Apropos
Inspiration
Nobody teaches you how to think across fields. You take a biology class, an economics class, a math class, and you're supposed to somehow connect them yourself. Almost nobody does.
But the people who actually change things are the ones who see across domains. Shannon used Boolean algebra to build communication theory. Black and Scholes borrowed from thermodynamics to price options. Darwin's key insight came from reading an economics book by Malthus. The most valuable ideas live at the intersections, and nothing in education is designed to help you find them.
We wanted to build a system that maps everything you know, finds structural patterns connecting different fields, and guides you to discover those connections on your own.
What it does
Apropos is a personal knowledge engine that pairs with your daily browsing to build a living map of what you've learned, then uses that map to make you smarter.
It has two modes.
A passive system runs as a Chrome extension. It silently watches what you read on Wikipedia, captures concepts, and periodically challenges you with Socratic dialogues. These aren't quizzes. They're real conversations where an AI tutor leads you to discover connections between fields you already understand.
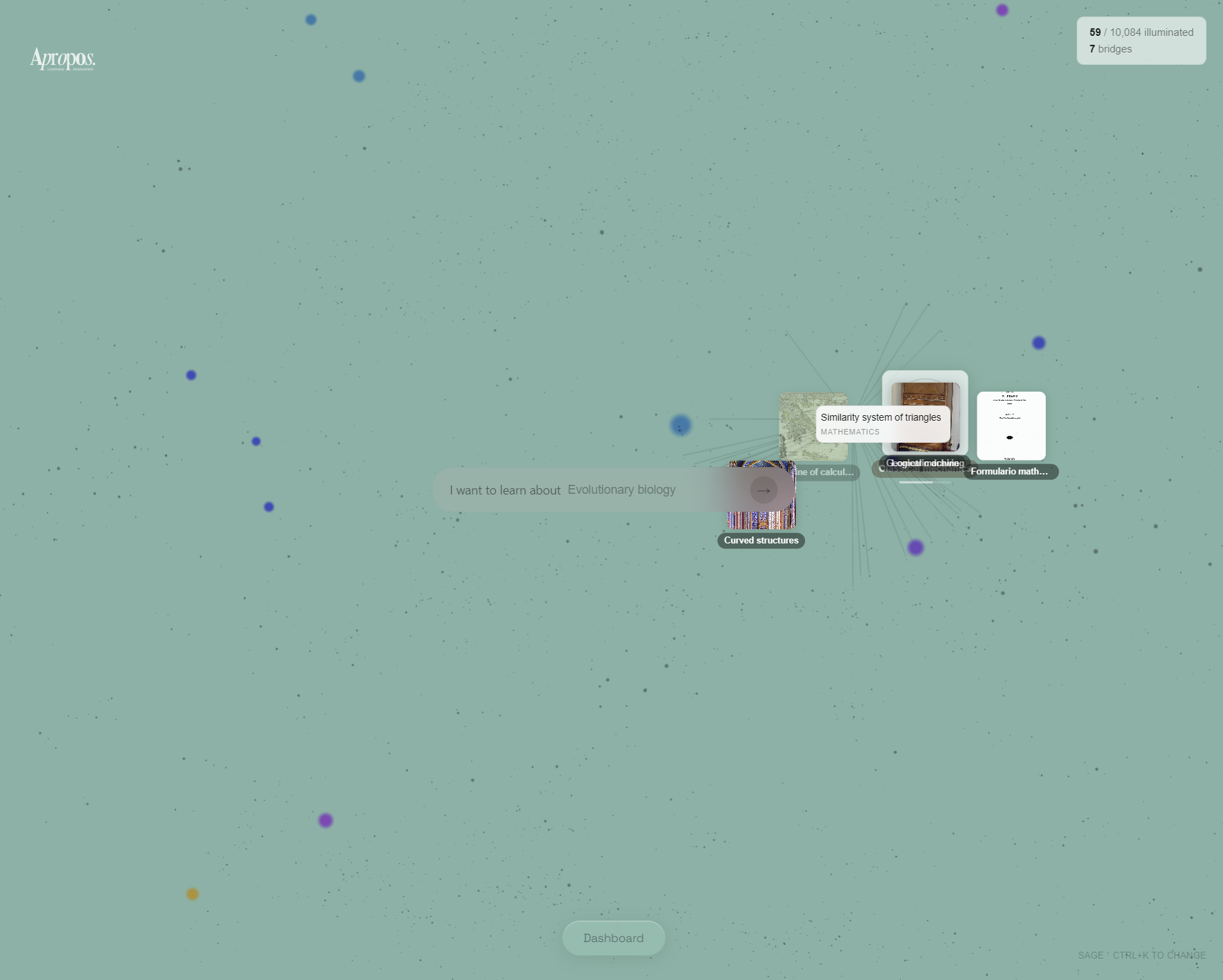
An active exploration mode lets you fly through a 3D space of 10,000 Wikipedia concepts. The entire landscape of human knowledge is rendered as a particle field. Your known concepts glow bright. The rest drift past like dark stars. You type what you want to learn, and the system plots a path from what you already know to where you want to go, walking you through each step in a flowing conversation.
