Inspiration
Nearly 40% of stroke survivors suffer from Anomic Aphasia—a condition where the "bridge" between a thought and a word is broken. These individuals have full language comprehension, yet they are trapped by the "tip-of-the-tongue" phenomenon which is frustrating and isolating for patients. Therapy is essential in recovery but relies on archaic picture boards and manual pointing, presenting a perfect opportunity for innovation. We were inspired to use AI to rebuild that bridge, turn daily struggles into clinical insights, and restore dignity to conversation.
What it does
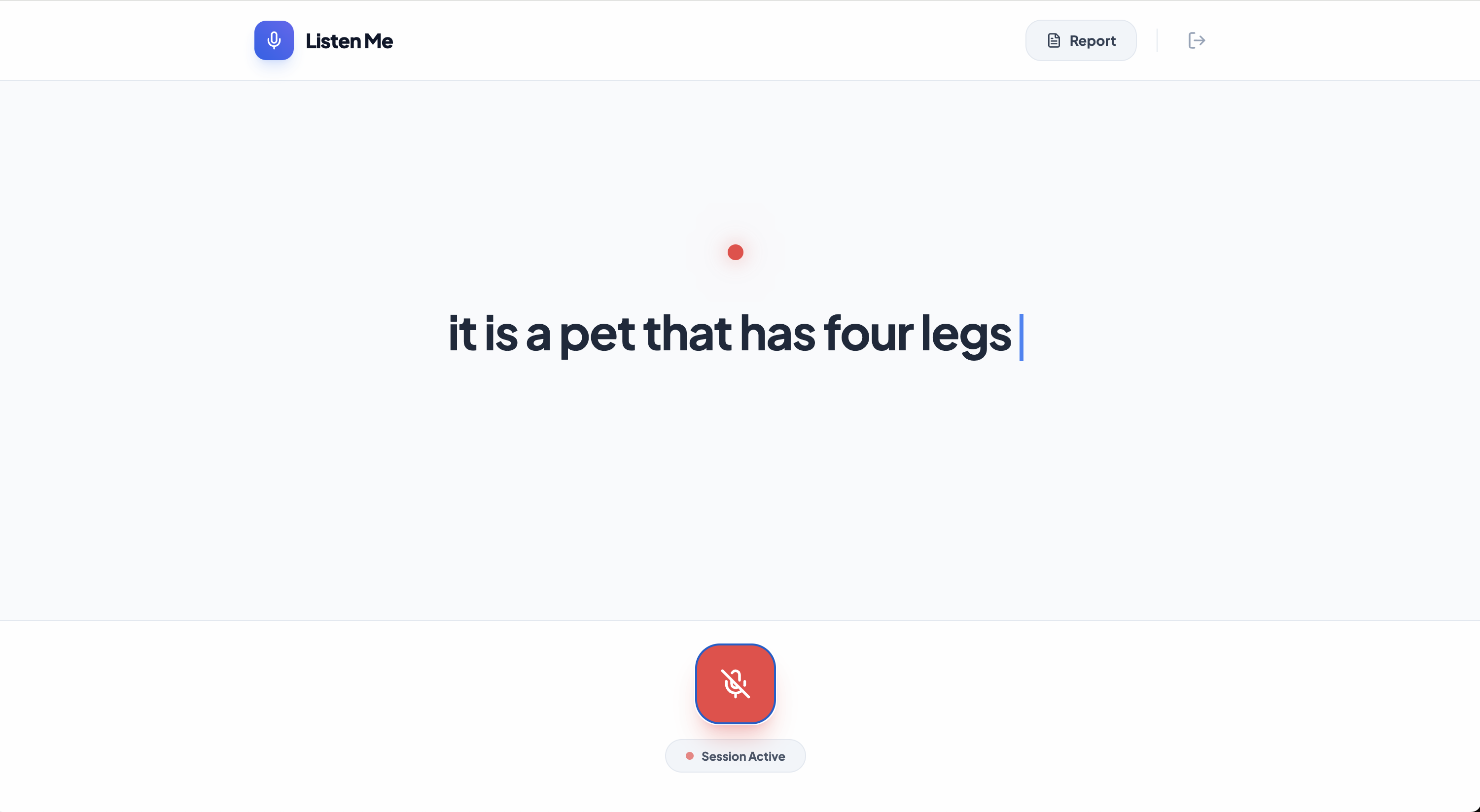
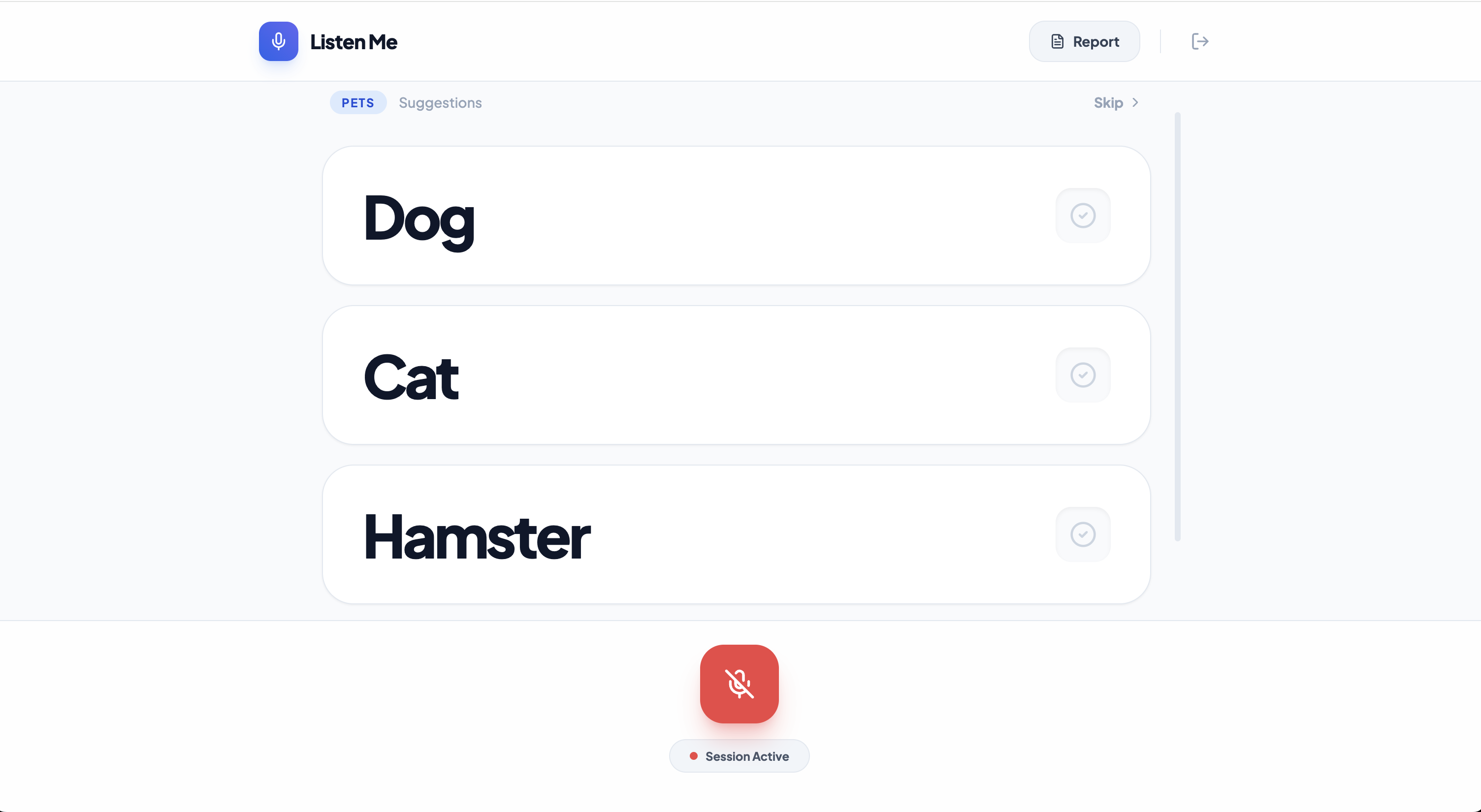
ListenMe is a real-time cognitive assistant. It listens to natural speech and, using multimodal AI, detects when a user is struggling to find a word (circumlocution). When a user describes an object (e.g., "It's a... red fruit... you crunch it"), the app instantly provides smart suggestions like "Apple." Every successful retrieval is logged into a Therapeutic Report, allowing Speech-Language Pathologists to track progress and tailor future therapy sessions based on real-world data.
