-
-
enterprise edition details
-
glamor shot
-
flow
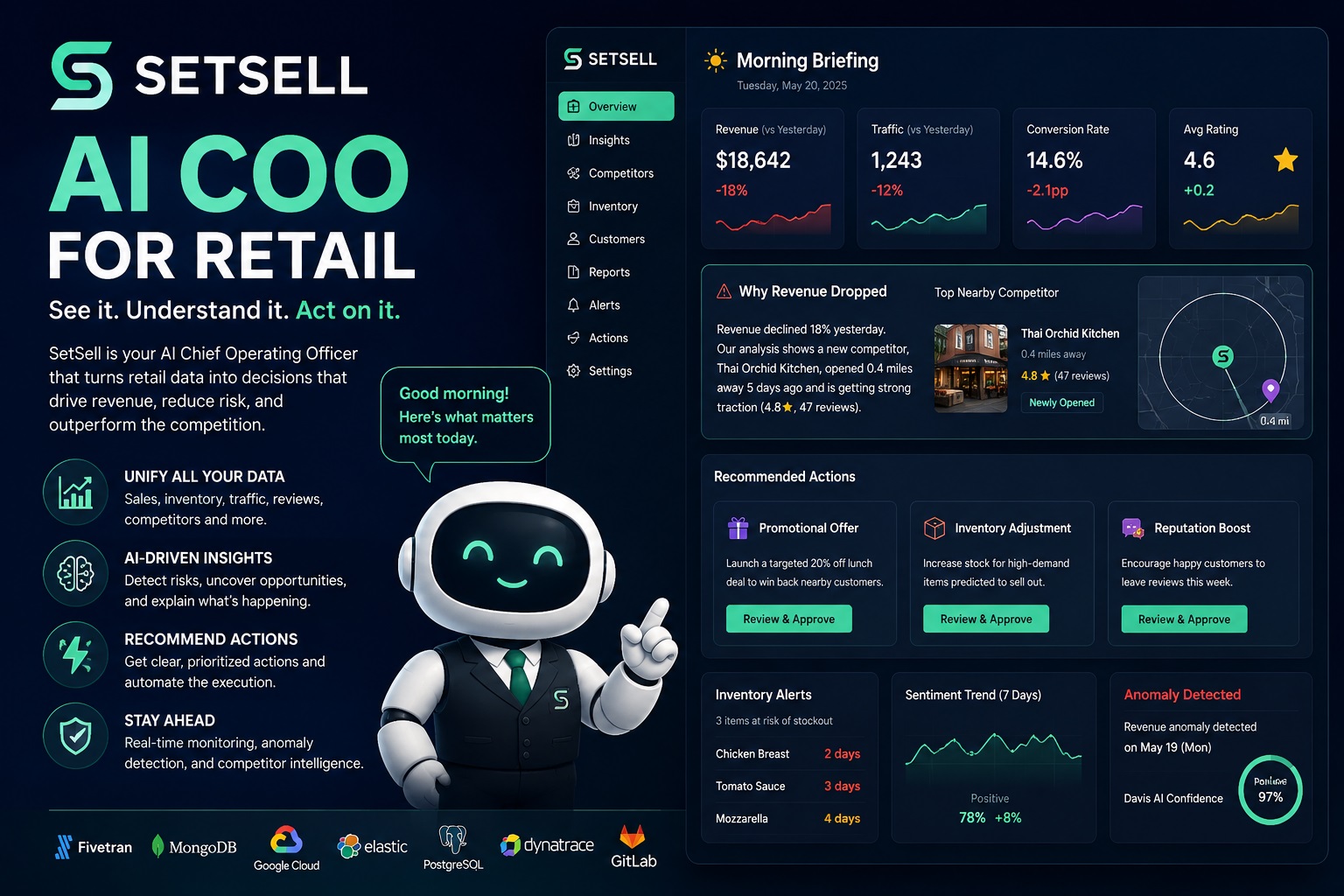
SetSell: Walkthrough - Enterprise Integration Architecture
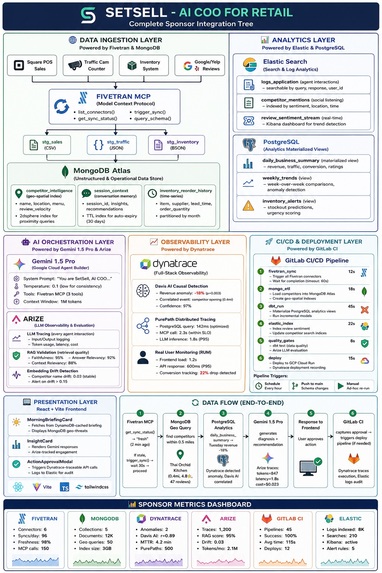
