-
-
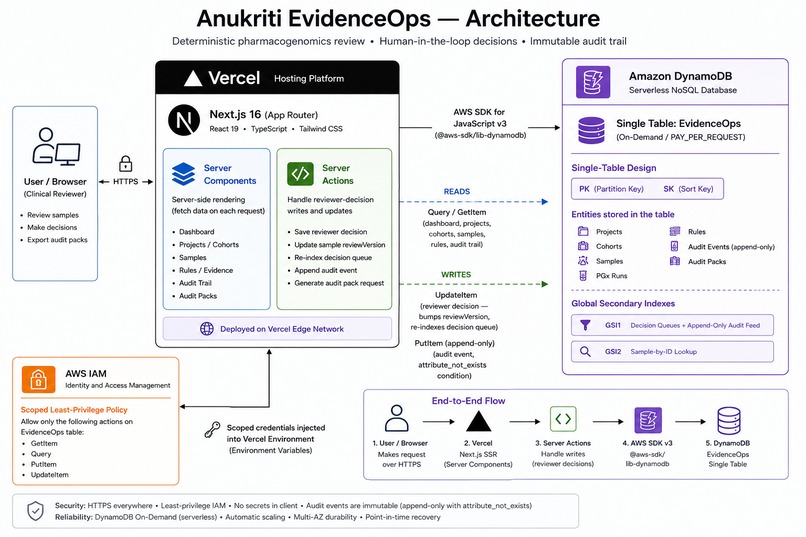
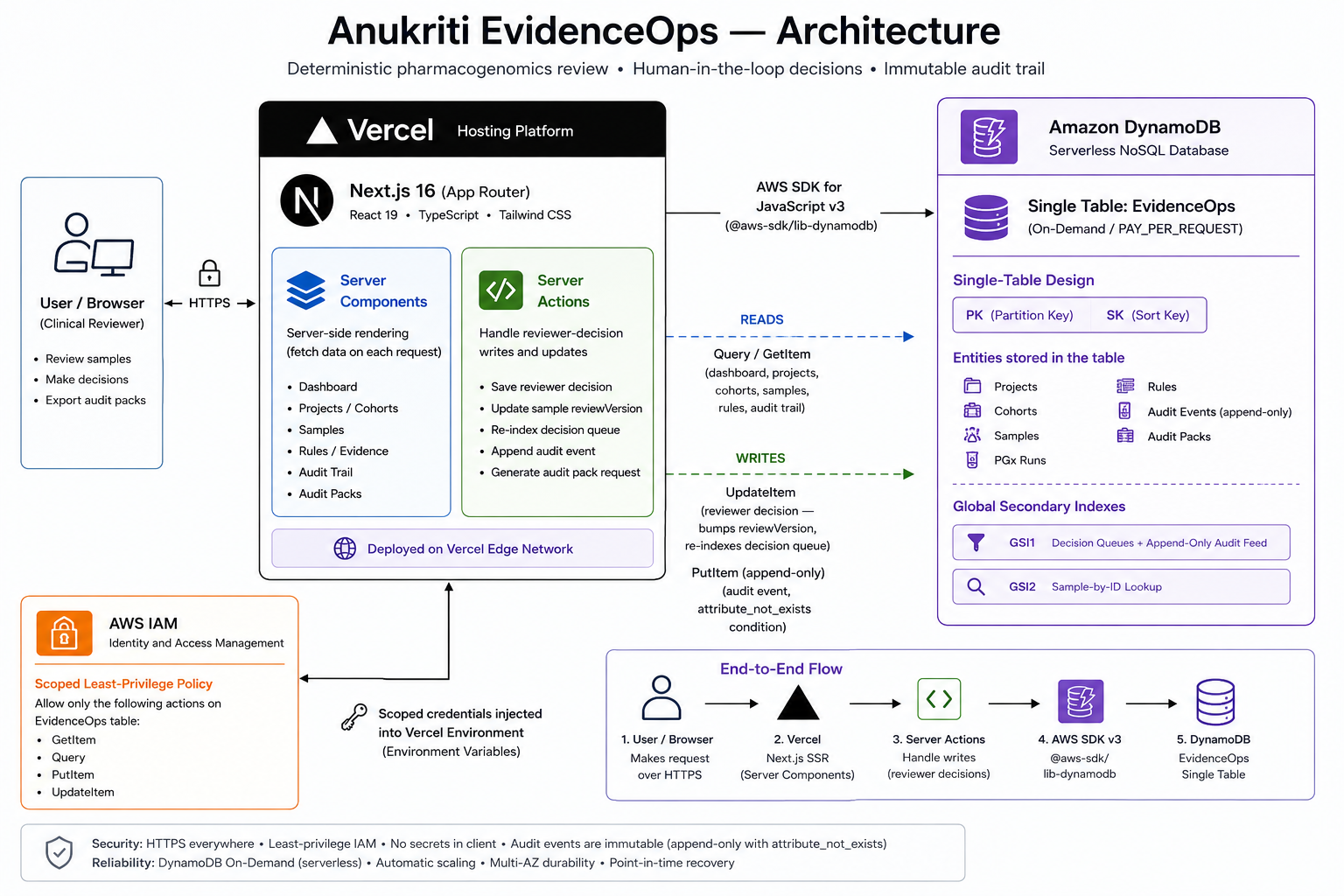
Architecture diagram
-
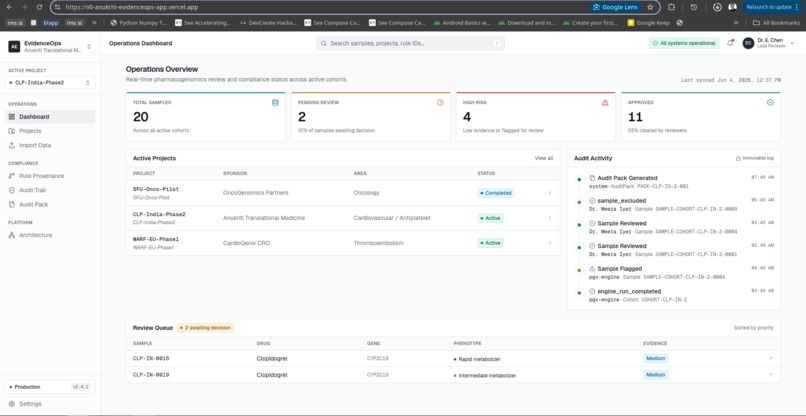
