
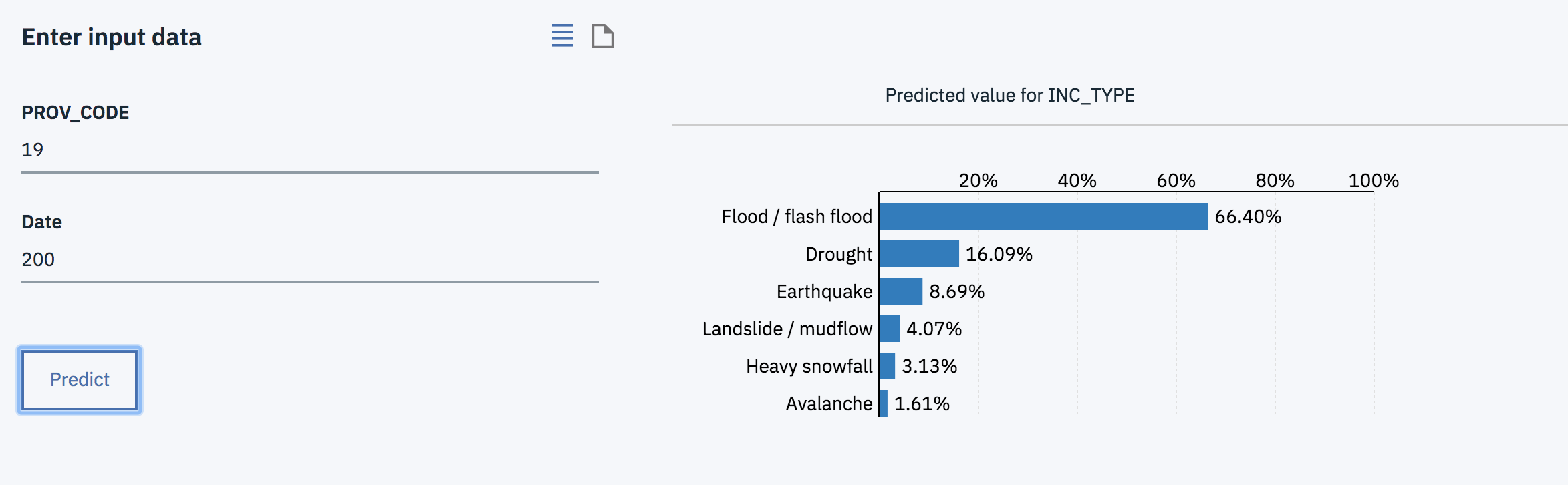
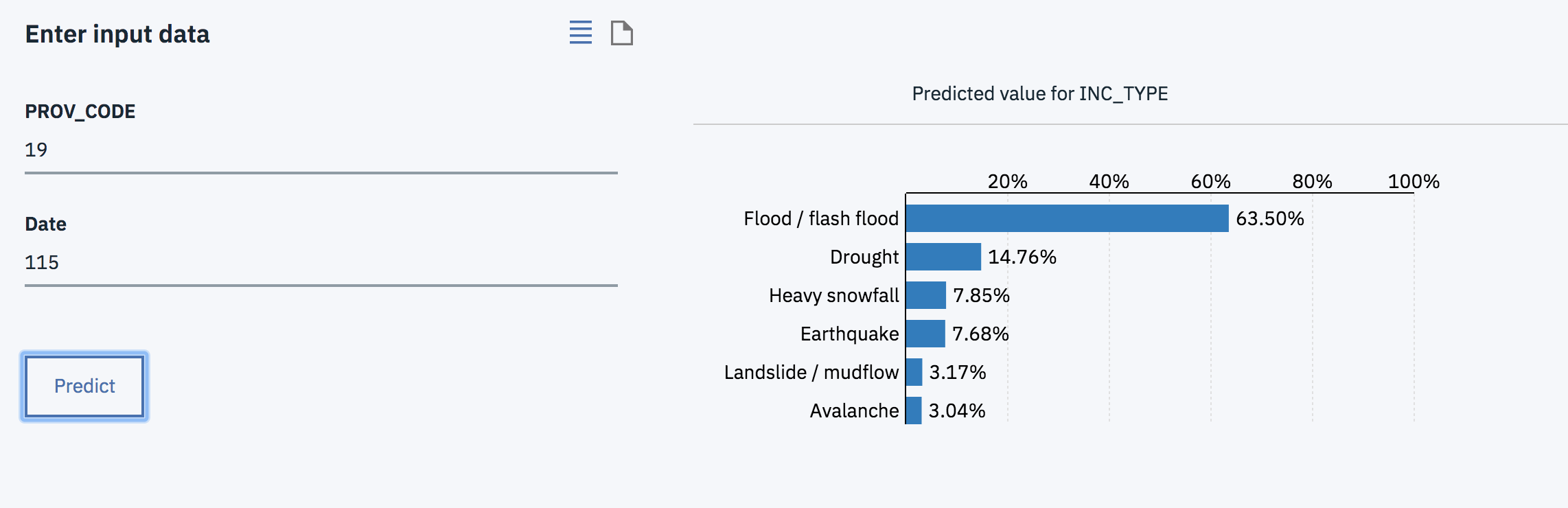
1) Project Description The project is called Pre Disaster and its purpose is to accurately predict natural disasters before they occur by using machine learning and data from previous disasters. Users can access the website and enter an area code for any place in the world and a date to identify the natural disasters that will occur and the probability that each disaster will happen. Using this website, users can better prepare for the identified disaster when it occurs. We thought this was important because being prepared for a natural disaster decreases potential fatalities and injuries. Risks from these natural processes cannot be eliminated completely; however, we can mitigate dangers to humans by further understanding and preparing for the event.
2) Problem Solved The problem is that natural disasters are hard to predict and therefore, people are unprepared for them when they strike. Natural hazards and possible disasters that are a threat to human life and property include: floods/flash flood, droughts, landslides/mudflow, earthquakes, avalanches, heavy snowfall. There are ways to plan ahead for future disaster, and our project’s purpose is to aid this goal. We solved this problem by creating Pre Disaster, a website that can predict natural disasters using data from previous natural disasters in areas around the world. We collected the set of natural disaster data from data.world. We then sorted the date and name of disaster with Python because different data sets might call the same disasters by different names. The variables for each data include: area code, type of disaster, and the day of the year it happened. After we sorted all the data onto one huge list, we trained it with Watson Machine Learning. At first, we tried to collect data from Kaggle and data.world and discovered that the data from data.world better suited our service. Many data files(csv files) did not work well with IBM watson because we did not have skills to clean the data. Therefore, from the limited data that we have acquired, our project simulates and predicts the chance of a natural disaster occuring only in Afghanistan. What we first did was a classification. We got a result that showed probabilities of each disaster. However, it