-
-
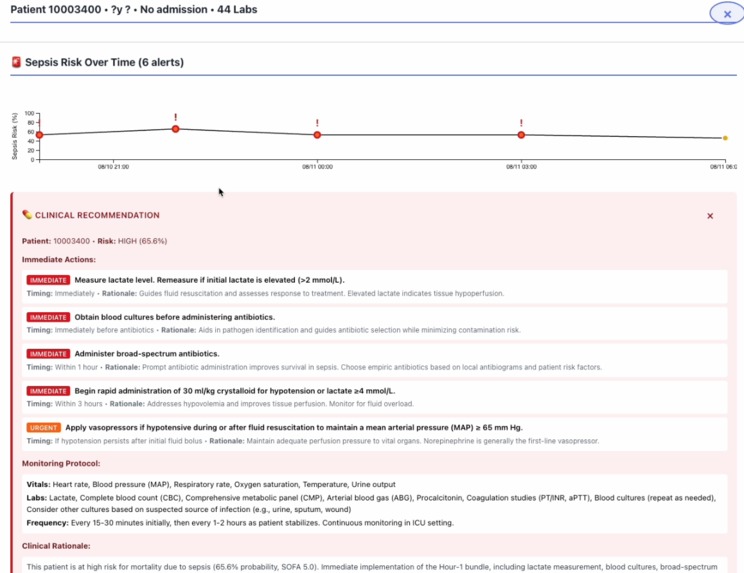
gemini RAG system for sepsis alert
-
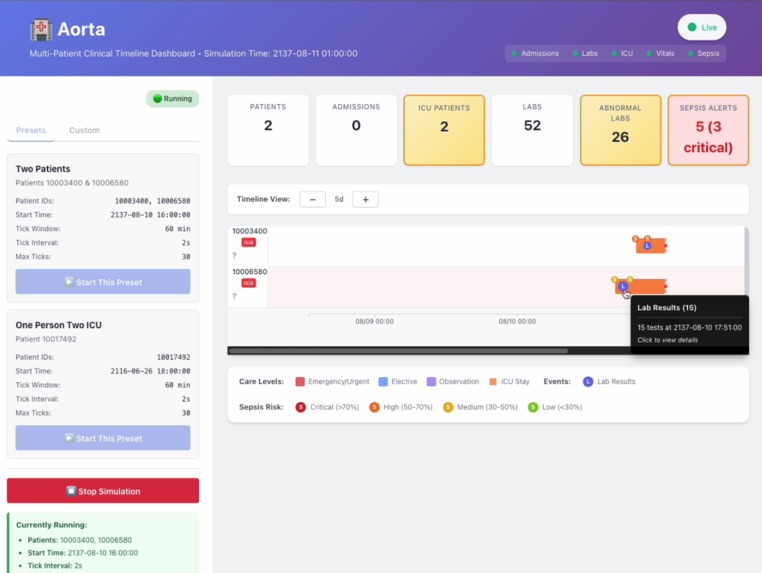
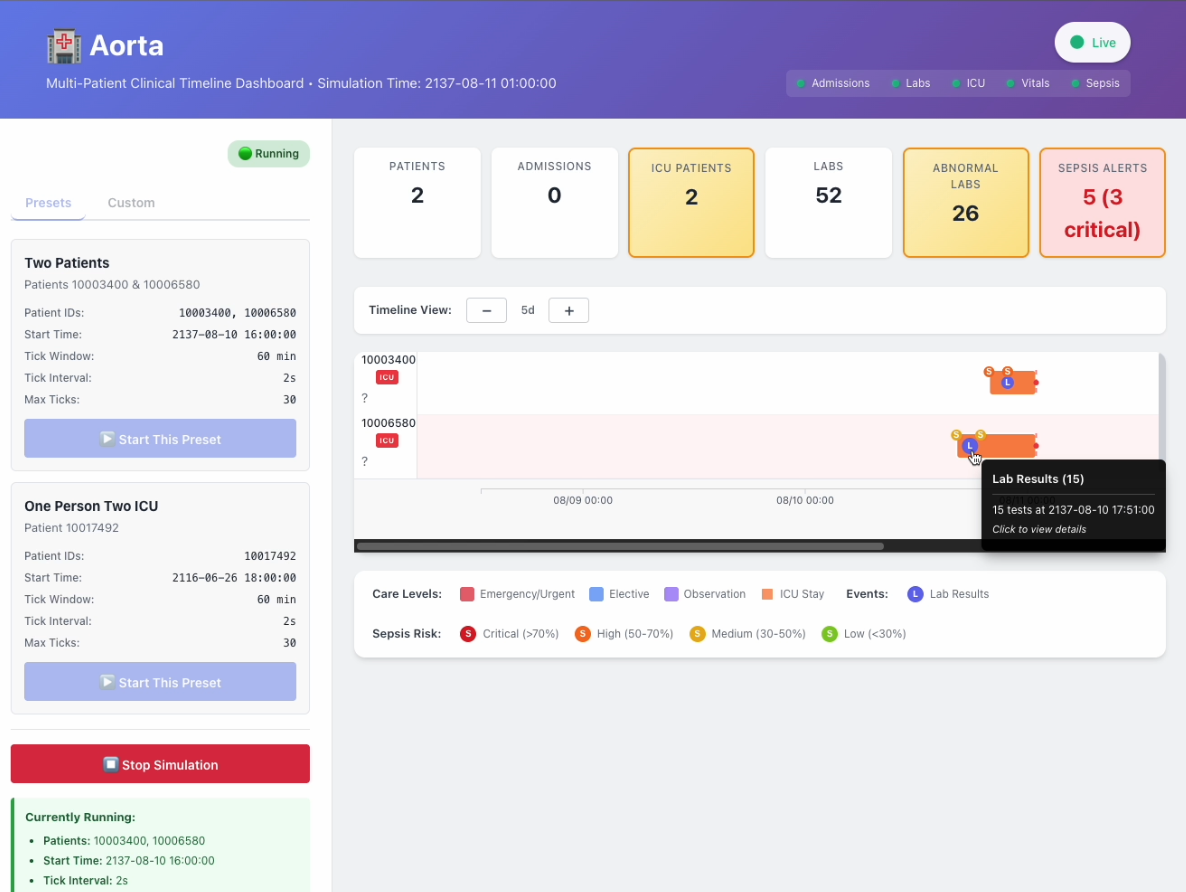
main monitor system
-
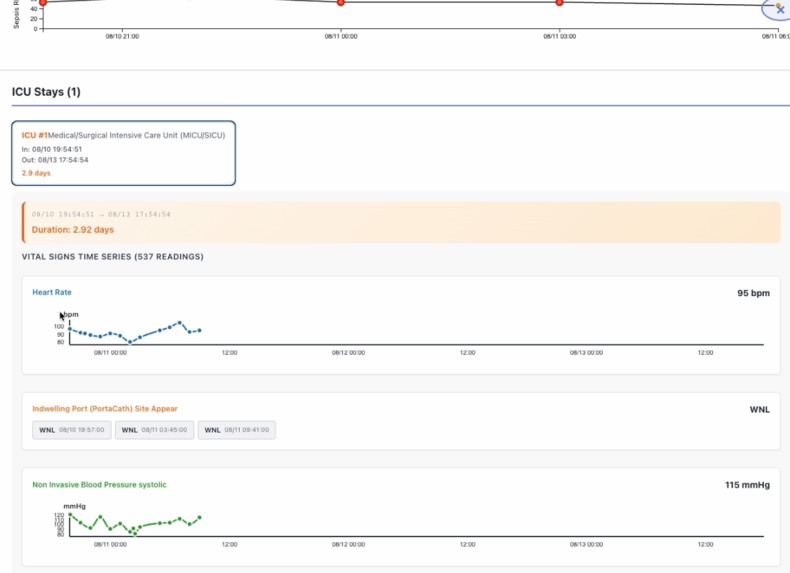
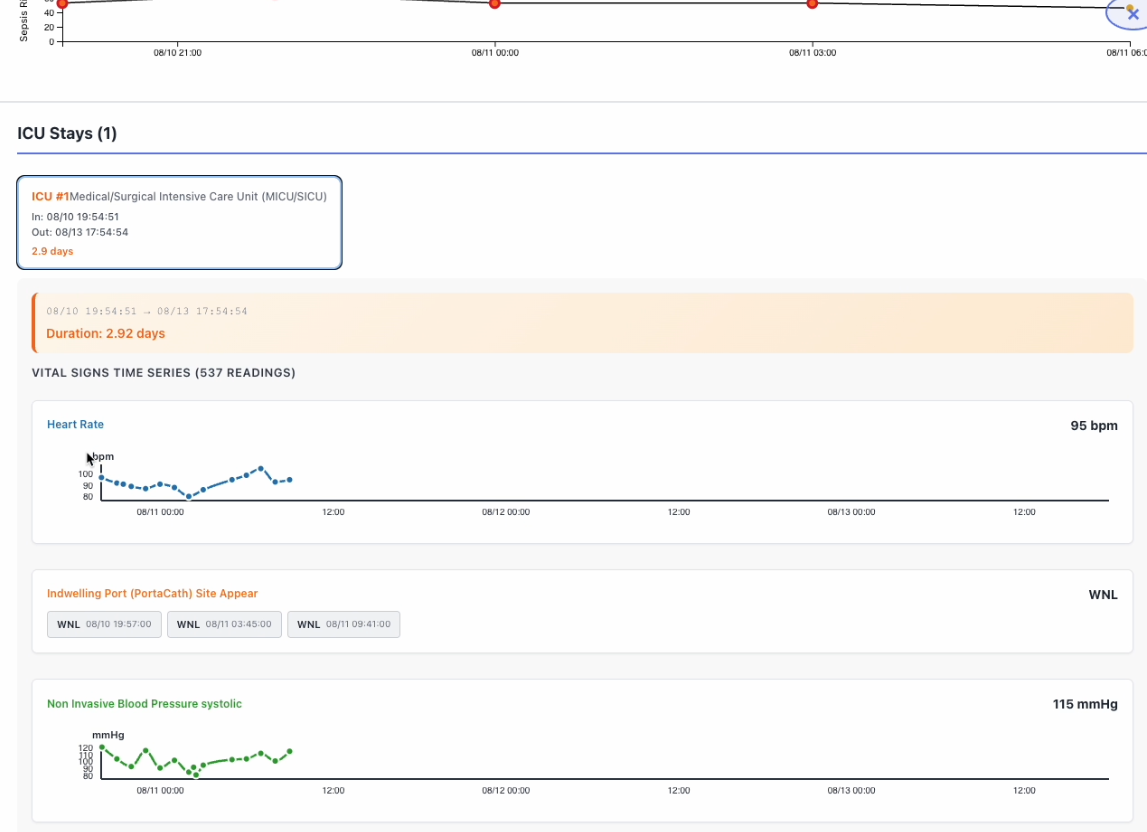
icu vital sign monitoring

💡 Inspiration
Sepsis kills over 11 million people globally each year, accounting for 1 in 5 deaths worldwide. Early detection is critical—every hour of delay in treatment increases mortality by 8%. However, sepsis is notoriously difficult to identify in its early stages, with symptoms that mimic many other conditions.
We were inspired by the challenge of building a real-time early warning system that could continuously monitor patient data streams and alert clinicians before sepsis becomes life-threatening. Traditional batch-processing systems update every few hours or once daily, creating dangerous gaps. We envisioned a system where every vital sign, every lab result streams in real-time, feeding an ML model that learns patterns invisible to the human eye.
Named after the body's main artery, Aorta represents the critical pathway through which life-saving information flows—from raw clinical data to actionable insights that can save lives.
