-
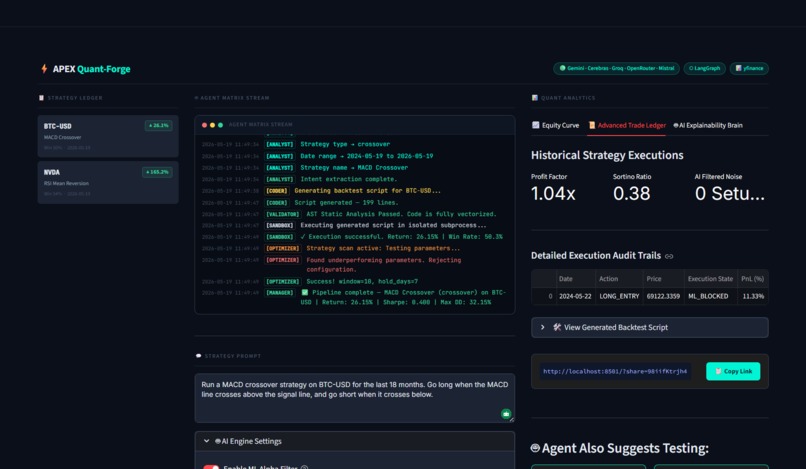
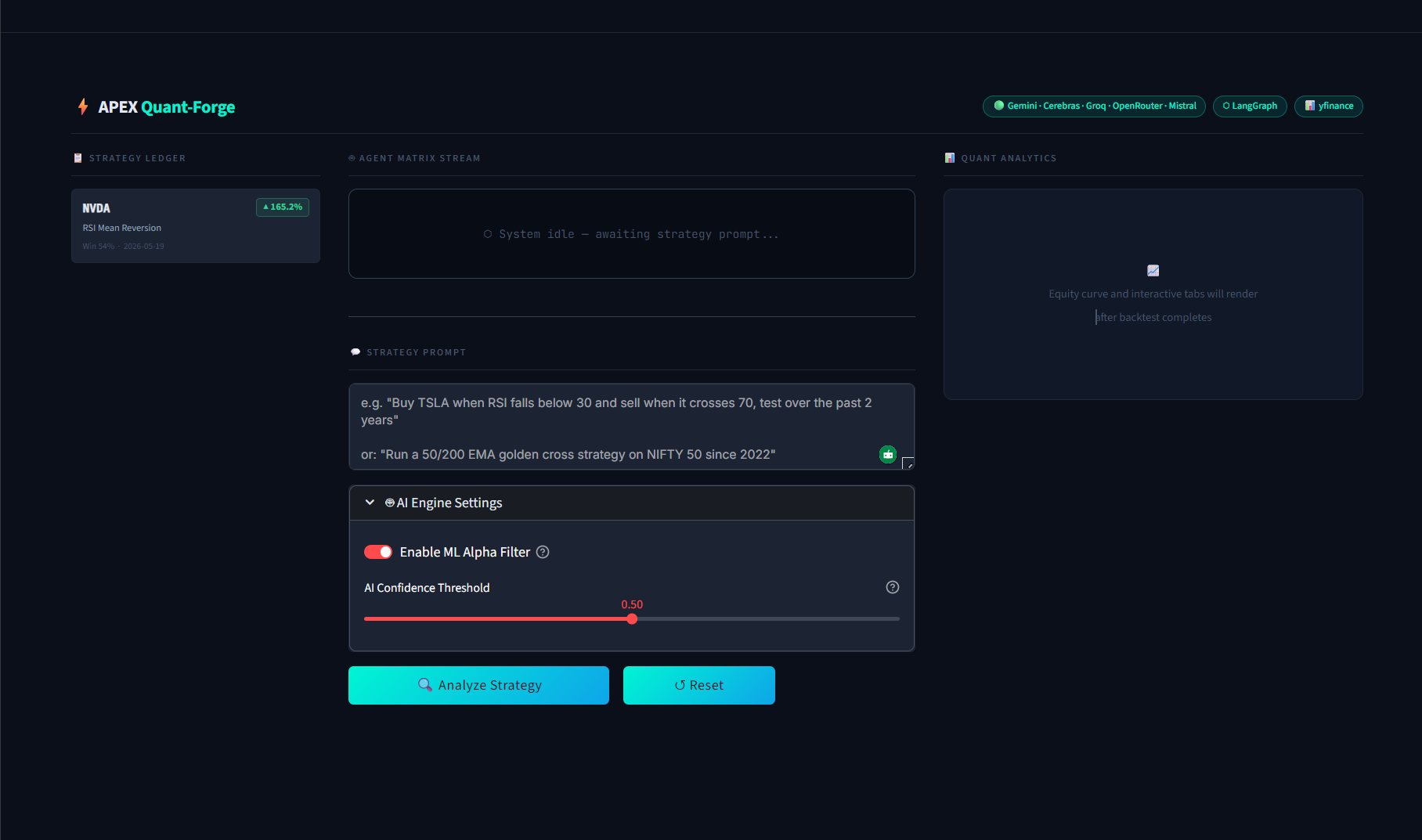
Typing a natural language trading strategy into the APEX Quant-Forge workspace.
