Inspiration
What it does
How we built it## Inspiration
Every city publishes open data — permits, inspections, violations — and almost none of it is usable. The records are technically public but practically dead: the interesting facts ("ADD 200A SUB PANEL & EV CHRGR") are buried in free-text blobs no electrician can filter and no AI agent can trust. Meanwhile, the agentic web is getting a native way to charge for things: HTTP 402 and the x402 pattern.
So we asked: what if an agent didn't just clean a dataset, but became its landlord — acquiring messy public data as property, refining it into typed, queryable fields, and renting it out per-query with a receipt and an official citation on every record?
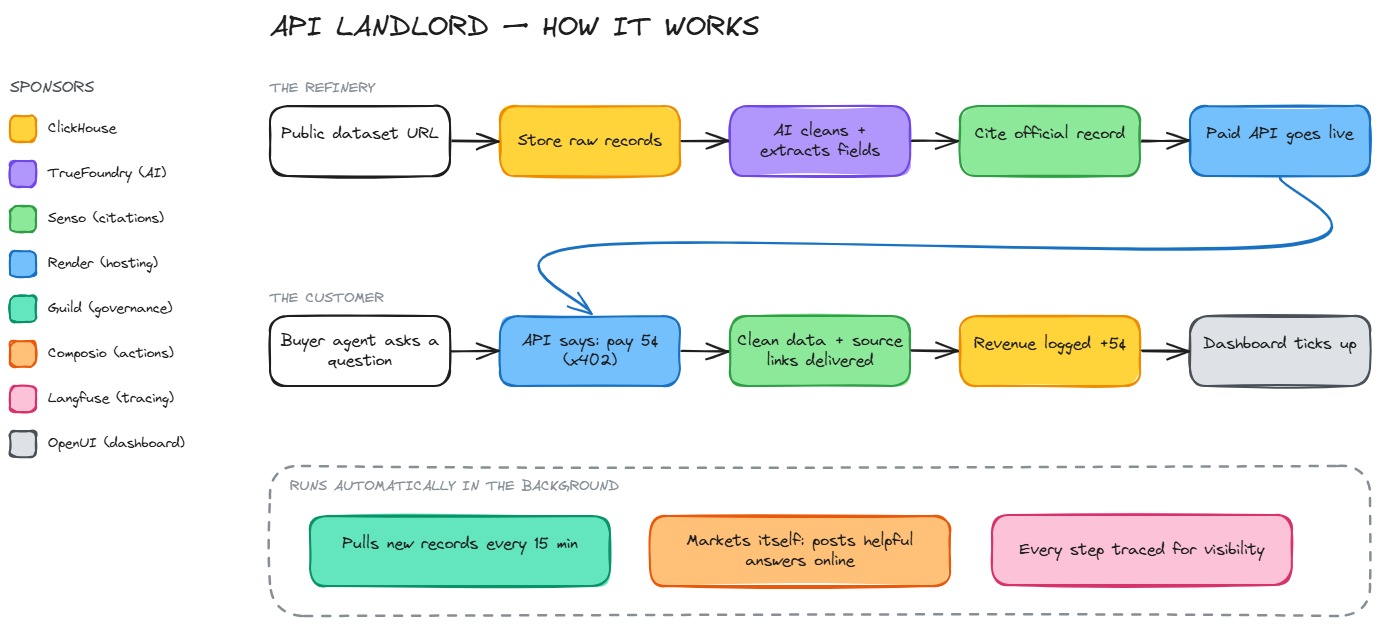
API Landlord is that agent. Feed it a raw open-data URL and it inspects the schema, writes its own dataset config, runs the refinery, and puts a paid, cited API on the market — without a server restart and without a human writing a line of pipeline code.
