-
-
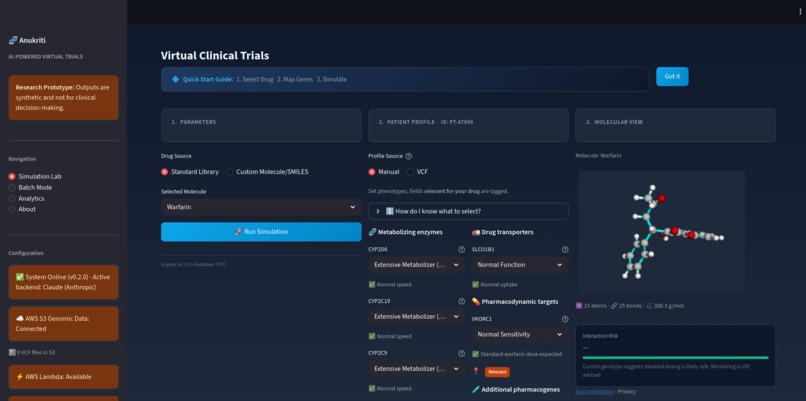
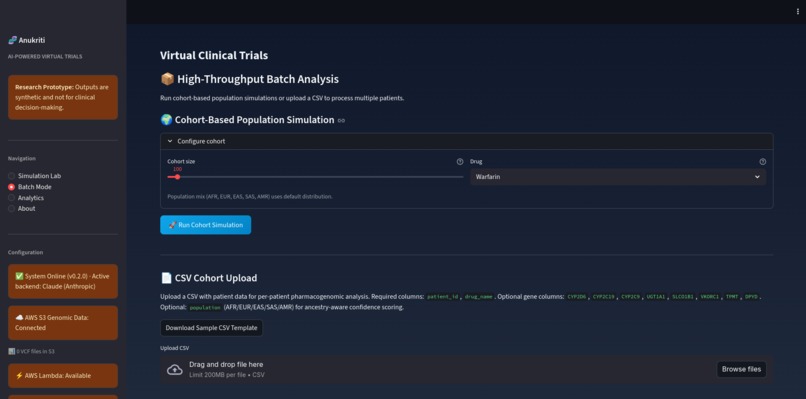
Simulation Lab Screenshot
-
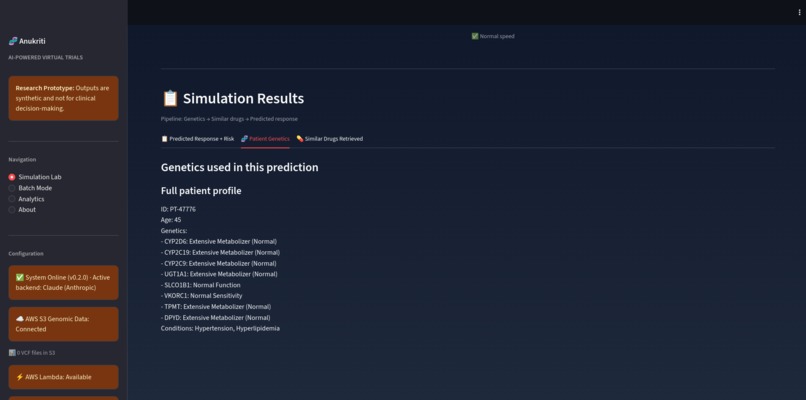
