-
-
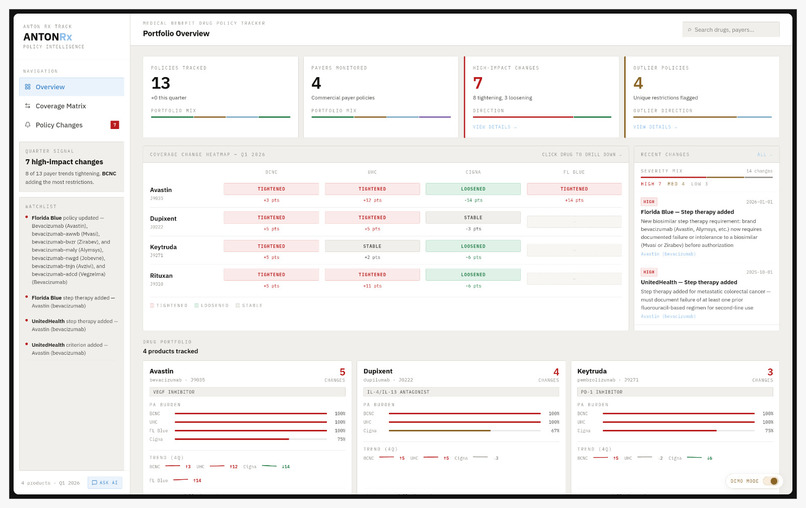
Dashboard | Portfolio View
-

Thumbnail Image
-
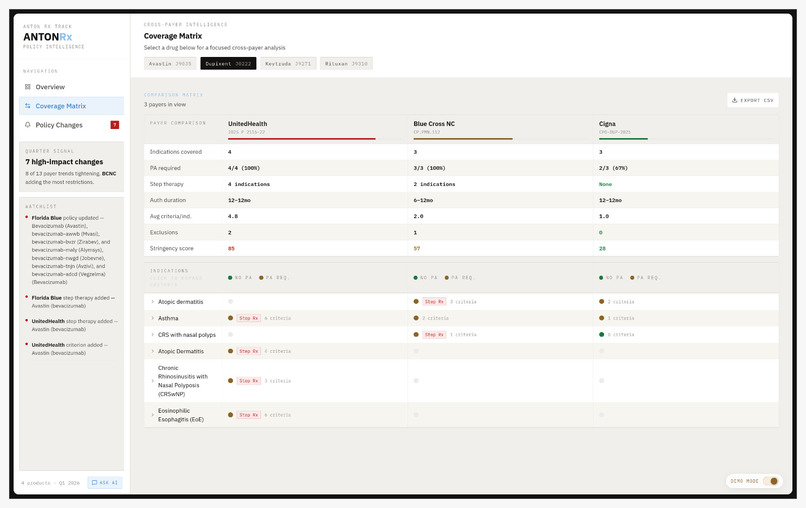
Drug Detail View
-
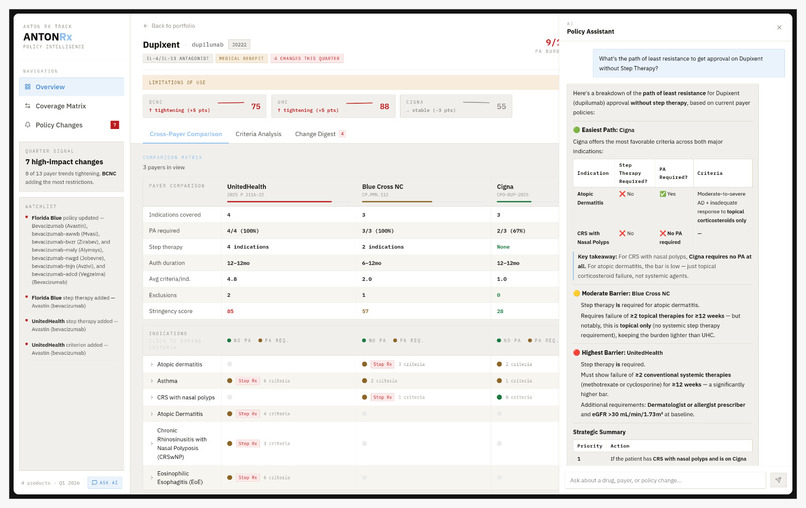
Dashboard Intelligence | Chatbot
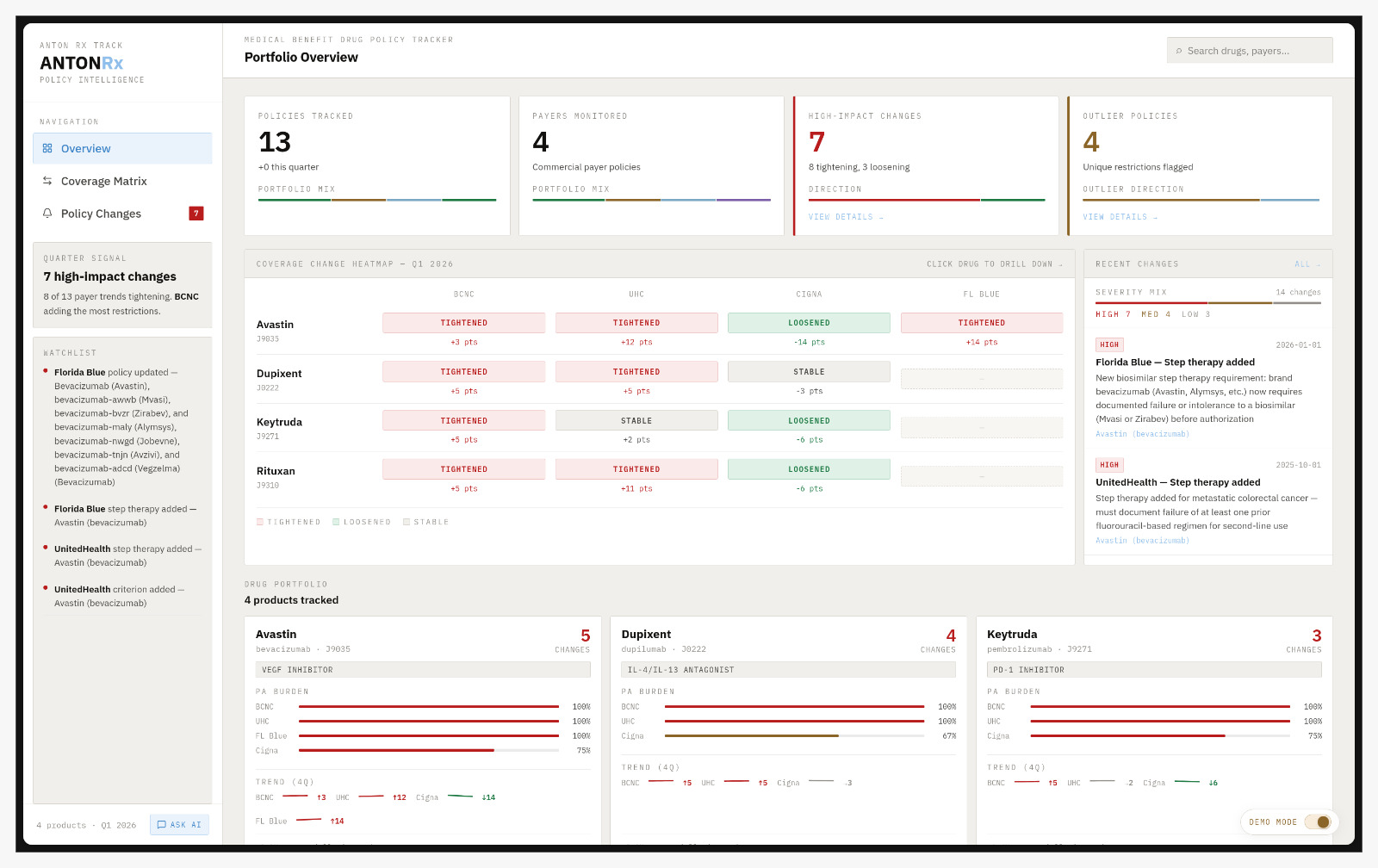

Inspiration
Medical benefit drugs, the kind injected or infused in a clinic, are governed by individual coverage policies published separately by each insurer. There is no standard format, no central database, and no easy way to compare them. Analysts at firms like Anton Rx spend hours reading PDFs one by one, manually extracting criteria, and trying to keep up with quarterly changes.
