


Annotate.ai
Inspiration
Over 50% of code created in modern society is generated by some sort of AI model, and this is an upwards trend from recent patterns in developer projects. AI is widely used in various leading tech companies, including AMD, Bitdeer AI, and IBM. Due to this, there has been a significant decrease of proper documentation within the code, as AI doesn’t properly construct it.
Developers lose a vast amount of time trying to decipher generated code and figuring out pull requests. This creates a lot of stress within the workflow of industries, thereby creating delays within the business and an overall decrease in productivity. As first-year computer engineers, we personally share a lot of the same difficulties, such as hating the hassle to create comments within code and creating effective commit messages. In addition, using AI is a very common trend when developing projects in hackathons; however this prevents the learning aspect when it comes to participating in these types of events. These are issues we saw as a team, and we wanted to find a solution to fix these problems.
What it does
Annotate.ai is an ultra-fast, context-aware coding assistant deeply integrated into Visual Studio Code as an extension. Its core capabilities include:
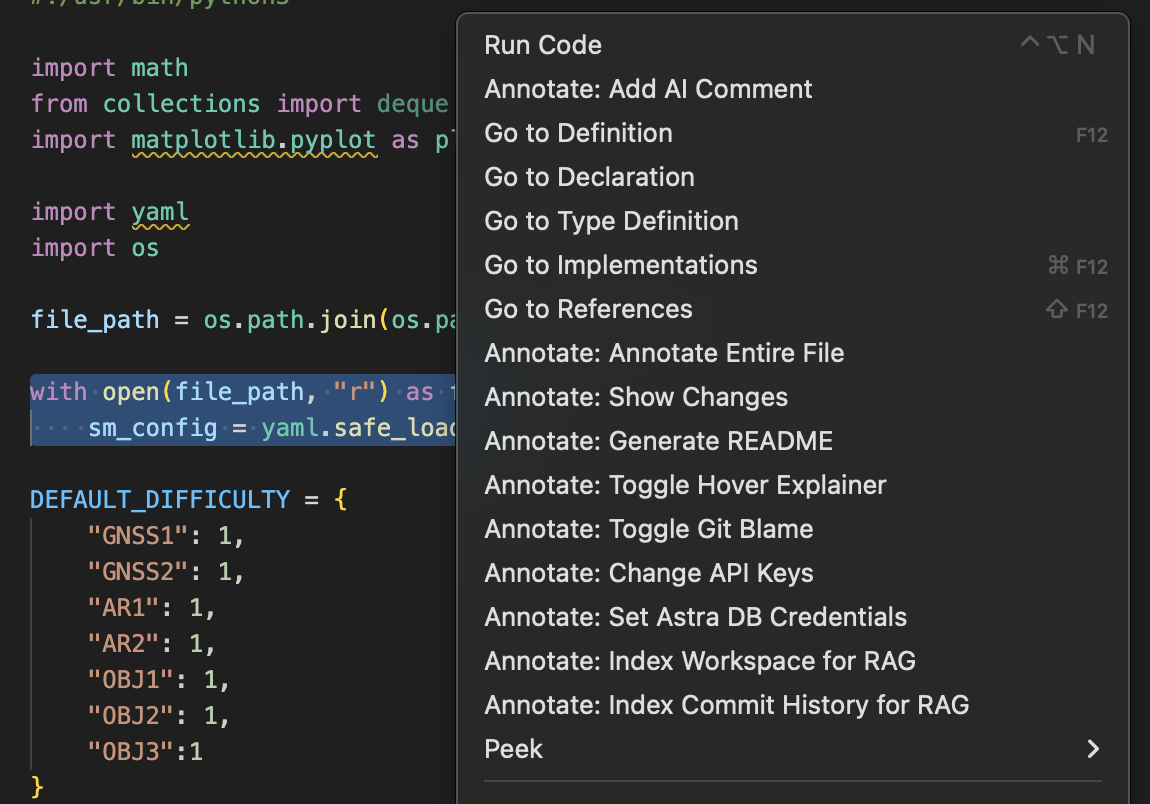
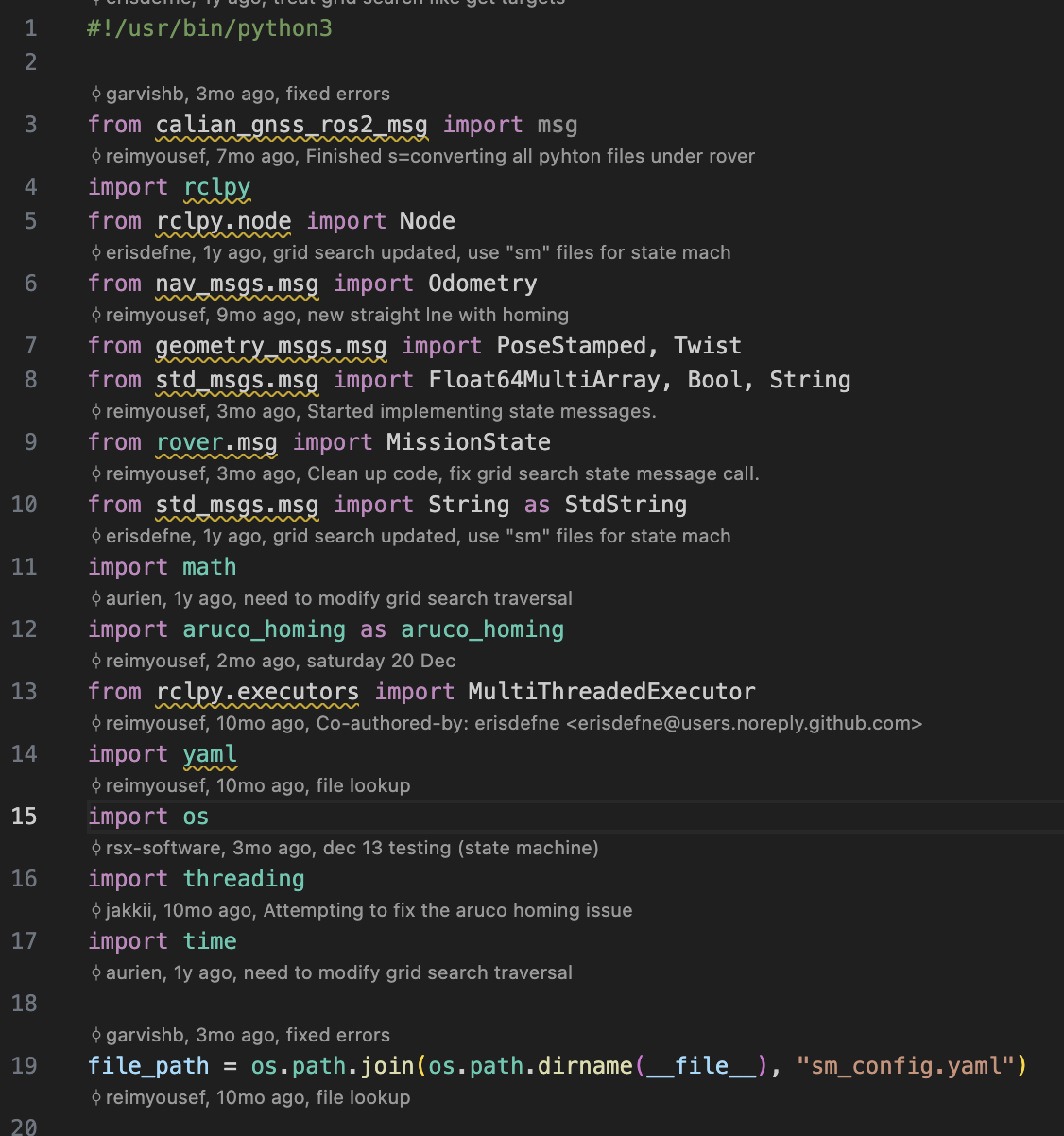
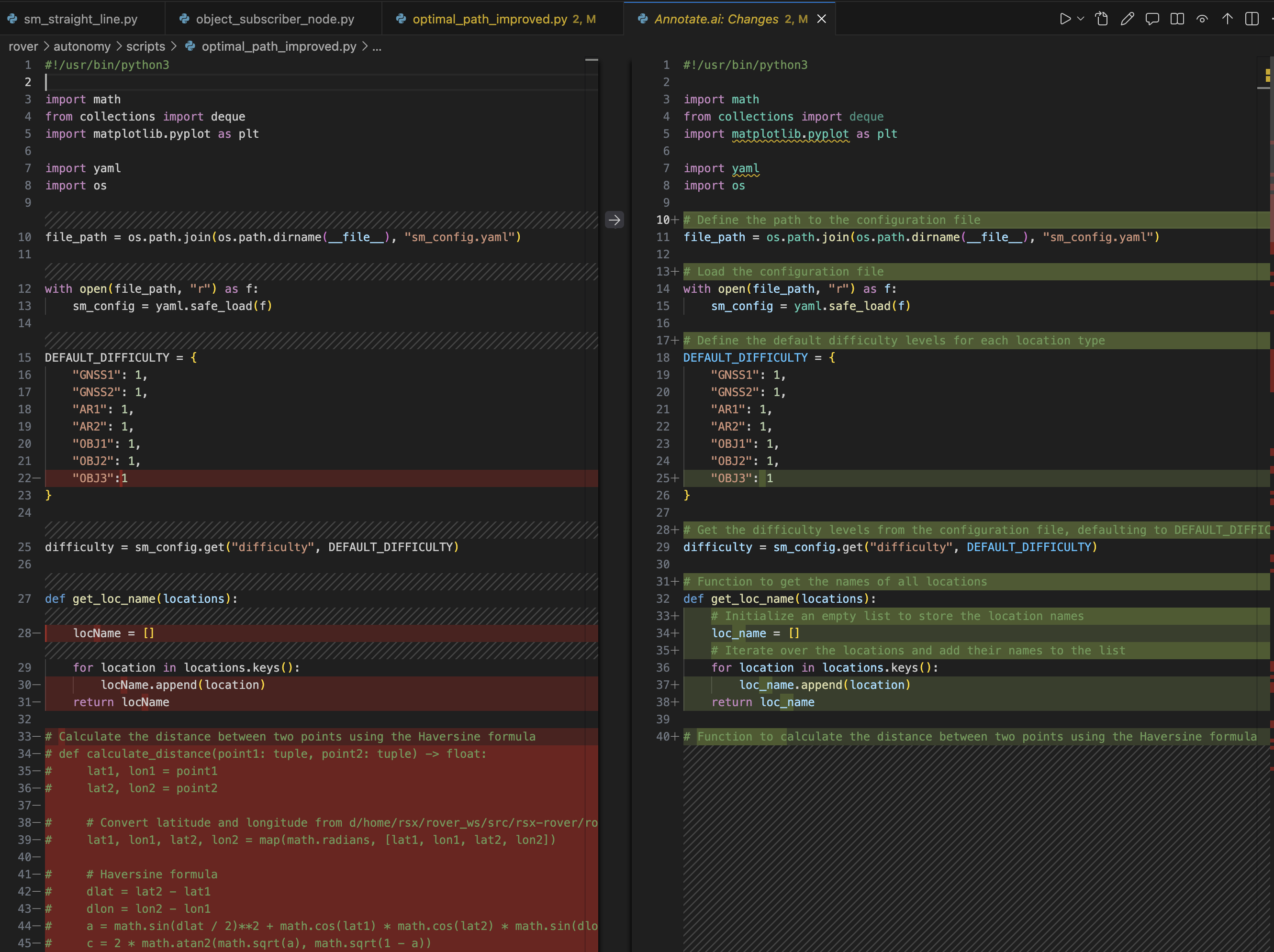
- Hover Explainer: Explains complex sections of code instantly when hovered over.
