-
-
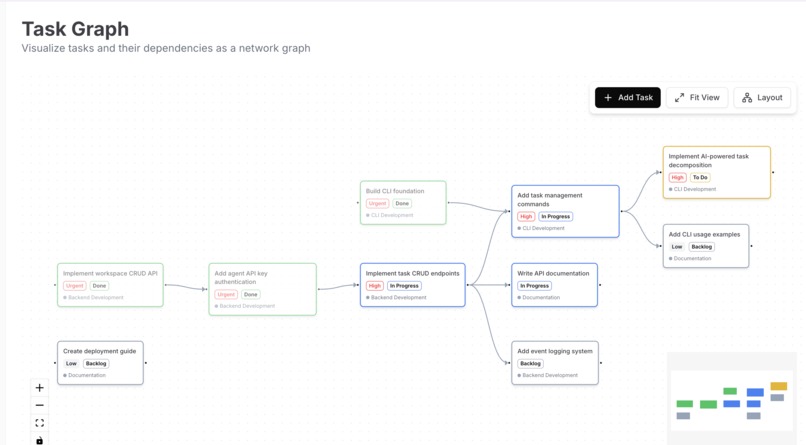
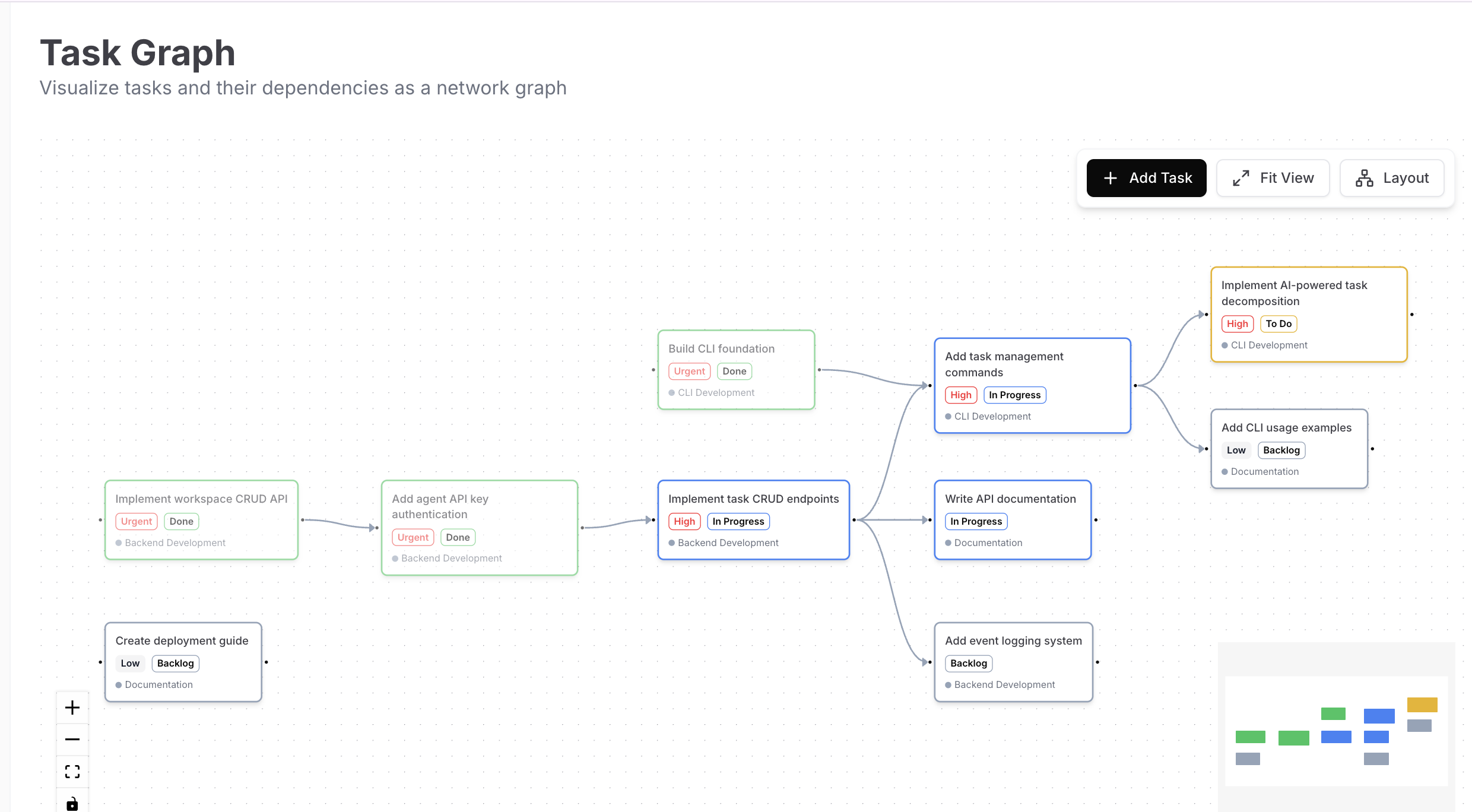
Graph Visualization
## Inspiration
We're entering an era where code is written by teams of humans and AI. Tools like Claude Code, GitHub Copilot, and Devin are moving from demos to production—but project management tools haven't evolved to support this shift.
