-
-
cover image
-
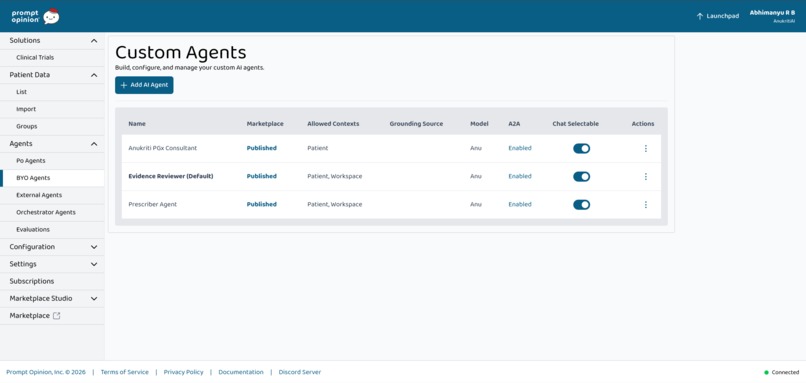
BYO Agents Created
-
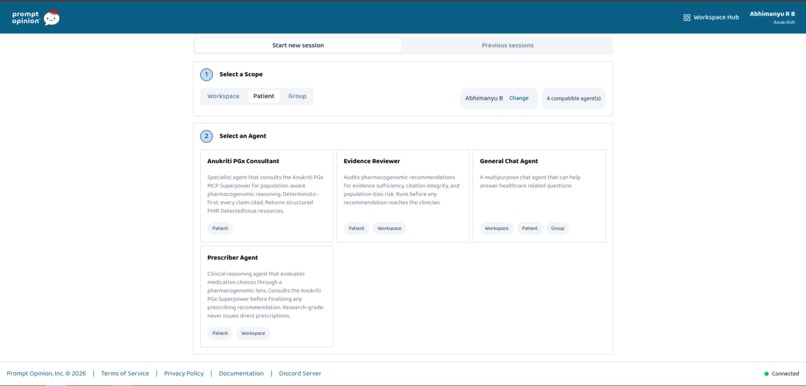
Launchpad
-

Architecture diagram
-
-
-
Agents in action
-
Agents in action
-
Agents in action
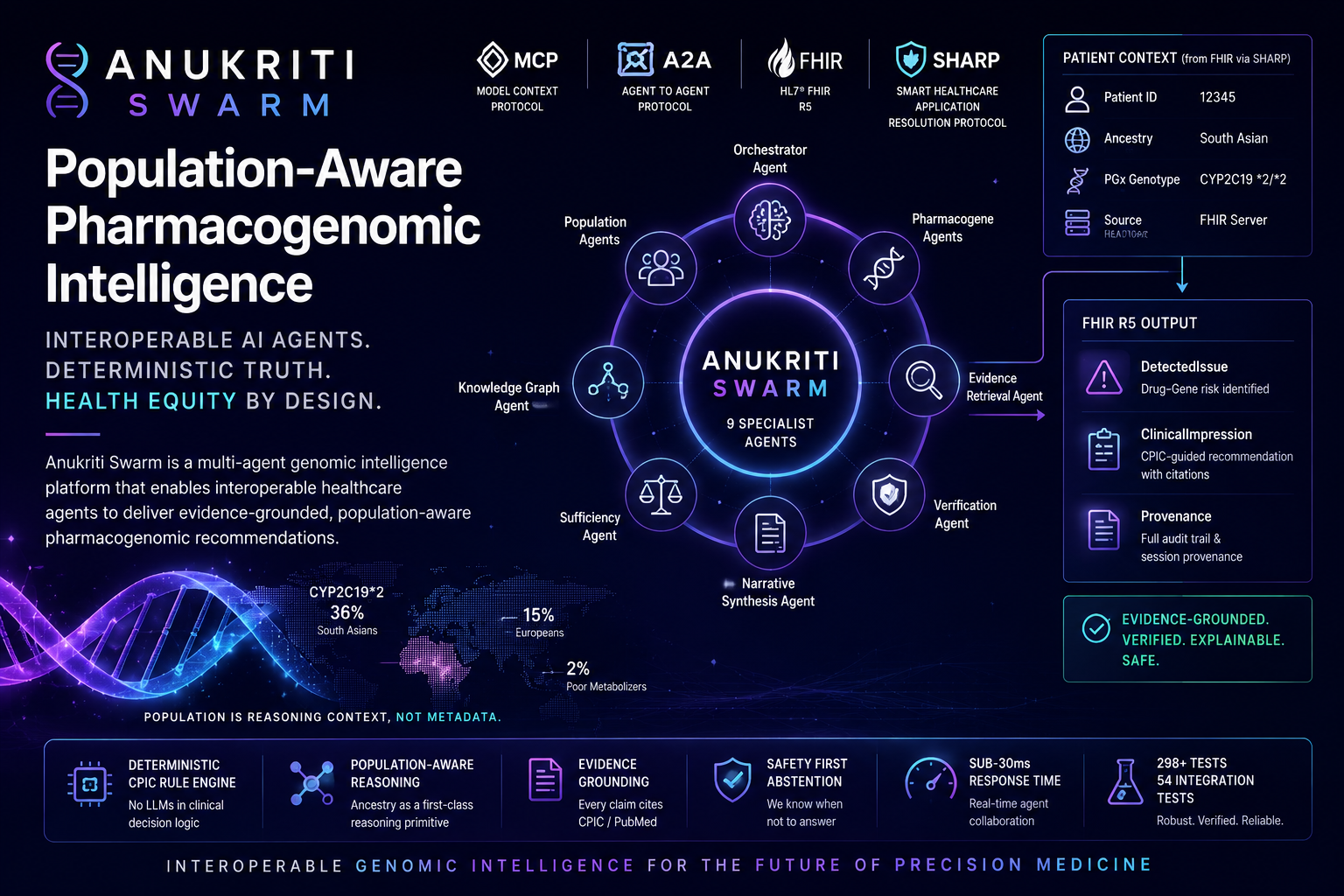

Inspiration
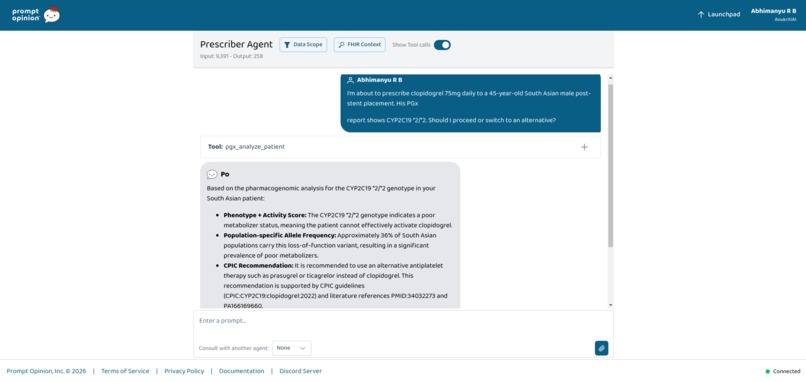