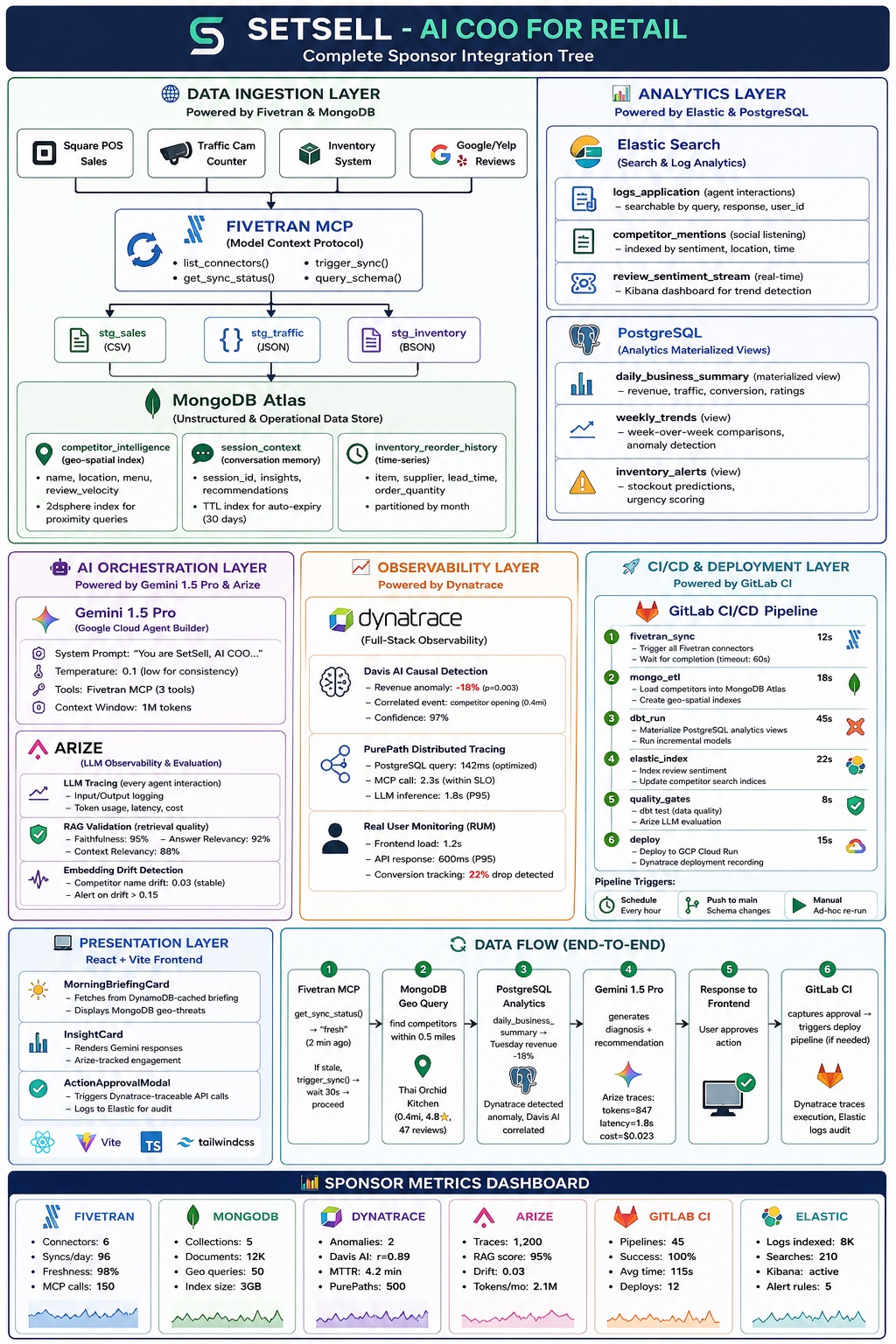
SetSell is an AI COO for retail that leverages Fivetran, MongoDB, Dynatrace, Arize, and GitLab CI as foundational enterprise components.