The system gets smarter about you over time. It reads your response latency, keystroke confidence, and optionally facial engagement signals via MediaPipe to calibrate difficulty in real-time. It knows when to push harder and when to give you a foothold, the same way a great human tutor reads the room, except it never forgets what you know.
How we built it
Research first
We spent real time digging into cognitive science and neuroscience research before writing any code. A few findings shaped everything:
Roediger and Karpicke (2006) showed that retrieving information strengthens memory more than restudying, with an effect size of d=0.74. So our system never explains things. It makes you generate answers.
Gruber and Ranganath's PACE framework (2019) showed that curiosity is triggered by prediction errors. When your brain predicts something and reality differs, dopaminergic circuits fire and everything you learn in that state sticks better. So we always ask you to predict before revealing.
Bjork and Bjork (2020) found that conditions which slow apparent learning actually enhance long-term retention and transfer. Making things feel harder than necessary is the point.
And Bloom's famous 2-sigma finding (1984) showed that one-on-one tutoring produces a 2 standard deviation improvement over classroom instruction. The average tutored student outperforms 98% of the control group. That was our ceiling. Could we approach 2-sigma with AI?
These weren't decorative citations. Each one directly drove a design decision that we implemented.
Architecture
Three components share a unified knowledge graph:
The server (FastAPI + SQLite + sentence-transformers) stores every concept you've encountered, computes dual embeddings, runs the Socratic dialogue engine via Claude, manages spaced retrieval scheduling, and computes exploration paths.
The Chrome extension (Manifest V3) silently parses Wikipedia articles you read, captures concepts with zero friction, handles highlight-to-explore on any webpage, and presents Socratic dialogues in a chat-style sidebar.
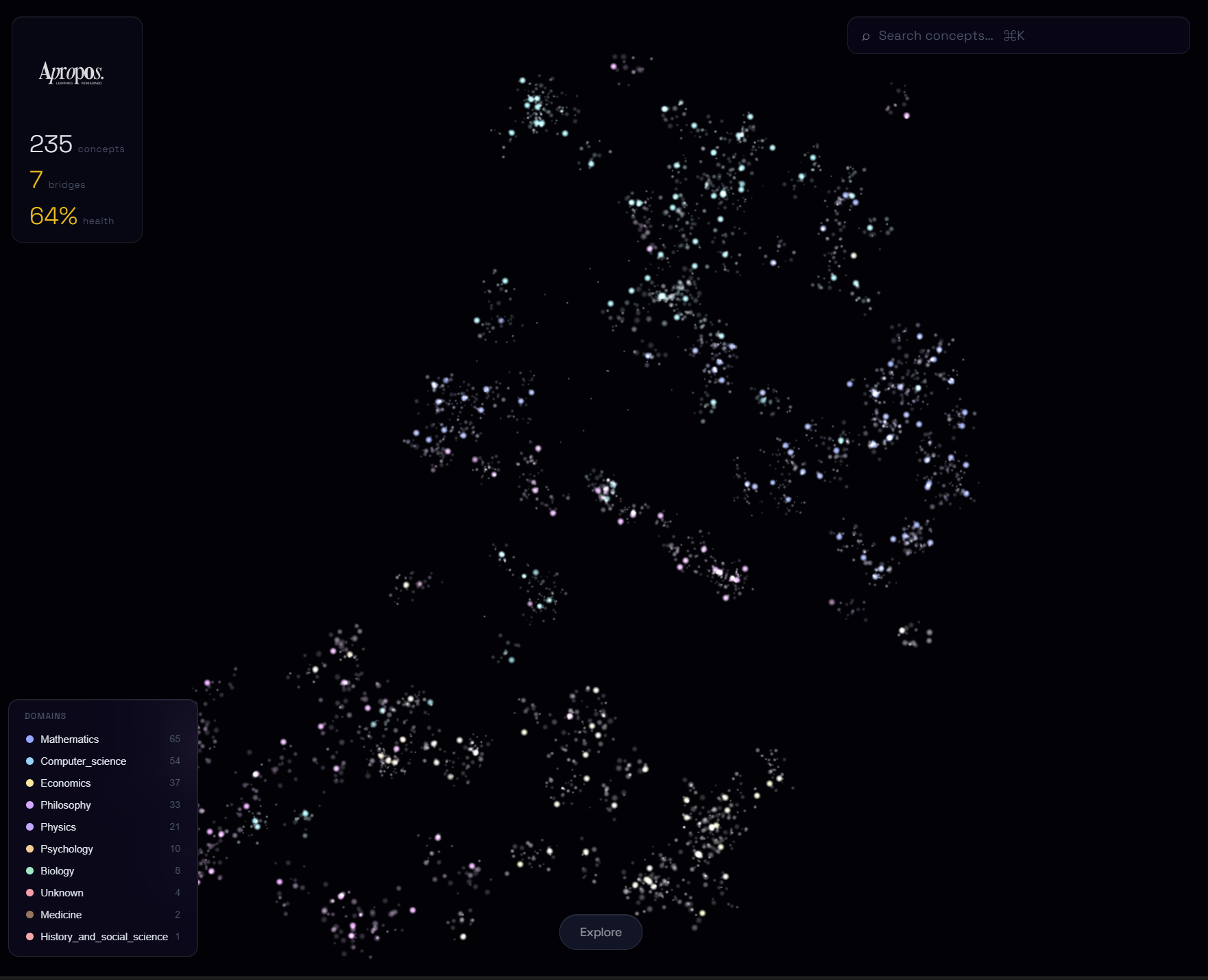
