-
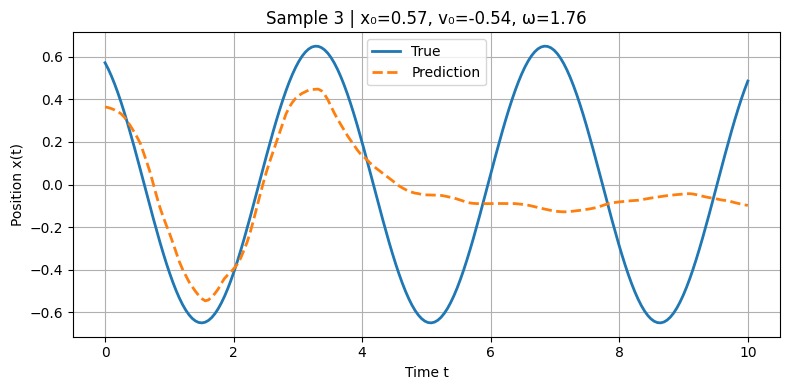
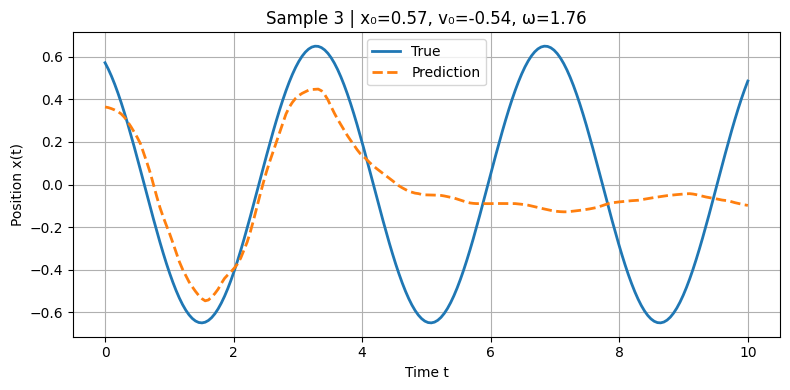
Model Prediction vs. Ground Truth (Position vs. Time) Initial model before making improvements
-
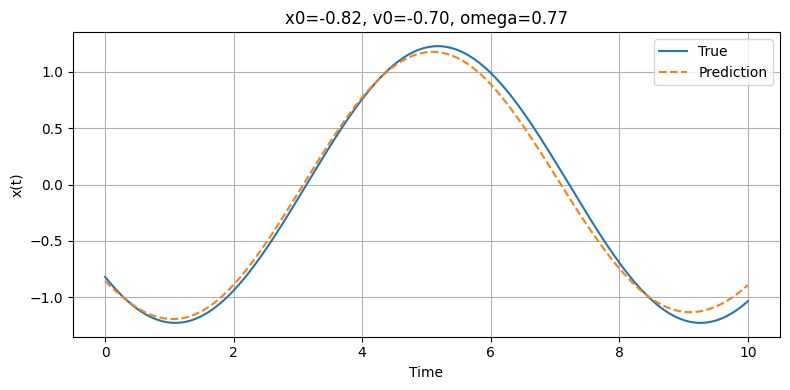
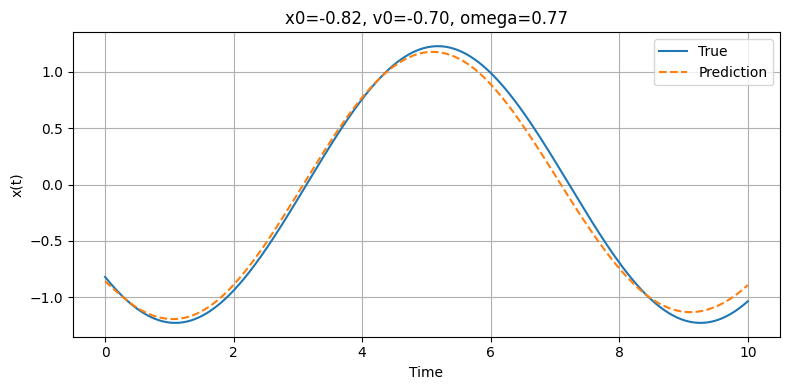
Model Prediction vs. Ground Truth (Position vs. Time)
-
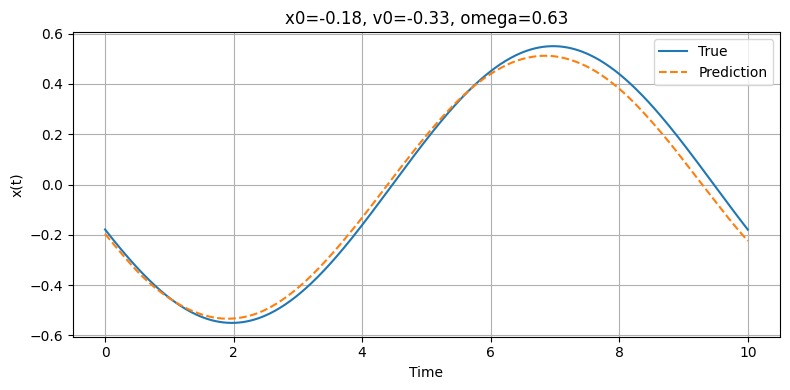
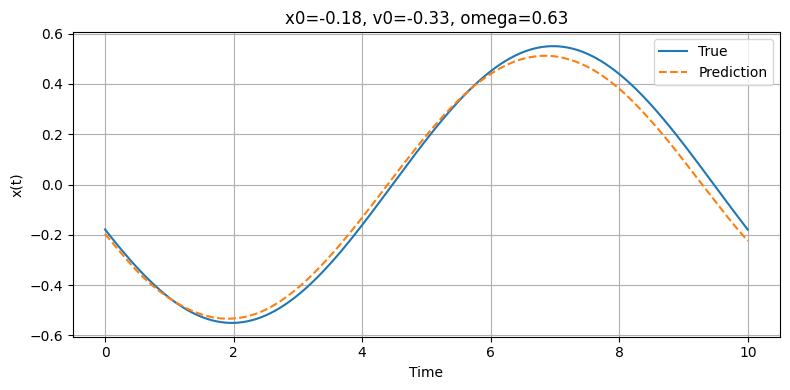
Model Prediction vs. Ground Truth (Position vs. Time)
-
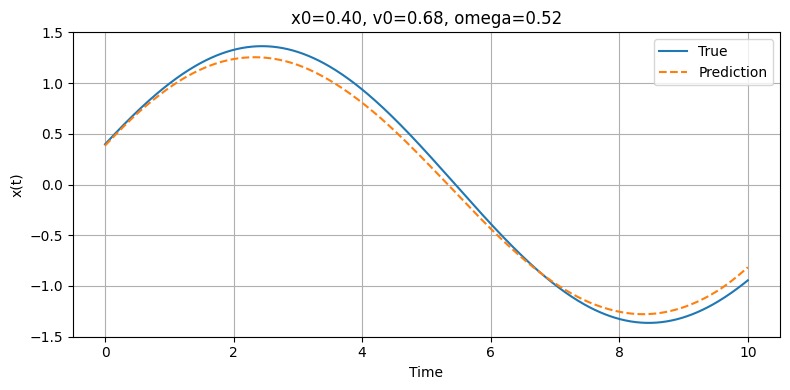
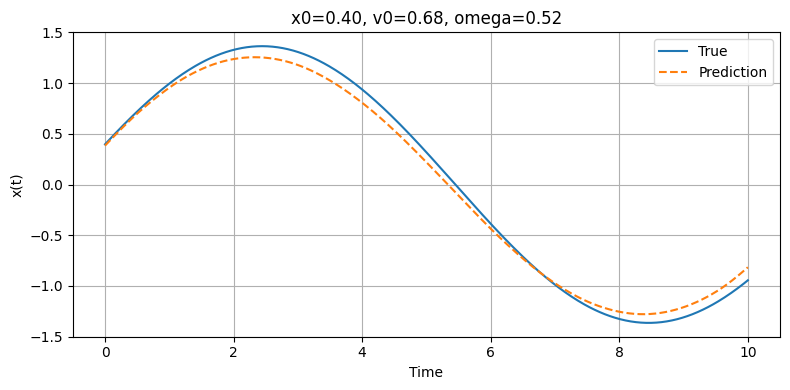
Model Prediction vs. Ground Truth (Position vs. Time)
Inspiration
We were inspired by the potential for deep learning to impact other real-world applications and scientific fields, specifically physics. We decided to explore the intersection between computer science and physics. Our project is inspired by a real-world application: https://github.com/neuraloperator/neuraloperator. This model is able to solve extremely complex mathematical equations by training the model to make predictions and correct itself. Similarly, we wanted to create our own model that can be applied to simpler mathematics for the application of physics.
What it does
Our deep model is designed to predict the position of a horizontally oscillating spring across a time interval of 10 seconds. Imagine a spring attached to vertical object such as a wall with some mass attached. After displacing the mass, the string will be stretched and will have a force opposing the direction of the displacement. Once the mass is released, the spring will oscillate back and forth. In real life, the spring will lose energy due to external forces such as air resistance and eventually will stop oscillating, but for our purposes we will assume that no energy will be lost and the spring would oscillate forever (in theory). Our model will predict the motion of the imaginary oscillating spring by plotting its prediction on a position vs. time graph. After each trial, it will compare its prediction