-
-
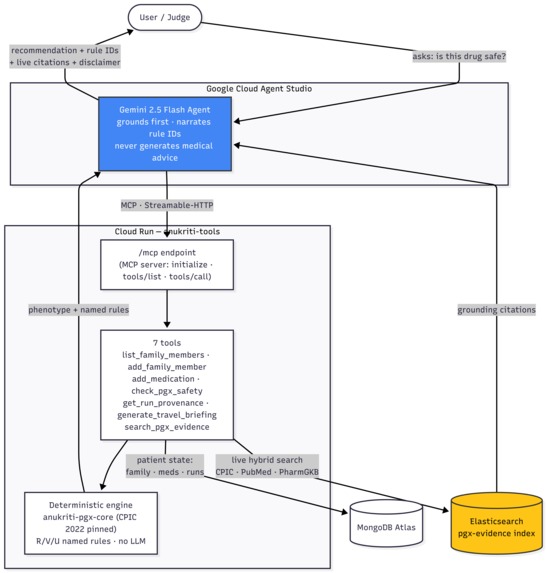
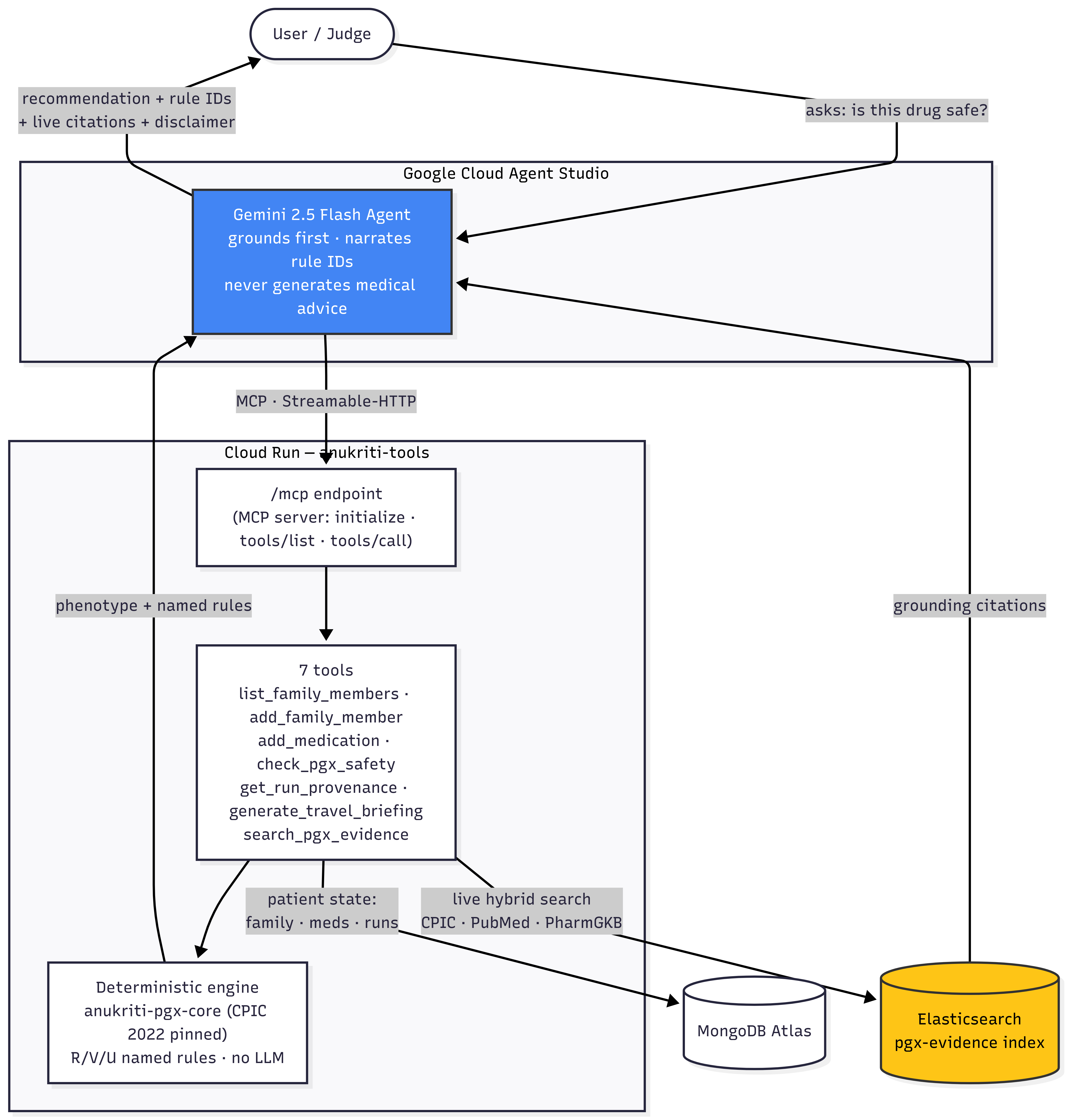
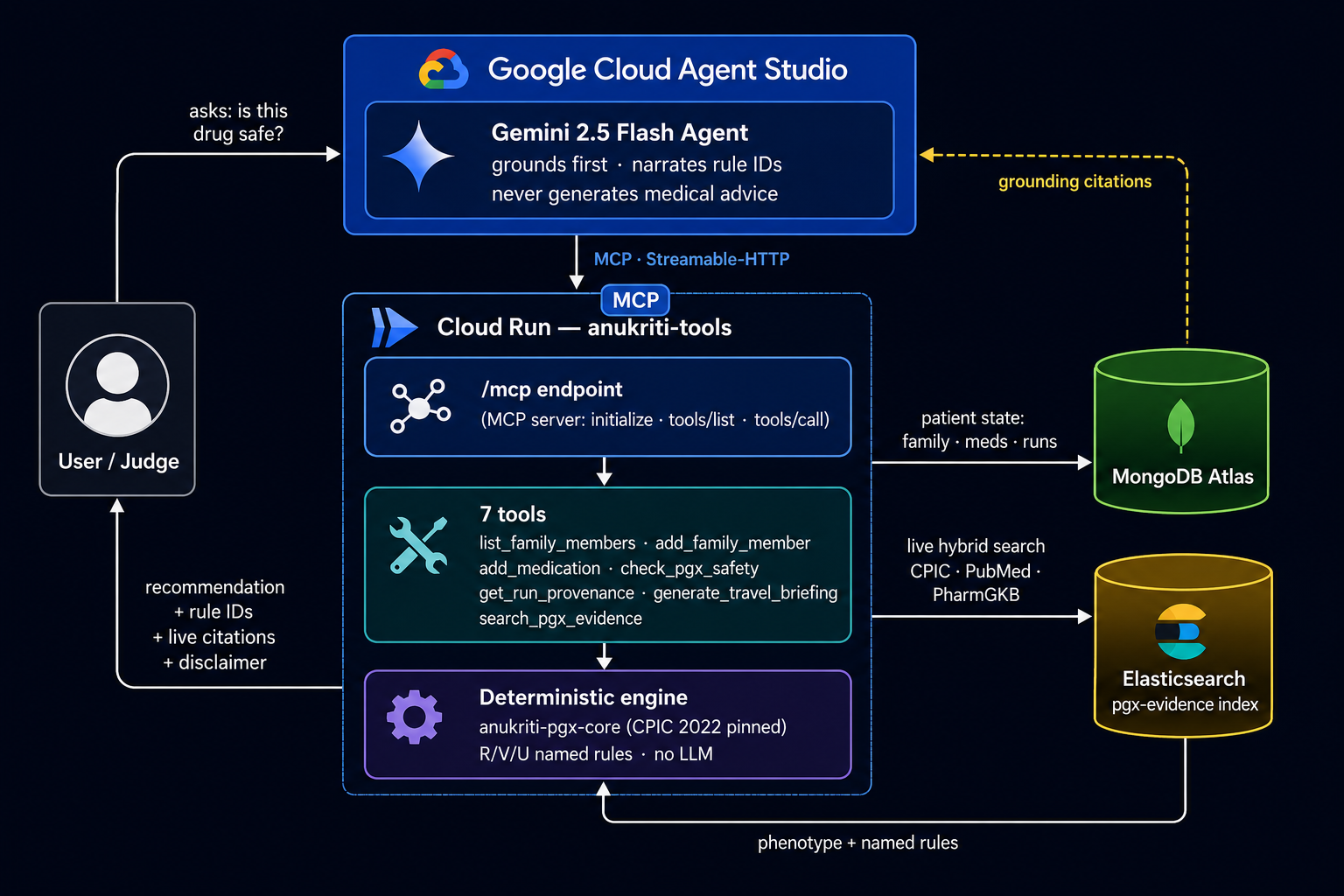
Architecture Diagram
-
-
-
-
-
Inspiration
In 2019, a relative — South Asian, post-stent — was prescribed clopidogrel.
