-
-
Presentation
-
Presentation
-
Presentation
-
Presentation
-
Presentation
-

Presentation
-
Presentation
-
Presentation
-

Presentation
-
-

-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-




Inspiration
My cousin has aphasia from birth, which means for his whole life he struggled to pronounce words and being able to effectively communicating himself. For this project the first goal is to see if I can properly translate what Aphasia patients say to text and identify where they likely make mistakes in their language.
What it does
Translates what Aphasia patients say to text and identify where they likely make mistakes in their language.
How we built it
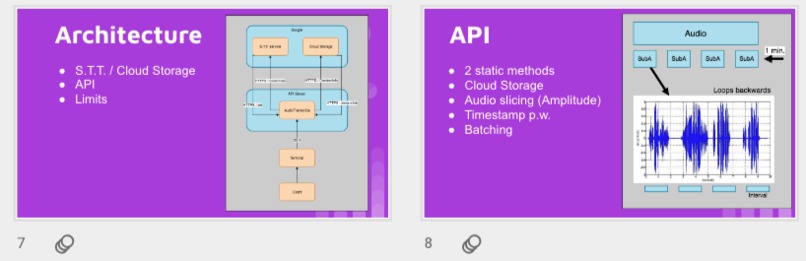
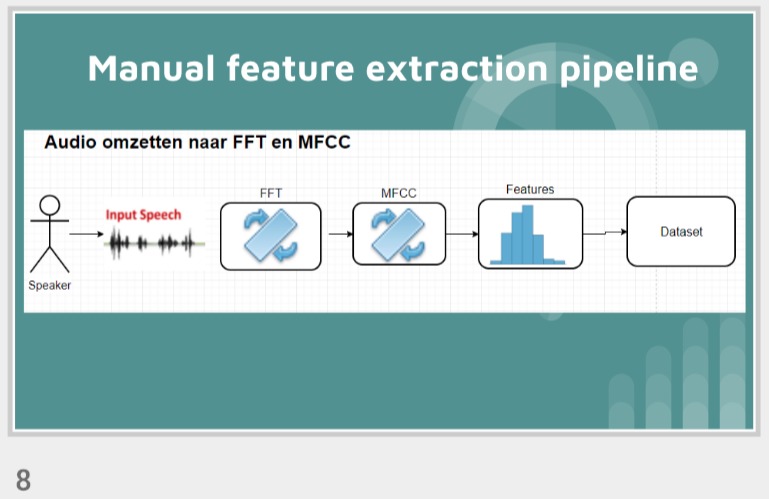
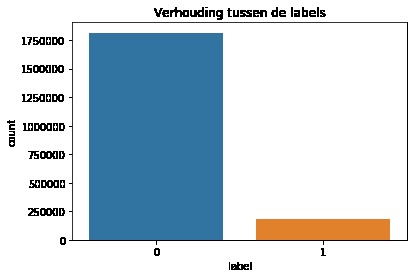
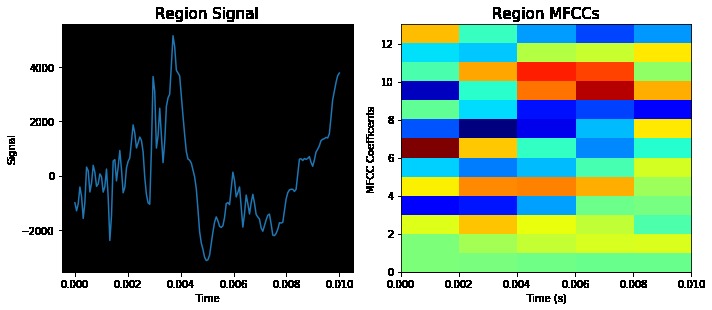
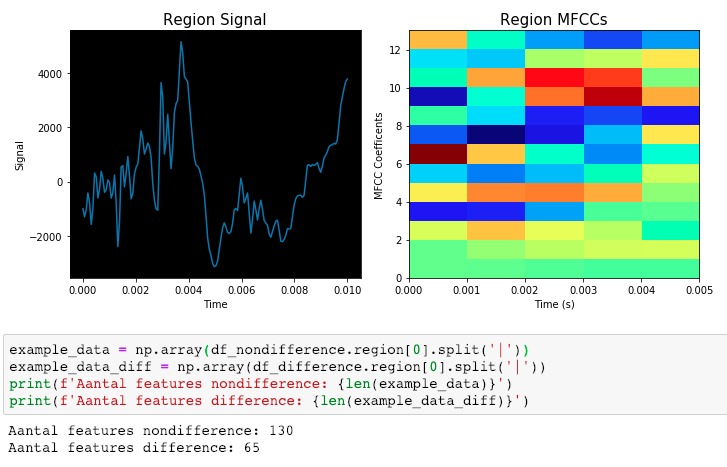
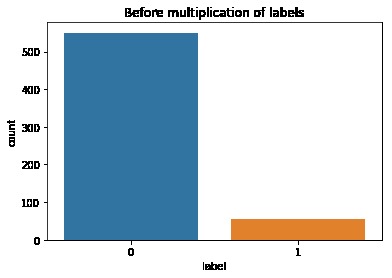