What it does
- Refines: ingests raw Socrata records losslessly, normalizes deterministically, then extracts typed fields from free text (
work_type: [subpanel, ev_charger],amperage: 200) using a fine-tuned small model with an LLM-gateway fallback. - Proves: every served record carries a
sourceblock — record ID, excerpt, timestamp, and a clickable official-record URL back to the city's own API. The corpus is also compiled into a grounded, citable knowledge base. - Charges: hitting
GET /api/{endpoint}without a payment token returns HTTP 402 with x402-style headers.POST /payissues a single-use, dataset-bound token (5¢); retry with the token and you get clean, cited JSON. Every transaction lands in a revenue ledger. - Acquires:
python -m landlord.onboard <socrata-url>is the factory — inspect → propose YAML config → register → refine → live paid endpoint. Tenant #2 (SF building permits) was onboarded with zero Python edits. - Runs itself: a refresh daemon pulls only new records on each dataset's schedule, the whole pipeline is traced hop-by-hop, a live dashboard shows the portfolio and revenue ticker, and the agent even markets its own APIs by composing and posting genuinely helpful answers that link the paid endpoint.
How we built it
We built it in two layers.
Layer 1 — the harness. Before writing any product code, we wired all 10 sponsor tools into a verified, idea-agnostic harness: one minimal primitive per sponsor (sponsors/<name>/example.py), each with a check() that feeds a single health board (python harness/health.py → 10/10 LIVE). ClickHouse is the raw store, product DB, and ledger; Pioneer (GLiNER) does extraction with TrueFoundry's AI Gateway as the strict-JSON fallback behind the same function signature; Senso compiles the grounded, cited knowledge base; Langfuse is the flight recorder for every refinery run; OpenUI renders the dashboard's stat cards; Composio is the posting arm; Guild governs the autonomous refresh loop; Render hosts via blueprint; Airbyte is the managed multi-source ingest layer for scaling beyond Socrata.
Layer 2 — the product, built by 8 parallel agents. We froze every interface up front in a CONTRACTS.md — exact function signatures, the response JSON shape, ClickHouse schemas, even a canonical extraction example every fixture had to pass — then launched 8 Claude Code agents in parallel git worktrees, each owning its own modules, port, and acceptance tests. The orchestrator merged eight green branches into a working system: ingestion, refinery chain, citations, x402 paywall, query engine, onboarding factory, portfolio/refresh/dashboard, and self-marketing + deploy.
Challenges we ran into
- Coordinating 8 agents without them stepping on each other. The answer was contracts-first development: frozen signatures, a shared response-shape example,
test-prefixed dataset IDs so synthetic rows never pollute real queries, and a rule that a blocked agent leaves aCONTRACT-QUESTIONcomment instead of editing someone else's file. - The refresh daemon flooded the LLM gateway. Re-extracting the whole dataset every tick blew through rate limits. We hardened the refinery to be incremental — refresh ticks skip already-seen records and only retry prior rejects — and proved it with a hermetic acceptance test.
- Payment tokens died on restart. Single-use tokens lived in process memory, so a redeploy orphaned every paid-but-unserved query. We moved the token store into ClickHouse: tokens now survive restarts and work across instances.
- A sponsor went billing-gated mid-hack. Pioneer's inference got gated behind a billing plan. Because extraction was designed as Pioneer-first with a TrueFoundry fallback behind one signature, the pipeline kept refining records with zero code changes — and Pioneer auto-re-engages the moment billing un-gates.
What we learned
- Wire once, build anything. Separating "is every tool live?" from "what are we building?" was the single biggest speed unlock. The health board made integration status a fact, not a hope.
- Contracts beat coordination. Eight agents merging cleanly wasn't luck — it was frozen interfaces and per-agent acceptance tests. The merge was boring, which is the highest compliment.
- Provenance is the product. Clean data is nice; clean data where every record links to the official source is something a buyer — human or agent — can actually act on. Citations turned a data-cleaning demo into a sellable API.
- Design for degradation. Every external dependency got a fallback behind the same signature. That's why a billing gate was a footnote instead of a demo-killer.
Challenges we ran into
The orchestration layer was difficult because of auto refreshing
What's next for APY
Make it a product and make it avaialble over the public
Built With
- airbyte
- clickhouse
- composio
- guild
- langfuse
- openui
- pioneer
- python
- render
- senso
- socrata-open-data-api
- truefoundry

Log in or sign up for Devpost to join the conversation.