How we built it
We built a hybrid stack designed for real-time, low-latency speech assistance:
Frontend: React with TypeScript, Vite for blazing-fast builds, and Framer Motion for smooth, accessible animations. We used Lucide React for icons and Recharts for data visualization in our clinical reporting dashboard.
Backend & Database: Firebase Authentication for secure user management and Firestore for real-time session data synchronization. We also implemented IndexedDB (via idb) for offline-first local storage of word logs.
AI Core: We leveraged the Gemini Live Multimodal API (@google/genai). Unlike traditional apps that transcribe audio to text first, we use native audio processing to detect pauses, hesitations, and vocal patterns that indicate word-finding difficulty—allowing the AI to "feel" when a user is struggling.
Deployment: Deployed on Vercel with a serverless architecture. The frontend is optimized for edge deployment while maintaining WebSocket connections for real-time AI interactions.
Challenges we ran into
The biggest technical hurdle was integrating real-time bidirectional audio streaming with the Gemini Live API while maintaining low latency. We had to carefully manage WebSocket connections and audio buffer handling to ensure suggestions appeared within milliseconds of a user's struggle.
We also faced challenges with Firebase Authentication configuration across multiple OAuth providers (Google, GitHub, Email/Password), requiring careful setup of authorized domains and proper error handling for various auth states.
Fine-tuning the AI's "trigger" sensitivity was crucial—ensuring it only suggests words when the user is actually struggling, rather than interrupting normal conversation. This required extensive prompt engineering and context management.
Accomplishments that we're proud of
We are incredibly proud of the Native Audio Integration. Achieving sub-second latency between a user describing an object and the AI suggesting the word feels like magic. The system processes natural speech patterns without requiring explicit commands.
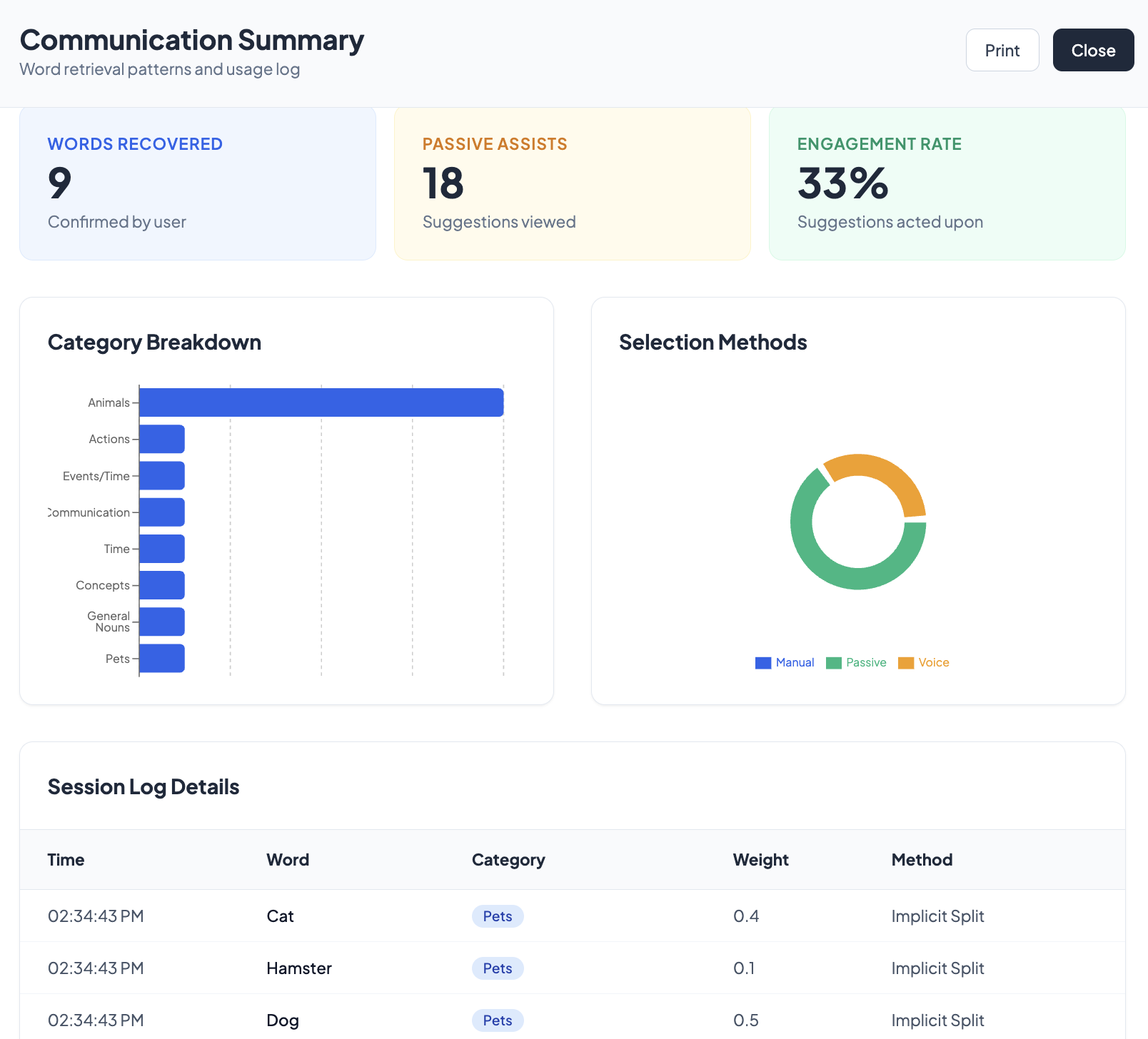