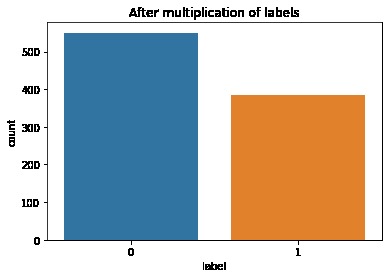
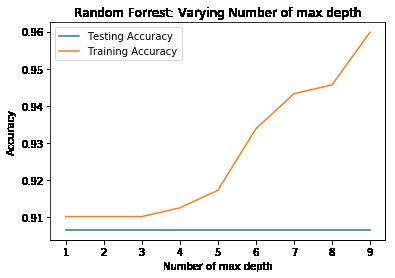
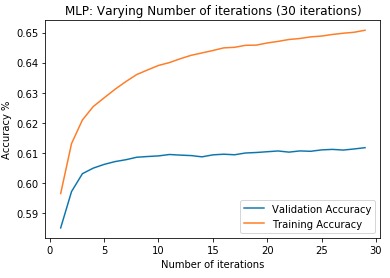
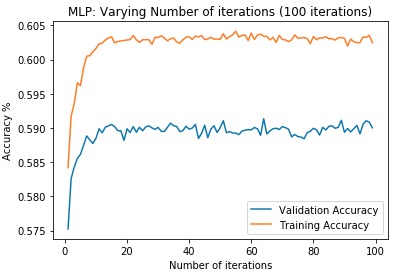
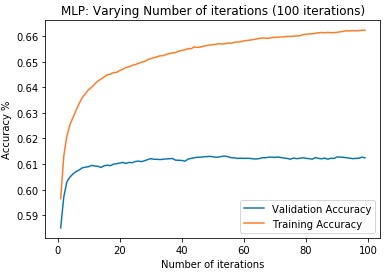
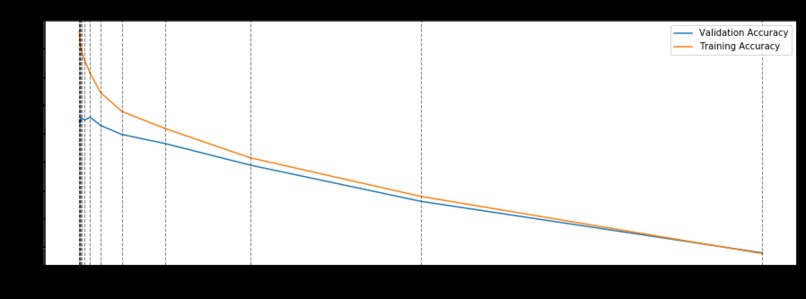
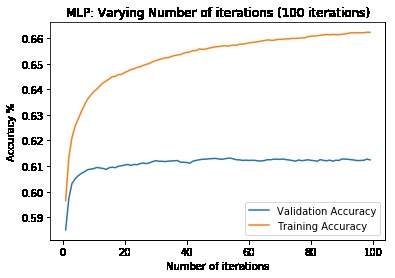
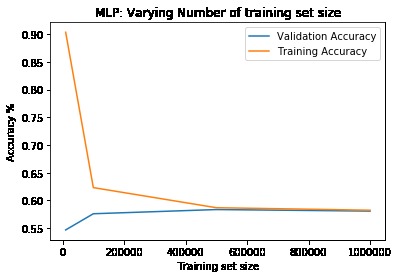
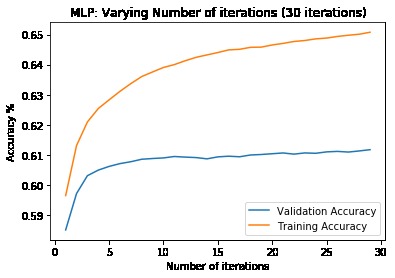
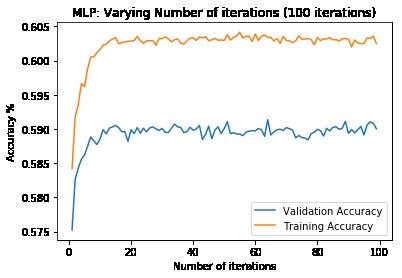
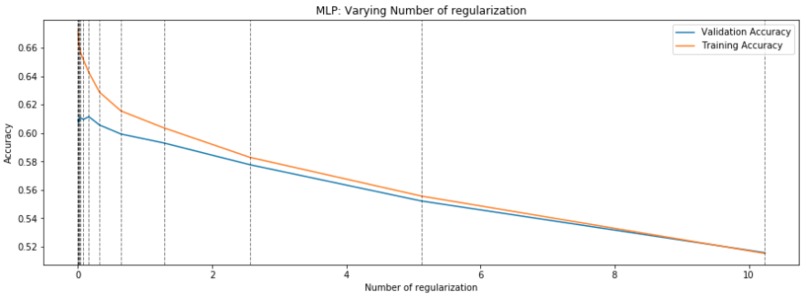
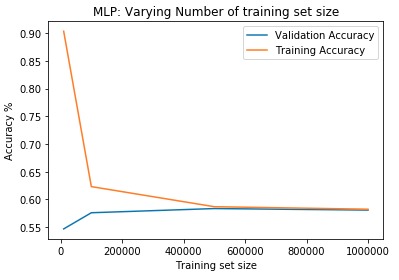
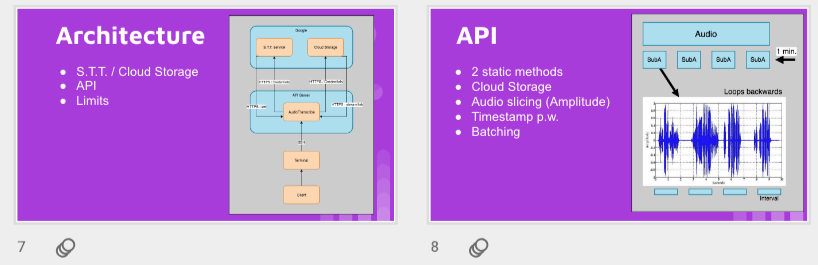
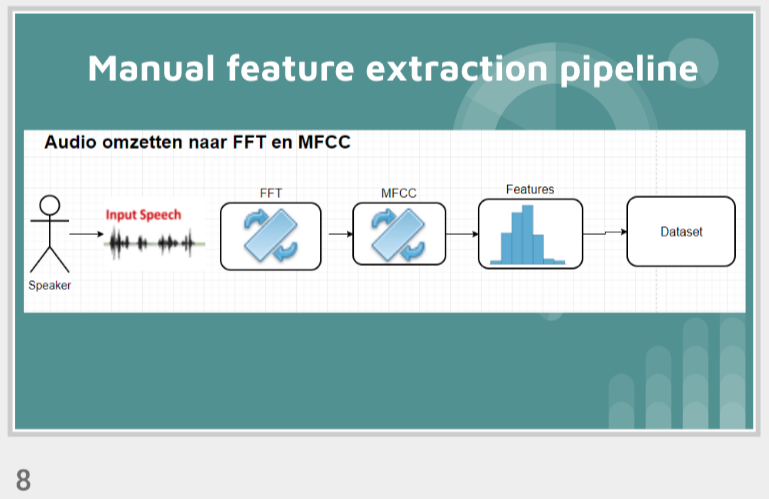
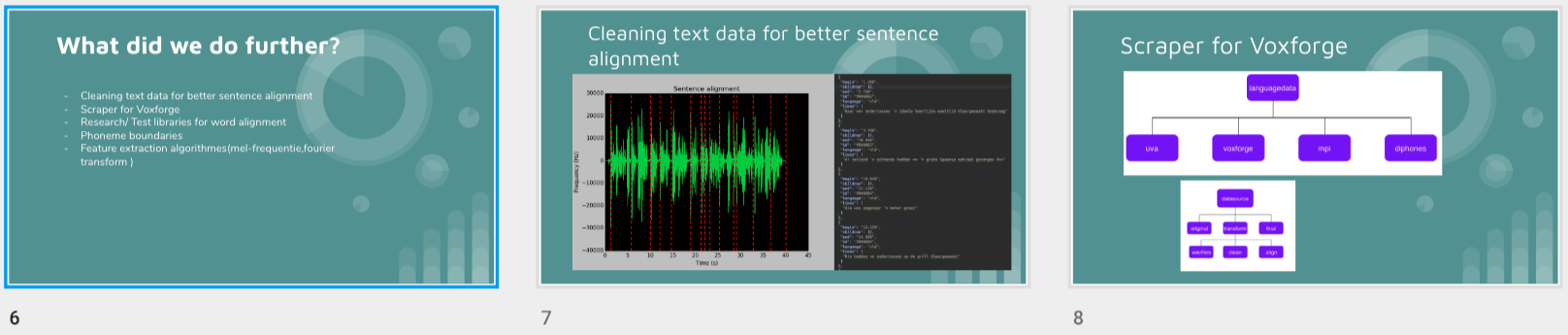
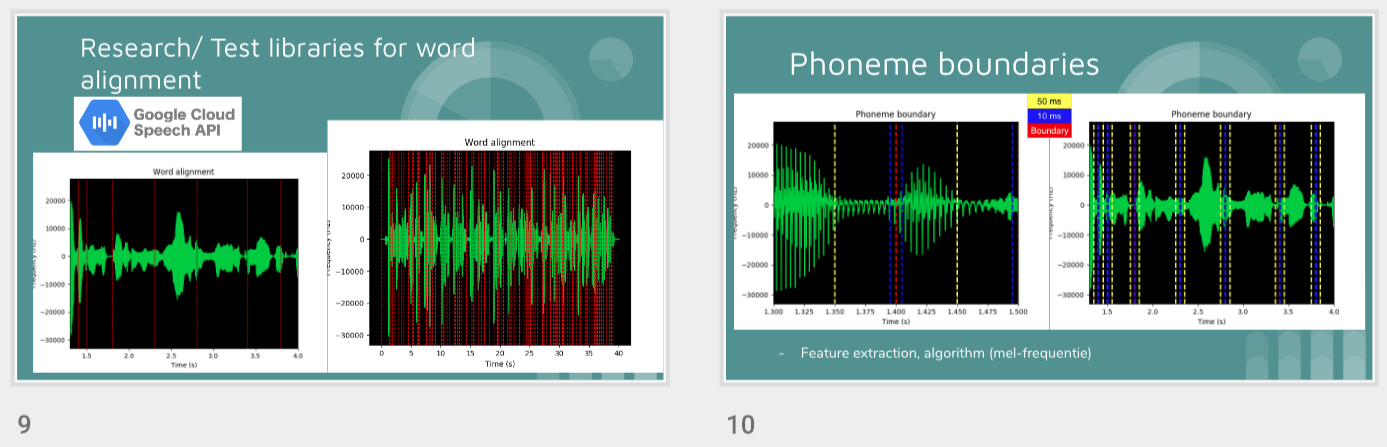
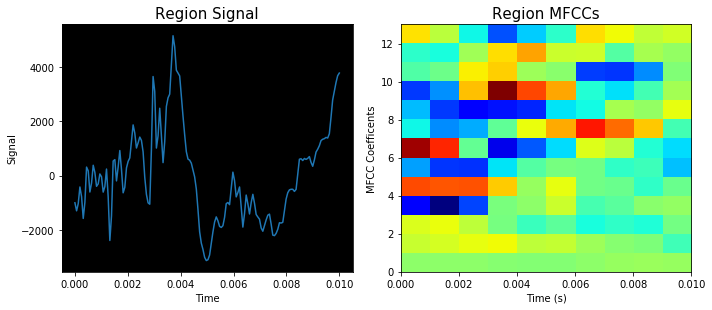
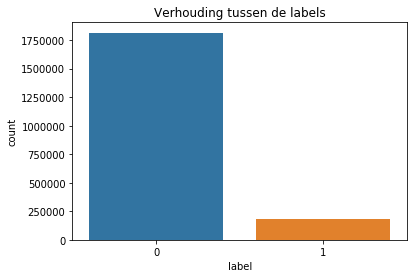
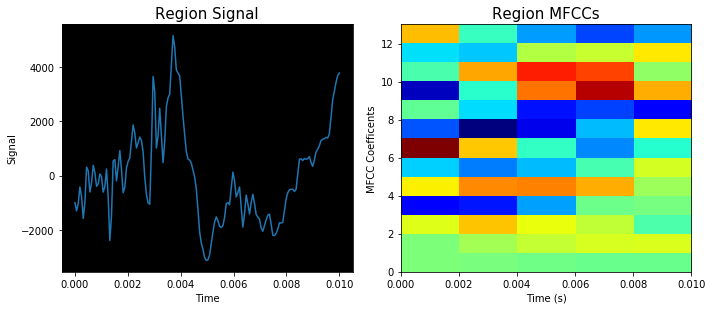
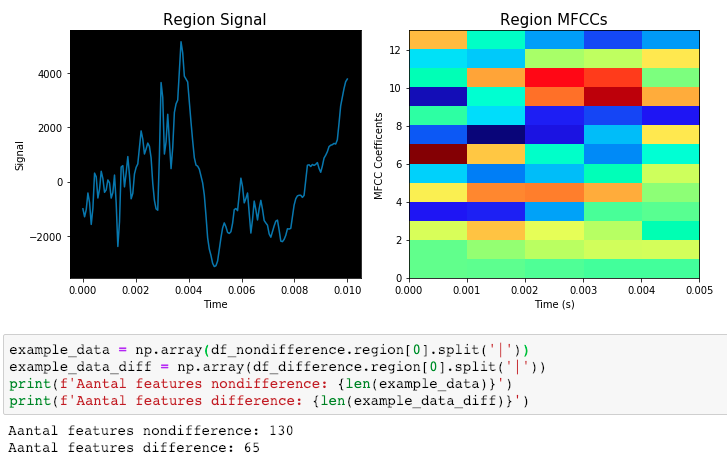
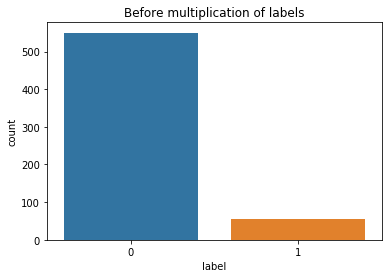
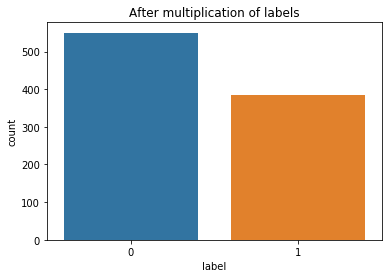
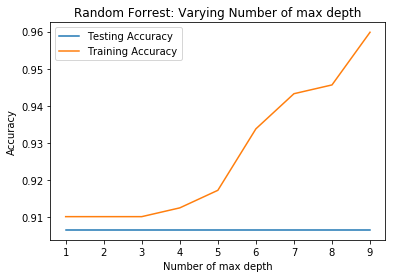