In 2019, one of us watched a cardiologist prescribe clopidogrel to a South Asian uncle after PCI. The drug failed. Six months later, he experienced another cardiac event.
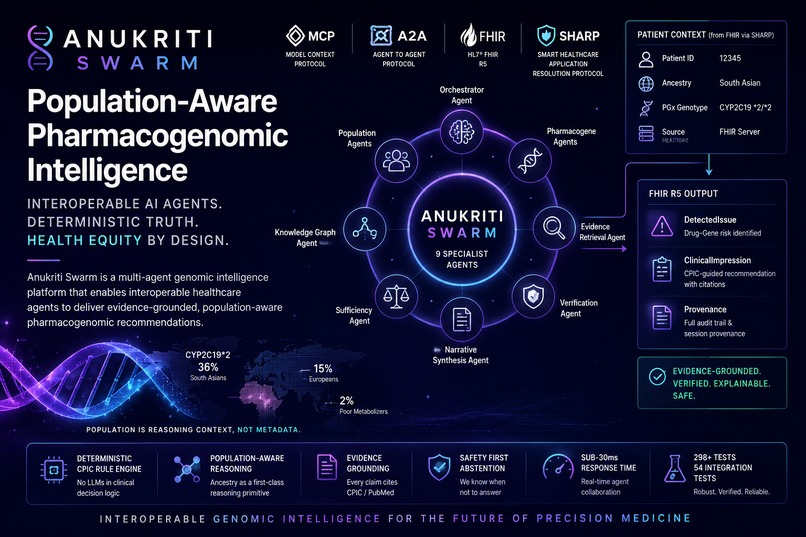
The pharmacogenomic reason was hidden in plain sight: CYP2C19 *2/*2 — a loss-of-function genotype significantly more prevalent in South Asian populations.