-
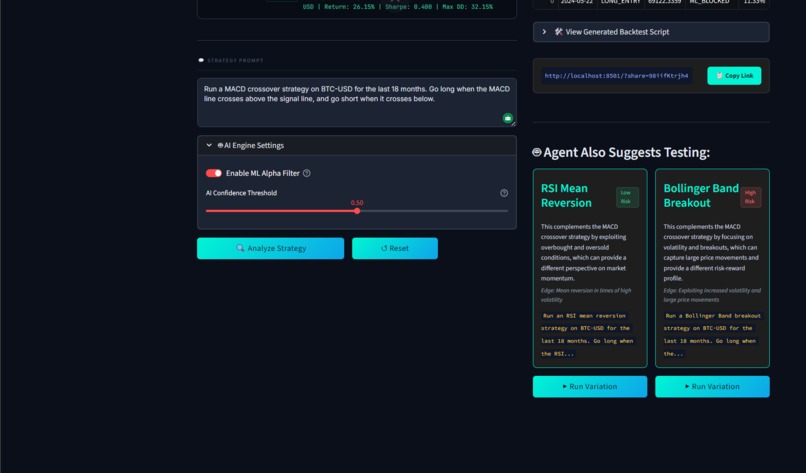
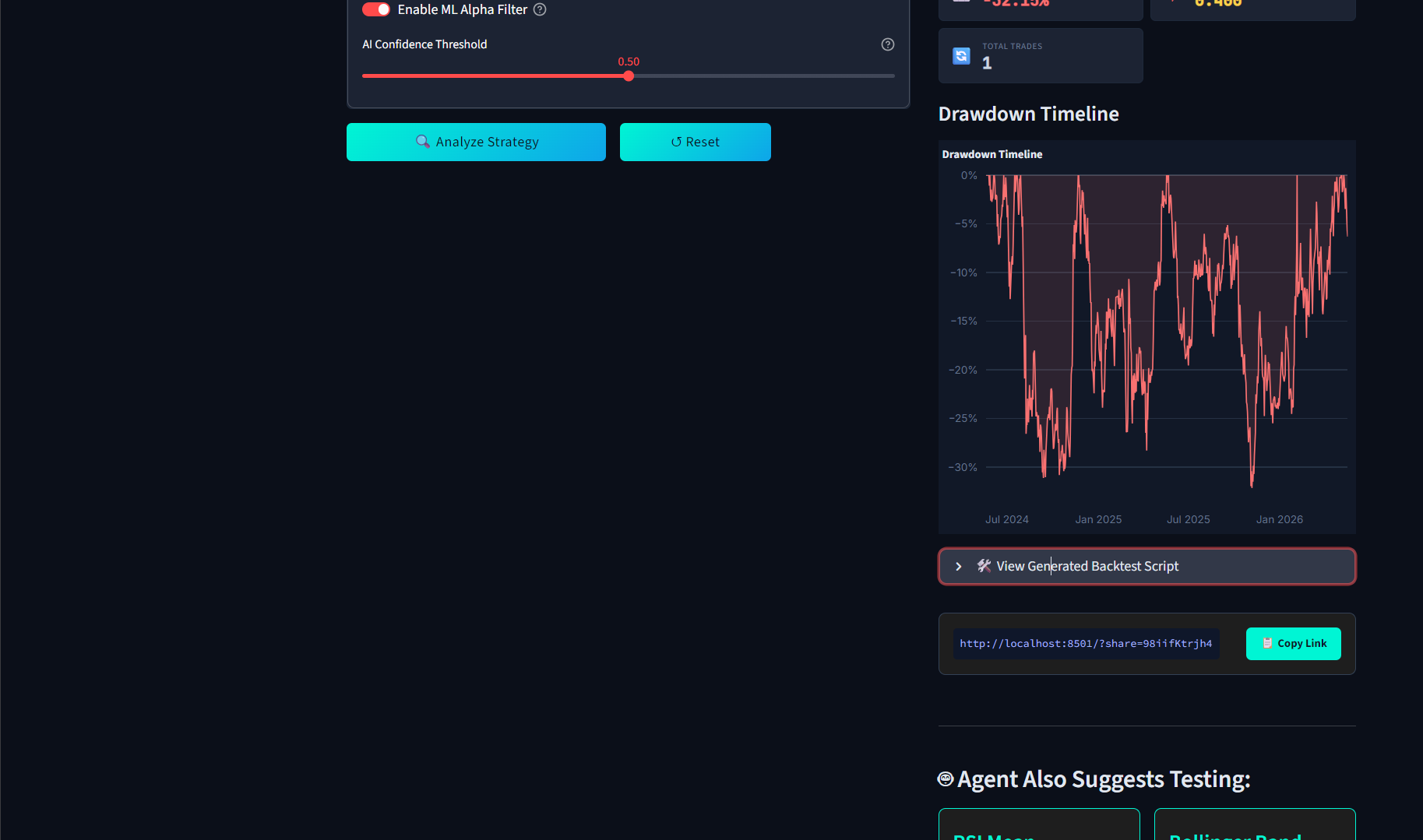
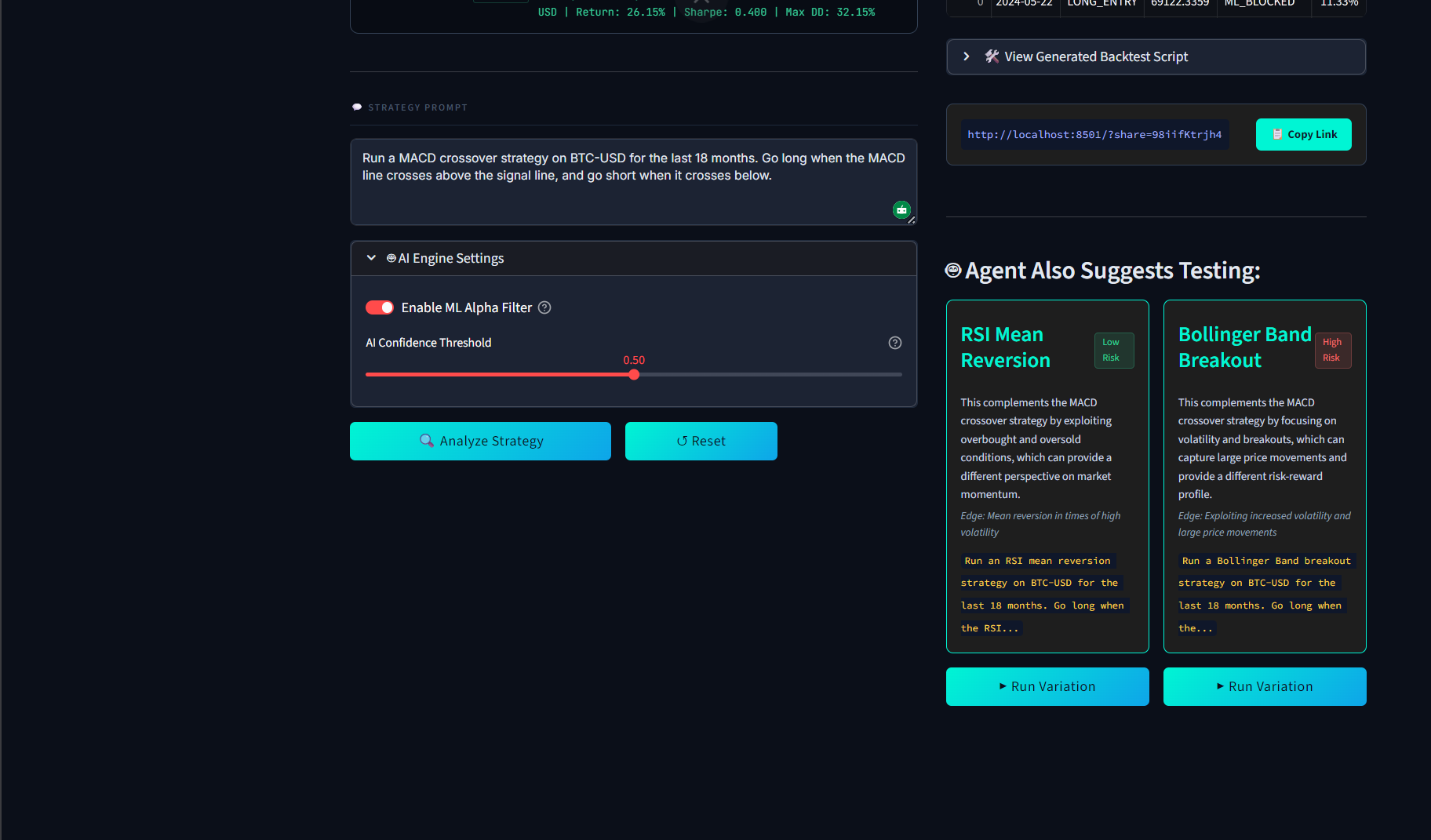
