Choosing the Right ML Strategy ⚖️
- We debated between one global model (trained on all stations) vs. per-station models (to capture local dynamics)
- Global models generalized poorly in some regions; per-station models lacked enough training data
- The solution was a hybrid approach → pre-train globally, then fine-tune per-station
3) Real-Time Scalability 📈
- Streaming thousands of time-series into ML inference in real time pushed system design limits
- Running large models on every API request was too slow and expensive.
- We solved this by using serverless + SageMaker endpoints (scale on demand)
Accomplishments that we're proud of
- End-to-End Serverless ML Pipeline: Fully automated from ingest → preprocess → train → inference → visualization — with zero servers to manage
- Interactive Geospatial Dashboard: Map-driven exploration; instant predictions + anomaly alerts in a clean, intuitive UI
- Predictive, Not Just Reactive: Forecasts days ahead; earlier warnings for floods, droughts, and water-quality risks
- Scalable + Cost-Efficient: Pay-per-use scalability with AWS serverless; designed to scale from a few stations to thousands globally
- Scientific + Practical Impact: Hydrology + ML combined into a production-grade, lightweight system
- Real-world potential: Environmental agencies, NGOs, climate researchers
What we learned
1) Data Quality > Model Complexity
- Clean, consistent, and well-engineered features had more impact on accuracy than picking a fancy ML algorithm
- Handling missing values and aligning time-series was half the battle.
2) One Size Doesn’t Fit All
- Different water stations behave very differently (seasonal rivers vs. urban reservoirs)
- A hybrid approach (global pre-training + local fine-tuning) gave us the best results
3) Serverless is Powerful but Demands Smart Design
- AWS Lambda + SageMaker gave us elasticity, but naive use would have been costly or slow
4) Visualization Makes AI Useful
- Raw predictions mean little to end users
- Putting insights on an interactive map + anomaly dashboard made the system actionable and easy to trust
5) Collaboration Across Domains is Key
- Hydrology + ML + Cloud architecture each required different expertise
- Real progress came when we combined scientific knowledge with engineering skills
What's next for AquaWatch - Global Water Stress Monitor
1) Satellite & Remote Sensing Integration 🛰️
- Fuse data from NASA/ESA satellites (rainfall, soil moisture, vegetation index) with station data for more holistic anomaly detection
2) Multi-Modal Prediction Models 🧠
- Move beyond time-series → combine climate forecasts, land use, and socio-economic factors for richer predictions
- E.g. predicting not just anomalies but also likely causes
3) Crowdsourced & IoT Inputs 📲
- Allow citizens or IoT devices (low-cost sensors, drones) to feed into the platform
- Democratizes water monitoring, especially in under-served regions
4) Early Warning & Alerting System 🚨
- Trigger SMS / push notifications for local communities or agencies when anomalies cross risk thresholds
- Could integrate with existing disaster response workflows
5) Global Coverage at Scale 🌍
- Deploy across thousands of stations worldwide with automated retraining pipelines
- Make AquaWatch a global water intelligence system
6) Open Data & Research Platform 🔓
- Expose an API for researchers and NGOs to access predictions, anomalies, and historical insights
- Encourage collaboration and transparency in climate resilience work



Log in or sign up for Devpost to join the conversation.