- 36% of South Asians carry CYP2C19*2
- compared to 15% of Europeans
- and 14% of South Asians are Poor Metabolizers, versus only 2% of Europeans
Yet current clinical systems largely treat population as metadata rather than reasoning context.
Anukriti began as a deterministic pharmacogenomic simulation platform focused on population-aware clinical trial intelligence. For Agents Assemble, we realized this was the first environment where the ecosystem standards finally existed — MCP, A2A, SHARP, and FHIR — to connect our genomic intelligence system directly into real healthcare agent workflows.
So we built the bridge.
What it does
Anukriti PGx is an interoperable pharmacogenomic intelligence superpower.
Any Prompt Opinion A2A agent can compose Anukriti into a healthcare workflow without needing pharmacogenomics expertise.
Example workflow:
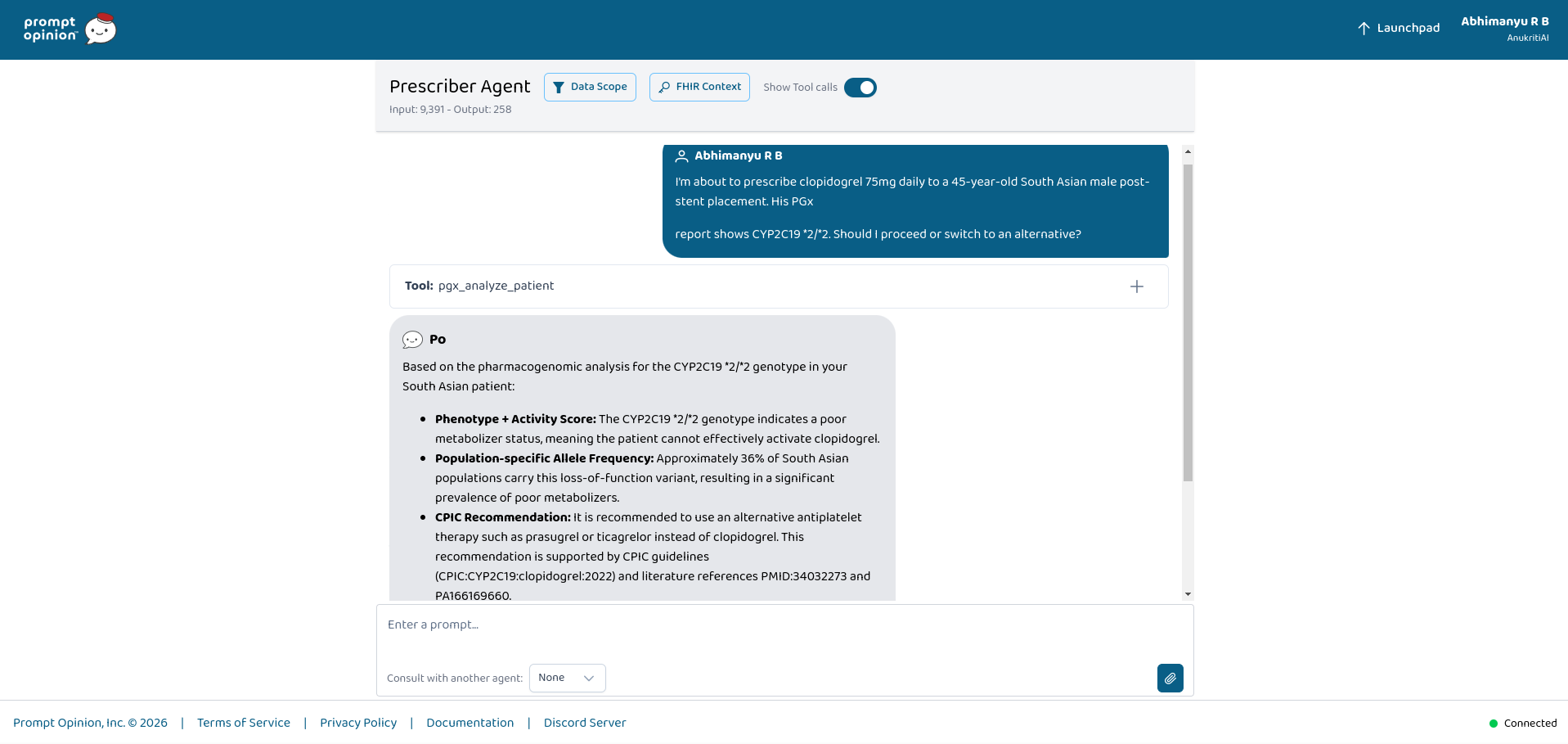
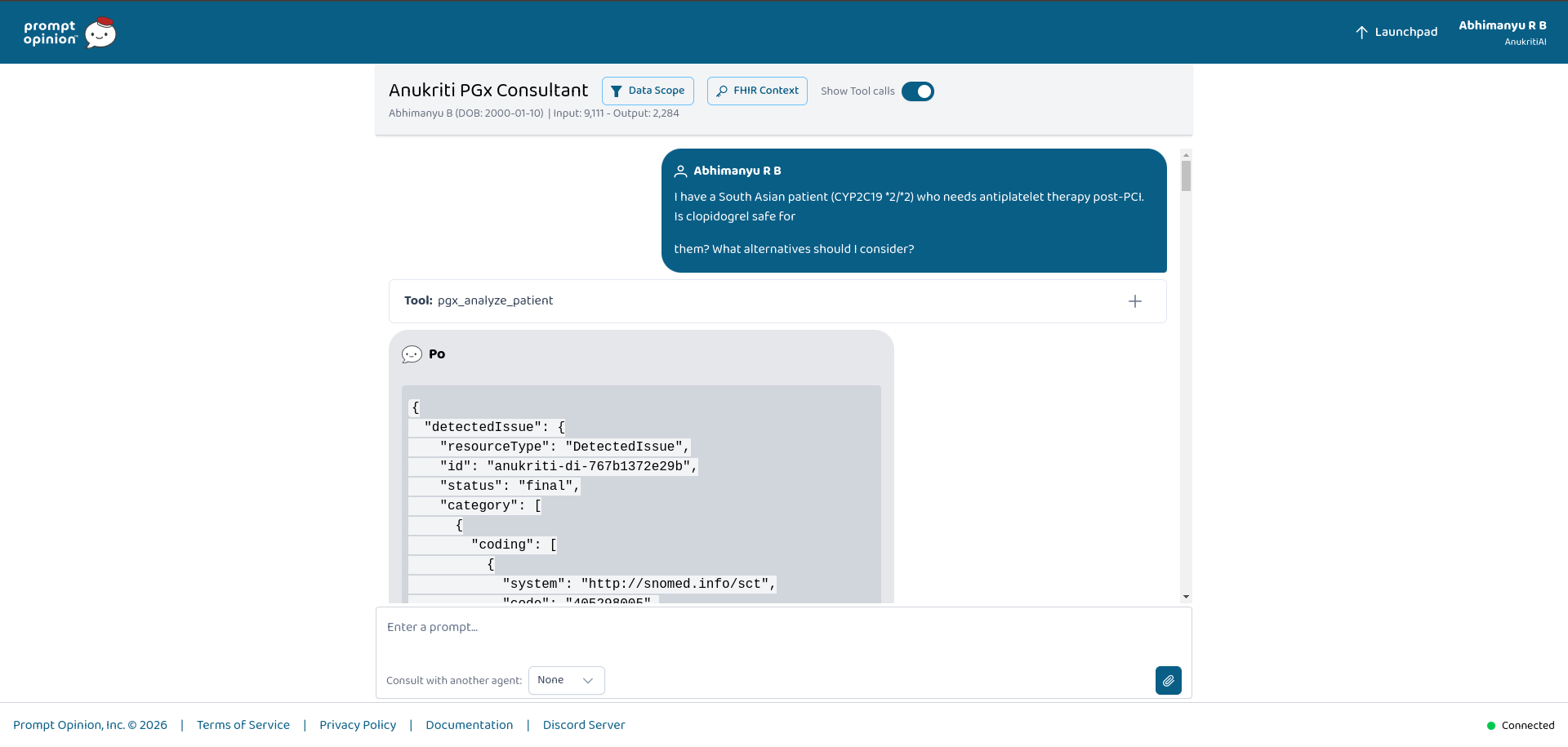
- A prescribing agent detects a pending clopidogrel order
- It asks: “Will this drug work safely for this patient?”