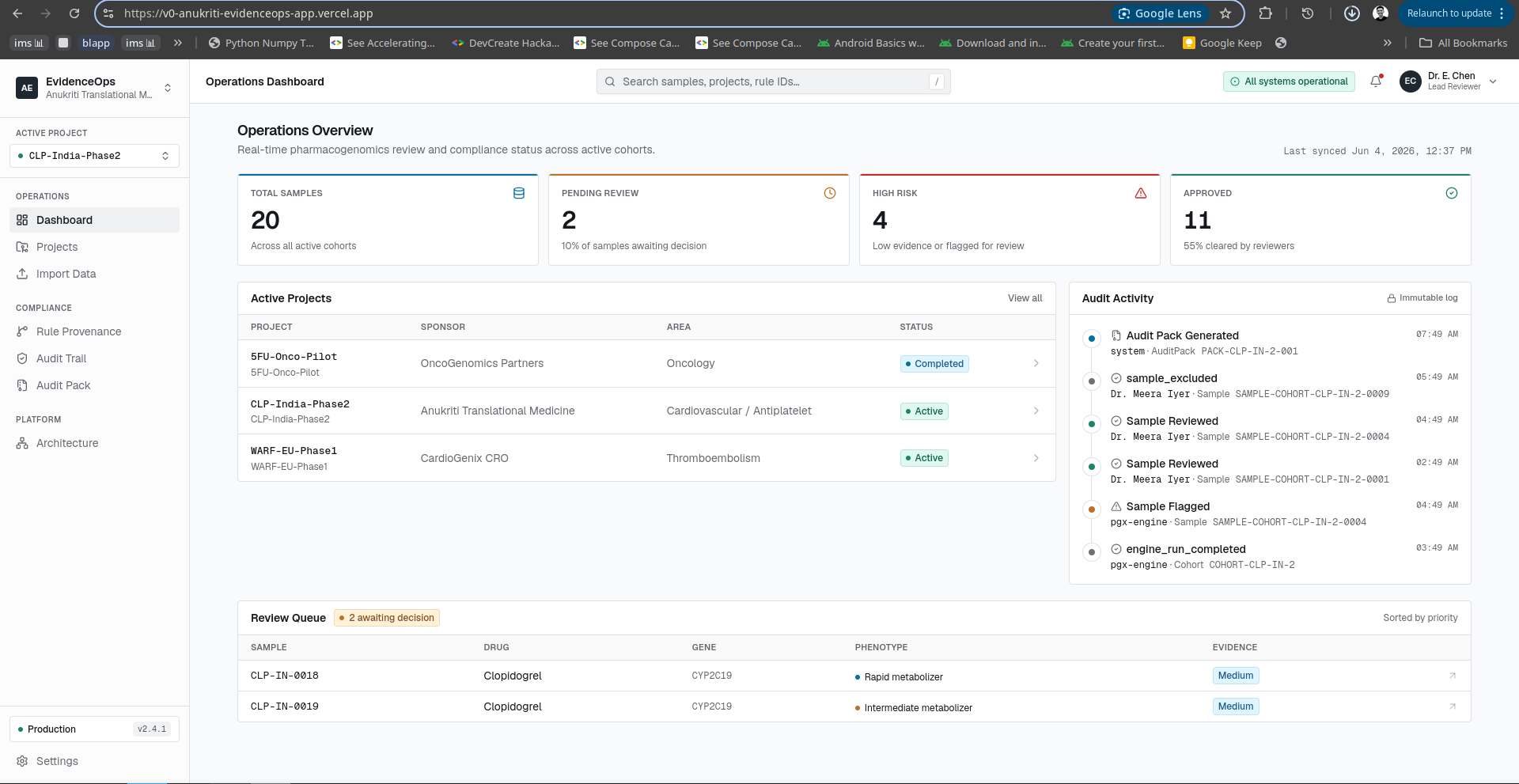
Dashboard Window
-
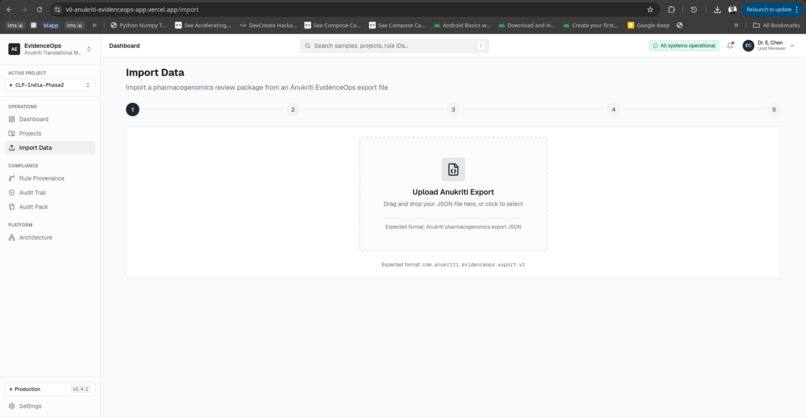
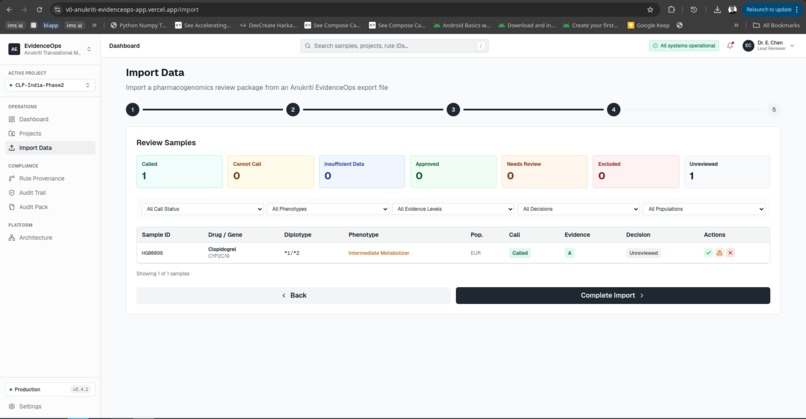