He carries CYP2C19 2/*2: a Poor Metabolizer who literally cannot activate
the drug. It was, for him, a placebo against stent thrombosis. He had a
second cardiac event. **14% of South Asians can't activate clopidogrel, yet
they're prescribed it at the same rate as Europeans, where ~2% are affected.*
Pharmacogenomic guidelines are calibrated on Eurocentric evidence, and the
gap is invisible at the point of care. Anukriti is our answer: an agent that
asks "will this drug work for this person, given their ancestry?" — before
the prescription is written.
What it does
Anukriti is a pre-prescription pharmacogenomic safety agent. You ask about a
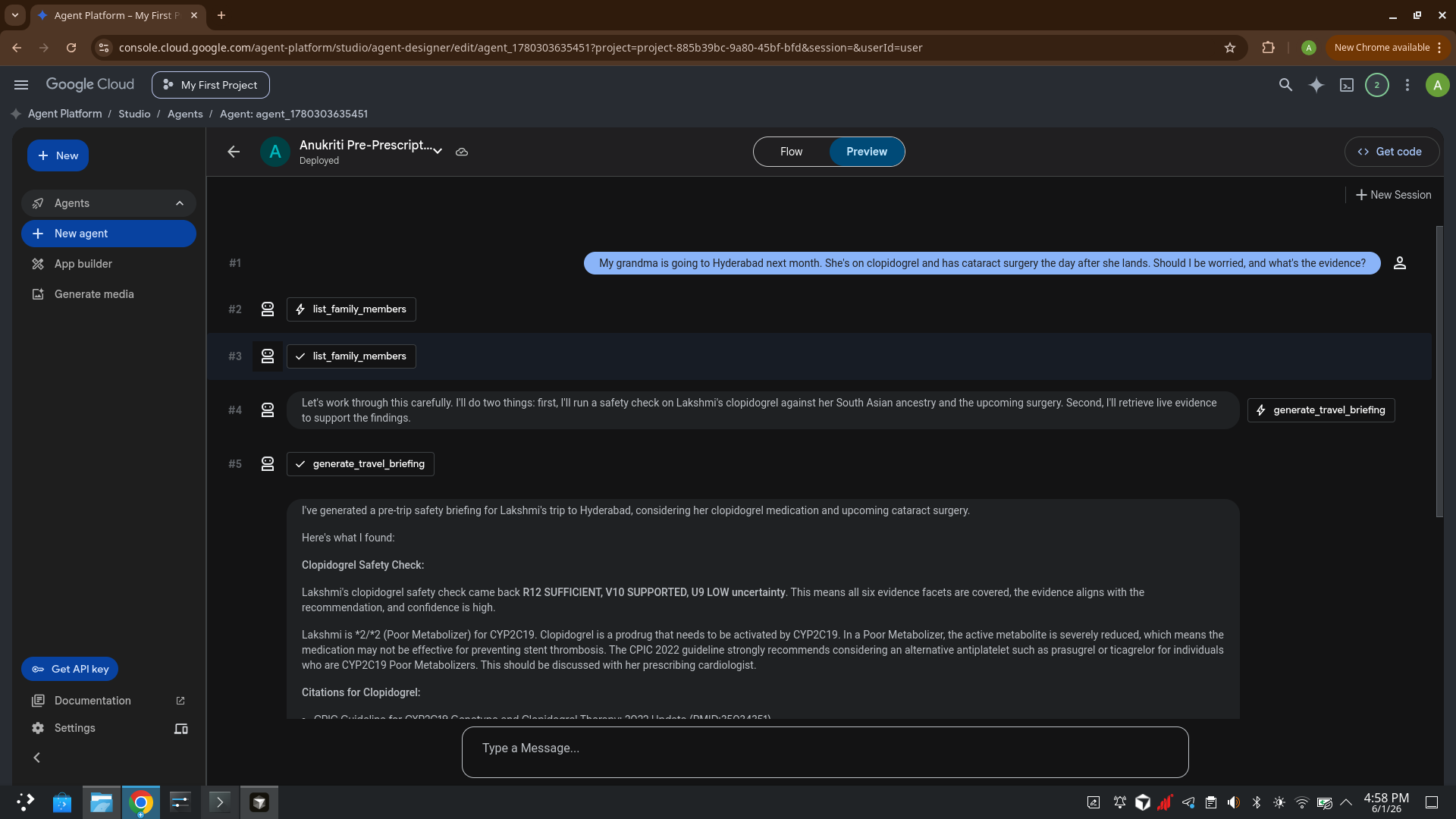
family member's medication or upcoming procedure, and it:
- Looks up the person's ancestry + medications (MongoDB Atlas)
- Runs a deterministic CPIC-pinned safety check — never an LLM guess
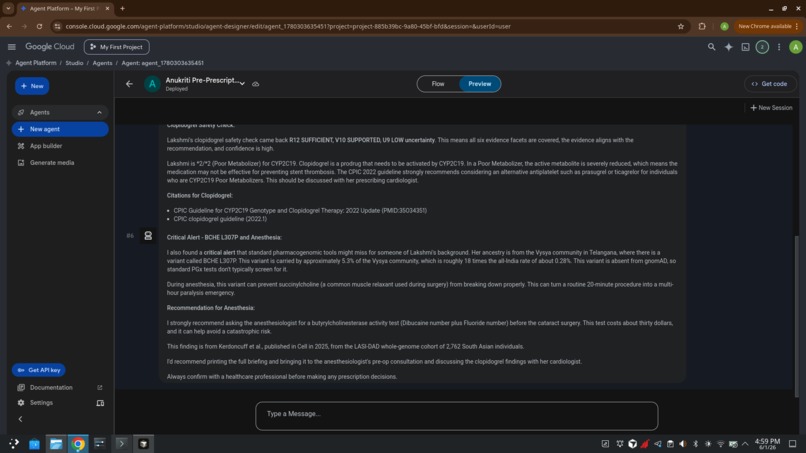
- Returns a named rule ID for every conclusion (R12 SUFFICIENT, V10 SUPPORTED,
U9 LOW uncertainty) and an honest named refusal when evidence is thin - Grounds every recommendation in live evidence retrieved from
Elasticsearch (CPIC guidelines, PubMed, PharmGKB) - Surfaces ancestry-specific risks standard tools miss — most strikingly the