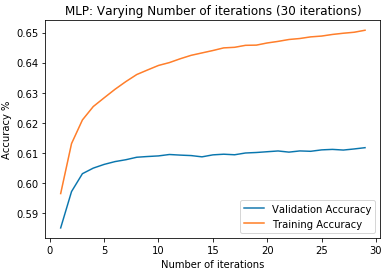
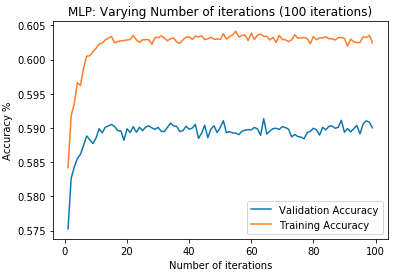
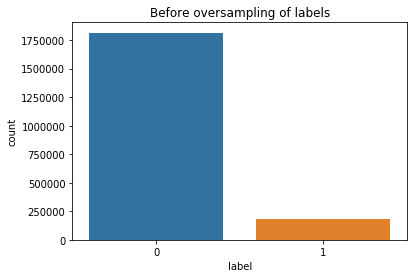
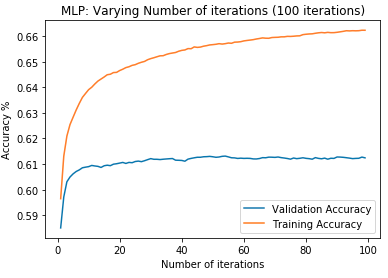
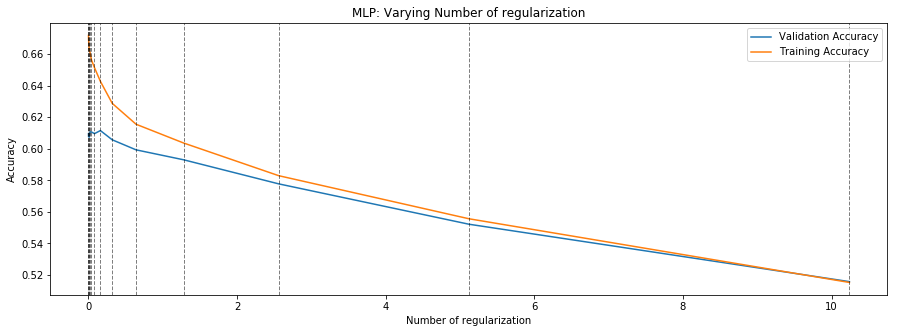
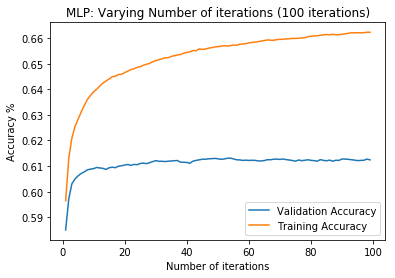
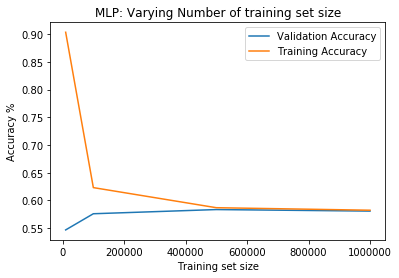
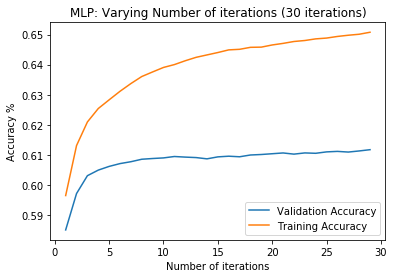
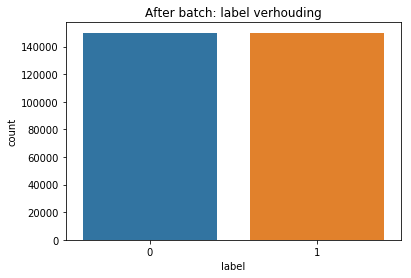
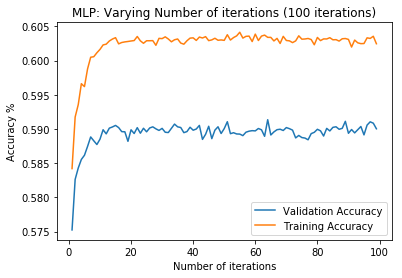
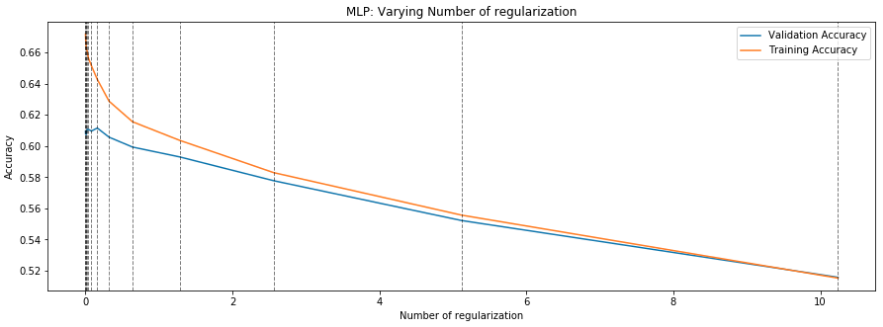
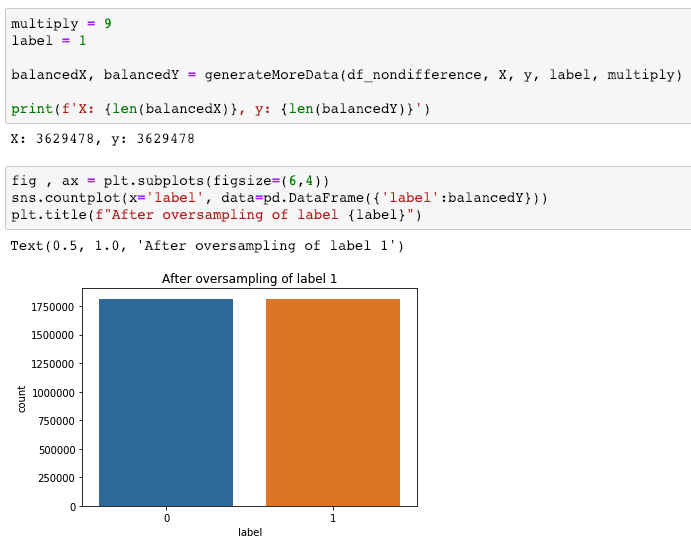
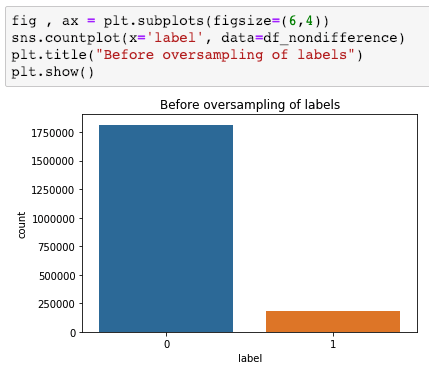
First, data has been collected from different sources. The sources are "VoxForge", "Uva" and "CORPUS". Developed API to quickly convert the process of audio files to text. Otherwise, that process had to be done manually which takes a lot of time. In addition, this API also has the function to get the timestamps of per word in an audio signal. This was important to be able to create a data set for future