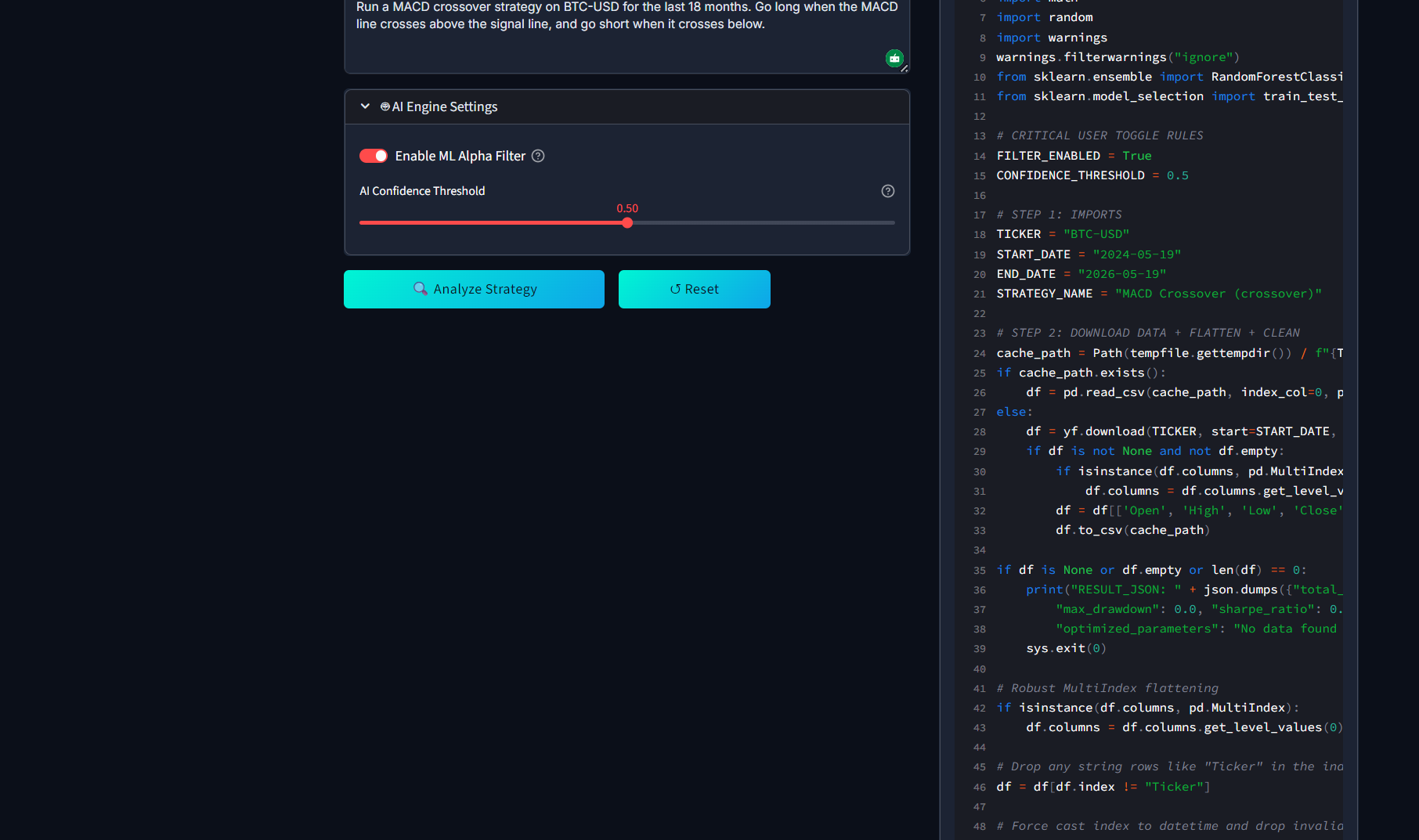
Enabling the on-the-fly Machine Learning Alpha Filter and configuring the AI confidence threshold
-
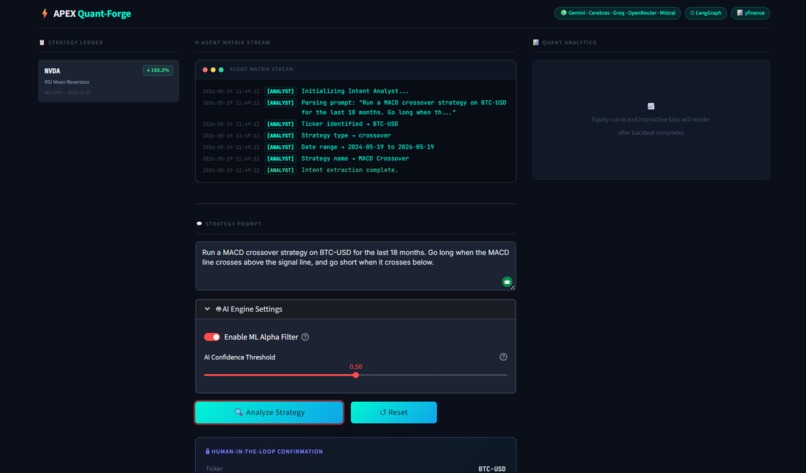