BCHE L307P variant, carried by ~5.3% of the Vysya community (≈18× the
all-India rate, absent from gnomAD), which causes succinylcholine paralysis
during anesthesia
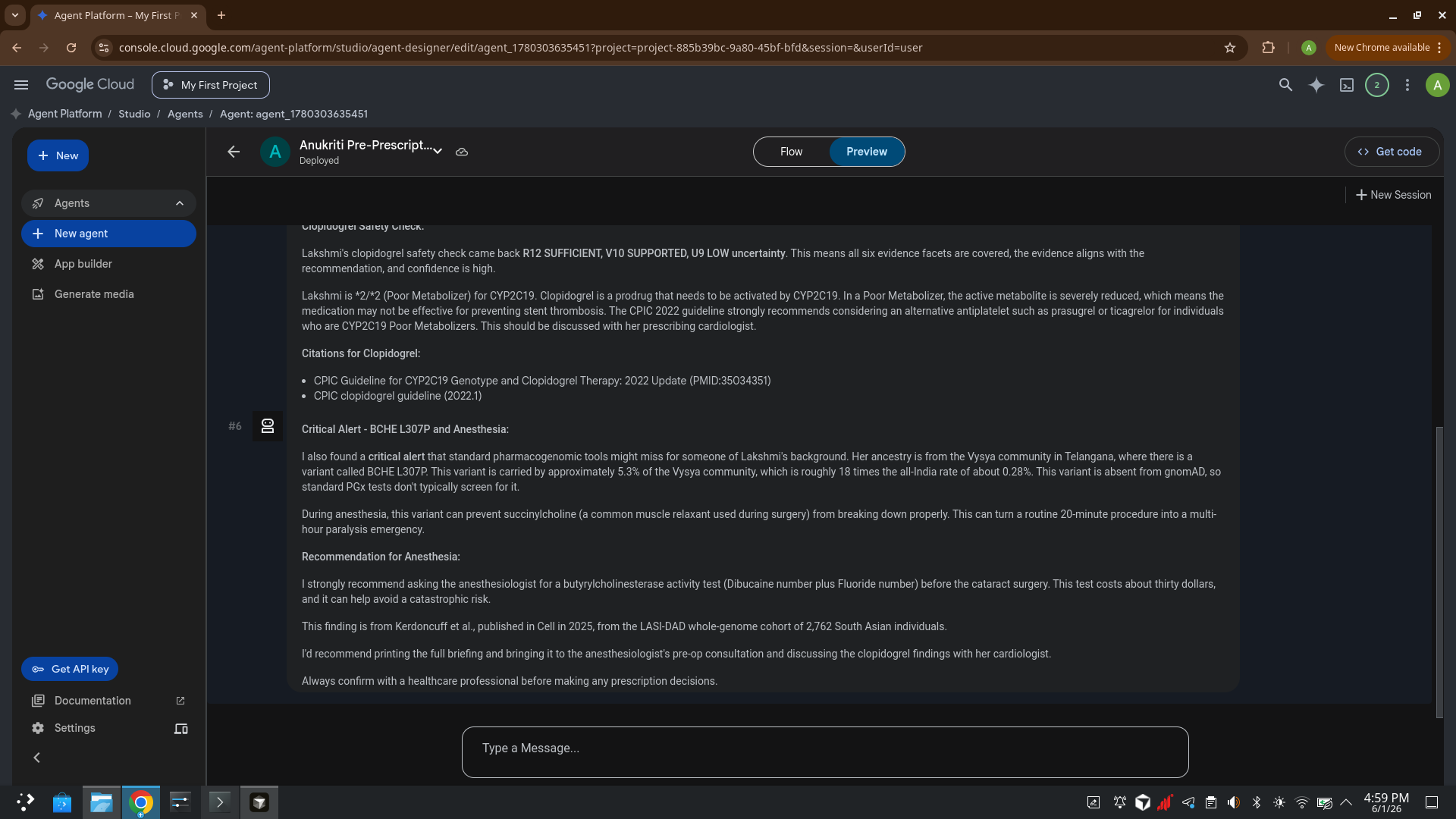
The flagship demo: a grandmother traveling to Hyderabad for cataract surgery.
The agent catches both her ineffective clopidogrel and a $30
butyrylcholinesterase test that prevents a multi-hour anesthesia emergency —
a risk no commercial PGx test screens for.
The LLM explains; it never decides. Every claim cites a rule; every rule
cites a paper; every refusal is named.