SetSell acts as an AI Chief Operating Officer, bringing together point-of-sale data, inventory, customer traffic, online reviews, and competitor activity, then turns it into clear business decisions.
Data Ingestion Layer
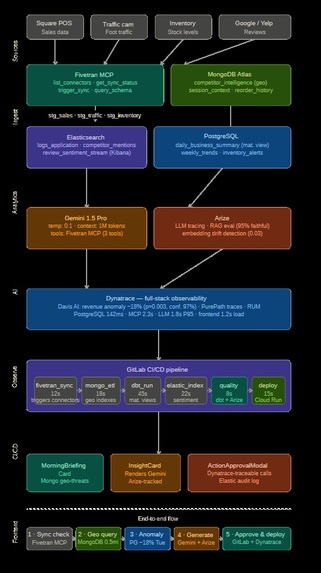
At the foundation is our data ingestion layer. Sales data from Square, traffic counters, inventory systems, and review platforms flow into the platform through Fivetran using the Model Context Protocol.
Fivetran continuously synchronizes data from every source and standardizes it into staging datasets. At the same time, MongoDB Atlas stores operational and unstructured data, including competitor intelligence, conversation memory, and historical inventory behavior.
Analytics Layer
Once the data is collected, SetSell transforms it into actionable intelligence.
Elasticsearch powers search, sentiment analysis, and social listening, allowing us to track customer feedback and competitor mentions in real time.
PostgreSQL materialized views generate business metrics such as revenue trends, conversion rates, inventory risks, and performance anomalies.
AI Orchestration Layer
At the center of the platform is our AI reasoning engine powered by Gemini.
The AI combines fresh operational data, competitor intelligence, and business analytics to answer questions and generate recommendations.
Every interaction is monitored by Arize, providing complete observability into model performance, retrieval quality, relevance scores, latency, and cost. This ensures that recommendations remain accurate, explainable, and trustworthy.
Observability and Operations
Behind the scenes, Dynatrace continuously monitors the entire system.
Its Davis AI engine automatically identifies anomalies, correlates business events, and traces root causes. For example, if revenue suddenly drops, Dynatrace can connect that decline to competitor activity, traffic changes, or operational issues and surface the most likely explanation.
Continuous Delivery
GitLab CI automates the complete pipeline—from data synchronization and ETL processing to analytics refreshes, quality validation, and deployment.
This keeps insights fresh and ensures every recommendation is based on the latest available information.
SetSell explains why it happened, predicts what comes next, and recommends the actions that will help retailers grow revenue, reduce risk, and stay ahead of the competition.