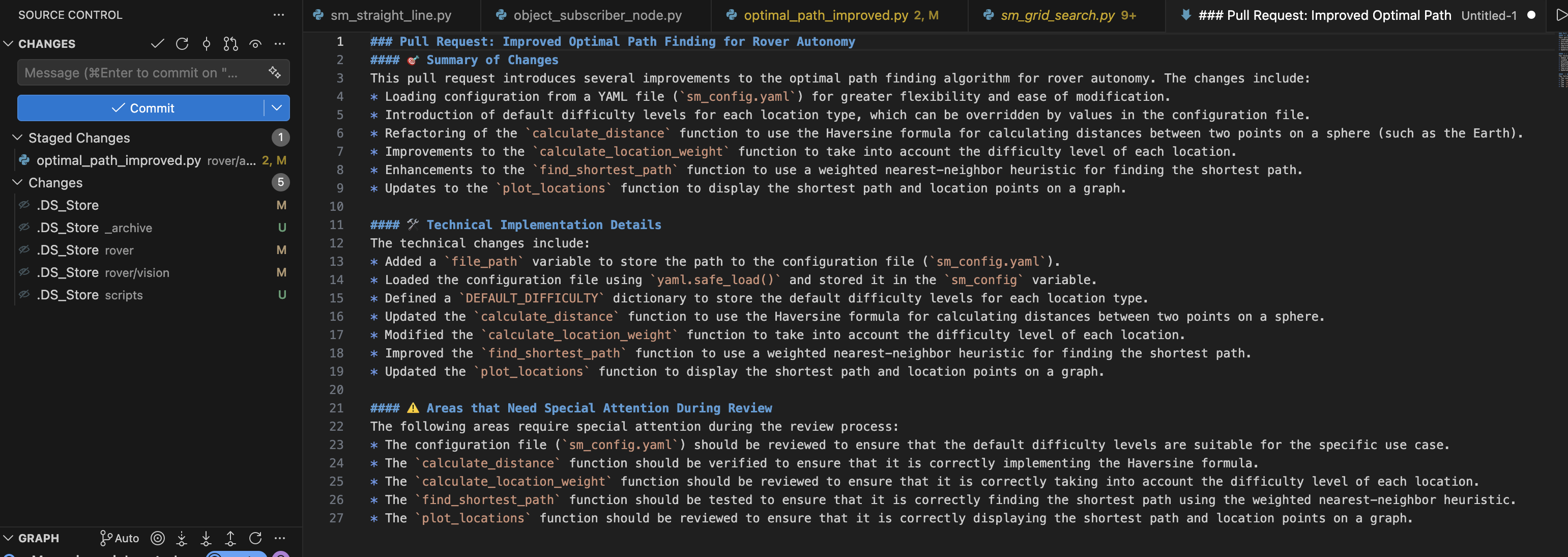
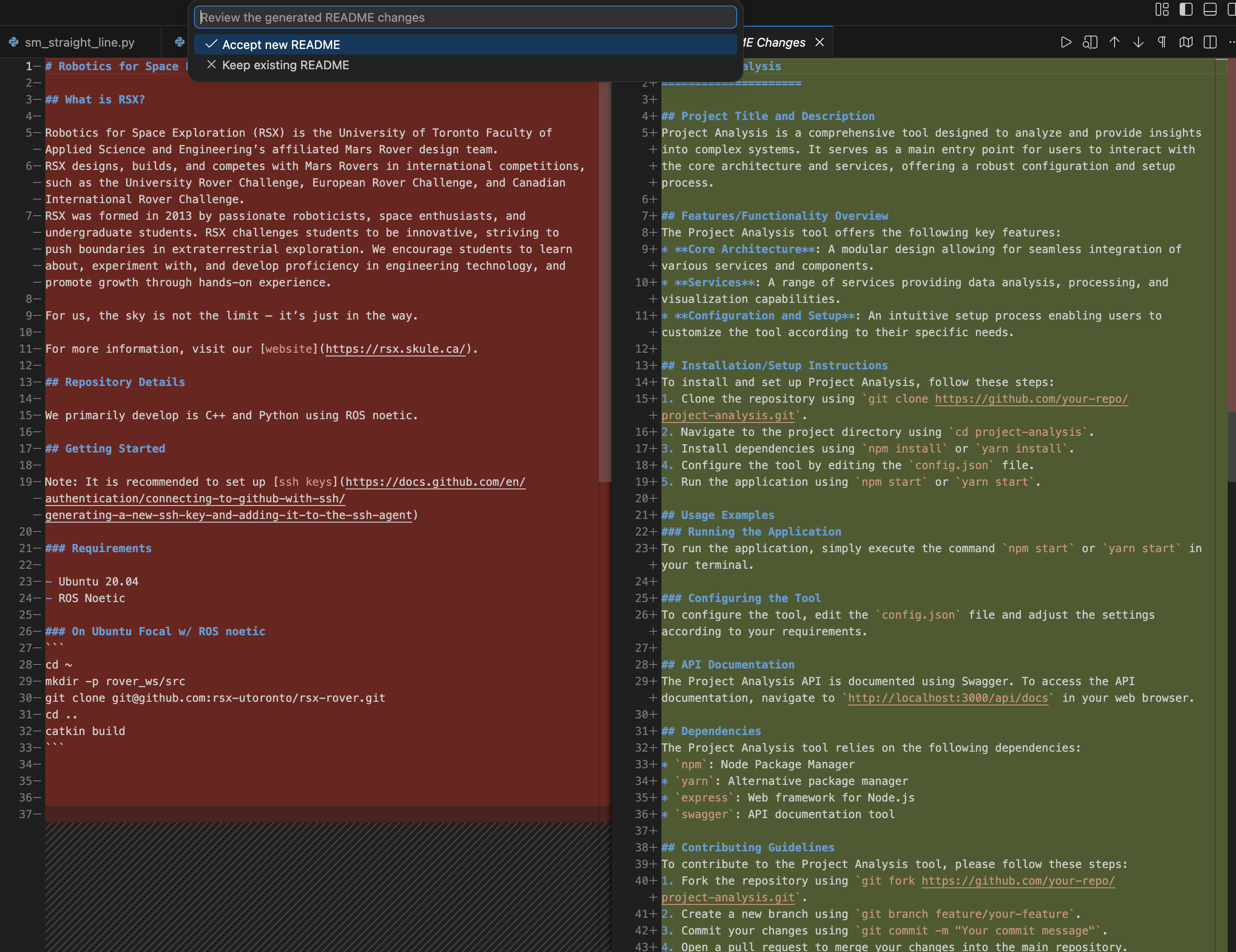
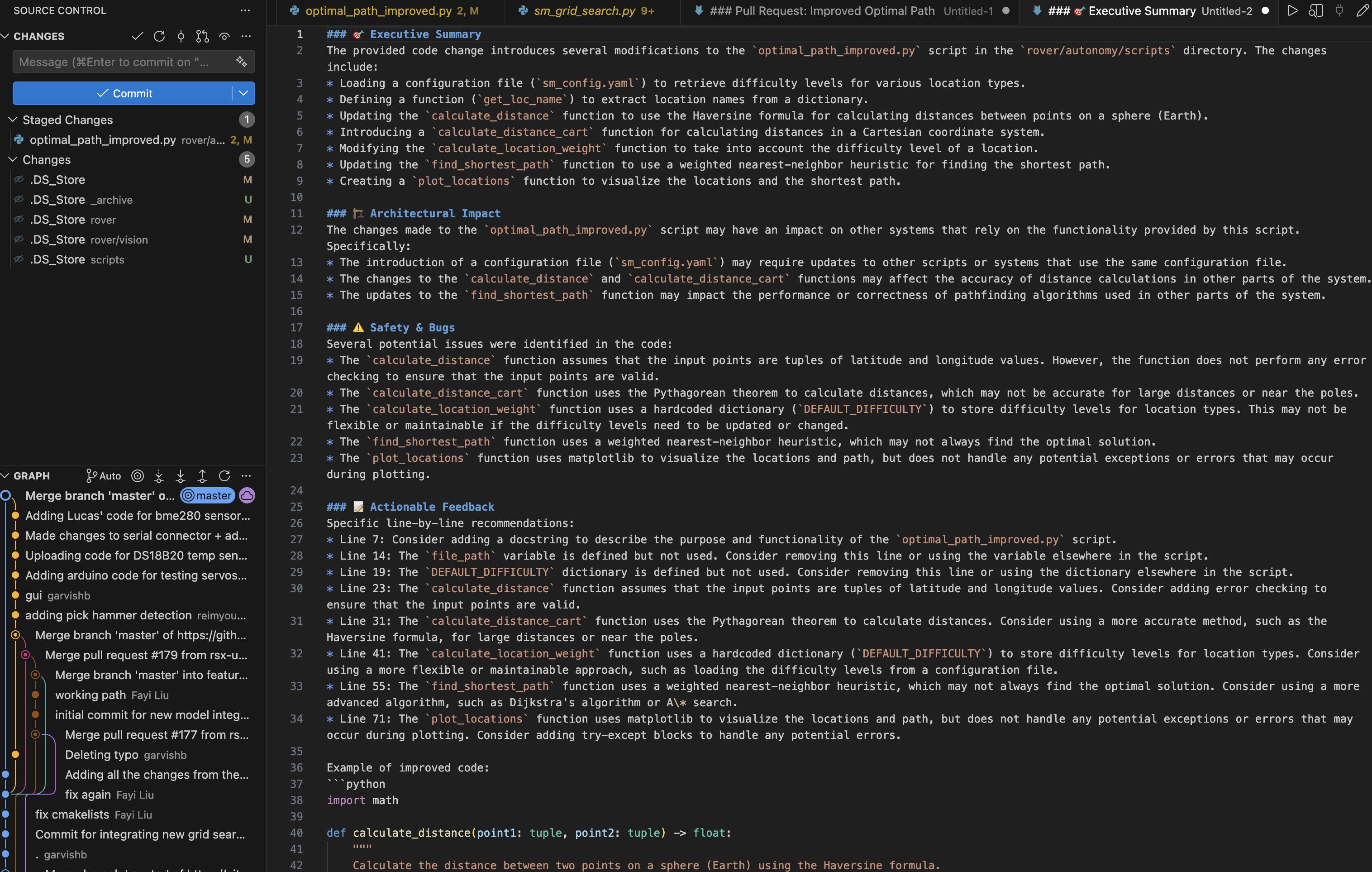
- Annotations: Generates inline documentation for selective sections of code or entire files. It can even analyze the entire repository to draft an accurate README file.