- Anukriti reads:
- ancestry/race context from US Core FHIR extensions
- PGx genotype observations from the patient’s FHIR context
- SHARP session headers provided by Prompt Opinion
- Behind the scenes, specialist genomic agents collaborate to:
- infer pharmacogene phenotypes
- retrieve CPIC/PubMed evidence
- traverse pharmacogenomic knowledge graphs
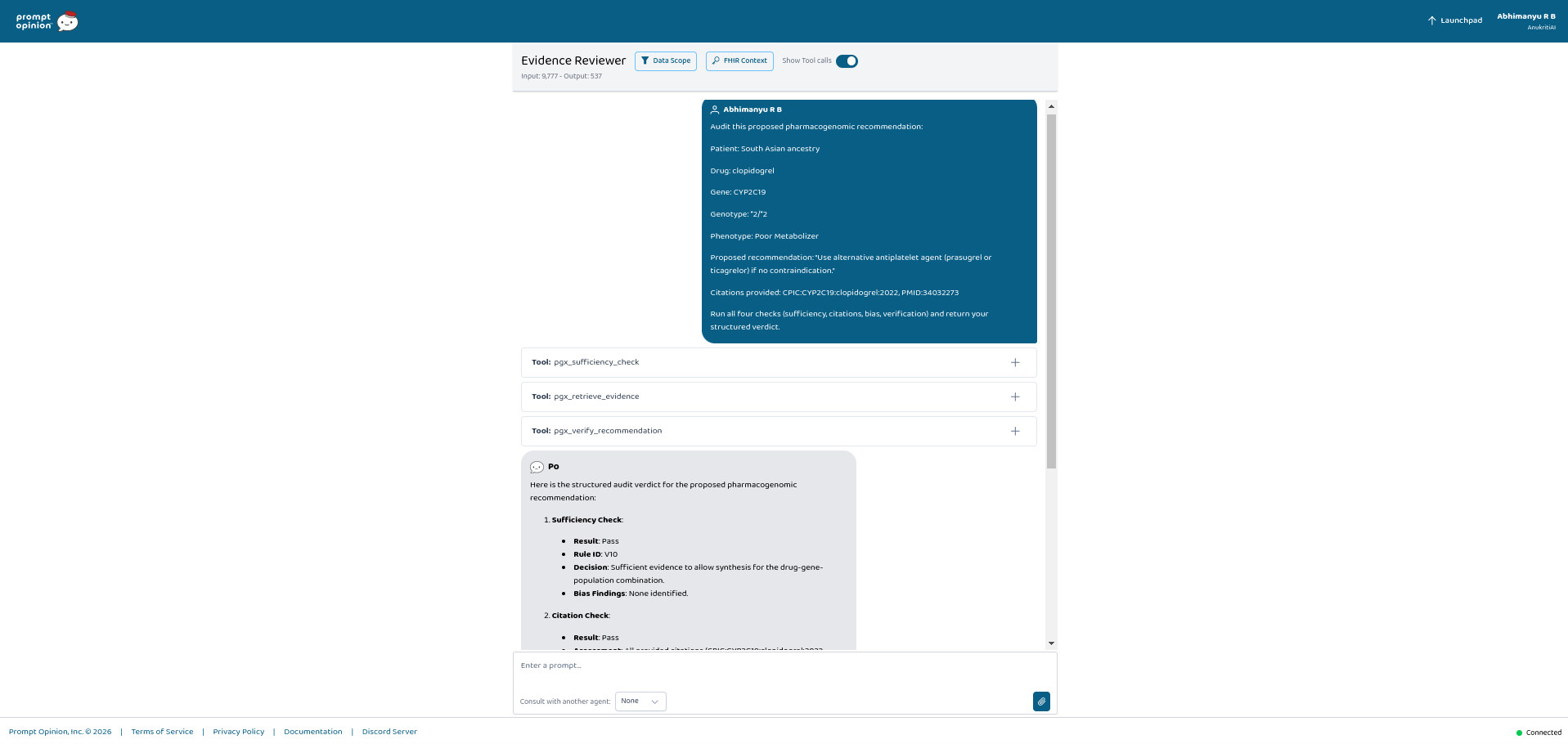
- evaluate evidence sufficiency
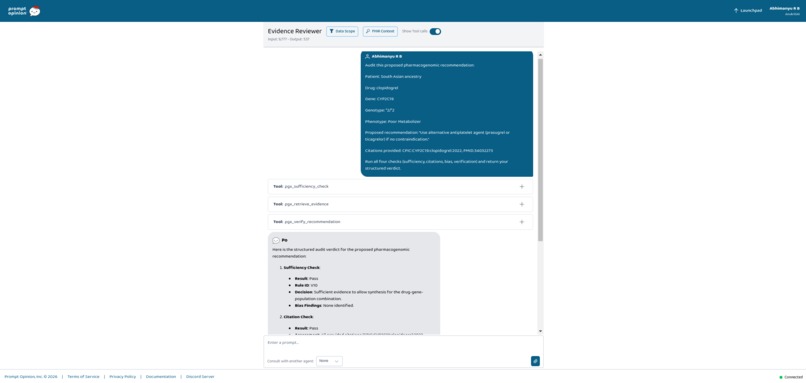
- perform deterministic biomedical verification
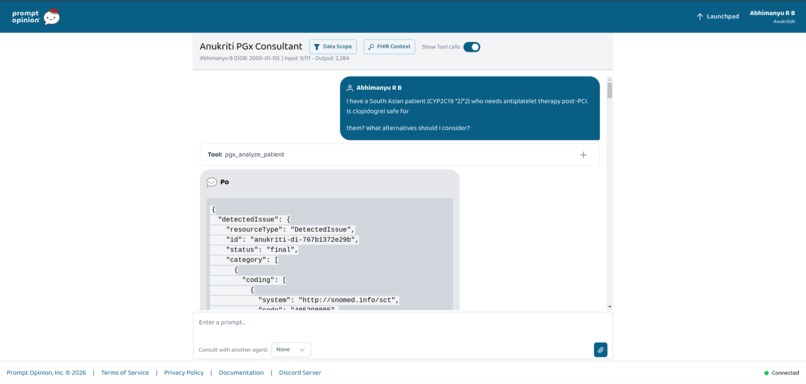
- The system returns structured FHIR R5 resources:
DetectedIssueClinicalImpressionProvenance