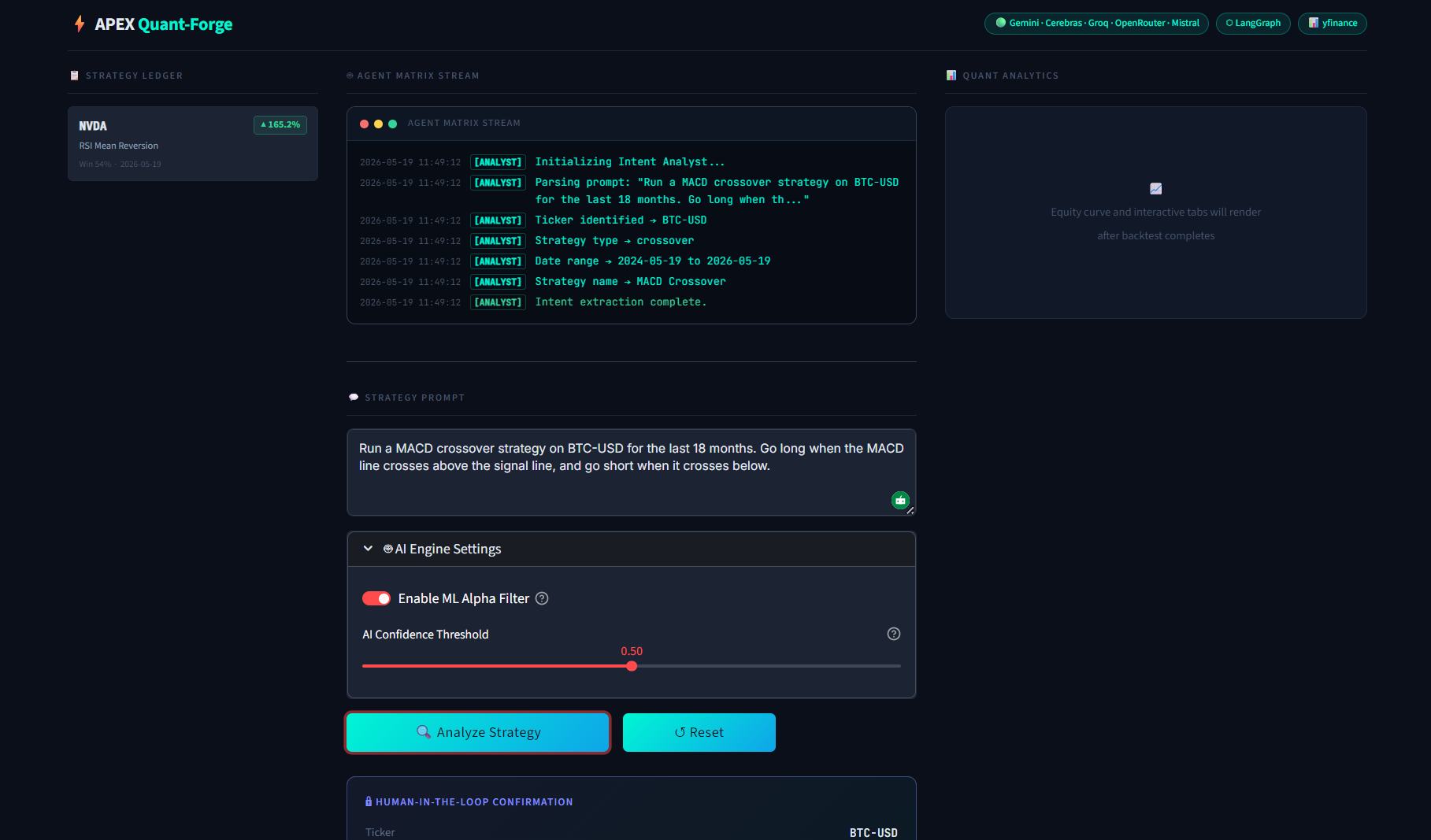
The AI Analyst dynamically parses the plain English prompt into structured parameters.