use, e.g. for a neural network. An aligner script has been developed for this project. The aligner was important to be able to generate data as training set for SPHINX (a ready-to-use Speech to Text tool). For the data of CORPUS, a transformer has been written that transforms the data of CORPUS to the desired structure consisting of columns "begin", "end", "word" and "audiopath" and save as CSV file. This data is used with the Phoneme Boundary Generator which then generates a new data set for the Phoneme Boundary Classifier . See notebook for further information. After "Data Collection" and "Data Preperation" topics, which have put the data in a desired structure, a Phoneme Boundary Generator has been developed. What this generator does is generate phoneme boundaries as data by concatenating the last N milliseconds of a word and beginning N milliseconds of the next word. This dataset is for training a Phoneme Boundary Classifier. In this project, not only data collection or data preparation was important, but also the development and training of a Phoneme Boundary Classifier. In order to train a Phoneme Boundary Classifier model with the collected Dutch-language CORPUS data, a number of machine and deep learning models have been tested. The models are: Random Forest Classifier MLP (Multi Layer Perceptron) Bi-LSTM (bi-directional Long Short-Term Memory) For some of the above models, Scikit-Learn and Tensorflow Core library have been used.
One reason for using the Tensorflow Core is more customization options such as selection of the GPU cores, application of activation function per neural network layer and it is more suitable for developing deep learning networks.
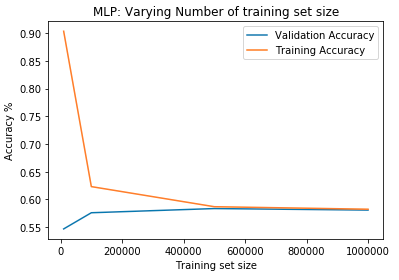
These models have been trained with the data generated by the Phoneme Boundary Generator (CORPUS NL) to develop a Phoneme Boundary Classifier.