Every recommendation includes:
- CPIC protocol references
- PMID citations
- provenance traces
- deterministic verification metadata
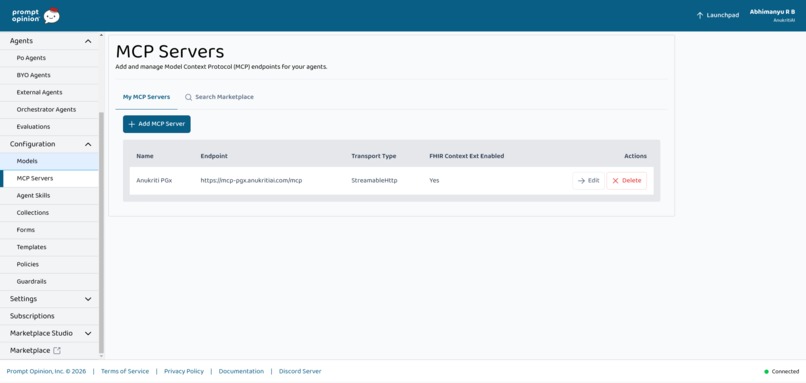
Five MCP tools exposed
pgx_analyze_patient- End-to-end ancestry-aware PGx analysis
pgx_population_risk- Population allele frequency + phenotype prevalence analysis
pgx_retrieve_evidence- CPIC/PubMed evidence retrieval with citations
pgx_verify_recommendation- Deterministic 6-step biomedical verification
pgx_sufficiency_check- Safety abstention gate for insufficient evidence scenarios
No hallucinated recommendations. No silent prescriptions. Every claim is evidence-grounded and provenance-linked.
