-
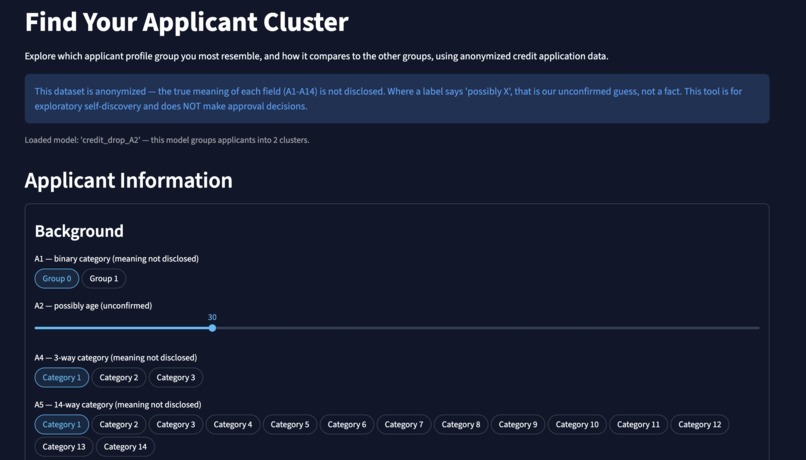
This is what the tool looks like for the user
Inspiration
Most credit tools are built for banks, not applicants. We wanted to make something that gives regular users a better idea of what kind of applicant profile they resemble without turning it into another approval prediction system.
What it does
Applicant Insight groups similar credit applicants into clusters using machine learning. Users enter anonymized applicant information and the app shows which applicant group they most closely match.
How we built it
We used Python, pandas, scikit-learn, and Streamlit. The data was cleaned, scaled, and one-hot encoded before training K-Means clustering models. We also used PCA to help visualize the clusters.
Challenges we ran into
The biggest challenge was working with anonymized data. Since the feature meanings were hidden, it made preprocessing, fairness decisions, and cluster interpretation a lot harder than usual.
Accomplishments that we're proud of
We’re proud that we built a full working pipeline from preprocessing and clustering to a usable frontend in a short amount of time. We also put a lot of thought into fairness and feature selection instead of just throwing a model together.
What we learned
We learned how important preprocessing is for clustering and how difficult fairness decisions can become when you don’t fully know what the features represent. I learned a lot about K-means and what K really means. lol
What's next for Applicant-Insight
We want to improve cluster explanations, add better visualizations, and experiment with other clustering methods to see if we can find even more meaningful applicant patterns. Possibly find more data.
Built With
- numpy
- pandas
- scikit-learn
- seaborn
- streamlit

Log in or sign up for Devpost to join the conversation.