The dashboard (React + Three.js) renders a 3D particle visualization of your knowledge graph that slowly rotates. Concepts glow based on how well you remember them. Bridges between domains show up as particle streams. The explore page renders 10,000+ particles representing all of Wikipedia's vital articles, with yours glowing bright and the unknown dark.
Dual embeddings for cross-domain discovery
This is the core technical idea. Every concept gets two embeddings:
A topical embedding (sentence-transformer on the article intro) captures what domain a concept belongs to. A structural embedding captures what abstract pattern it follows. We generate this by having an LLM describe each concept using 30 fixed structural primitives (things like "feedback," "threshold," "competition," "equilibrium"), then embed that description.
Two concepts can be topically distant (auction theory vs evolutionary biology) but structurally close (both involve agents with private information competing under mechanism rules). The structural embedding finds these. It's how the system discovers that Nash equilibria and chemical equilibria share the same mathematical skeleton, or that immune system evasion follows the same pattern as principal-agent problems.
We tested this on 10 cross-domain analogy pairs. 8 out of 10 scored high structural similarity while having low topical similarity.
The Socratic engine
We rejected the quiz model early. Getting asked a question, typing an answer, and seeing a score kills curiosity. It turns learning into performance anxiety.
Instead, every interaction is a multi-turn Socratic dialogue. The tutor leads you to discover connections through conversation. It never says "correct" or "incorrect." It says "that's the right shape, push it further" or "interesting, but what happens when you consider this edge case?" Difficulty signals (turns needed, hints given, user-led insights) feed the scheduling model without ever being shown as a grade.
The system also chooses between three teaching modes per concept. Bridge mode connects new concepts to something you know. First-principles mode builds a concept's own logic from scratch. Contextual mode explains it in the context where you encountered it. A quality filter prevents forced analogies. If the structural parallel is shallow, the system teaches from first principles instead of contorting two concepts to fit.