We saw a clear problem that AI is perfectly suited to solve.
What it does
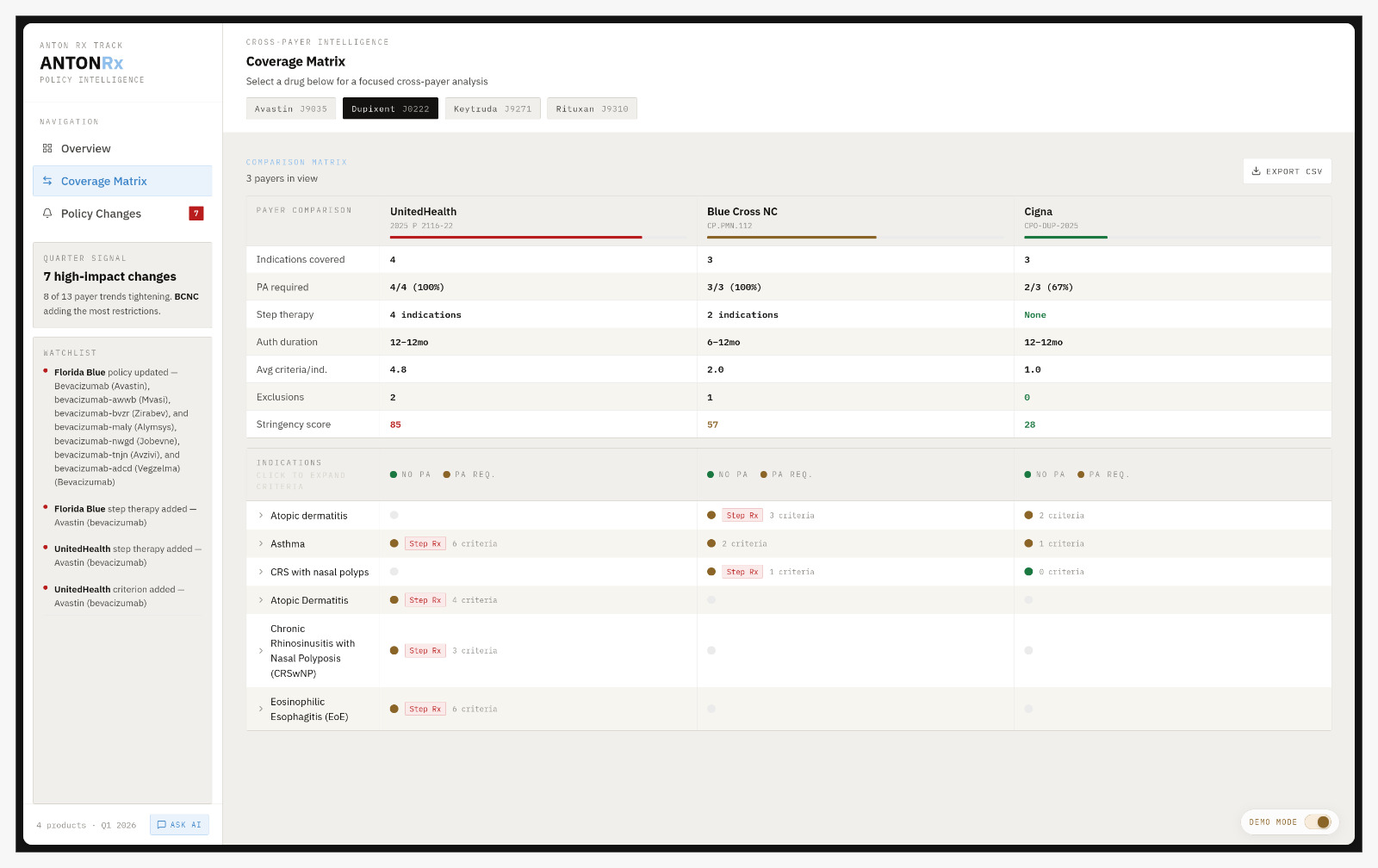
AntonIQ is an AI-powered medical policy intelligence platform. It ingests PDF and DOCX policy documents from any payer and extracts structured coverage data, including indications, prior authorization criteria, step therapy requirements, HCPCS codes, and effective dates. It then normalizes everything into a single comparable format.