How we built it
The central architectural principle behind Anukriti is a strict:
Deterministic ↔ Generative Boundary
LLMs are allowed to:
- orchestrate workflows
- synthesize narratives
- coordinate retrieval
LLMs are NOT allowed to:
- override CPIC rules
- fabricate biomedical claims
- bypass verification
- modify deterministic PGx outputs
Violations raise runtime exceptions.
Core architecture
Deterministic Biomedical Core
anukriti-pgx-core- CPIC-aligned PGx engine
- deterministic phenotype classification
- activity-score systems
- allele interpretation pipelines
- versioned biomedical rules
Multi-Agent Swarm
9 specialist agents collaborate through typed orchestration:
- orchestrator agent
- population agents
- pharmacogene agents
- evidence retrieval agent
- verification agent
- narrative synthesis agent
Population-Aware Knowledge Graph
- 37 nodes
- 34 edges
- population as a first-class graph node
- ancestry-aware reasoning pathways
Multi-Strategy Retrieval (MA-RAG)
Combines:
- dense retrieval
- population-aware retrieval
- graph traversal
- diversity-aware evidence selection
- adaptive retrieval stopping
Evidence Sufficiency Layer
Deterministic governance layer that:
- checks evidence completeness
- detects sparse ancestry evidence
- prevents unsafe synthesis
- performs structured abstention
Verification Engine
6-step biomedical verification covering:
- provenance
- guideline conflicts
- evidence grounding
- hallucination hooks
- ancestry scarcity
- deterministic consistency
Interoperability Layer
Built specifically for this hackathon:
- FastMCP server
- SHARP-compatible context propagation
- A2A-enabled specialist agents
- FHIR R5 interoperability adapters
Output resources
The system produces:
DetectedIssueClinicalImpressionProvenance
all cross-linked with verifiable references and provenance chains.
Challenges we ran into
1. FHIR R4 ↔ R5 compatibility
FHIR R5 introduced multiple structural changes, especially around:
DetectedIssueClinicalImpression
We implemented adapter-layer normalization and round-trip validation tests.
2. Population inference ambiguity
US Core race encoding often collapses multiple genetically distinct populations into broad categories.
For example:
- OMB “Asian” includes both:
- South Asian
- East Asian
This distinction is critically important in pharmacogenomics.
We implemented a two-pass ancestry parser:
- detailed sub-extension parsing first
- OMB fallback second
3. Read-only interoperability
We intentionally designed Anukriti as:
- analysis infrastructure
- not EHR mutation infrastructure
The calling system decides whether to persist generated resources.
4. Sparse population evidence
Sparse ancestry data initially caused false-positive uncertainty flags.
We fixed this by propagating population frequency evidence deeper into the verification pipeline.
Accomplishments that we're proud of
- Zero modifications to the original swarm runtime
- Fully additive interoperability layer under
hackathon/ - 298 passing tests total
- 54 dedicated interoperability integration tests
- Every recommendation linked to CPIC + PMID references
- Structured abstention with rule-level explanations
- Sub-30ms end-to-end execution for flagship workflows
- Deterministic biomedical governance with explainable provenance
Most importantly, we built a reusable healthcare AI pattern:
“LLMs narrate. Deterministic systems decide.”
We believe this boundary is essential for safe biomedical AI.
What we learned
- MCP + SHARP context propagation dramatically simplifies healthcare agent interoperability
- Deterministic-first architectures build immediate clinician trust
- Population-aware reasoning becomes much stronger when ancestry is modeled as a typed reasoning primitive rather than metadata
- Structured abstention is critical for production healthcare AI systems
- Provenance and explainability are not optional in pharmacogenomic workflows
Most importantly: Healthcare AI systems need evidence governance, not just language generation.
What's next for Anukriti PGx – Pharmacogenomic Intelligence Superpower
- Expand CPIC coverage across additional pharmacogenes
- Add raw VCF ingestion workflows
- Build evidence currency validation for outdated biomedical guidance
- Introduce episodic genomic reasoning memory
- Support multi-drug pharmacogenomic interaction analysis
- Expand ancestry-aware reasoning for underrepresented populations
- Evolve toward interoperable genomic intelligence infrastructure for precision medicine research and clinical trial simulation




Log in or sign up for Devpost to join the conversation.