The inspiration struck when we realized: traditional tools like Jira and Linear have no concept of agent attempts, retries, or failure causes. When an AI agent fails a task, there's no structured way to understand why—was it a test failure? A context window limit? A permission error? Teams piloting AI coding agents were stitching together GitHub Issues + PRs + CI logs + observability dashboards just to get basic visibility.
We saw the opportunity to build the missing layer: a task management system designed for AI agents as first-class users, not an afterthought. This is the "Jira moment" for the age of AI-assisted software development.
## What it does
AnyTask is an AI-native task management platform that provides mission control for human-AI development teams. It combines a powerful CLI tool with a web dashboard to enable seamless collaboration between developers and coding agents.
### Core Features
🎯 Agent-Aware Task Management
- Linear-style task identifiers (e.g.,
DEV-123) with workspace prefixing - Status workflow:
backlog → todo → inprogress → done/canceled - Hierarchical structure:
Workspace → Projects → Tasks → Attempts → Artifacts - Optimistic concurrency control prevents lost updates in multi-agent scenarios
🔄 Attempt & Failure Tracking
- First-class Attempts entity: every agent run is tracked with status, duration, and cost
- Failure taxonomy:
test_fail,tool_error,context_limit,rate_limit,permission_error - Retry intelligence: see what worked, what failed, and why
- Cost metrics: token usage and wall-clock time per task
📊 AI-Powered Workflows
- Goal decomposition: AI breaks down high-level goals into atomic tasks with dependencies
- Dependency DAG visualization with circular detection
- Automatic task summarization and organization
- Event sourcing: append-only audit trail of all changes
💾 Rich Artifact Support
- Track diffs, files, logs, benchmarks, and screenshots
- Link artifacts to specific attempts for full traceability
- Version control for all task updates
### API Coverage 50+ REST endpoints including:
- Workspace & membership management
- Project CRUD operations
- Task management with dependencies
- Attempt tracking & failure analytics
- Event history & unified timeline
- Agent API key lifecycle management
## How we built it
### Technology Stack
Backend (FastAPI + PostgreSQL)
- Framework: FastAPI (async Python) with uvicorn ASGI server
- Database: PostgreSQL with asyncpg driver for true async performance
- Validation: Pydantic v2 for type-safe request/response models
- Authentication: Supabase JWT + custom bcrypt-based API keys
- AI Integration: LangChain with Anthropic Claude and OpenAI
Architecture Patterns
- Repository Pattern: Clean separation between data access (SQLAlchemy) and domain logic (Pydantic)
- Dependency Injection:
RepositoryFactoryprovides unified access to all data repositories - Domain-Driven Design:
BaseRepository[T, DBModel]with entity-specific extensions - Event Sourcing: Append-only events table enables full history reconstruction
- Multi-Tenancy: Workspace-scoped isolation with role-based access control
Development Workflow
- Package Management: uv (modern Python package manager)
- Code Quality: ruff (linting + formatting), mypy (type checking)
- Testing: pytest with async support, integration tests with TestClient
- Migrations: Alembic with auto-generated migration scripts
- Docker: Multi-stage builds with docker-compose orchestration
### Key Implementation Details
- Async Throughout: All database operations use
async/awaitfor maximum performance - Standardized Responses:
- Success:
{success: true, data: {...}, message: "...", request_id: "uuid"} - Error:
{error: "Type", message: "...", code: "CODE", details: [], request_id: "uuid"}
- Success:
- Request Middleware: Auto-generates UUID per request, captures duration and structured logs
- Agent Key Security: Format
anyt_agent_<32_alphanumeric>, stored as bcrypt hash with prefix indexing - Linear-Style IDs: Workspace prefix + auto-increment (e.g.,
DEV-123)
## Challenges we ran into
1. Dual Authentication Model Designing a unified auth system that treats both users (JWT) and agents (API keys) as first-class actors was complex. We needed to:
- Abstract authentication into a unified
AuthActorinterface - Support different header patterns (
Authorization: BearervsX-API-Key) - Implement permission scoping that works for both humans and autonomous agents
- Solution: Created
get_current_actor()dependency that handles both paths, withrequire_workspace_access()andrequire_permission()authorization helpers
2. Optimistic Concurrency Control When multiple agents (or humans) edit tasks simultaneously, preventing lost updates without database locks was critical:
- Row-level version fields track changes