Users can search across payers, compare coverage criteria side by side, and get alerted when a policy changes between versions.
How we built it
Ingestion: PDFs land in S3 via upload or crawler. A SHA-256 hash on every document prevents redundant reprocessing. The same (payer, policy_id) combination that produces a new hash creates a new version record rather than overwriting; old versions are never deleted. The pipeline orchestrator runs as a background FastAPI task, scanning S3, extracting, writing to MongoDB, and triggering change detection.
Extraction: PyMuPDF is the primary parser, with pdfplumber as a fallback on low text-yield pages and Camelot for table extraction. The segmentation pipeline uses only layout signals to detect headings and isolate the PA criteria section: font size relative to the page median, boldness, x-position indentation bucketing, and block text length. No content regex, so it generalizes across payer formats. Python hands the LLM a focused section, not a 28-page document. Claude Sonnet 4.6 runs through Instructor to enforce a typed PolicyRecord Pydantic schema, catching malformed outputs before they reach the database.
Normalization: After extraction, drug names resolve to RxNorm CUIs via the public API, billing codes canonicalize to HCPCS, and diagnoses validate against ICD-10. Cross-payer queries join on (rxcui, icd10_codes), not on whatever string the payer happened to use.
Diff engine: A structured diff runs against the prior version of every policy on ingestion, comparing field by field, detecting new indications, removed criteria, changed thresholds, and added step therapy requirements, then logging each change with a HIGH/MED/LOW severity score. The change digest feed is the homepage of the frontend; every entry includes the specific field that changed, the before and after values, and a link to the source document.
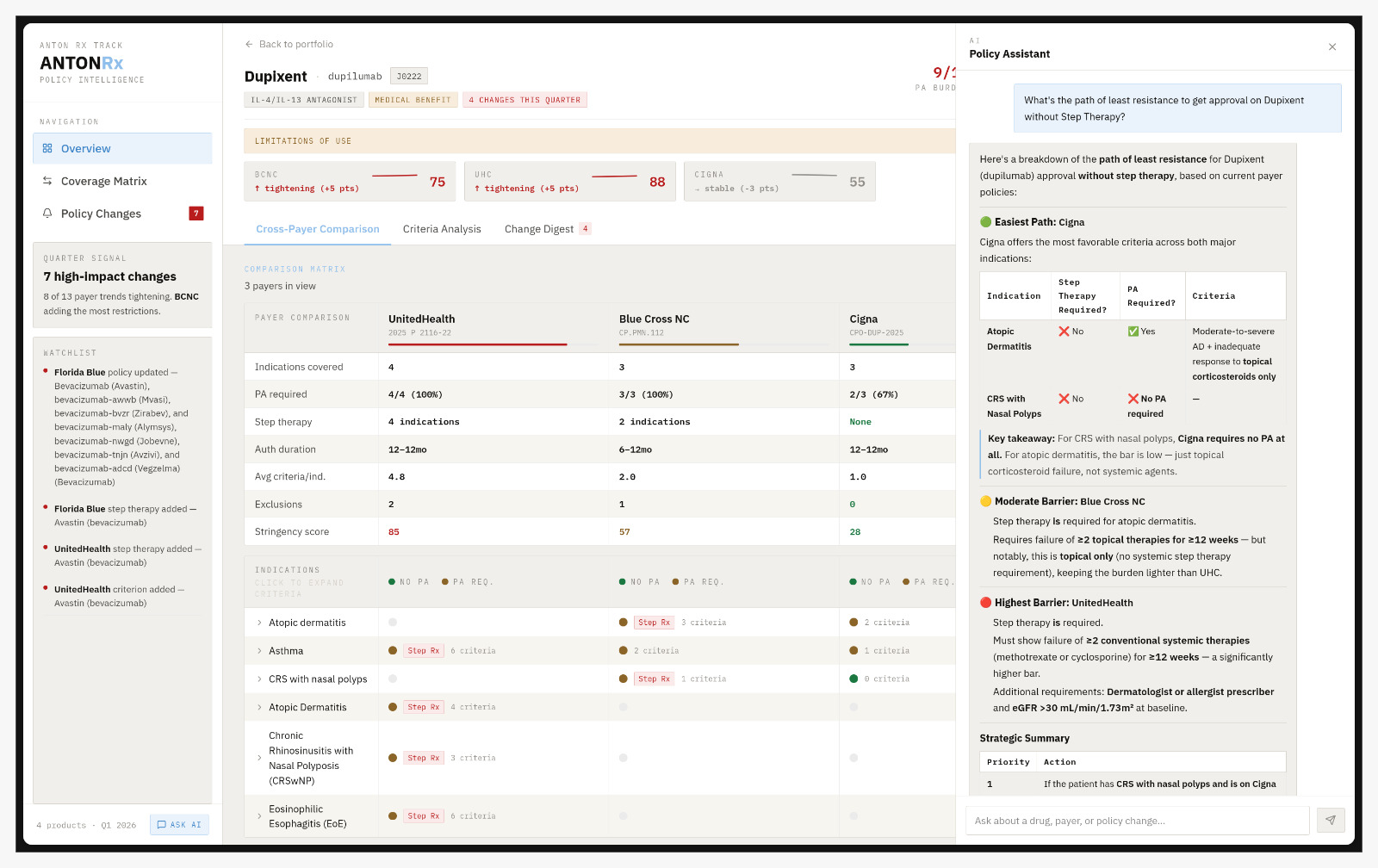
Chat: POST /v1/chat runs a 3-iteration agentic loop with three tools backed by live MongoDB: search_drug_policy, get_policy_changes, and compare_payers. Drug names in queries resolve brand to generic via RxNorm before any lookup. Every response includes SourceRef provenance objects — the policy ID, section, and a presigned S3 link to the source PDF — rendered as clickable chips in the UI. A separate endpoint generates structured insight cards for each drug: Claude is forced via tool-use to emit exactly 2–3 cards (the schema hard-caps at 3 to prevent padding).