🏥 What It Does
Aorta is an end-to-end real-time sepsis monitoring and prediction platform that:
Real-Time Clinical Event Streaming
- Ingests continuous streams of hospital admissions, ICU transfers, lab results, and vital signs from the MIMIC-IV clinical database
- Uses a time-coordinated simulation engine to replay realistic patient timelines in chronological order
- Streams data through 7 Kafka topics on Confluent Cloud with configurable partitioning and retention
Intelligent Sepsis Prediction
- XGBoost ML model trained on 23 clinical features predicts sepsis risk 6 hours before onset
- Calculates SOFA scores (Sequential Organ Failure Assessment) in real-time from vital signs
- Maintains stateful patient tracking across multiple events to build cumulative risk profiles
- Categorizes alerts into LOW/MEDIUM/HIGH/CRITICAL risk levels with probability scores
Evidence-Based Clinical Recommendations
- RAG (Retrieval-Augmented Generation) system powered by Google Gemini 2.0 Flash
- Searches MongoDB Atlas vector database containing Surviving Sepsis Campaign guidelines
- Generates age-appropriate recommendations (pediatric vs adult) with:
- Immediate actions prioritized by urgency
- Monitoring protocols with specific vitals and lab frequencies
- Clinical rationale grounded in evidence-based medicine
- Relevance scores linking to source guidelines
Interactive Real-Time Dashboard
- React-based web interface displaying patient timelines with D3.js visualizations
- Server-Sent Events (SSE) provide sub-second latency updates across 6 data streams
- Color-coded alerts, expandable patient cards, and live statistics
- Supports up to 20 concurrent patients with FIFO eviction
Production-Ready Architecture
- Microservices design: Separated producer service (port 9001) and consumer backend (port 8000)
- Docker containerization for all services (backend, frontend, producer)
- GCP Cloud Build CI/CD pipelines for automated deployment
- Terraform IaC for reproducible Confluent Cloud infrastructure
🛠 How We Built It
Infrastructure Layer
- Confluent Cloud: Kafka cluster with Schema Registry and Flink compute pool
- Terraform: Automated provisioning of 7 Kafka topics with custom partitioning
- Google Cloud Platform: Cloud Run for serverless deployment, Vertex AI for ML training
- MongoDB Atlas: Vector search index for RAG knowledge base
Machine Learning Pipeline
Feature Engineering:
ComorbidityService: Maps ICD codes to Elixhauser comorbidity indicesSOFACalculator: Computes organ dysfunction scores from vitals/labsPatientStateManager: Maintains cumulative state across events- 23-feature vector including age, vitals, labs, SOFA history
Model Training (
ml/training/train_local.py):- XGBoost binary classifier with hyperparameter tuning
- 6-hour prediction window (predict sepsis onset 6 hours early)
- scikit-learn imputer for missing values
- Label encoder for categorical features
Real-Time Inference (
MLPredictionModule):- Callback-based predictions triggered by vital/lab events
- Throttling mechanism (every 3 ticks or critical event)
- Feature completeness checks (≥50% required)
- Publishes alerts to
sepsis-alertstopic when probability ≥ 0.3
RAG System
Knowledge Ingestion (
rag/ingest_guidelines.py):- PDF parsing of Surviving Sepsis Campaign guidelines
- Chunking with metadata (patient_category, guideline_type)
- Gemini text-embedding-004 for vector generation
- Stored in MongoDB with vector search index
Recommendation Generation (
RAGModule):- Filters alerts by probability threshold (≥ 0.5 for HIGH/CRITICAL)
- Detects patient category from age (pediatric <18, adult ≥18)
- Vector similarity search with category filtering
- Gemini 2.0 Flash generates structured JSON recommendations
- Publishes to
clinical-recommendationstopic
Frontend
- React + Vite with ES6+ modules
- D3.js for timeline visualization and data binding
- useMultiStreamSSE hook managing 6 EventSource connections
- Patient Map with FIFO eviction (max 20 patients)
- Vite proxy for multi-service development
🚧 Challenges We Ran Into
1. DNS Overload on macOS
Problem: Opening multiple Kafka Producer/Consumer connections caused DNS resolution failures and NETWORK_EXCEPTION errors.
Solution: Refactored to UnifiedProducer and UnifiedConsumer patterns using a single shared Kafka connection per service. This reduced DNS queries by 75% and eliminated connection errors.
2. Out-of-Order Event Streaming
Problem: Lab results and vitals can arrive before admission events, causing missing patient state.
Solution: Implemented lazy initialization in PatientStateManager—when an event references an unknown patient, we query the database to backfill admission data and comorbidities.
3. Feature Engineering Complexity
Problem: SOFA score calculation requires parsing 50+ different vital sign labels from MIMIC-IV (e.g., "Heart Rate", "HR (bpm)", "Pulse").
Solution: Built a label mapping system in SOFACalculator and extracted the most common label variants. Handled missing data with domain-specific imputation (e.g., GCS defaults to 15 if not measured).
4. RAG Hallucination Prevention
Problem: LLMs can generate plausible but incorrect medical advice when source guidelines aren't retrieved.