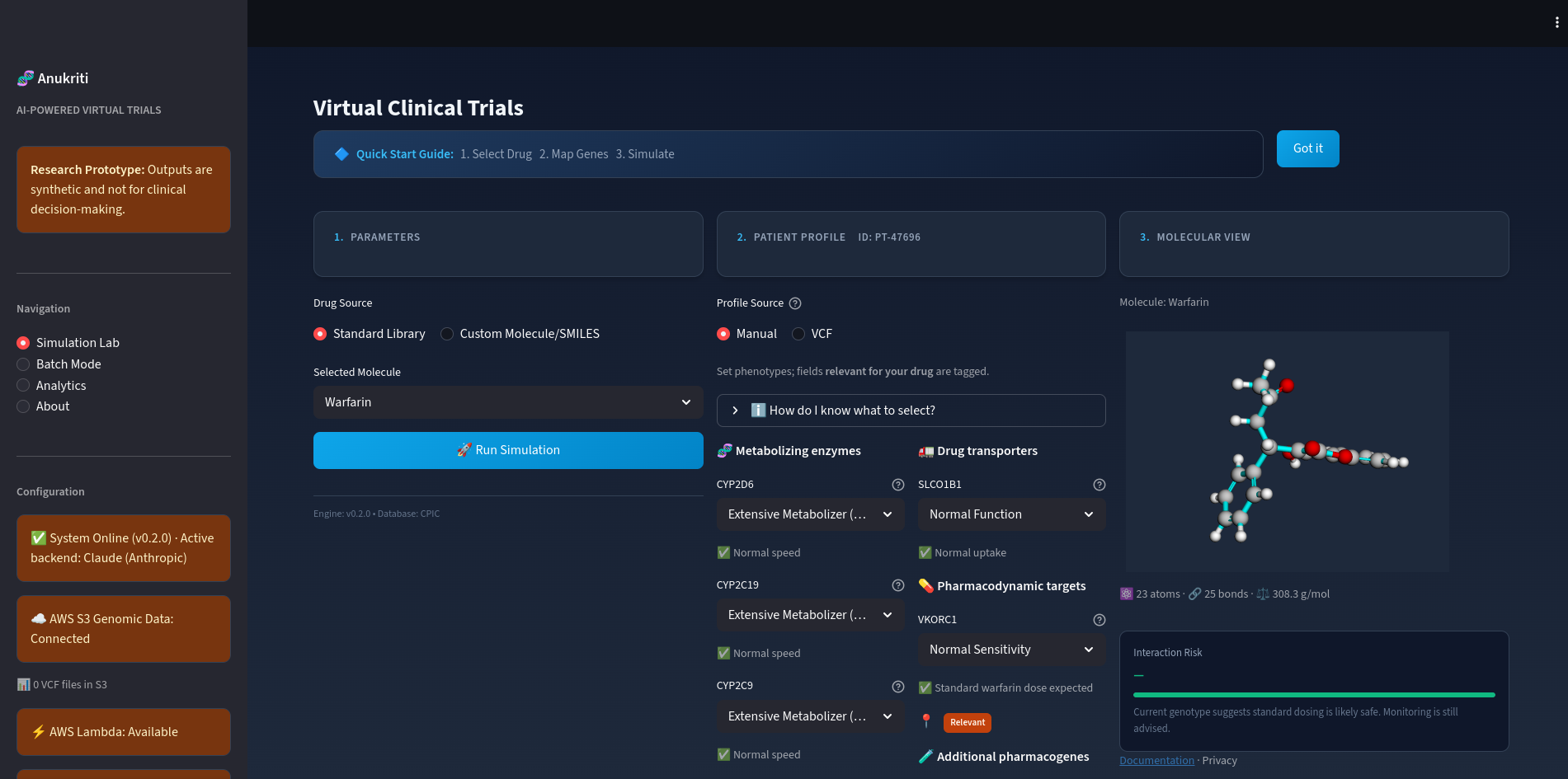
Patient Genetics Screenshot
-
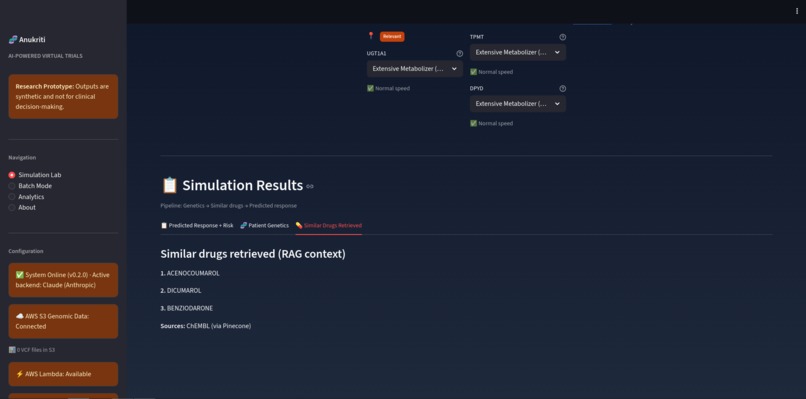