Stack: FastAPI + Python backend, MongoDB Atlas for normalized records, AWS S3 for raw PDF versioning, React 19 + Vite + TypeScript + Tailwind v4 + shadcn for the frontend, Docker Compose orchestration, deployed on Render
Challenges we ran into
Ingestion: PDFs land in S3 via upload or crawler. A SHA-256 hash on every document prevents redundant reprocessing. The same (payer, policy_id) combination that produces a new hash creates a new version record rather than overwriting; old versions are never deleted. The pipeline orchestrator runs as a background FastAPI task, scanning S3, extracting, writing to MongoDB, and triggering change detection.
Extraction: PyMuPDF is the primary parser, with pdfplumber as a fallback on low text-yield pages and Camelot for table extraction. The segmentation pipeline uses only layout signals to detect headings and isolate the PA criteria section: font size relative to the page median, boldness, x-position indentation bucketing, and block text length. No content regex, so it generalizes across payer formats. Python hands the LLM a focused section, not a 28-page document. Claude Sonnet 4.6 runs through Instructor to enforce a typed PolicyRecord Pydantic schema, catching malformed outputs before they reach the database.
Normalization: After extraction, drug names resolve to RxNorm CUIs via the public API, billing codes canonicalize to HCPCS, and diagnoses validate against ICD-10. Cross-payer queries join on (rxcui, icd10_codes), not on whatever string the payer happened to use.
Diff engine: A structured diff runs against the prior version of every policy on ingestion, comparing field by field, detecting new indications, removed criteria, changed thresholds, and added step therapy requirements, then logging each change with a HIGH/MED/LOW severity score. The change digest feed is the homepage of the frontend; every entry includes the specific field that changed, the before and after values, and a link to the source document.
Chat: POST /v1/chat runs a 3-iteration agentic loop with three tools backed by live MongoDB: search_drug_policy, get_policy_changes, and compare_payers. Drug names in queries resolve brand to generic via RxNorm before any lookup. Every response includes SourceRef provenance objects — the policy ID, section, and a presigned S3 link to the source PDF — rendered as clickable chips in the UI. A separate endpoint generates structured insight cards for each drug: Claude is forced via tool-use to emit exactly 2–3 cards (the schema hard-caps at 3 to prevent padding).