Adversarial model refinement
For high-importance concepts, the tutor goes further. It finds the edge of your understanding and stress-tests it. It constructs scenarios where your current mental model makes a wrong prediction, lets you fail, then guides you to revise your model. This is how experts actually develop expertise: by discovering where their intuitions break.
The system maintains a per-concept model of what you understand and misunderstand, updated after every dialogue. When it re-engages you weeks later, it remembers where your model was weak and probes those exact points.
The tutor also never asks you to compute or calculate. It asks you to predict, reason, and diagnose. If a computation would help verify your intuition, it suggests you run it in Python. The learning is in the prediction, not the arithmetic.
The living dashboard
The knowledge graph visualization isn't a static chart. Concepts breathe with subtle animation. Nodes fade as you forget them (retrieval strength decays exponentially). Bridge edges glow with domain-color gradients and animated particles flowing between connected concepts. You can click a fading bridge to "remember" it through a quick Socratic dialogue, and watch it reignite on the graph.
The explore page renders the full landscape of human knowledge as a 3D starfield. 10,000 particles representing Wikipedia's vital articles drift toward you. Your known concepts are anchored bright, constellations you've named in a sky full of unknowns. The stat in the corner reads "347 / 10,000 illuminated."
Challenges we ran into
Wikipedia's link graph is noisy. Every internal link was initially treated as a prerequisite, so "Mathematical Induction" ended up with 30 prerequisites including the Fibonacci sequence and the Golden ratio. We rebuilt edge creation with position weighting (only links from the first two paragraphs), reciprocity bonuses, and a cap of 8 per concept. Cut from 1,778 noisy edges to about 100 clean ones.
Domain classification was stubborn. 214 out of 219 concepts were initially classified as "Unknown." We expanded keyword matching from 20 to 150 terms, added title-based classification (if the title says "(mathematics)" it's obviously math), and built a three-pass system: Wikipedia categories, then nearest-neighbor propagation, then k-means clustering with LLM labeling. Got it under 1%.
Bridge quality was a real problem. Early dialogues produced connections like "derivatives and lesions both involve threshold-triggered irreversible state changes." Technically true, but so abstract it applies to everything and teaches nothing. We built a quality filter that checks whether a bridge carries predictive load (can you actually reason about B using your knowledge of A?) and falls back to first-principles teaching when the answer is no.
The quiz model was just wrong. Our first version asked questions, scored answers, and showed grades. It felt like school. We scrapped it entirely and rebuilt around multi-turn Socratic conversations where evaluation is invisible and curiosity is preserved.
What we learned
The structural level of knowledge is real and teachable. When the system bridges auction theory to fitness landscapes and the user independently arrives at the parallel through guided dialogue, you can see the moment it clicks. The bridge isn't a metaphor. It's a genuine thinking tool. The user can now reason about evolutionary dynamics using machinery they built in economics.
Difficulty calibration matters more than content quality. A perfect explanation given at the wrong difficulty level is worse than a mediocre explanation at the right level. Behavioral signals like latency trends, keystroke confidence, and blink rate give the tutor enough to adjust in real-time. Static educational content can never do this.
What's next
Enriched content sources. The tutor currently draws on Wikipedia intros. Adding full articles, ArXiv abstracts, and LLM-generated textbook-level explanations would let it go much deeper on high-importance concepts.
Weekly auto-calibration. The system already collects enough behavioral data to tune its model of the user automatically. One LLM call per week analyzing learning patterns could update domain priorities, preferred explanation styles, and difficulty thresholds.
Insight logging. Sometimes you learn something outside the system, from a book or a conversation, and want to tell it. A manual bridge-creation feature would let you connect concepts spatially on the graph and describe the connection in your own words.
Mobile companion. Voice-only Socratic dialogues while walking or exercising. The sleep consolidation research suggests that studying before sleep is neurologically optimal, so a bedtime review mode could be powerful.
Built with
Python, FastAPI, SQLite, sentence-transformers, Anthropic Claude API, JavaScript, Chrome Extension (Manifest V3), React, Three.js, WebGL, D3.js, UMAP, Web Speech API, MediaPipe Face Mesh, KaTeX, Vite


Log in or sign up for Devpost to join the conversation.