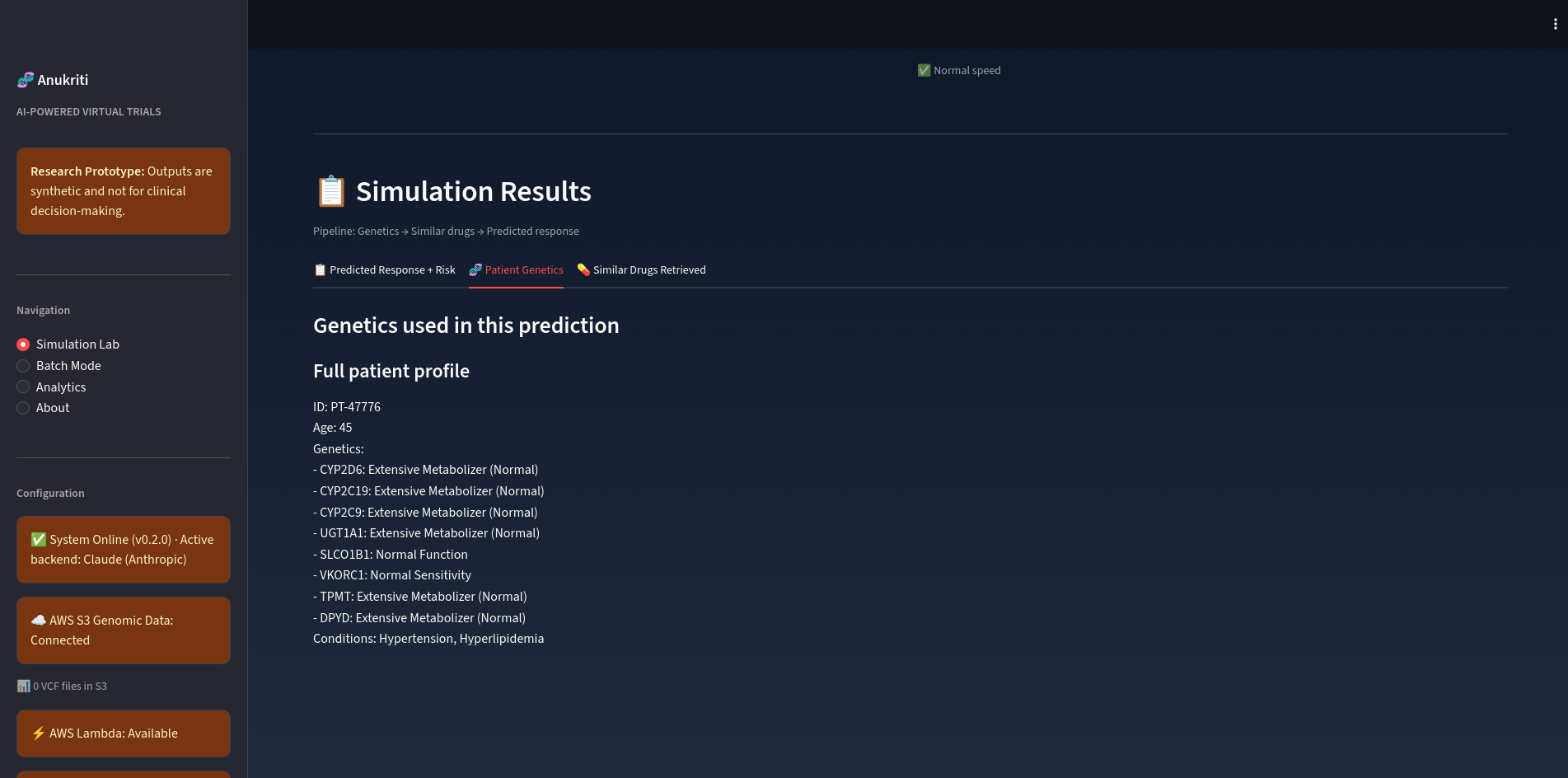
Similar Drugs Screenshot
-
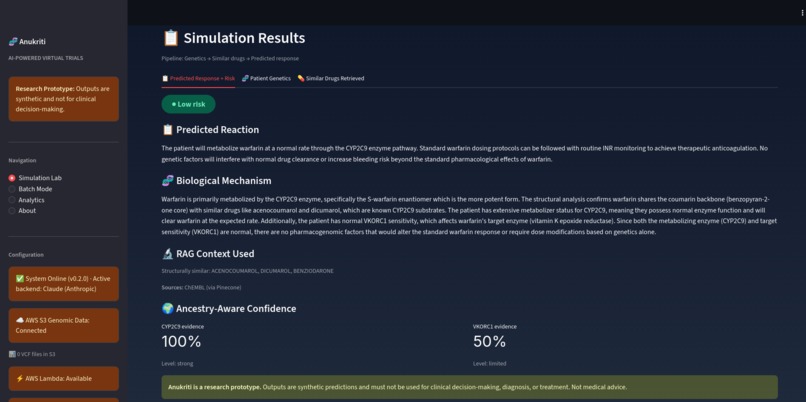
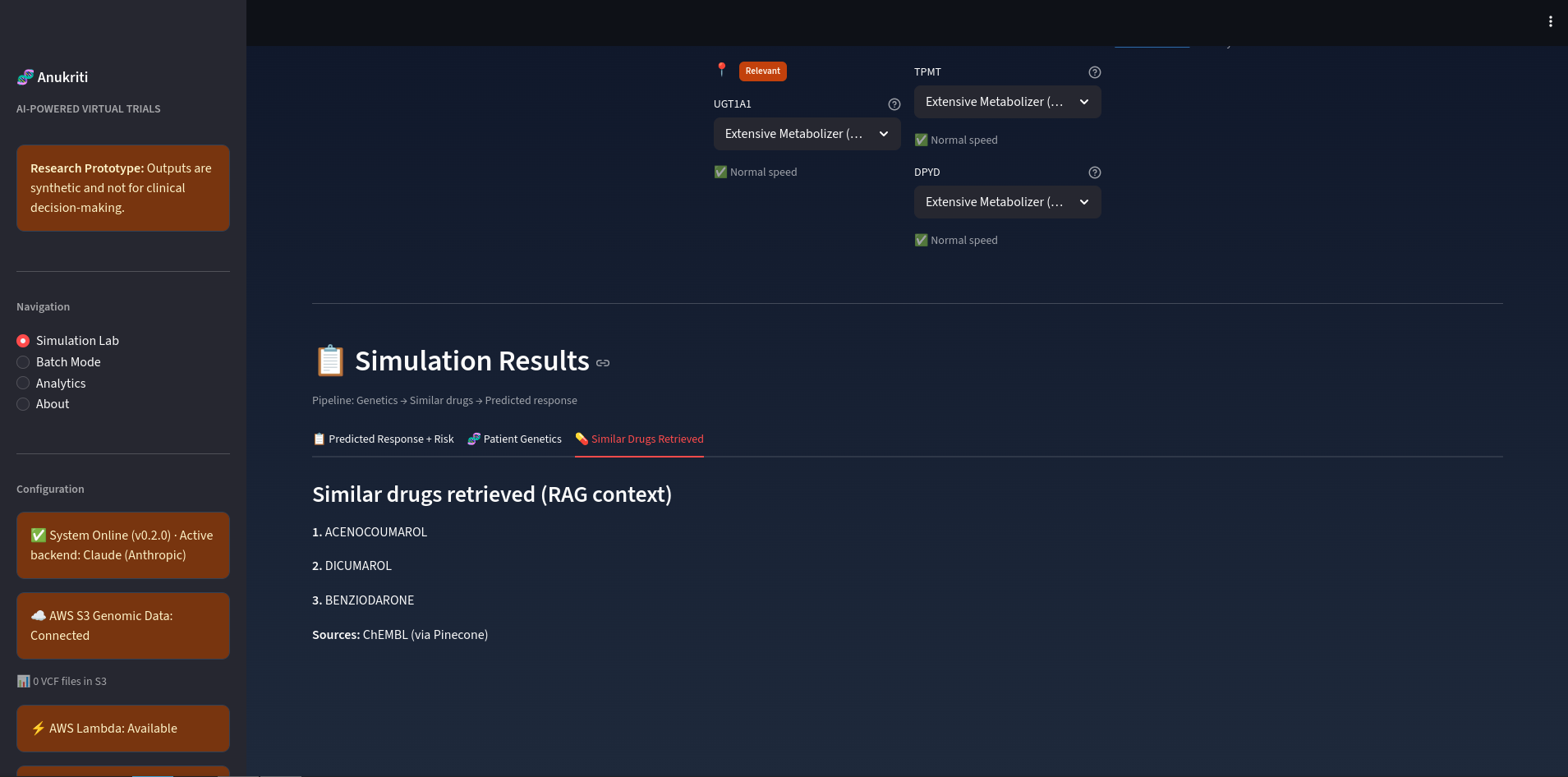