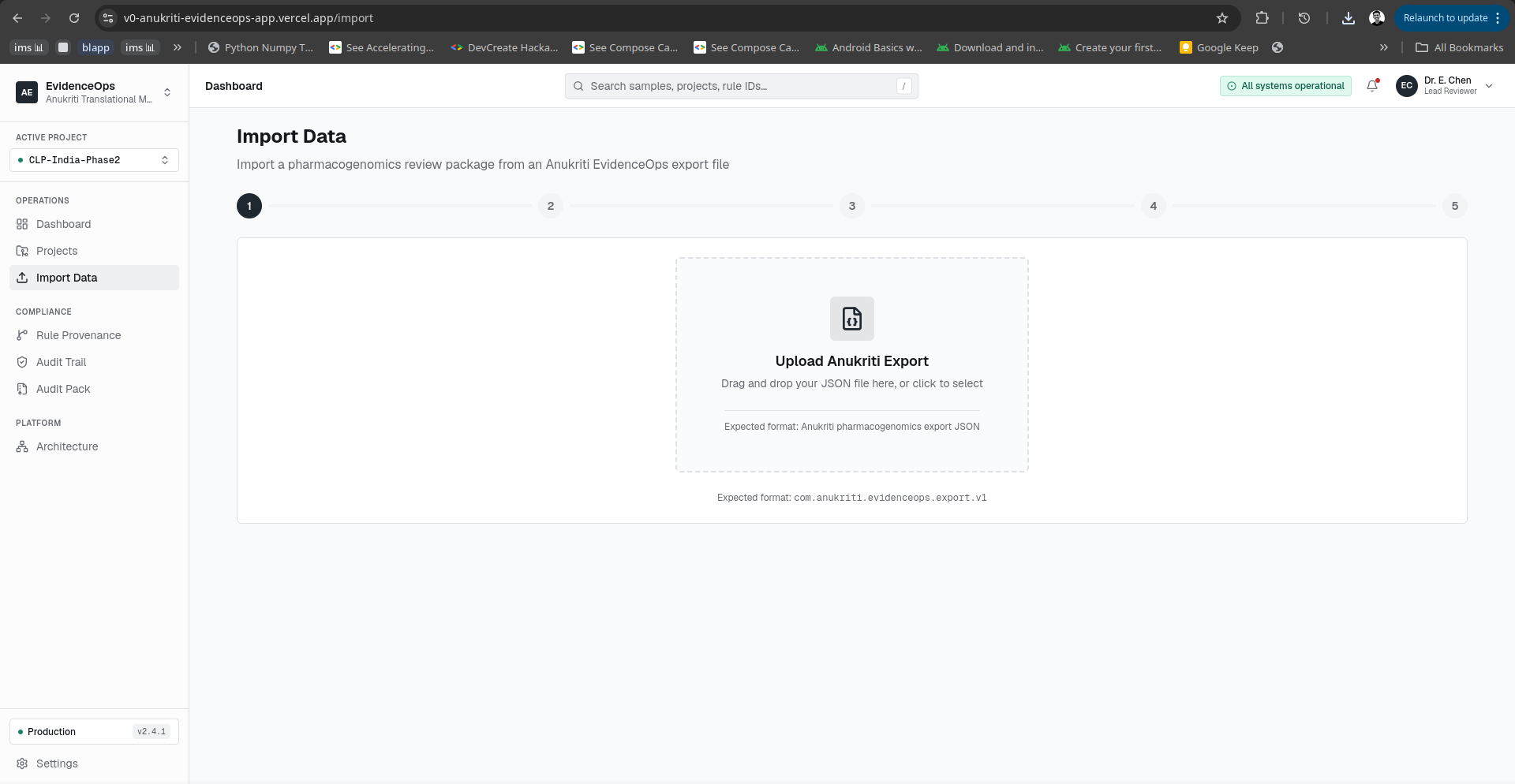
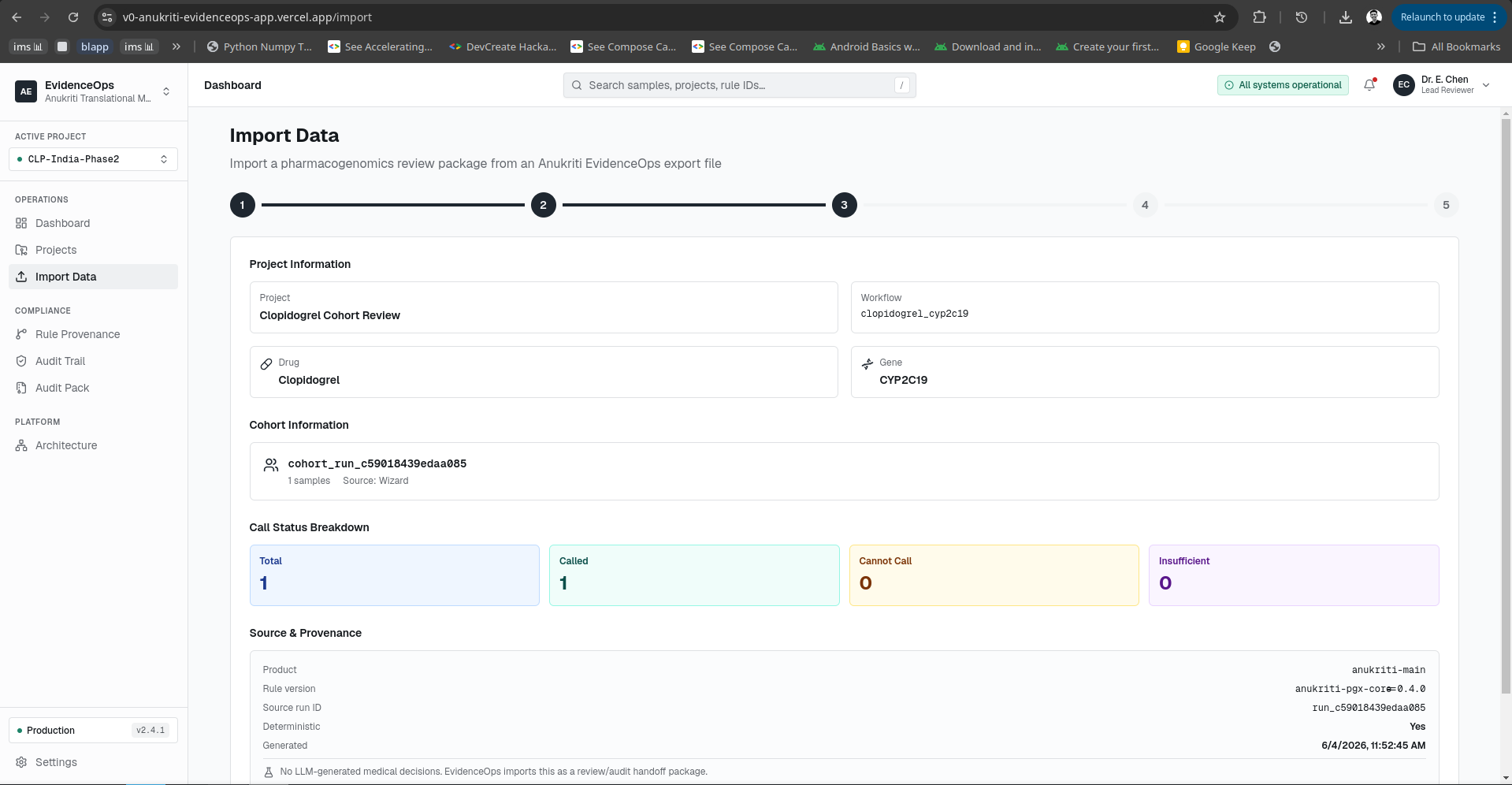
Import Data Window
-
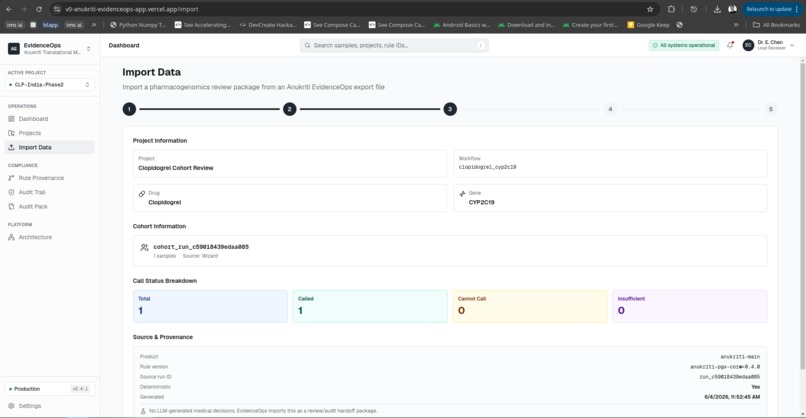