to the true position vs. time graph and will calculate the margin of error. Following each iteration, the model will observe and learn from the error in an attempt to understand the pattern more accurately. As the model's understanding of the true expression increases, the model will become more accurate. Eventually, the model will be completed with all of its trials and will display one final prediction which will be the final result.
How we built it
We decided to use Python to code our project since Python has many built in libraries which would be very useful for our AI related project. We used several libraries from PyPI to build our model such as torch, numpy, matplotlib, and sklearn within our project. We first generate around 10,000 data points, 90% of which will be used to train the model, and the remaining 10% will be used to test the model. The model will use the data to train, and after each output, it will compare its own prediction with the actual true result. To learn from its own mistakes, it will go back and self-adjust its parameters so its next prediction would be more accurate and reduce error. After training the model, we will feed it the remaining 10% of the data which is unseen by the model. The model will try to make a prediction based on its training which will be displayed.
Challenges we ran into
The biggest challenge we encountered was attempting to decrease the error. At first, the model predictions were extremely inaccurate due to the model not having enough training. We fixed this by providing more data and more diverse data to help the model train. We also increased the amount of trials which increased the amount of time the model took but increased its accuracy. We had to decide between having a high run-time and a high accuracy or a lower run-time and less accuracy. We decided to find a middle ground so the model would still be fairly accurate without taking too long to run.

Log in or sign up for Devpost to join the conversation.