How we built it
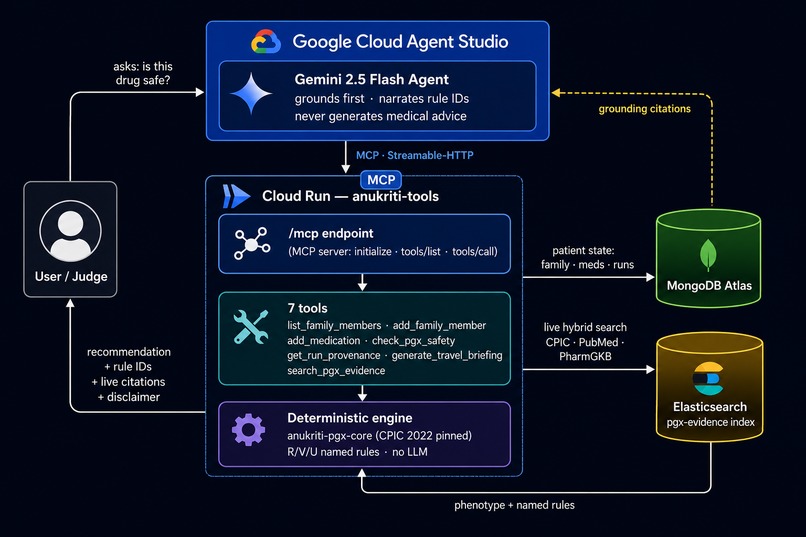
- Agent: Gemini (Google Cloud Agent Studio / Gemini Enterprise Agent
Platform), with a hardened system prompt that forces grounding-first and
rule-ID narration. - Tools: 7 MCP tools served from a Cloud Run container, exposed to
Agent Studio via a Streamable-HTTP MCP server endpoint (/mcp). - Deterministic engine:
anukriti-pgx-core(CPIC 2022 pinned tables),
composed in-process behind the tools — no LLM in the calling path. - Elasticsearch (partner track): a
pgx-evidenceindex seeded with the
exact papers the engine cites; thesearch_pgx_evidencetool runs a live
hybrid query so every citation resolves to a real, retrievable source. - MongoDB Atlas: per-user family rosters, medications, travel plans, runs.
Challenges we ran into
- Agent Studio attaches custom tools only via an MCP server (no OpenAPI
import, no-auth only). Our tools were REST, so we wrote a thin
Streamable-HTTP MCP wrapper over the existing functions. - Smaller models occasionally guessed an ID instead of grounding first; we
fixed it with an explicit "always call list_family_members first, never
invent an ID" hard rule. - Validating partner SDKs against their current contracts surfaced three
real breaks (Elasticsearchbody=deprecation, Fivetran endpoint rename,
Arize v8 API) — caught before they shipped.
Accomplishments that we're proud of
- A medical-safety agent that is hallucination-resistant by construction:
deterministic rules first, LLM only narrates, every refusal named. - Live, load-bearing Elasticsearch grounding — the agent's evidence step
is a real hybrid query, not a static list. - The BCHE/Vysya wedge: surfacing a 2025 Cell-published variant that
gnomAD-based commercial tests are blind to. - 57 passing tests; the engine is independently validated against an external
warfarin cohort (n=5,700).
What we learned
Equity in drug safety is an infrastructure problem, not a model problem.
A bigger LLM over Eurocentric evidence just produces confident wrong
answers. Treating evidence density as first-class — and refusing honestly
when it's thin — is the real fix.
What's next for Anukriti
Wire the remaining partner integrations live (Dynatrace self-observability,
Fivetran cohort ingestion, Arize narration eval — all built), expand beyond
the 3 CPIC workflows, and pursue institutional data partnerships for
controlled-access ancestry data.
Built With
- anukriti-pgx-core
- cloud-run
- cpic
- docker
- elasticsearch
- flask
- gemini
- google-cloud-agent-studio
- gunicorn
- model-context-protocol
- mongodb-atlas
- python

Log in or sign up for Devpost to join the conversation.