assumed that a disaster would occur. In order to predict the probability that a disaster will occur on certain date, we tried to do regression. We gave different weight values for each disaster. However, we could not exactly predict precise values. As we have talked to the data scientist who is working IBM, with our dataset, it is not able to get regression value. We can continue to improve our project by further analyzing the regression values. We could also scale this so that we can include worldwide influence.
3) Technologies Used The services we utilized are Watson Machine Learning, Javascript, HTML, Express.js, Python, Visual Studio, and IBM Cloud.
4) Team members & Roles Team Name: Asian Persuasion Team Members: Seongjun Park - I worked on web development, collected data, used IBM Watson Machine Learning to process the data, and used Python for machine learning. The tools I used for web development are Javascript, Express.js, and HTML Kyuhak Yuk - I worked on web development, collected data, used IBM Watson Machine Learning to process the data, and used Python for machine learning. The tools I used for web development are Javascript, Express.js, Visual Studio, and HTML. Eric Wu - I learned how to use the IBM visual recognition for wildfires that might occur in case the project we did didn’t work Earl Padron - app development,working with IBM API’s, project report Julian Liao - My role in this project was to create an Android app that would display the prediction of the natural disaster and notify users. One of the services I initially used is Streaming Analytics. However, I only had time to implement Firebase into the app because I ran into technical issues and bugs. One of the bugs I faced was that the documentation I was following used outdated dependencies and caused errors while building the app. I spent a lot of time researching on ways to fix it. A major technical issue I ran into was that whenever I closed the Android emulator for the app, my laptop would crash and a Blue Screen would occur. We decided to move towards web development instead. I mostly contributed to the project report.
Built With
- express.js
- html
- ibm-cloud
- javascript
- python
- visual-studio
- watson-machine-learning
- watson-maching-learning



Log in or sign up for Devpost to join the conversation.