We successfully built a comprehensive reporting system with visual analytics (bar charts, pie charts, engagement metrics) that turns a simple "help" tool into a legitimate clinical asset. Therapists can now track word retrieval patterns, category breakdowns, and patient progress over time.
The visual feedback system with animated selection cues and confirmation toasts provides clear, accessible feedback for users with cognitive challenges.
Being our first hackathon, we are all extremely proud of being able to take an idea from conception to full deployment in such a short amount of time!
What we learned
We learned that multimodal AI with native audio processing is a game-changer for accessibility. Moving away from text-based prompts allowed us to create a much more human, empathetic experience that respects the natural flow of conversation.
We gained deep experience in:
Real-time WebSocket management for bidirectional audio streaming Firebase ecosystem (Auth, Firestore, offline persistence) Accessibility-first design with Framer Motion animations Clinical data visualization with Recharts TypeScript best practices for type-safe React development
What's next for ListenMe
Visual Cues: Integrating image generation so that suggested words appear with contextual pictures to further aid memory retrieval through visual association.
Mobile PWA: Developing a Progressive Web App that runs in the background, providing a "safety net" for individuals with Anomia during their daily lives outside therapy sessions.
Therapist Dashboard: Expanding the reporting system with longitudinal tracking, goal-setting features, and exportable clinical reports.
Multi-language Support: Extending the AI to support multiple languages, making the tool accessible to non-English speakers with Anomia.
Offline Mode Enhancement: Improving offline capabilities with cached AI responses for common word categories when internet connectivity is limited.
Built With
- fastapi
- firebase
- google-gemini-live-api
- indexeddb
- oauth
- react
- tailwind-css
- typescript
- vercel
- vite
- web-audio-api


Log in or sign up for Devpost to join the conversation.