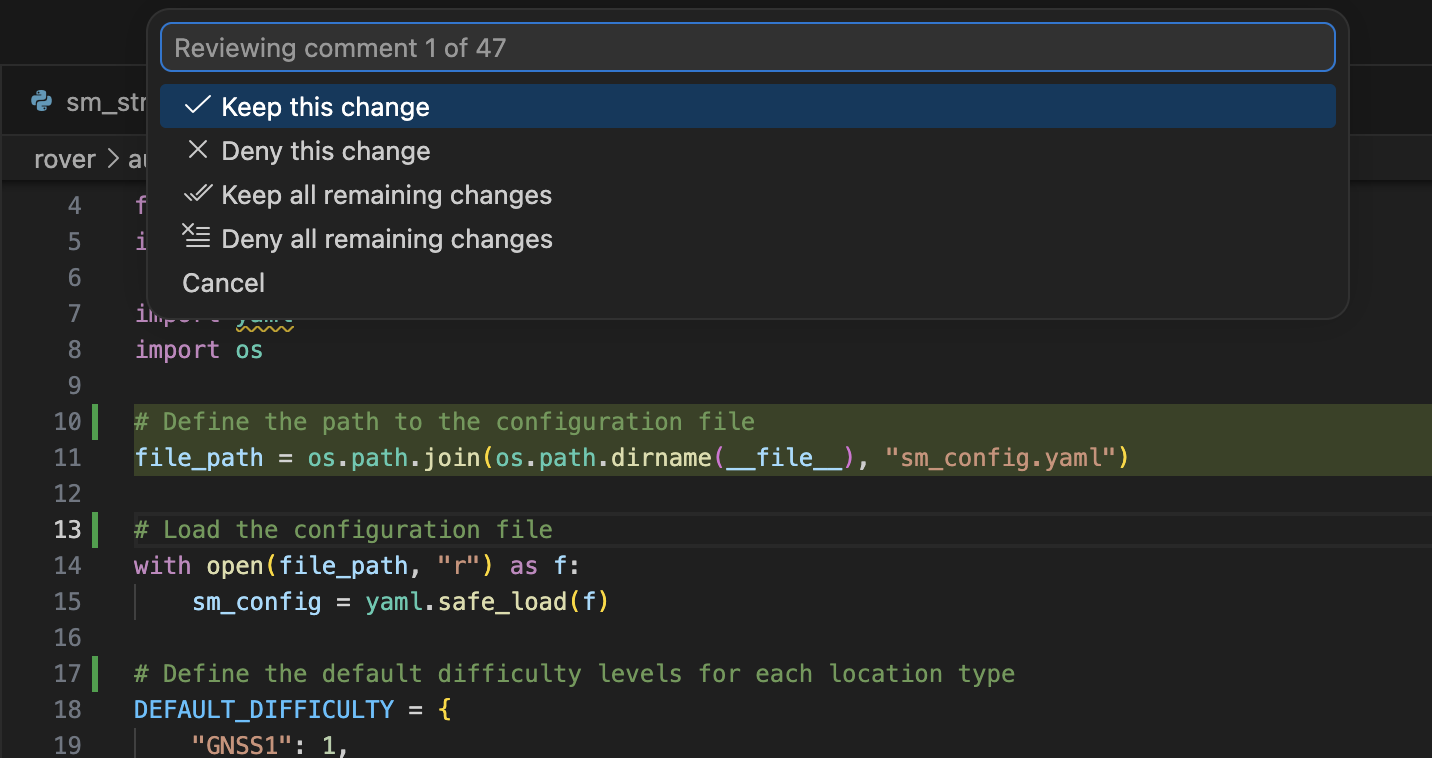
- AI Code Review: Performs a comprehensive review of your local changes while staging, catching issues before you even commit them to the repository.