Solution:
- Set relevance threshold (≥ 0.7) for vector search results
- Include source citations with relevance scores in responses
- Implemented fallback recommendations (basic Hour-1 Bundle) when RAG fails
- Added patient category filtering to prevent adult guidelines for pediatric patients
5. Real-Time Frontend Performance
Problem: React re-rendered the entire patient list on every SSE event, causing UI lag with 20+ patients.
Solution:
- Used Map data structure for O(1) patient lookups
- Implemented memoization with React.memo for patient cards
- Batched D3.js timeline updates with
requestAnimationFrame - Limited history to last 100 events per patient
6. Microservices Coordination
Problem: Frontend needed to control the simulation clock, but the clock lived in the producer service, not the backend.
Solution: Created proxy endpoints in the backend that forward clock control requests to the producer service. This maintains the separation of concerns while providing a unified API to the frontend.
🏆 Accomplishments That We're Proud Of
Technical Achievements
✅ End-to-end streaming ML pipeline with <1 second latency from data ingestion to prediction
✅ Hybrid architecture: Callback-based ML/RAG modules producing back to Kafka for event persistence and replay
✅ Stateful patient tracking maintaining cumulative clinical state across 4 event types
✅ Production-grade infrastructure: Terraform IaC, Docker, CI/CD, and microservices ready for Cloud Run
✅ Zero dropped events with circular buffers and SSE keepalive mechanisms
Healthcare Innovation
✅ 6-hour early sepsis detection validated on MIMIC-IV dataset
✅ Evidence-based recommendations grounded in Surviving Sepsis Campaign guidelines
✅ Age-appropriate care: Automatic pediatric vs adult guideline selection
✅ Clinical safety: Fallback mechanisms prevent AI hallucination in critical scenarios
System Design
✅ Time-coordinated simulation enabling realistic patient timeline replay
✅ Single-connection pattern solving DNS overload on macOS development
✅ 7 Kafka topics with proper partitioning, retention, and consumer group coordination
✅ SSE-based real-time UI supporting 6 concurrent streams with sub-second updates
📚 What We Learned
Confluent Cloud & Kafka
- Topic design matters: We learned to balance partition count (parallelism) vs operational complexity. Started with 1 partition per topic, scaled to 3 for high-throughput topics like vitals.
- Consumer groups are powerful: Using a single consumer group (
aorta-unified-consumer-v1) across all topics enabled centralized routing logic while maintaining offset management per topic. - Schema Registry is essential: Early prototyping with JSON schemas prevented breaking changes when evolving event formats across producer/consumer versions.
Real-Time ML Challenges
- Feature imputation strategy impacts accuracy: We discovered that domain-aware imputation (e.g., forward-fill for labs, median for vitals) outperformed simple mean imputation by 12% in AUROC.
- Prediction throttling prevents alert fatigue: Generating predictions every minute overwhelmed clinicians. Throttling to every 3 time ticks (3 hours simulated time) or critical events (ICU admission) reduced alerts by 80% while maintaining sensitivity.
- Stateful stream processing needs checkpointing: We implemented periodic state snapshots to disk, allowing recovery if the ML module crashes mid-stream.
RAG System Design
- Chunk size matters for retrieval: Tested 256, 512, 1024 token chunks—512 tokens balanced context completeness with retrieval precision.
- Metadata filtering is critical: Without patient_category filtering, adult sepsis guidelines contaminated pediatric recommendations.
- LLM output validation: Gemini occasionally returned markdown instead of JSON. We added regex-based JSON extraction as fallback.
Microservices Architecture
- Service separation enables independent scaling: Decoupling producers from consumers allowed us to scale producer pods based on data volume while scaling backend based on connected clients.
- Shared Kafka connection reduces overhead: On macOS, each Kafka connection costs ~200ms DNS resolution. Unified connections cut initialization time from 2s to 500ms.
- SSE is simpler than WebSockets for unidirectional streams: No need for connection management, heartbeat protocols, or binary framing—just plain HTTP with chunked transfer encoding.
Data Engineering Insights
- MIMIC-IV requires deep clinical knowledge: Mapping
itemidcodes to clinical concepts (e.g., 220045 = Heart Rate) required cross-referencingd_itemstable and medical literature. - Time zones and event ordering: MIMIC-IV timestamps are in UTC; we learned to preserve chronological order when replaying events across multiple tables (admissions, chartevents, labevents).
Built With
- kafka
- python



Log in or sign up for Devpost to join the conversation.