Stack: FastAPI + Python backend, MongoDB Atlas for normalized records, AWS S3 for raw PDF versioning, React 19 + Vite + TypeScript + Tailwind v4 + shadcn for the frontend, Docker Compose orchestration, deployed on Render
Accomplishments that we're proud of
Ingestion: PDFs land in S3 via upload or crawler. A SHA-256 hash on every document prevents redundant reprocessing. The same (payer, policy_id) combination that produces a new hash creates a new version record rather than overwriting; old versions are never deleted. The pipeline orchestrator runs as a background FastAPI task, scanning S3, extracting, writing to MongoDB, and triggering change detection.
Extraction: PyMuPDF is the primary parser, with pdfplumber as a fallback on low text-yield pages and Camelot for table extraction. The segmentation pipeline uses only layout signals to detect headings and isolate the PA criteria section: font size relative to the page median, boldness, x-position indentation bucketing, and block text length. No content regex, so it generalizes across payer formats. Python hands the LLM a focused section, not a 28-page document. Claude Sonnet 4.6 runs through Instructor to enforce a typed PolicyRecord Pydantic schema, catching malformed outputs before they reach the database.
Normalization: After extraction, drug names resolve to RxNorm CUIs via the public API, billing codes canonicalize to HCPCS, and diagnoses validate against ICD-10. Cross-payer queries join on (rxcui, icd10_codes), not on whatever string the payer happened to use.
Diff engine: A structured diff runs against the prior version of every policy on ingestion, comparing field by field, detecting new indications, removed criteria, changed thresholds, and added step therapy requirements, then logging each change with a HIGH/MED/LOW severity score. The change digest feed is the homepage of the frontend; every entry includes the specific field that changed, the before and after values, and a link to the source document.
Chat: POST /v1/chat runs a 3-iteration agentic loop with three tools backed by live MongoDB: search_drug_policy, get_policy_changes, and compare_payers. Drug names in queries resolve brand to generic via RxNorm before any lookup. Every response includes SourceRef provenance objects — the policy ID, section, and a presigned S3 link to the source PDF — rendered as clickable chips in the UI. A separate endpoint generates structured insight cards for each drug: Claude is forced via tool-use to emit exactly 2–3 cards (the schema hard-caps at 3 to prevent padding).
Stack: FastAPI + Python backend, MongoDB Atlas for normalized records, AWS S3 for raw PDF versioning, React 19 + Vite + TypeScript + Tailwind v4 + shadcn for the frontend, Docker Compose orchestration, deployed on Render
What we learned
- Structured output with instructor is far more reliable than prompt-only JSON extraction. Enforcing a Pydantic schema catches malformed responses before they reach the database.
- Document structure matters as much as content. Poor segmentation upstream degrades LLM extraction quality downstream regardless of model capability.
- Model confidence scores are not inherently reliable. Outputs can show high confidence while still containing null fields or duplicated data.
- Healthcare terminology is highly variable. The same concept can have multiple names depending on the payer.
What's next for AntonIQ
- Automated policy monitoring: Build crawlers that detect new or updated policies and trigger re-extraction automatically
- Deduplication and merge: Improve post-processing to consolidate duplicate indications from multi-chunk extraction
- Expanded payer coverage: Scale from 7 payers to the top 20 commercial payers in the US
- Alert subscriptions: Allow users to subscribe to specific drugs or payers and receive notifications when policies change
The system is built around a document ingestion model because that's what currently exists. CMS-0057-F, which takes effect in 2026–2027, requires payers to expose FHIR-based Prior Authorization APIs. When that happens, the ingestion layer switches to API calls. The extraction pipeline, schema, diff engine, and UI are unchanged; they operate on PolicyRecord objects, not on PDFs. Building around structured records rather than documents means the pipeline survives the format change.
Built With
- amazon-web-services
- claude
- docker
- fastapi
- mongodb
- pdfplumber
- pymupdf
- python
- react
- render
- s3
- tailwind
- typescript
- vite

Log in or sign up for Devpost to join the conversation.