-
-
Start page
-
Recording audio
-
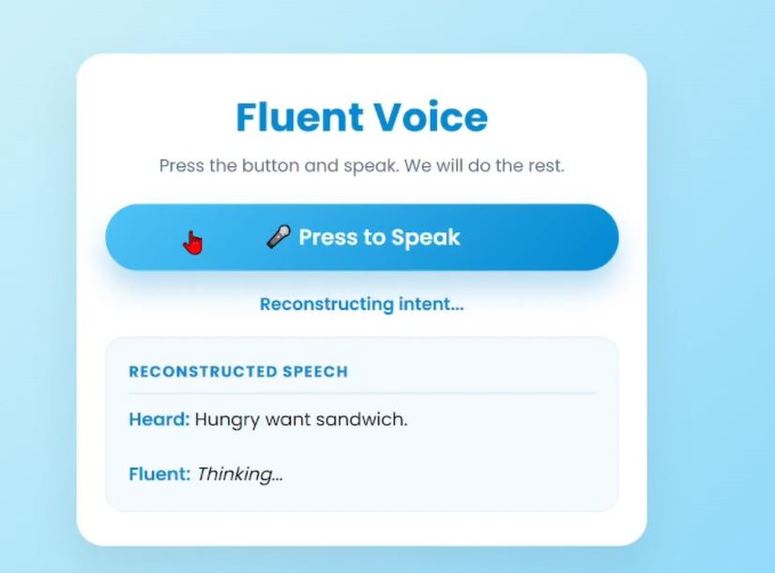
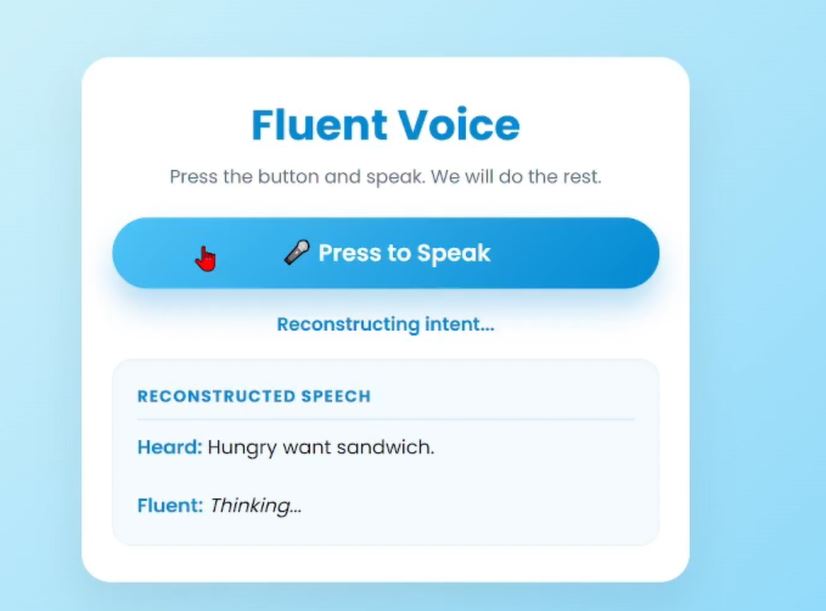
Processing the recorded audio
-
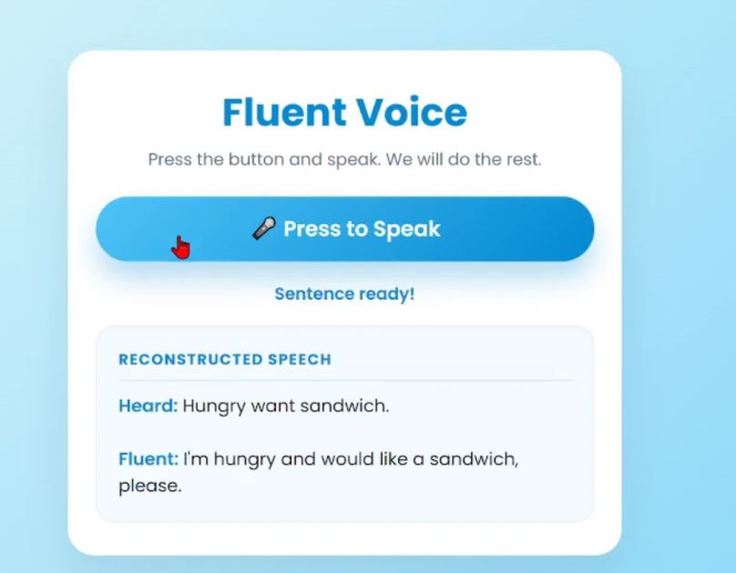
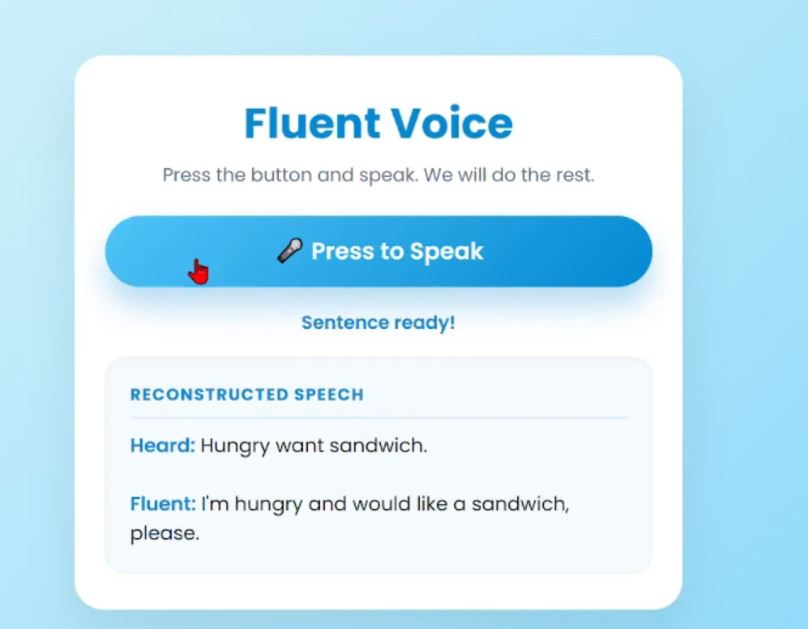
Fluent text and audio generated
Inspiration
Millions of people deal with aphasia after a stroke or brain injury. They know exactly what they want to say, but their words come out in broken fragments like water cold please. Current tools rely on tapping pictures on a screen, which feels slow and unnatural. I wanted to build something that actually listens to their voice and helps them communicate smoothly without losing their dignity.
What it does
Aphasia Fluent Voice acts as a real time translator for broken speech. A user presses a button and speaks their thoughts, even if the words are disjointed or stuttered. The app listens, figures out what they are trying to say, and then speaks a complete and grammatically correct sentence out loud for them.
How we built it
I built the frontend using plain HTML, CSS, and JavaScript so it runs right in the browser without any heavy downloads. For the backend logic, I connected the browser audio recorder to the Groq API using the Whisper large v3 model for incredibly fast speech to text. Then I passed that text to Google Gemini 2.5 Flash. I wrote a strict prompt telling Gemini to act only as an intent reconstructor. Finally, I used the native Web Speech API to read the new sentence aloud. The whole thing is hosted on GitHub Pages.
Challenges we ran into
Figuring out how to capture audio in the browser and send it properly to an API was tricky. Dealing with raw audio blobs in JavaScript took a lot of trial and error. Another big challenge was getting the AI to behave. At first, Gemini kept adding conversational filler like sure here is your translated sentence before giving the actual output. I had to spend a lot of time tweaking the system prompt to force it to only return the final sentence.
Accomplishments that we are proud of
I am really proud of the speed. By combining Groq and Gemini, the app processes the audio and speaks the final sentence in just a couple of seconds. I am also proud of the user interface. It is a clean sky blue design with large touch targets, making it very accessible for people who might have limited motor control.
What we learned
I learned a ton about browser APIs, specifically the MediaRecorder and Web Speech APIs. I also learned how powerful prompt engineering can be when you need a language model to perform a strict programmatic task instead of just chatting. Most importantly, I learned that you can build incredibly fast AI tools without needing a complex backend server.
What is next for Aphasia Fluent Voice
The biggest next step is adding voice cloning. Right now the app uses the default browser voice, but I want to integrate technology that allows the app to speak using a clone of the patient actual voice from before their stroke. I also want to explore running smaller models directly on the device so the app works completely offline.

Log in or sign up for Devpost to join the conversation.