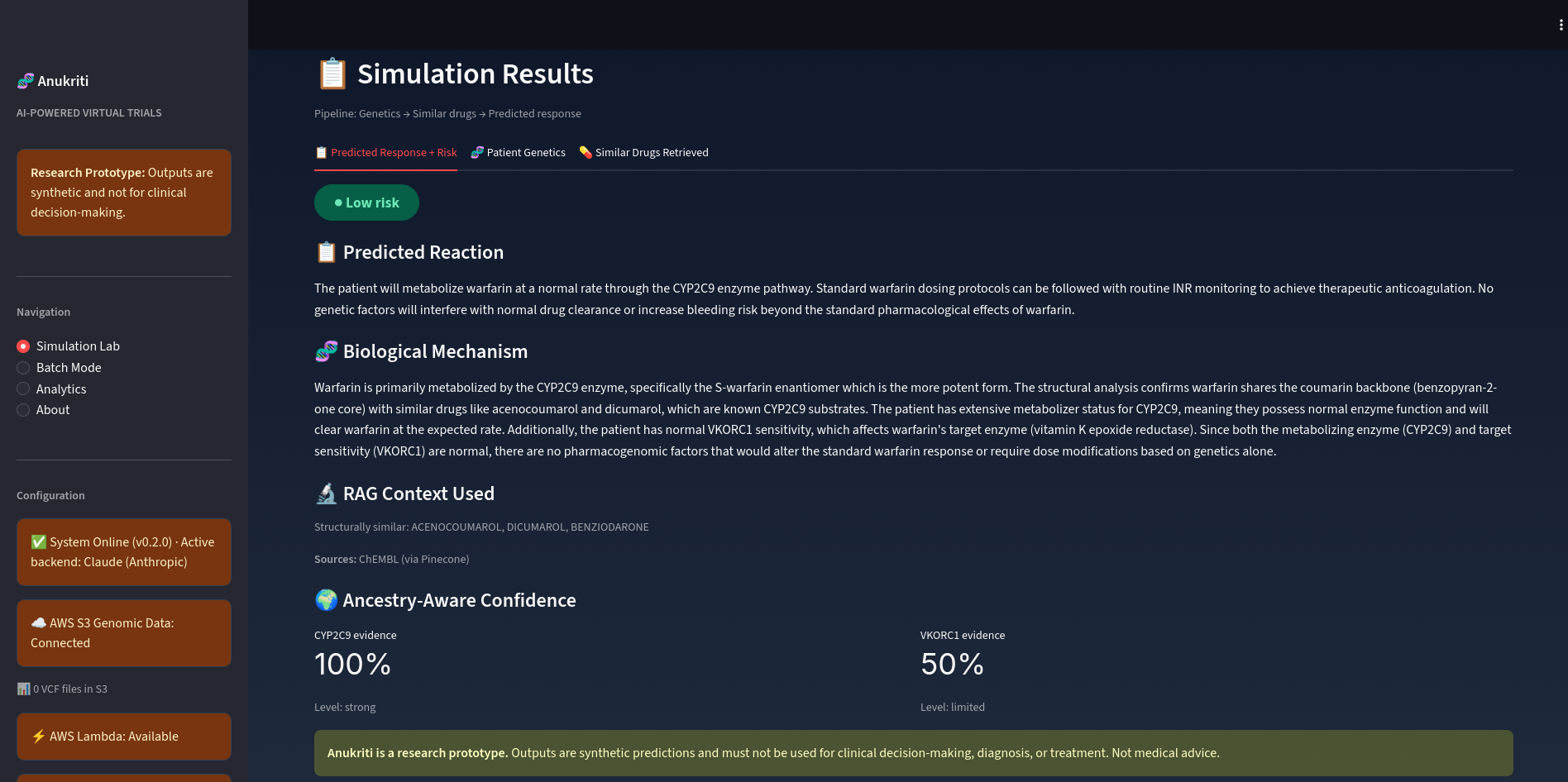
Result Screenshot
-
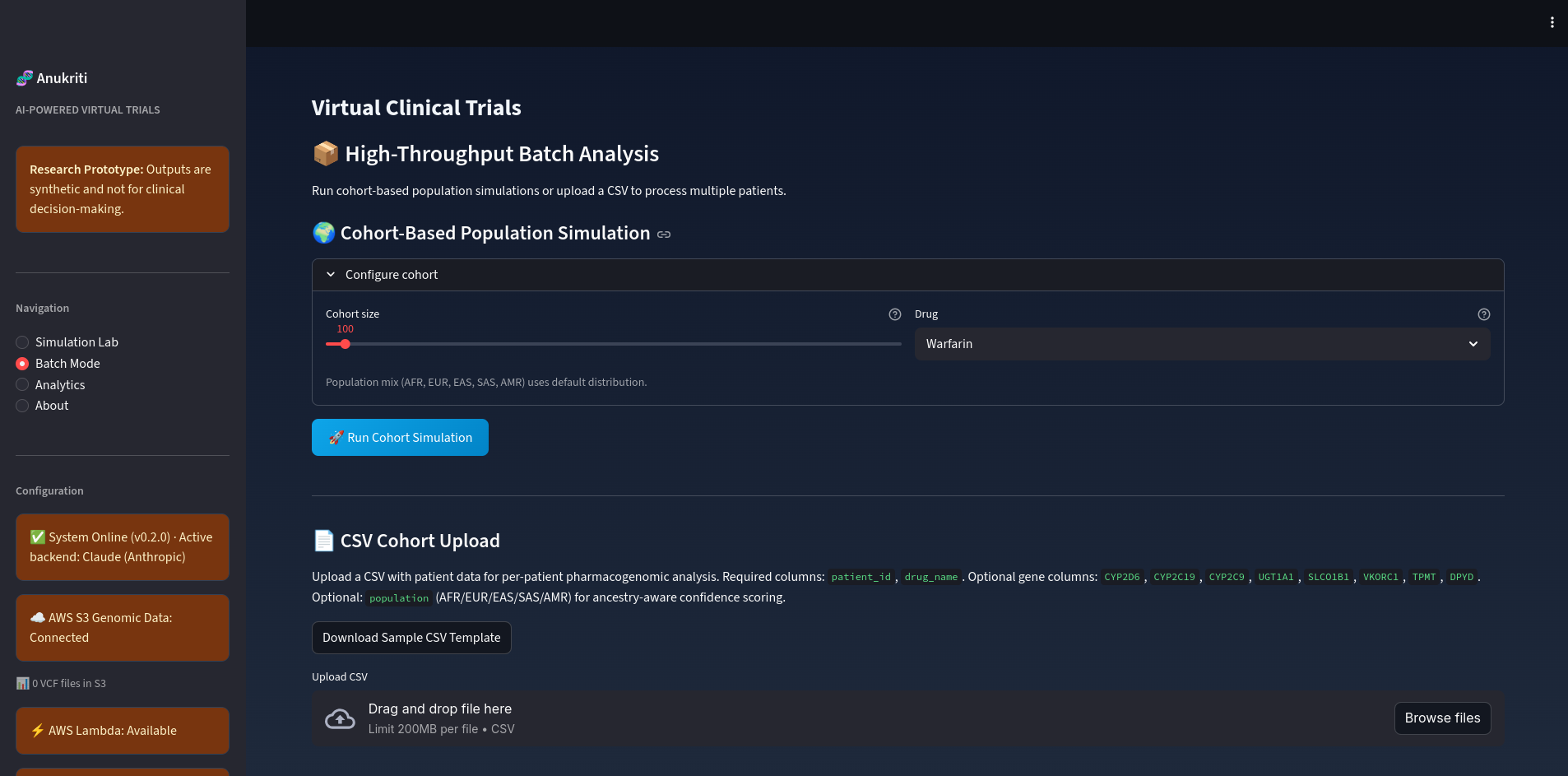
Batch Mode Screenshot
Inspiration
Modern drug development faces a major challenge: the same medicine can produce very different effects across individuals due to genetic differences. Many drugs fail late in clinical trials because these variations are discovered only after expensive testing.