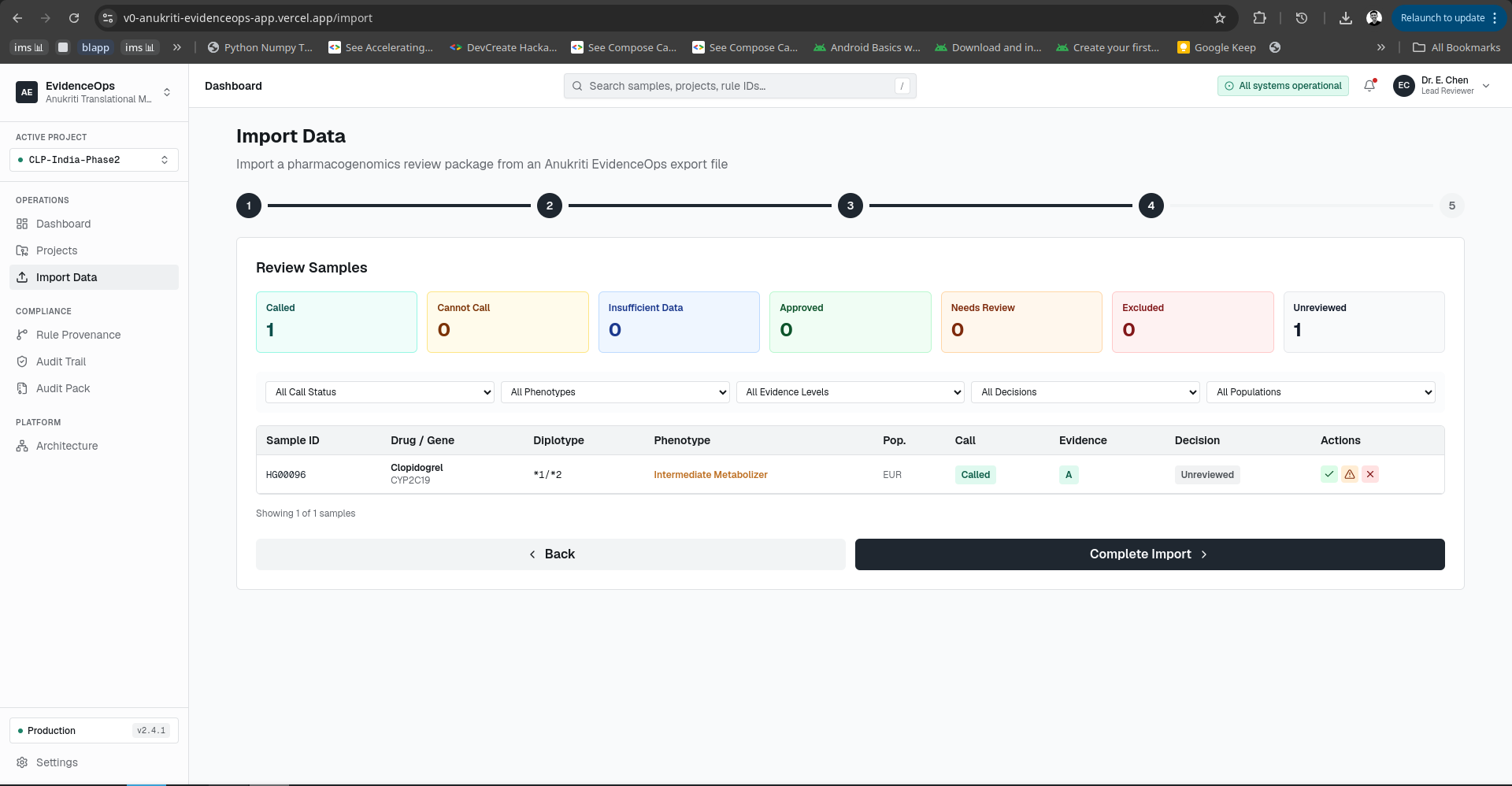
Imported Data summary
-
Saving imported data
Inspiration
Pharmacogenomics has the potential to make therapies safer and more effective by tailoring treatment decisions to a patient's genetic profile. While deterministic PGx engines can generate clinically relevant outputs, there is still a major gap between generating a result and operationalizing it within biotech and CRO workflows.