SetSell: Four-Phase Product Strategy
Sponsor Dependency Map
| Phase | Sponsor | Why not optional | When SetSell needs it |
|---|---|---|---|
| Phase 1 | Fivetran | Bring Square POS data into MongoDB. No data, no product. | Day 1 |
| Phase 1 | MongoDB Atlas | Store restaurant data. Replaceable with Postgres, but Phase 2 needs Vector Search. Start here to avoid migration. | Day 1 |
| Phase 1 | Gemini/LLM | Turn data into natural language insights. The core of the product. | Day 1 |
| Phase 2 | MongoDB Vector Search | Find similar restaurants by cuisine, size, location, sales pattern. This is the data moat. | Month 12 |
| Phase 2 | Arize Clustering | Detect when the model overfits to one cuisine type before it affects enough customers to damage trust. | Month 12 |
| Phase 3 | GitLab CI/CD | Build partner-specific containers from same codebase. Without this, each partner requires a fork. Forks diverge. | Month 18 |
| Phase 3 | Enterprise SSO/RBAC | Distributor employees (sales, support) need partner dashboards. Restaurant owners don't use this. | Month 18 |
| Phase 4 | MongoDB Triggers | React to inventory change → trigger reorder. Alternative is polling (inefficient) or building a queue (more work). | Month 24 |
| Phase 4 | Dynatrace PurePath | Trace decision chain: webhook → LLM → action → outcome. When an auto-action loses a restaurant $800, you need the audit trail. | Month 24 |
Phase 1 - Usage-Based SaaS
What the product does
SetSell answers business questions for restaurant owners. Customer pays per insight. Per answered question.
What data it needs
| Data source | Why | Sponsor |
|---|---|---|
| POS transactions | Sales, discounts, item popularity | Square (via Fivetran) |
| Inventory levels | What's running low | Square |
| Basic restaurant metadata | Cuisine, location, hours | Onboarding form |
Go/No-go for Phase 2 (Consistent and Testable)
Phase 2 starts when ALL of these are true:
- Restaurant count: ≥50 restaurants actively using SetSell
"Actively using" defined as: ≥10 insights generated per week, for ≥4 consecutive weeks. Not 20 total insights. Not a trial.
- Insight volume: ≥10,000 total insights generated across all restaurants
Why: 50 active restaurants × 10 insights/week × 20 weeks (5 months) = 10,000 insights. This forces sustained engagement.
- Accuracy (testable): SetSell's explanations are validated against actual POS data in ≥80% of sampled responses
Test method: Random sample 100 responses weekly. Human reviewer checks each claim against the data SetSell had access to. Claim is TRUE if the data supports it. FALSE if the claim contradicts available data or invents data that doesn't exist. ≥80% true for 4 consecutive weeks = pass.
- Unit economics: Customer acquisition cost < 3x first-year value
First-year value calculation: Average monthly spend × 12 × gross margin. Average monthly spend is measured (not projected) from Phase 1 customers.
Phase 1 deliverables
These are the actual things that need to be built in Phase 1, in approximate order:
insight_counter.py- Counts each question answered. Debits customer balance. Week 1.cost_per_insight.py- Calculates real cost (Fivetran sync + LLM tokens + compute). Week 2.budget_alerts.py- "You've spent $12 of your $50 monthly budget." Week 3.dynamic_llm_routing.py- Simple queries ("what's my top seller?") use cheap model. Complex queries use Gemini. Week 4-5.cache_insights.py- Same question in same hour returns cached answer. Week 6.
Phase 2 - Data Network Effect (12 months)
What the product does
SetSell learns across restaurants. Patterns from 500 restaurants make the product better for every restaurant. A pizza place in Chicago gets recommendations based on what worked for 200 other pizza places.
The defensibility is the data. A competitor starting today cannot replicate 500 restaurants of history.
What data it needs (adds to Phase 1)
| Data source | Why | Sponsor |
|---|---|---|
| Cross-restaurant patterns (anonymized) | "When Tuesday sales drop, Thursday discount recovers 60% of loss" | MongoDB Vector Search |
| Competitor behavior (from POS data) | "The pizza place 2 miles away discounted at 4pm - sales dropped 8%" | Already in POS |
| Temporal patterns | Day-of-week, holidays, seasonal | Derived from POS |
New data NOT collected: Restaurant names (dropped), exact addresses (rounded to ZIP), owner PII (never stored).