-
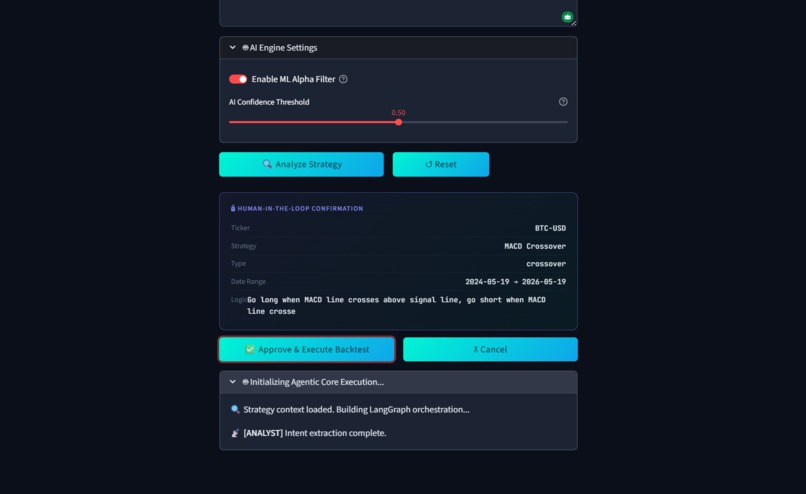
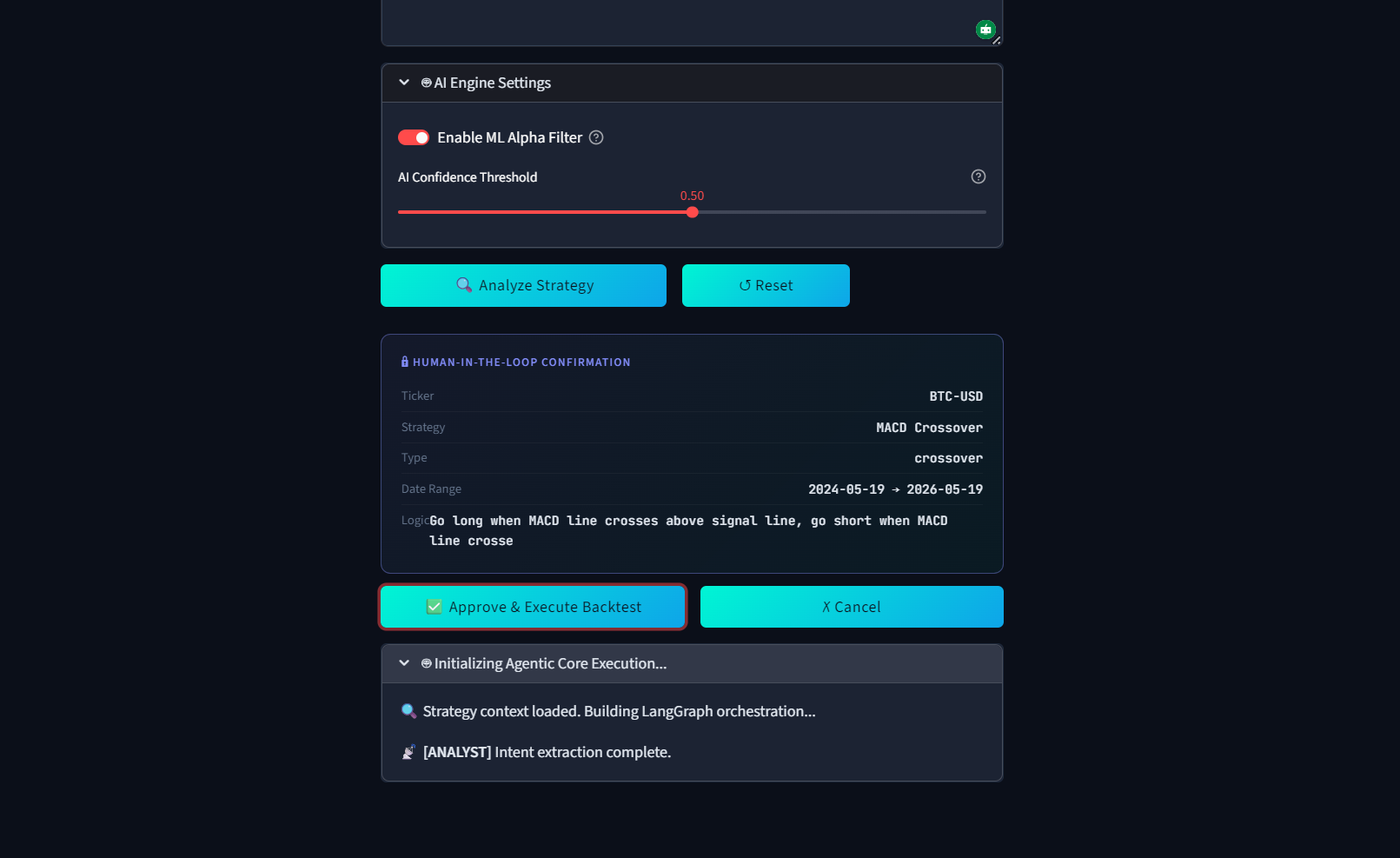
Reviewing the AI's extracted logic and conditions before approving the backtest execution.
-
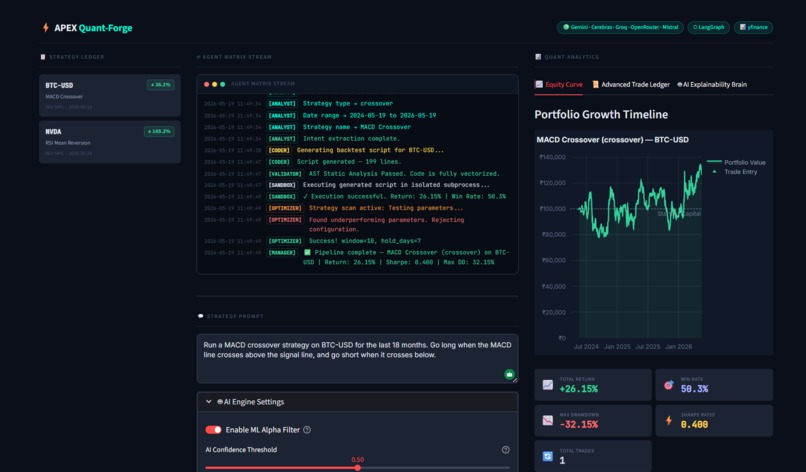
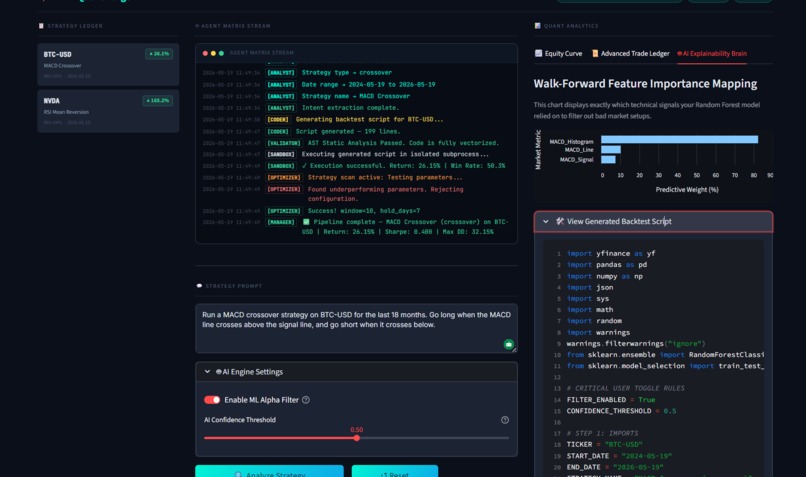
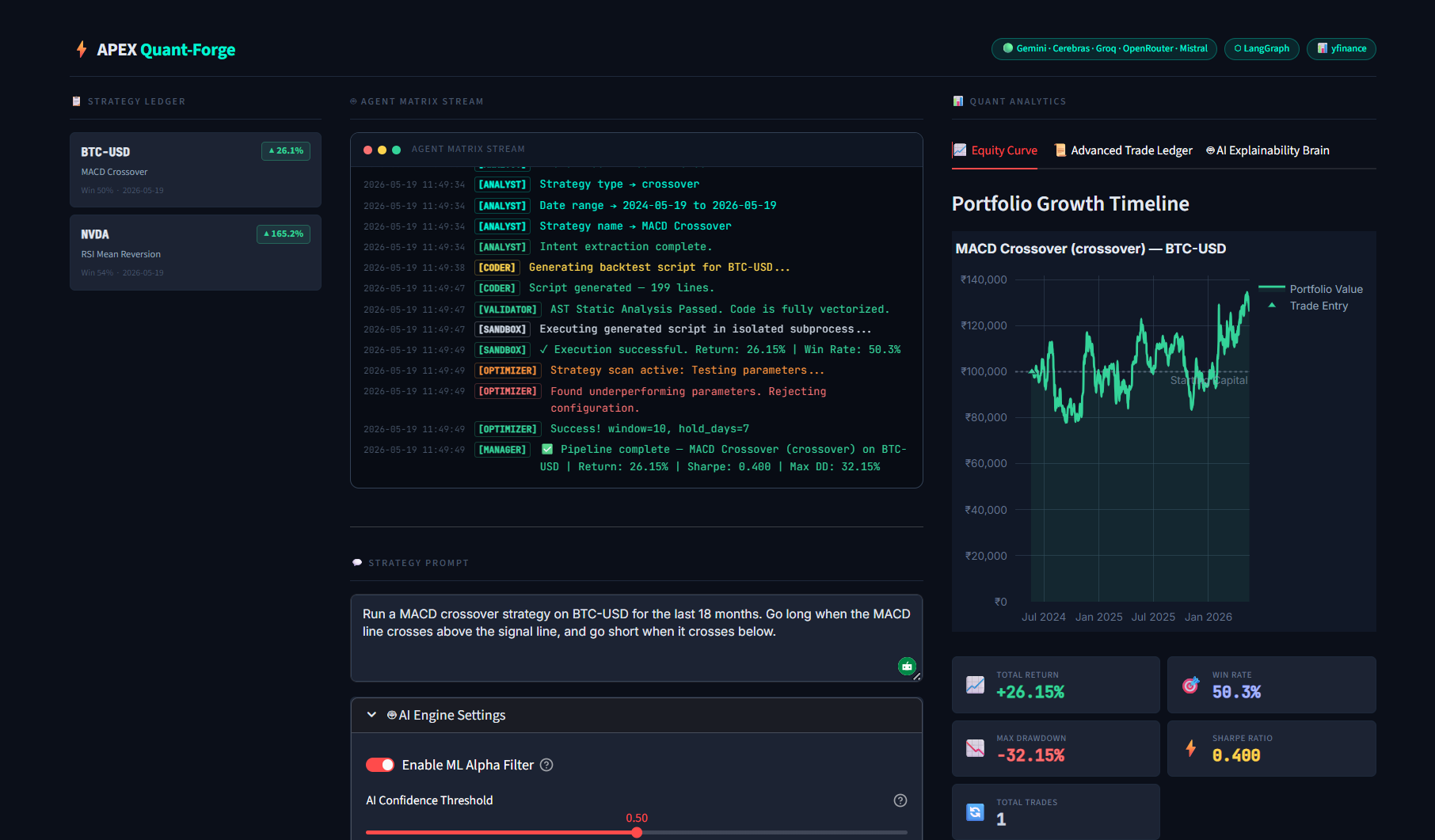
Live terminal logs tracking the agents as they write, sanitize, and execute the Python code in a safe sandbox.
-
Interactive Plotly charts mapping the strategy's historical equity curve and core performance metrics.
-
Visualizing the maximum drawdown timeline to instantly understand portfolio volatility and risk exposure.