- PATCH requests require
If-Match: versionheaders - On conflict, return HTTP 409 with
current_version,provided_version, and detailedconflicts[] - Solution: Implemented optimistic locking in
BaseRepositorywith automatic version increment and conflict detection
3. Circular Dependency Detection Task dependency graphs can easily create cycles (A depends on B depends on A), which would deadlock agent workflows:
- Needed efficient graph traversal for large dependency trees
- Had to prevent cycles at creation time, not just detect them later
- Solution: Implemented recursive DFS-based cycle detection in
TaskDependencyRepository.add_dependency()that validates before insertion
4. Repository Pattern Migration Transitioning from inline SQLAlchemy queries to a clean repository pattern across 10+ entities required:
- Defining domain models (Base, Create, Update, Full) for each entity
- Creating type-safe
BaseRepository[T, DBModel]generic class - Refactoring all 50+ endpoints to use dependency injection
- Solution: Built
RepositoryFactorywith lazy-loaded repository properties and comprehensive test coverage
5. Event Sourcing vs Performance Logging every change to an append-only events table was crucial for audit trails, but risked performance degradation:
- Every task update generates multiple events (status change, field updates, etc.)
- Timeline queries need to join events + attempts + artifacts efficiently
- Solution: Indexed events table on
(entity, entity_id, created_at)and implemented smart pagination with cursor-based pagination for timelines
## Accomplishments that we're proud of
✅ Complete, Production-Ready API: 50+ endpoints covering the full task management lifecycle, from workspace creation to artifact tracking
✅ True Agent-Native Design: Not a retrofit—built from the ground up with attempts, retries, and failure telemetry as core primitives
✅ Type-Safe Architecture: Full type coverage with Pydantic v2 and mypy enforcement prevents runtime errors
✅ Comprehensive Test Coverage: Unit tests for repositories, integration tests for endpoints, and seeding utilities for consistent test data
✅ Real-World AI Integration: Uses LangChain with Anthropic Claude for actual goal decomposition and task organization
✅ Clean Architecture: Repository pattern provides excellent separation of concerns, making the codebase maintainable and testable
✅ Developer Experience:
make dev→ instant local server with auto-reloadmake test-setup→ one-command test database creationmake lint && make format && make typecheck→ enforced code quality
✅ Conflict Resolution: Optimistic concurrency with detailed conflict reporting—critical for multi-agent coordination
✅ Full Audit Trail: Event sourcing enables complete history reconstruction and compliance logging
✅ Multi-Tenancy Ready: Workspace isolation with role-based access control from day one
## What we learned
1. AI Agents Have Different Needs Than Humans Traditional task systems assume synchronous, human-paced work. Agents need:
- Fast retry loops with failure classification
- Cost tracking (tokens aren't free!)
- Artifact preservation (diffs, logs, benchmarks)
- State recovery after context resets or rate limits
2. Optimistic Concurrency > Locking For agent workloads, database locks are a non-starter. Optimistic concurrency with version fields and conflict detection is the right pattern—it's fast, scales horizontally, and gives agents clear conflict signals.
3. The Repository Pattern is Worth It The upfront investment in clean architecture pays off immediately:
- Type safety catches bugs at compile time
- Testing is trivial with mock repositories
- Domain models (Pydantic) stay clean and separate from persistence (SQLAlchemy)
- New features are faster to implement because patterns are consistent
4. Event Sourcing Enables Debugging When agents fail mysteriously, having a complete event log is invaluable. We can replay exactly what happened: which fields changed, who (human or agent) made the change, and when.
5. Async Python is Production-Ready SQLAlchemy 2.0's async support with asyncpg is genuinely fast and stable. Combined with FastAPI's native async, we're handling concurrent agent requests efficiently.
6. Authentication Flexibility Matters Supporting both user JWTs and agent API keys from the start was the right call—it opened up use cases we hadn't anticipated (CLI tools, CI/CD integration, webhook consumers).
7. Dependency Graphs Are Hard Circular detection, transitive closures, and efficient graph queries require careful schema design. Our solution (simple edge table + in-memory validation) strikes a good balance between simplicity and correctness.
Built With
- anthropic
- cli
- fastapi
- llm
- nextjs
- openai
Log in or sign up for Devpost to join the conversation.