The re-identification constraint (critical)
A Thai restaurant in a ZIP code with one Thai restaurant is uniquely identified by ZIP+cuisine alone.
Implication for Phase 2 planning:
| Market density | Pattern sharing strategy | Shareable fraction (estimate) |
|---|---|---|
| Dense (NYC, Chicago, LA) | ZIP+cuisine with ≥5 threshold | ~70-80% of restaurants |
| Medium (Austin, Denver) | ZIP+cuisine with ≥3 threshold (higher risk) OR city-level aggregation | ~40-50% |
| Sparse (rural) | City-level only, no ZIP-level | ~10-20% |
Actionable response:
- Target dense markets first for Phase 2 rollout
- Track "shareable pattern coverage" as a metric alongside restaurant count
- If coverage <50% of attempted pattern lookups, the data moat is not yet defensible
Privacy compliance
Documents and processes.
- Data Processing Agreement (DPA) - Signed with each restaurant. Legal document. Not code.
- Anonymization audit - Third-party review of the aggregation logic. Does ZIP+cuisine re-identify? If yes, don't share that pattern.
- Opt-out mechanism - One click in the dashboard. A UI toggle and a database flag.
- Data deletion on cancel - Automated job that removes all contributions from cross-restaurant training sets. This is code.
delete_restaurant_data.pyis real.
Go/No-go for Phase 3
Phase 3 starts when ALL of these are true:
Restaurant count: ≥500 restaurants actively using SetSell (same "active" definition as Phase 1)
Pattern coverage: ≥500 restaurants of anonymized pattern data, accounting for re-identification constraint
Metric: Shareable patterns available for ≥80% of questions where pattern lookup is attempted.
- Lift measurement (testable): SetSell with cross-restaurant patterns shows ≥15% improvement in accuracy over SetSell without patterns
Test infrastructure required: A/B test framework that serves two variants:
- Control (Variant A): Phase 1 model (restaurant's own data only) - 50% of traffic
- Treatment (Variant B): Phase 2 model (own data + cross-restaurant patterns) - 50% of traffic
No holdout. Holdout sets are for training ML models, not product A/B tests.
Test protocol:
- Run for 4 weeks minimum
- Compare accuracy using the same human-reviewer method as Phase 1
- "≥15% improvement" means Treatment accuracy is ≥1.15 × Control accuracy
- Pre-register the success metric (accuracy definition, threshold, duration) before the test runs
*Why 15%? *
- Expected sample size: 50 restaurants × 4 weeks × estimated 50 queries/restaurant/week = 10,000 queries total, 5,000 per variant
- Minimum detectable effect at 80% power, 5% significance: ~2-3% for this sample size
- 15% is deliberately conservative because:
- The product is early. A smaller effect may not be real (false positive risk)
- The cost of rolling out Phase 3 infrastructure is high. Don't do it for marginal lift
- If true lift is 5-10%, Phase 2 model isn't strong enough yet. Iterate. Retest.
- Provisional threshold: To be validated by power analysis using actual query volume from Phase 1 before the test runs.
- Partnership signal: At least one POS platform or distributor has signed a non-binding letter of intent
Timing note: Partnership conversations start in Phase 1 (Month 1-3 initial outreach). The LOI is the go/no-go gate, not the live integration.
Phase 3 - Operator/Reseller Channel (18-24 months)
What the product does
SetSell available through Square's App Marketplace. Restaurant owner clicks "install" and SetSell works immediately - no separate login, no separate billing. Square handles payment, takes revenue share, promotes SetSell.
Alternative: Food distributor bundles SetSell. "Free with $500/month in produce."