We were inspired by a simple question:
How can a translational medicine team trust, review, audit, and reuse pharmacogenomics outputs across studies?
Most existing workflows rely on spreadsheets, fragmented documentation, and manual review processes. We wanted to build the governance and operational layer around pharmacogenomics analysis—one that emphasizes traceability, reproducibility, and human oversight.
What it does
Anukriti EvidenceOps is a pharmacogenomics review and audit workspace designed for biotech companies, clinical research organizations (CROs), and translational medicine teams.
The platform enables users to:
- Import pharmacogenomics cohort results
- Review deterministic PGx calls at the sample level
- Examine evidence sufficiency and rule provenance
- Flag uncertain or insufficient-evidence cases
- Record reviewer decisions and notes
- Maintain an immutable audit trail of every action
- Generate audit-ready exports for partners, sponsors, and regulatory workflows
A key principle of the platform is:
No LLM-generated medical decisions.
Every recommendation is tied to deterministic rules, evidence sources, reviewer actions, and auditable provenance.
How we built it
We built Anukriti EvidenceOps as a modern full-stack application using:
Frontend
- Next.js App Router
- TypeScript
- Tailwind CSS
- shadcn/ui
- Lucide icons
AWS Infrastructure
- Amazon DynamoDB as the primary operational datastore
- AWS Lambda for audit pack generation workflows
- Amazon S3 for export storage
- Amazon EventBridge for immutable event processing
Core Data Model
The application uses a DynamoDB-backed single-table design to manage:
- Projects
- Cohorts
- Samples
- PGx Runs
- Evidence Reviews
- Audit Events
- Audit Packs
We also implemented:
- Cohort review workflows
- Evidence review side panels
- Rule provenance tracking
- Import validation against a real Anukriti export schema
- Version manifests for engine, evidence, and review tracking
- Audit-ready CSV and JSON export generation
The frontend is deployed on Vercel and designed as a dense healthcare operations dashboard optimized for enterprise users rather than consumers.
Challenges we ran into
One of the biggest challenges was designing a workflow that felt realistic for biotech and clinical operations teams rather than building another generic dashboard.
We spent significant time modeling how reviewer decisions, evidence sufficiency, rule provenance, and audit requirements interact in real-world pharmacogenomics programs.
Another challenge was designing a DynamoDB schema that supports both operational queries and immutable audit history while remaining scalable and easy to extend.
We also had to balance usability with compliance-focused requirements, ensuring that the system remained approachable while exposing enough metadata for scientific review and reproducibility.
Accomplishments that we're proud of
- Built a complete pharmacogenomics review and governance workflow
- Created a realistic evidence review experience centered on deterministic PGx calls
- Implemented rule provenance and evidence traceability throughout the platform
- Designed an immutable audit-event model suitable for regulated environments
- Developed a real-schema import pipeline instead of relying on mock-only data
- Integrated AWS-native architecture patterns using DynamoDB, Lambda, S3, and EventBridge
- Created a polished healthcare operations interface tailored to biotech and CRO users
What we learned
This project reinforced how important governance, auditability, and reproducibility are in healthcare software.
We learned that generating an analysis result is only one part of the problem. Equally important is helping teams review, understand, justify, and operationalize those results in a transparent way.
From a technical perspective, we gained deeper experience designing event-driven workflows, modeling healthcare review systems, and building scalable DynamoDB access patterns.
What's next for Anukriti EvidenceOps
Our vision is to evolve EvidenceOps into a production-ready governance platform for pharmacogenomics programs.
Future work includes:
- Multi-user reviewer workflows and approvals
- Integration with laboratory and clinical data systems
- Advanced cohort analytics and risk stratification
- Automated compliance reporting
- Electronic signatures and reviewer attestation
- Sponsor and partner collaboration portals
- Real-time audit monitoring
- Integration with the broader Anukriti pharmacogenomics ecosystem
Ultimately, we want to make pharmacogenomics workflows more transparent, reproducible, and operationally scalable for research and clinical teams worldwide.'
Built With
- amazon-dynamodb
- amazon-web-services
- aws-iam
- aws-sdk
- css
- git
- javascript
- next.js
- node.js
- pnpm
- radix-ui
- react
- react-hook-form
- recharts
- shadcn-ui
- tailwindcss
- typescript
- vercel
- zod

Log in or sign up for Devpost to join the conversation.