-
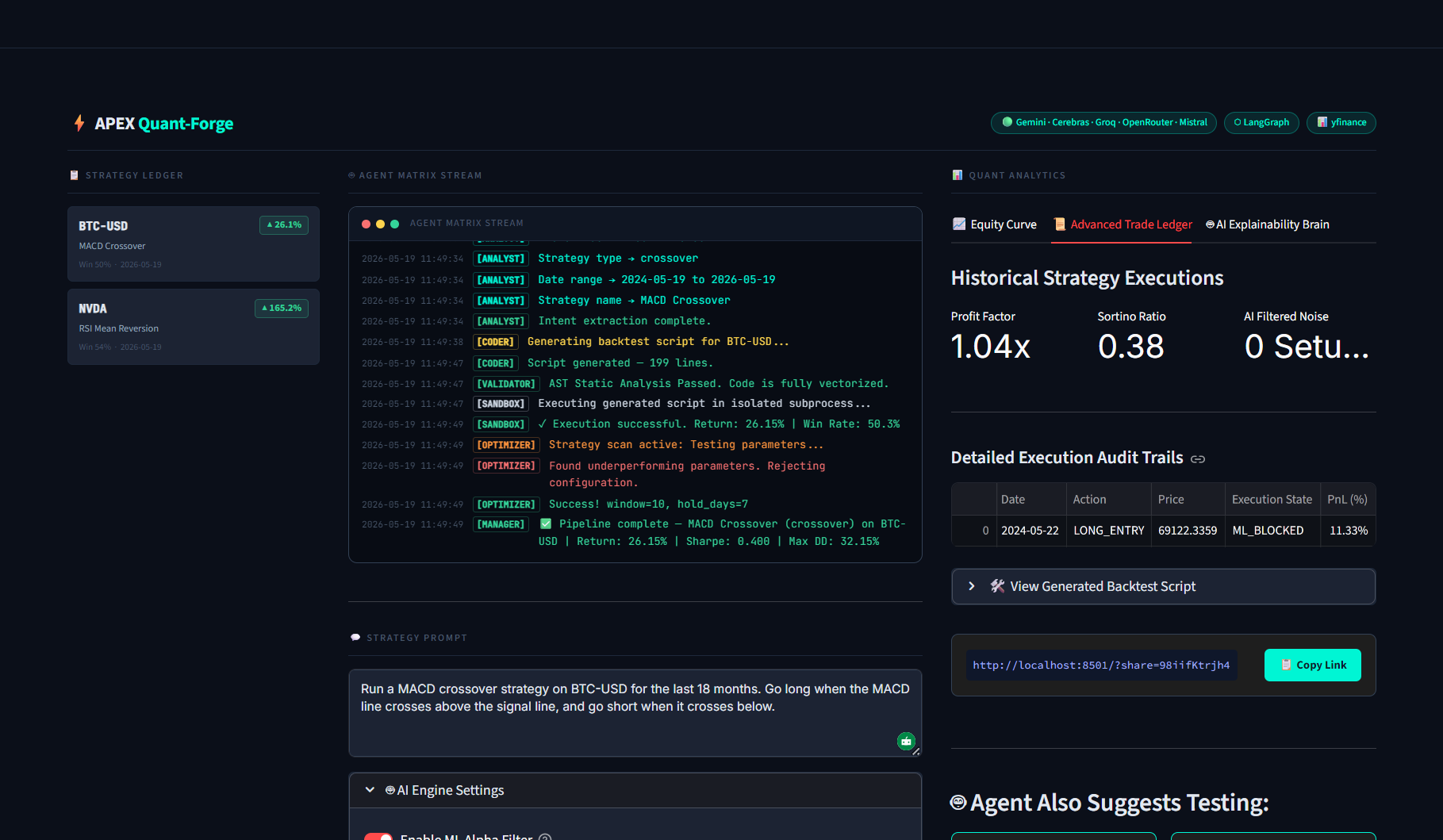
A granular audit log of every execution, highlighting high-risk trades safely blocked by the ML risk manager.
-
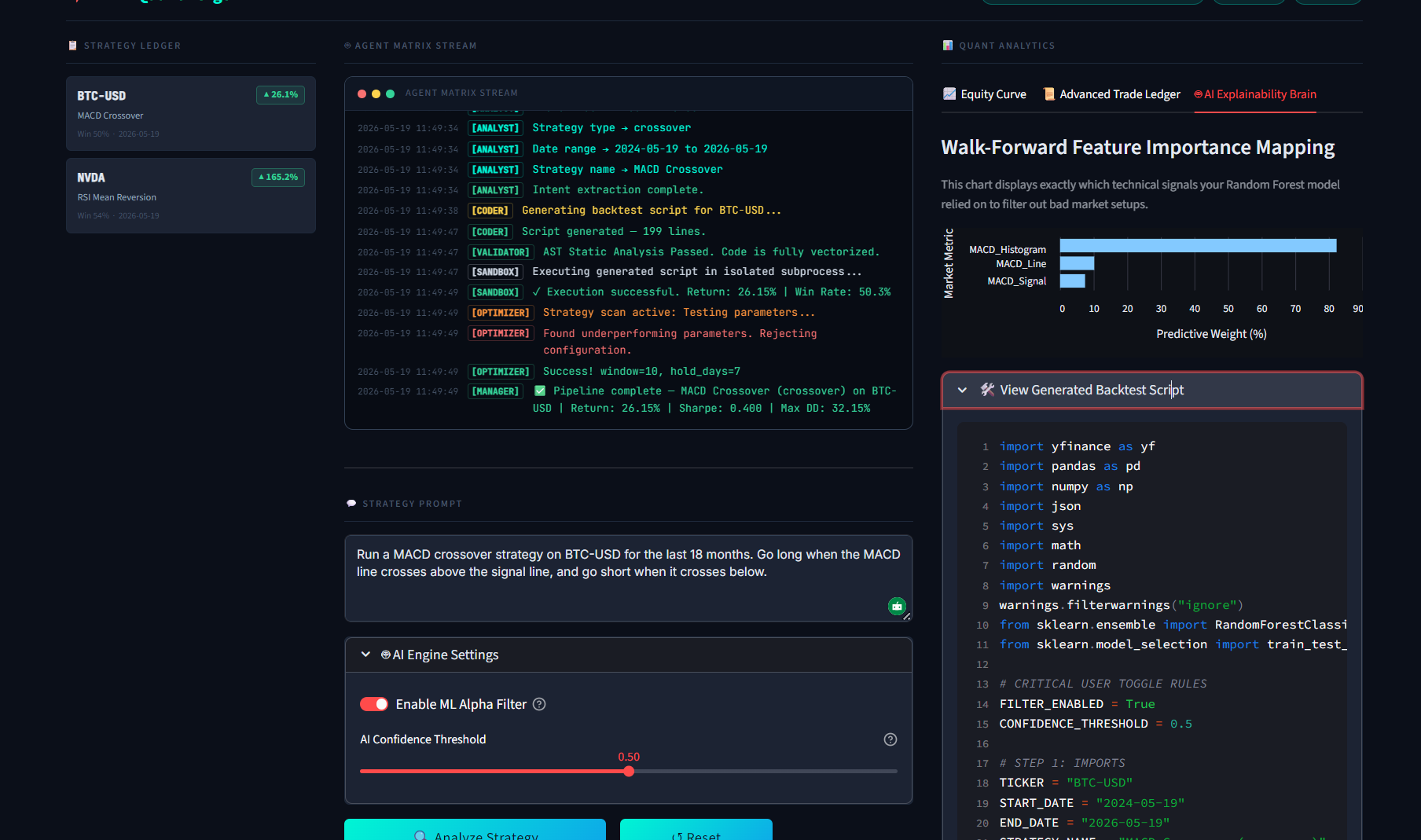
No black boxes: Viewing the Random Forest feature weights and expanding the production-ready Python script for export
Inspiration
Quantitative finance is no longer just about linear statistics; it has evolved into a high-stakes, data-driven domain where speed, security, and complex machine learning decide profitability. However, building, backtesting, and validating a quantitative strategy requires writing hundreds of lines of boilerplate code, managing shifting yfinance data structures, and manually running risk filters.