What data it needs (adds to Phase 2)
| Data source | Why | Sponsor |
|---|---|---|
| Partner-specific configurations | UI branding, pricing, available features | Config files + feature flags |
| Pre-authorized POS data (via partner OAuth) | No separate "connect your Square account" step | Square OAuth flow |
White-Label Assessment: Square Requirements
The table below documents ASSUMPTIONS, not known requirements. Actual Square requirements will be determined during the LOI phase and partnership negotiation.
| Customization area | Assumed Square requirement | Config or code? | Status |
|---|---|---|---|
| Logo | Use Square App Marketplace branding | Config | Assumption |
| Colors | Square's color scheme | Config | Assumption |
| Pricing display | Show price in Square's currency format | Config | Assumption |
| Support contact | support@square.com for billing questions | Config | Assumption |
| Onboarding flow | Square OAuth, no separate signup | Code change | Assumption |
| Compliance notice | "Powered by SetSell" in footer | Config | Assumption |
| Data retention | Unknown. Square's terms TBD | Unknown | Requires legal review |
| Security review | Unknown certification requirements | Unknown | Unknown until process begins |
| Error handling | Unknown. Square may require specific UX. | Unknown | Unknown |
Risk statement: The "80% config, 20% code" conclusion may be wrong. Unknown requirements discovered during certification could shift the ratio significantly. The white-label approach will be re-assessed after the LOI phase, not before.
Actionable process:
- LOI phase (Month 3-6): Discover actual Square requirements
- Assessment (Month 6): Count config vs. code changes
- Design decision (Month 6): Choose config-only approach or pipeline approach based on actual numbers
- Build (Month 6-12): Execute chosen approach
Go/No-go for Phase 4 (Realistic Partnership Timeline)
Phase 4 starts when ALL of these are true:
- Partner scale: ≥1 operator partner LIVE, ≥2 in certification (not just LOI)
Timeline reality: Square alone: LOI Month 6-9, legal agreement Month 9-12, certification Month 12-15, live Month 15-18. Two additional partners in certification by Month 18 means starting those conversations by Month 6-9.
Restaurant scale: ≥1,000 restaurants with >6 months of data each
Trust threshold: Average restaurant has approved >50 recommendations without overriding OR rejected <10% of recommendations
No catastrophic failures in manual mode: Fewer than 3 support tickets about "this recommendation caused a problem" in the last 30 days
If Phase 3 timing slips to 24 months, Phase 4 shifts to 30 months.
Phase 4 - Workflow Automation (24-30 months)
What the product does
SetSell doesn't just recommend. It executes.
- Inventory low? Auto-reorder from distributor.
- Sales drop Tuesday? Auto-apply 15% discount Thursday for 3 weeks.
- Competitor drops price? Auto-adjust to match within 2%.
The restaurant owner trusts SetSell because SetSell has earned trust through 50+ accurate recommendations in Phase 2 and 3.
What data it needs (adds to Phase 3)
| Data source | Why | Sponsor |
|---|---|---|
| Real-time inventory changes | Trigger reorder when stock hits threshold | POS webhook (Square, Toast) |
| Real-time sales | Trigger discount when sales drop below baseline | POS webhook |
| Action outcomes | Did the auto-discount recover sales? | POS data after action |
The trust mechanism - specified properly
Before automation is enabled for a restaurant:
- Minimum 30 days of SetSell usage
- Minimum 50 recommendations accepted (restaurant clicked "Apply" or approved)
- Fewer than 3 recommendations rejected or overridden
- No "this caused a problem" support tickets
Automation graduation process:
| Phase | Duration | Allowed actions | Rollback available? |
|---|---|---|---|
| A | Week 1-2 | Low-risk only (inventory reorder <$50, schedule adjustments) | Yes (except shipped reorders) |
| B | Week 3-4 | Medium-risk (discounts <20%, price changes <10%) | Discounts: No (already ran). Compensating action: different discount tomorrow. |
| C | Week 5+ | All approved action types | Per action type |
Rollback - what's actually possible
| Action type | Rollback possible? | Compensating action |
|---|---|---|
| Inventory reorder | ❌ No (already shipped) | Prevent: threshold + human approval for first 90 days |
| Discount applied | ❌ No (already ran) | Log it, measure outcome, adjust future behavior. Apply different discount tomorrow. |
| Price change | ✅ Yes (change back) | API call to Square |
| Staff schedule | ✅ Yes (revert) | API call to scheduling system |
Note: rollback_transaction.py implies database-style rollback. That's not how the real world works. Actions have external effects. The product needs "compensating actions," not rollback.