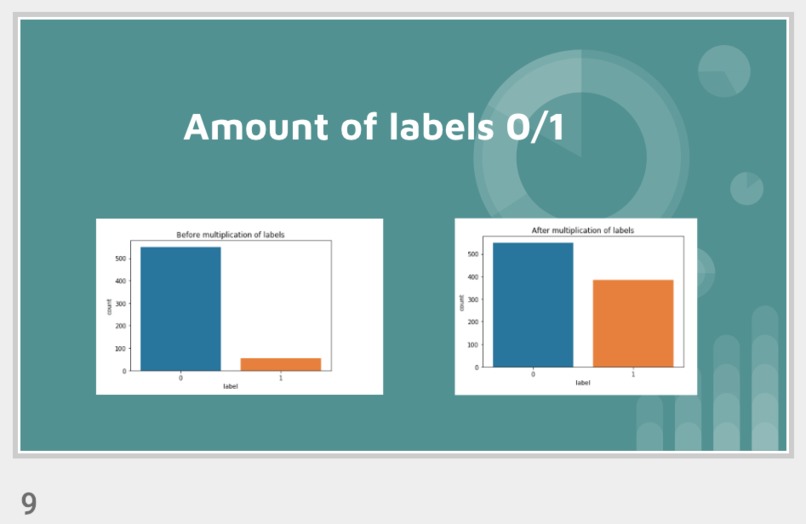
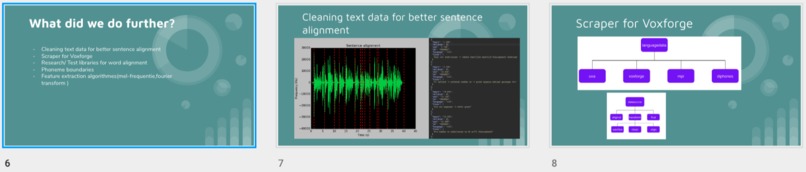
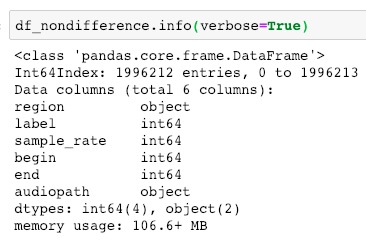
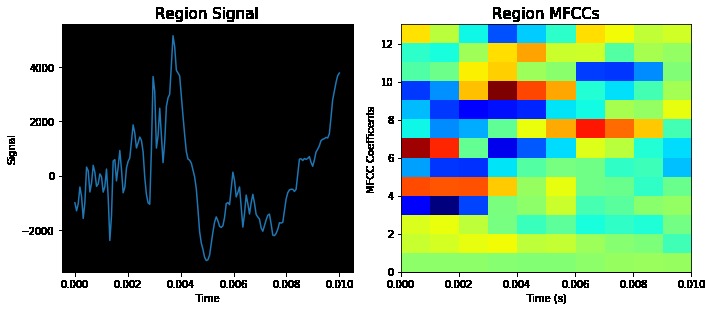
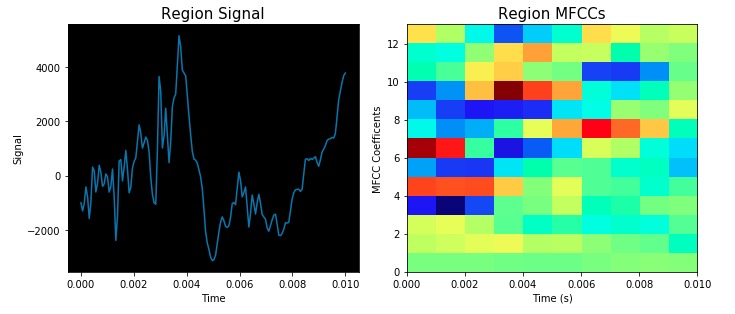
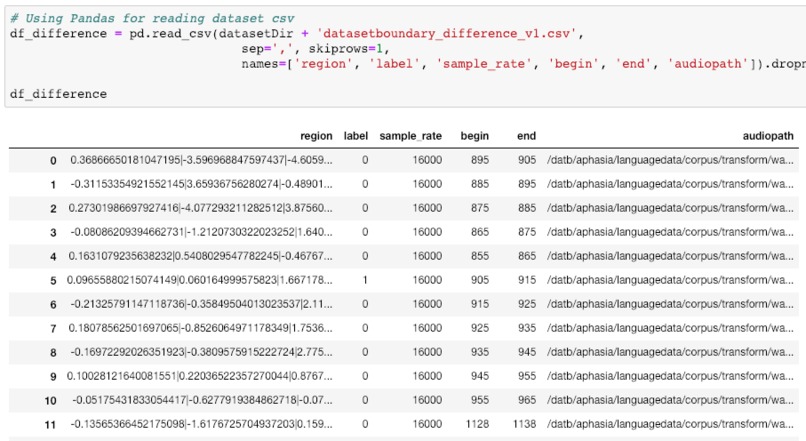
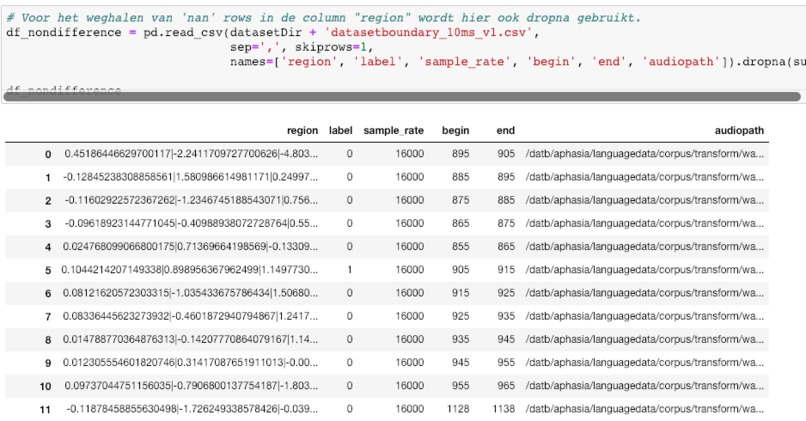
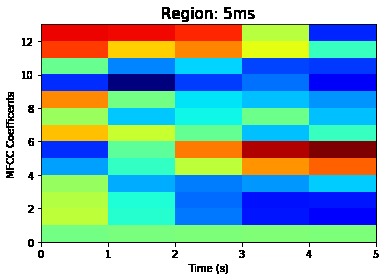
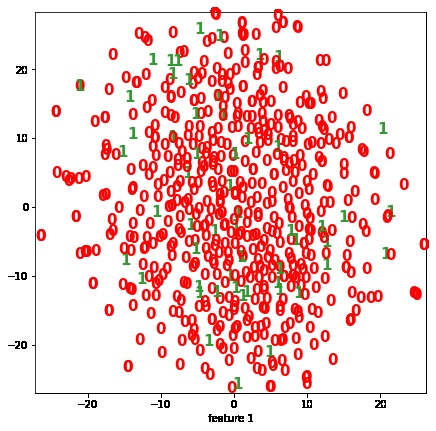
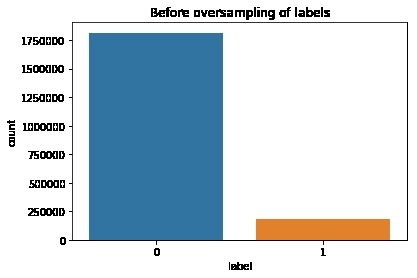
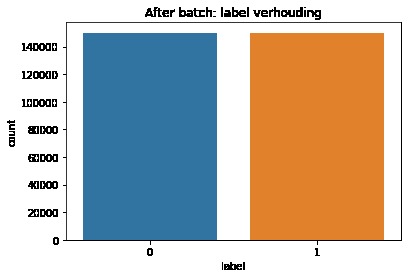
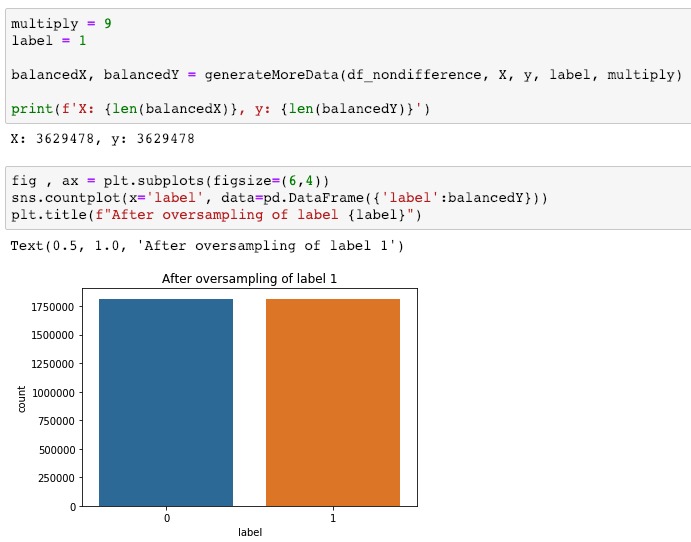
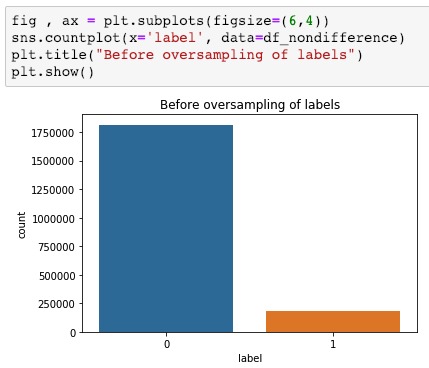
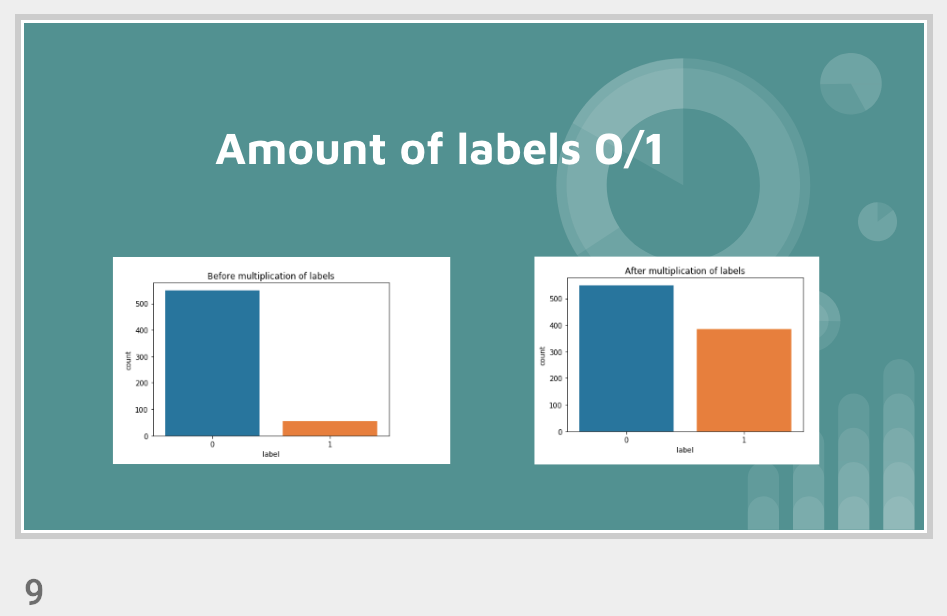
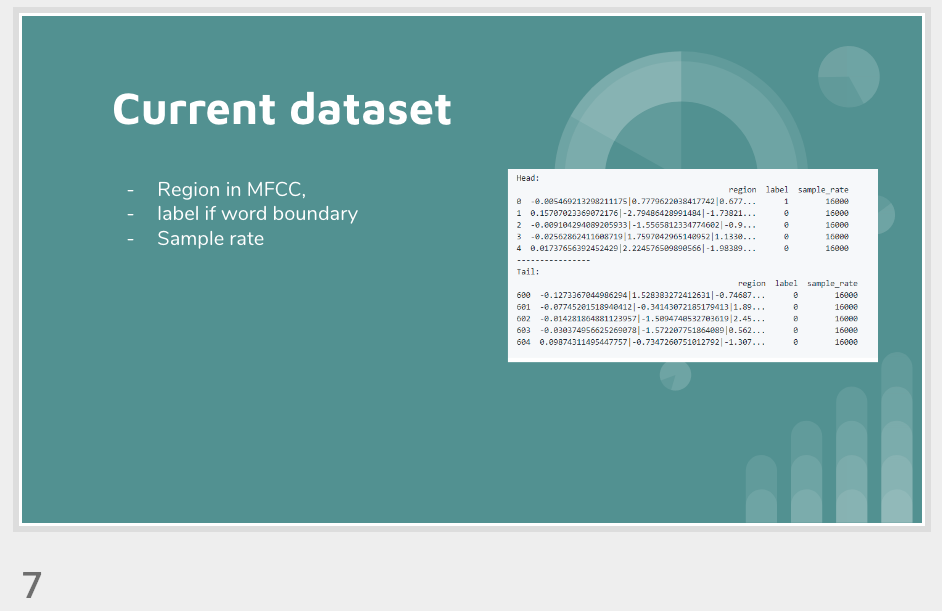
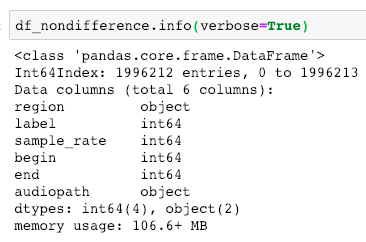