We were inspired by the idea that AI could help researchers explore these differences earlier. If we could simulate how drugs interact with genetically diverse populations before trials begin, researchers could detect risks sooner and design safer and more inclusive treatments.
This led to Anukriti, an AI-powered system that explores pharmacogenomic variations and simulates possible drug responses across different genetic profiles.
What it does
Anukriti is an AI-driven research assistant that helps explore how genetic differences may influence drug responses across populations.
The system allows users to input information such as:
- Drug name
- Genetic variants (e.g., CYP450 genes)
- Population characteristics
Using AI reasoning and pharmacogenomic knowledge, Anukriti generates insights about:
- Potential metabolic differences
- Population-specific drug sensitivity
- Possible adverse reactions
- Variations in therapeutic effectiveness
Conceptually, the system explores relationships like:
$$ Drug\ Response = f(Genetics, Metabolism, Dosage, Population) $$
By simulating these interactions, Anukriti helps researchers think about potential risks before clinical trials begin.
How we built it
Anukriti combines AI reasoning with biological data interpretation to simulate drug response insights.
The system architecture includes:
Frontend
- Interactive interface for entering drug and genetic information
Backend
- Python-based analysis layer
- Data processing for pharmacogenomic relationships
AI Layer
- Gemini models used to reason over drug–gene relationships
- AI-generated explanations and risk insights
Knowledge Sources
- Public pharmacogenomic datasets
- Scientific literature
- curated gene–drug interaction information
The overall workflow:
- User inputs drug and genetic context
- Backend structures the pharmacogenomic data
- Gemini processes the information
- The system generates reasoning-based simulation insights
Challenges we ran into
Building a system that connects AI reasoning with biological concepts came with several challenges.
Data complexity
Pharmacogenomics involves many interacting variables including enzymes, metabolic pathways, and population genetics. Structuring this information in a usable format required careful design.
Scientific interpretation
AI can generate insights, but those insights must remain scientifically grounded. Ensuring that outputs were meaningful rather than speculative required prompt design and validation.
Model reasoning limits
While LLMs are strong at reasoning, translating biological relationships into structured simulations required multiple iterations and experiments.
Accomplishments that we're proud of
- Designing an AI system capable of reasoning about pharmacogenomic relationships
- Building a working prototype that connects drug data, genetic context, and AI analysis
- Demonstrating how AI could assist early exploration of drug response diversity
- Creating a foundation for future research tools in computational pharmacology
Most importantly, we proved that AI can help researchers explore population-level drug response questions in an interactive way.
What we learned
Working on Anukriti taught us several important lessons.
AI can act as a research collaborator
Large language models are capable of assisting in scientific exploration when guided with structured prompts and contextual data.
Biology is deeply interconnected
Drug responses are influenced by multiple genetic and metabolic factors, making simulation-based exploration a promising approach.
AI tools can accelerate early-stage research
While not a replacement for laboratory experiments, AI systems can help researchers generate hypotheses faster.
What's next for Anukriti
The current prototype demonstrates the concept of AI-assisted pharmacogenomic exploration. The next steps include:
- Expanding integration with genomic datasets
- Improving drug–gene interaction modeling
- Building population-scale simulation capabilities
- Developing an interactive research dashboard
- Enabling researchers to test multiple drug scenarios simultaneously
Our long-term vision is to create a virtual population simulator for drug development, helping researchers explore treatment safety across diverse genetic groups before clinical trials begin.
Built With
- fastapi
- gemini-api
- google-ai-studio
- javascript
- pharmacogenomic-datasets
- python
- react
- rest-apis

Log in or sign up for Devpost to join the conversation.