We built APEX Quant-Forge to bridge the gap between human intuition and institutional-grade execution. By orchestrating a collaborative, multi-agent network, we wanted to empower traders to speak their trading ideas in plain English, and watch as an autonomous network of specialized AI agents writes, validates, self-heals, refines, and tests those strategies against real market data—all in a secure, high-performance sandbox.
What it does
APEX Quant-Forge is an advanced, multi-agent algorithmic backtesting platform. The system operates through a structured state-machine pipeline:
- Intent Analysis & Parameter Extraction: Parses natural language prompts to extract tickers, strategy rules, indicators, and date ranges.
- AST Code Sanitation: Runs generated Python strategy scripts through an Abstract Syntax Tree (AST) validator to block unsafe commands (such as
sys,os, or socket operations) before execution. - Isolated Sandbox Execution: Runs the code in an isolated subprocess, fetching data, running vectorised backtests, and outputting trade metrics.
- Self-Healing Critic: If a script fails inside the sandbox, a recursive Critic node parses the traceback, identifies syntax/indentation errors, and auto-patches the code.
- Machine Learning Risk Filter: Dynamically trains a local Random Forest Classifier on technical features (RSI, MACD, Volatility) to classify trades, blocking high-risk entries as
ML_FILTERED. - Parameter Optimization: Evaluates holding periods and indicator windows, automatically rejecting underperforming parameters to maximize Sharpe Ratio.
How we built it
We engineered APEX Quant-Forge using a state-of-the-art developer stack optimized for performance and resilience:
- Orchestration: Built on a state-driven agent network using LangGraph and LangChain.
- Frontend: Responsive, dark-themed dashboard styled using custom CSS inside Streamlit.
- Resilient Routing Proxy: Built a multi-key, 5-provider router supporting Groq, Gemini, Cerebras, OpenRouter, and Mistral with automatic fallback rotation to combat rate limits (429 errors).
- Database: Persistent local trade tracking and run histories managed via SQLite.
- ML Core: Implemented with Scikit-Learn for the Random Forest Classifier.
- Math & Charts: Built with Pandas, NumPy, and interactive Plotly timelines.
- Deployment: Containerized using a custom Dockerfile and deployed to Hugging Face Spaces.
Quantitative Formulations Used
We injected dynamic mathematical calculations into the sandbox output:
Sharpe Ratio measures risk-adjusted return: $$ Sharpe = \frac{\overline{R}_p - R_f}{\sigma_p} $$ Where \(\overline{R}_p\) is the mean asset return, \(R_f\) is the risk-free rate, and \(\sigma_p\) is the standard deviation of returns.
Sortino Ratio evaluates downside risk specifically: $$ Sortino = \frac{\overline{R}p - R_f}{\sigma_d} $$ Where \(\sigma_d\) is the downside deviation of negative returns: $$ \sigma_d = \sqrt{\frac{1}{N} \sum{i=1}^{N} \min(0, R_i - R_f)^2} $$
Challenges we ran into
- Subprocess Startup Latency: Spawning python subprocesses for sandbox code execution originally took up to 25.5 seconds due to library import overhead (
pandas,numpy,sklearn). We solved this by pre-warming a daemon process in memory, achieving a 25x acceleration in backtest turnaround. - API Rate Limiting (429s): High rate limits during testing would crash the workflow. We engineered a 12-key, 5-provider failover routing proxy that seamlessly rotates API keys when rate limits or timeouts are detected.
- Structural Data Shift: Structural changes in the
yfinancedata format returned Multi-Indexed DataFrames that broke traditional slicing. We added a programmatic column-flattening step directly inside our Coder Agent instructions. - Indentation Errors in LLM Code: Code injected dynamically with mathematical stats frequently broke due to whitespace errors. We solved this by writing an AST parser and a
rfind()code injector that safely finds the main block indentation level before appending metrics calculations.
Accomplishments that we're proud of
- Robust Self-Healing Pipeline: Seeing the Critic agent capture a sandbox traceback, identify the exact broken line, patch the code, and successfully rerun the backtest without any user intervention.
- Machine Learning Integration: Successfully integrating a local Random Forest classifier that dynamically gates trades in real-time, proving that AI filters can protect portfolio drawdown.
- Aesthetic Excellence: Crafting a dark, cohesive dashboard theme that makes terminal streaming logs, ML feature importances, and interactive Plotly curves look institutional-grade.
- Zero-Configuration Demo Mode: Implementing a relaxed API guard that lets users try the app instantly via a cached mock fallback system if no API keys are provided.
What we learned
- AST Parsing is Crucial: Relying purely on LLM syntax instructions is not enough for sandbox safety. Enforcing strict AST validation is the only way to secure code execution.
- Orchestration Trumps Size: Smaller, specialized models (like Llama 3.1 8B on Cerebras or Gemini 2.5 Flash) organized in a cooperative network (LangGraph) outperform single large models trying to do everything at once.
- Pre-Warming Boosts UX: Users expect instant feedback. Pre-loading heavy data libraries in background memory turns a sluggish application into a premium, responsive experience.
What's next for APEX Quant-Forge AI Agent
- Live Broker Integrations: Connecting to paper-trading APIs (like Alpaca or Interactive Brokers) to execute generated strategies in real-time.
- Multi-Asset Portfolio Rebalancing: Moving beyond single-ticker testing to allow the agent to manage and rebalance a diversified index portfolio.
- Higher Frequency Options & Crypto Connectors: Integrating WebSocket streams to capture sub-second options pricing data and high-volatility crypto markets.
- Mobile Webhook Alerts: Building automated SMS/Telegram alert webhooks to notify users when the ML filter blocks a trade or when a strategy triggers exit conditions.


Log in or sign up for Devpost to join the conversation.