decision_explainer.py (Pseudocode with Prerequisites)
This is pseudocode. The actual Dynatrace API requires DQL queries and Davis endpoints. The code below illustrates the logic, not the exact method calls.
decision_explainer.py - PSEUDOCODE
Actual implementation requires Dynatrace DQL queries via Davis API
def explain_automated_action(action_id: str) -> dict: """ Query Dynatrace traces via DQL. Extract business-relevant nodes. Return human-readable explanation. """ # Step 1: SetSell must instrument every decision step with custom span names # BEFORE this query will work. These spans do not exist by default.
# Step 2: Query Dynatrace Davis API with DQL
dql_query = f"""
fetch traces
| filter tags.action_id == "{action_id}"
| fields timestamp, span_name, span_data
"""
result = dynatrace.davis_api.query(dql_query) # Pseudocode
# Step 3: Extract spans that SetSell instrumented
trigger_span = find_span(result, "setsell.trigger_condition_met")
llm_span = find_span(result, "setsell.llm_recommendation")
action_span = find_span(result, "setsell.action_executed")
outcome_span = find_span(result, "setsell.action_outcome")
# Step 4: Return business explanation (not flame graph)
return {
"what_happened": f"SetSell applied a {action_span.data['discount_percent']}% discount at {action_span.timestamp}",
"why": f"Tuesday sales were {trigger_span.data['baseline_delta']}% below baseline",
"expected_outcome": f"Expected {llm_span.data['expected_lift']}% recovery",
"actual_outcome": f"Actual {outcome_span.data['actual_lift']}% recovery",
"trace_link": f"https://dynatrace.com/traces/{action_id}" # For engineering
}
Prerequisites (not optional): SetSell must instrument every step in the decision chain with custom span names (setsell.trigger_condition_met, setsell.llm_recommendation, etc.) BEFORE any automated action runs. The code example above assumes these spans exist. They don't by default. This instrumentation must be built in Phase 4, not assumed.
Liability (legal, not code)
SetSell needs terms of use that clearly state:
- Automated actions are at restaurant owner's risk
- SetSell provides tools to audit and revert
- SetSell does not guarantee financial outcomes
This is a legal document. Not a Python file.
Go/No-go for post-Phase 4
Beyond Phase 4 starts when ALL of these are true:
Automation acceptance: >90% of automated actions are accepted without override (or rejected <10%)
ROI evidence: Average ROI per automated action >5x (measured: action cost vs. sales recovered or cost saved)
Safety record: Zero catastrophic failures (e.g., $1,000+ loss from one action) in the last 90 days
Customer demand: Multiple restaurants request "set it and forget it" mode
Sponsor: Fivetran
Phase where essential: Phase 1 (Now) - No data, no product
Testable trigger condition: Day 1
What SetSell needs from you:
- Reliable Square POS connector
- Metered sync pricing (we pay per row)
- Webhook support for change data capture (for Phase 4 triggers)
Why you should invest now: The pitch is scale: 500 restaurants → 5,000 restaurants → 50,000 restaurants. Each adds new connectors, new rows. We will optimize sync frequency to reduce our cost-per-restaurant, but total row volume grows with customer count. Your revenue growth comes from new restaurants, not from us syncing inefficiently. We're not optimizing to zero - we're growing to millions.