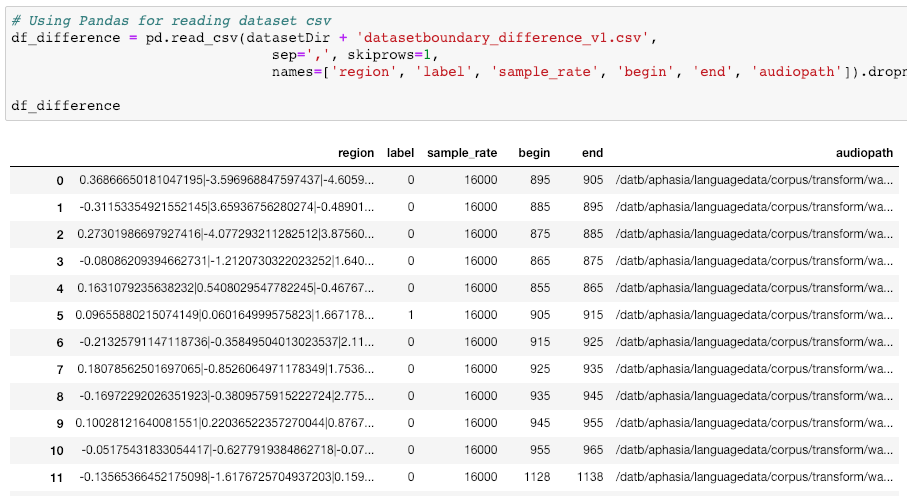
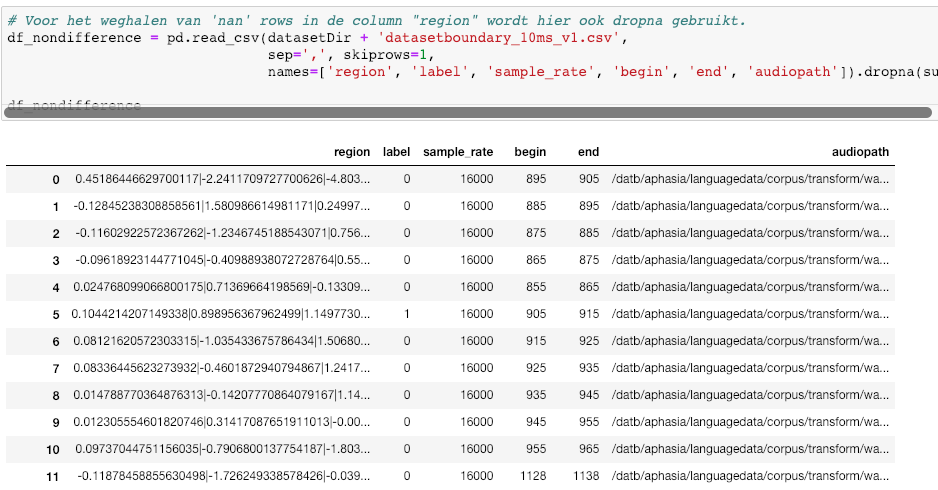
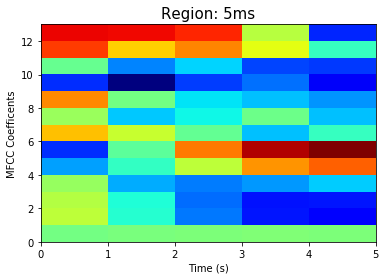
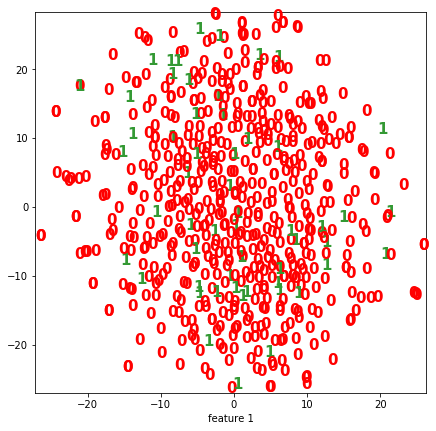
Visualization of the datasets generated by V2 and V3 generators. Each dataset consists of the columns "region", "label", "sample_rate", "begin", "end" and "audiopath".
Running out of space here. Full descriptions are in GitHub Readme
Challenges we ran into
The hardest part is actually getting data for this project. Aphasia datasets are pretty rare so it took me a while to find and collect good data. I also took a while finding good speech-to-text libraries as some of them don't work that well.
Accomplishments that we're proud of
Built a complete project that has impact on the world and improved my data science skills by going through the full process of creating a model.
What we learned
How to train Phoneme Boundary Classifier model with the collected data.
What's next for Aphasia Translation/Mistake Detection with MFCCs and SPHINX
In the future, when there are more aphasia datasets available, I hope to train this model on more languages so that every person around the world will be able to use it.
Built With
- beautiful-soup
- librosa
- matplotlib
- numpy
- pandas
- pydub
- python
- scikit-learn
- seaborn
- tensorflow

Log in or sign up for Devpost to join the conversation.