-
-
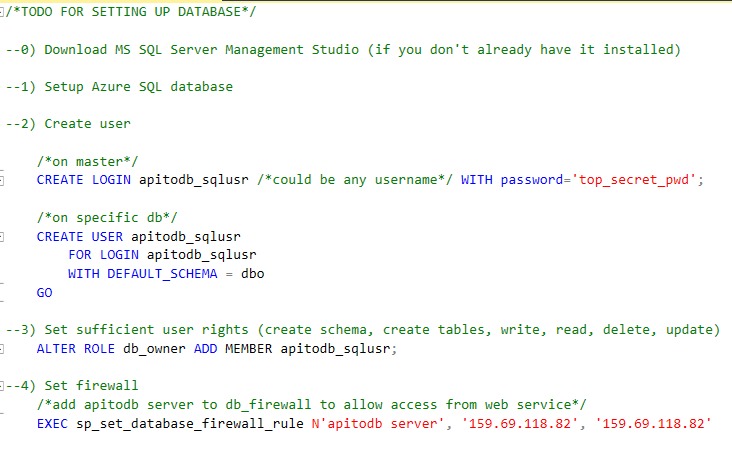
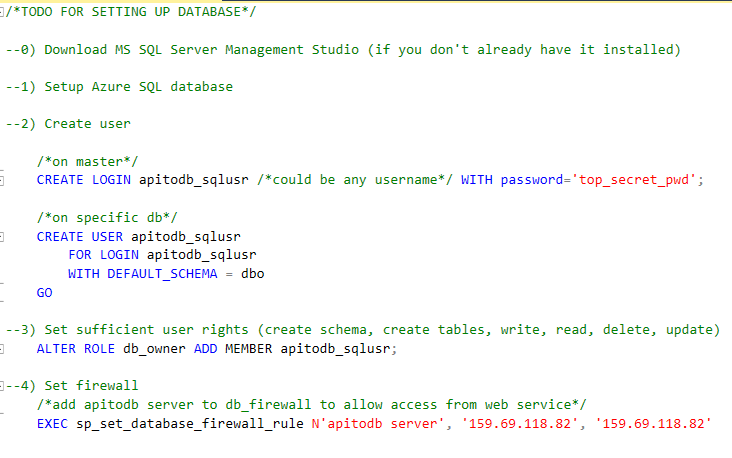
Todo when setting up a database for the API to DB service
Inspiration
As a Business Intelligence consultancy company we are often facing the challenge of moving data from REST apis to relational database tables to build datawarehouses for our customers. We have done a lot of prototyping on how we can make the task more generic to save time. We always use Postman for exploring the Apis we are connecting to - so we asked ourselfs “Why not use the Postman collections and the Postman API to work as our configuration of the data load and not only as a tool for exploration?” This has been the basis of this hackathon project.
What it does
1) We set up a collection of get requests in Postman. Each endpoint represents a dataset, that we would like to automatically load into a database table.
2) We connect to the Postman collection using the Postman API to extract the full configuration of URL, authentication, headers etc.
3) Our load script then automatically loads data from the API endpoint specified, Reads the metadata of the JSON returned to specify tables, columns and data types. Tables are then created automatically and data is then inserted to the table(s).
How we built it
We use Python and Azure SQL databases.
Challenges we ran into
Reading metadata of JSON, and especially nested JSON was quiet complicated.
Accomplishments that we're proud of
Setting up a complete data load, that is fully configurable from Postman. It will be a very usefull tool for us in the future, since the work steps have been simplified a lot.
What we learned
We have learned how we easily can subtract collection information out of the Postman API. We have also learned that streamlining this workflow has a lot of potential - at least within the field of Business Intelligence, where setting up scheduled data loads can be very time consuming, if you are not using effective tools that automates some of the work.
What's next for API to DB
We now have a working prototype! However please be aware, that it has a few limitations, that we are all working on..
- a better performance when loading very large datasets (qued jobs not running on the browser side)
- currently we only authenticate header-based APIs, we are looking into multiple authentication types (token based, Bearer etc.)
- pagination (currently we only load the first page of data returned from the API)
Try it out!
Review the video to see the full tutorial and then setup your free account. Please send us all of your feedback to datarocks@datawareness.dk

Log in or sign up for Devpost to join the conversation.