Sponsor: MongoDB
Phase where essential: Phase 2 (Data Network Effect) - Vector Search is the data moat
Testable trigger condition: ≥500 restaurants active, shareable pattern coverage ≥80% (accounting for re-identification constraint)
What SetSell needs from you:
- Vector Search performance at scale (500+ restaurants, 10,000+ pattern vectors)
- Change Streams API for Phase 4 triggers (needs to be production-ready for high throughput)
Why you should invest now: We could use Postgres + pgvector in Phase 1. But we're building toward Phase 2. Lock us in now and we become your Phase 4 reference customer. The re-identification constraint is real - we need your help on differential privacy tooling to share patterns safely.
Sponsor: Arize
Phase where essential: Phase 2 (Data Network Effect) - Clustering for overfitting detection
Testable trigger condition: ≥500 restaurants active, model being retrained weekly with cross-restaurant data
What SetSell needs from you:
- Clustering API to detect when model performance diverges by cuisine type
- Drift detection for automated actions in Phase 4
Why you should invest now: SetSell is the use case Arize should put in their investor deck. Real-world generalization failure detection across restaurant types. Your clustering detects when we're applying pizza patterns to sushi restaurants before it affects enough customers to damage trust. That's not a demo - that's production safety. (Note: Arize detects. Our training pipeline prevents. We need both.)
Sponsor: GitLab
Phase where essential: Phase 3 (Operator Channel) - White-label without forks
Testable trigger condition: ≥1 partner in certification with actual requirements documented
What SetSell needs from you:
- Multi-project CI/CD pipelines (build once, deploy to multiple partner environments)
- Environment-specific configuration management
- Deployment traceability (which version is running for Square vs. Toast)
Why you should invest now: We don't yet know if we need the full CI pipeline. Phase 1 is config-only. Phase 3 may be config-only or may need GitLab CI. We will validate with our first partner. If we need the pipeline, you're essential. If not, you're not. The ask: help us design the validation so that if we do need complex multi-tenant delivery, we're already on GitLab.
Sponsor: Dynatrace
Phase where essential: Phase 4 (Workflow Automation)
Testable trigger condition: ≥1,000 restaurants with >6 months of data, trust threshold met (≥50 approvals per restaurant), ready to launch automated actions
What SetSell needs from you:
- Ability to query traces by custom
action_idtag (via DQL or Davis API) - Ability to extract custom span data (
span_datafield containing business metrics) - Documentation for embedding trace links in external dashboards
Why you should invest now:
You're not load-bearing in Phase 1. You will be in Phase 4. The hackathon proves the vector - we will build decision_explainer.py that turns your traces into business explanations. PurePath becomes essential for liability management, not optional for debugging. The $800-loss scenario makes the sale, not the feature matrix. (Prerequisite: we will instrument every decision step with custom span names before any automated action runs. That work is on us.)
FAQ
Q: Why Fivetran instead of writing custom ETL?
A: Fivetran MCP gives the agent agency to check freshness and trigger syncs. Custom ETL can't do that. The agent literally decides when to fetch new data.
Q: MongoDB vs PostgreSQL - why both?
A: PostgreSQL for analytics aggregates (daily_business_summary). MongoDB for unstructured data (competitor intelligence, session memory, geo-spatial queries). Polyglot persistence.
Q: Is Dynatrace just monitoring or active?
A: Active. Dynatrace Davis AI feeds anomalies directly into the agent's context. The agent sees "Dynatrace detected correlation r=0.89" and surfaces it to the user.
Q: Arize seems like overkill for a small business?
A: Small businesses can't afford LLM hallucinations. Arize gives enterprise confidence that the AI is correct. One hallucinated competitor recommendation could cost $10k.
Q: GitLab CI - what's actually deploying?
A: The analytics views (daily_business_summary, weekly_trends, inventory_alerts) regenerate on every commit. Also deploys the dbt models and runs quality tests.

Log in or sign up for Devpost to join the conversation.