- Smart Commits & PR Messages: Uses Retrieval Augmented Generation (RAG) to pull your repository's historical commits, adapting the generated messages to your historic format and style.
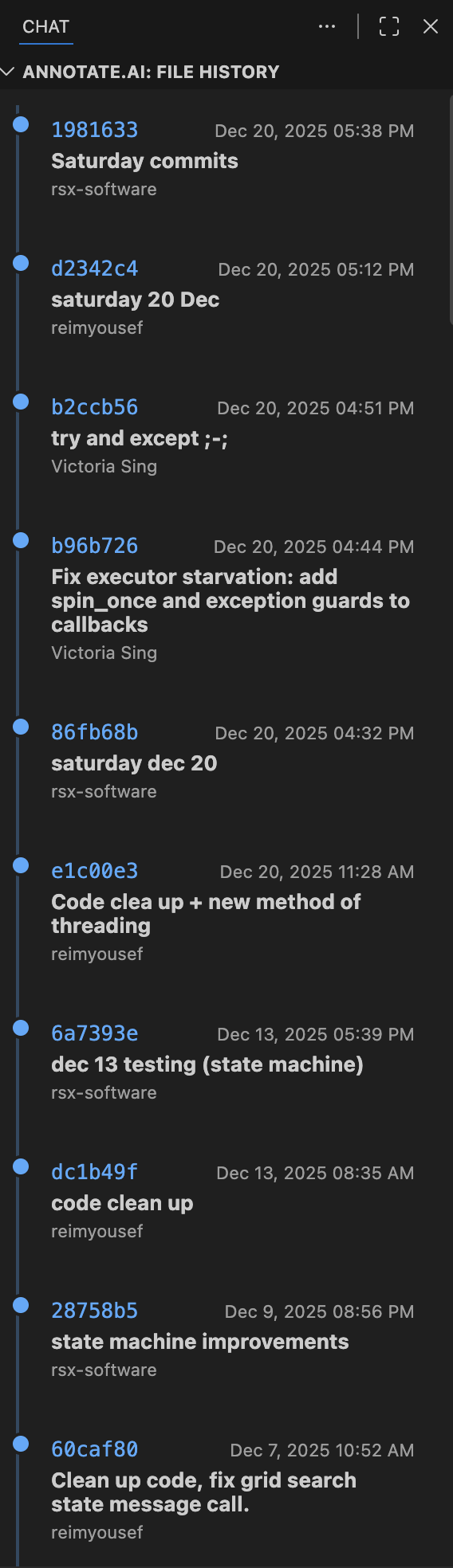
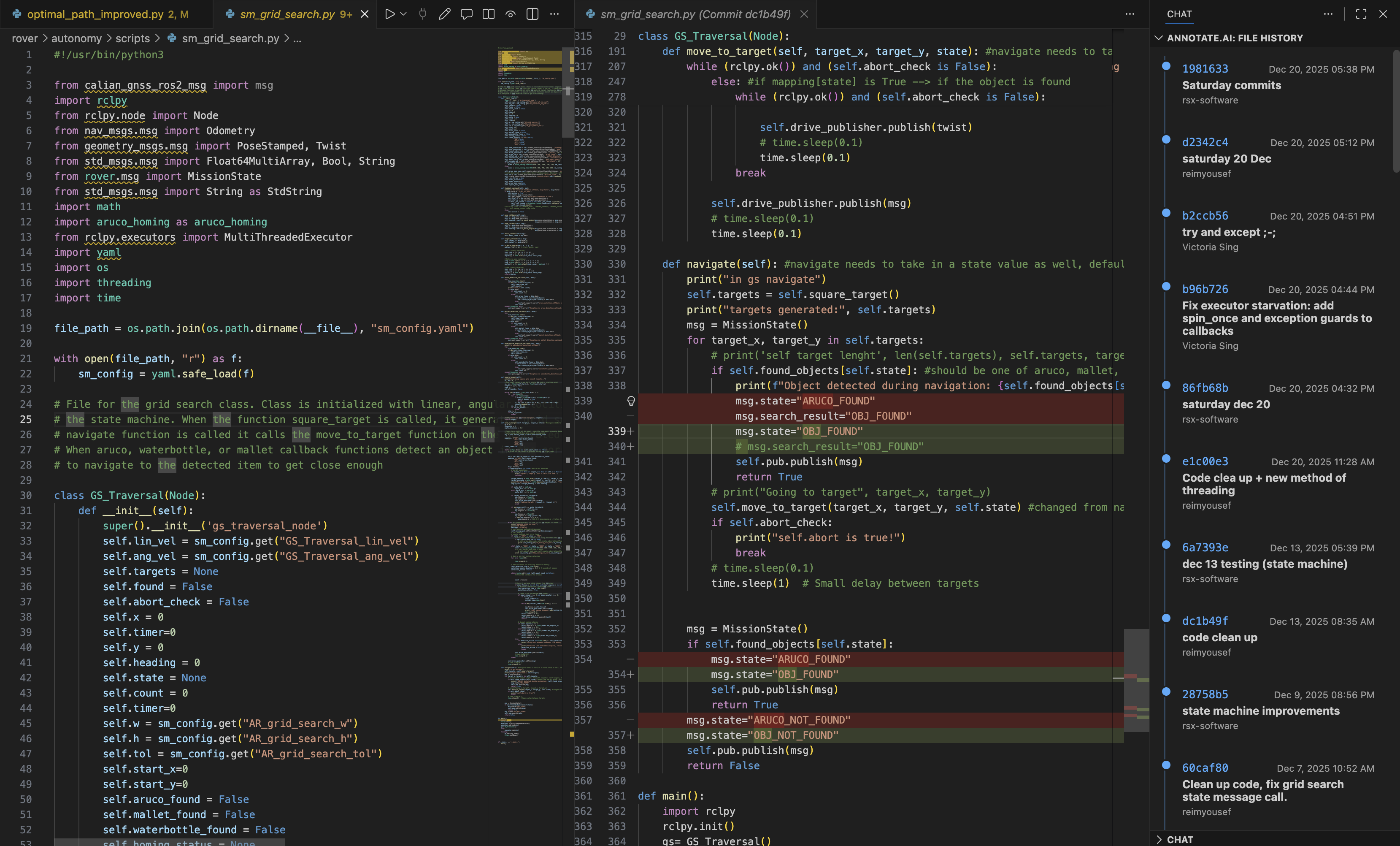
- Git File Lineage: Visualizes inline Git history and a dedicated file historic sidebar view.
How we built it
We built the extension using TypeScript and the VS Code Extension API. For our AI architecture, we focused on prioritizing speed and context:
- Inference: We use Groq (specifically
llama-3.3-70b-versatile) for fast generative logic and results with very little latency. - Vector Database: We utilized Astra DB as our serverless vector database to store document chunks and historical commit hashes.
- Local Embeddings: To keep things private and secure, we use HuggingFace Transformers (
@xenova/transformers) running locally in Node.js to generate vector embeddings right on the user's machine before indexing them in Astra DB.
Challenges we ran into
Our first major challenge was trying to utilize the Moorcheh AI API. We primarily used this tool for implementing the RAG to receive past repository commits to prompt towards the AI models. However, we faced constant authentication issues with the API key. We performed some research on the discord for any advice, and we stumbled upon the Astra DB tool by IBM. The tool caught our attention as a mentor mentioned it was a free option without accessibility issues, which is why we made this transition.
Another major challenge were usage limits on our API keys for Groq. To solve this issue, we became stricter with our API usage, limiting testing to what was necessary. We also implemented a function in the code to change the API keys for users who may experience the same problem.
At the beginning of the hackathon, we had trouble developing all of the functionalities of the extension. We needed to think of features that developers would find useful, while also being practical and feasible within the timeframe of the hackathon. We solved this issue through various iterations of idea generation and several feature pivots throughout the implementation of the project.
We had a hard time implementing seamless interactive functionalities, such as single-line commenting with accept/deny iterations, side-by-side diff views, and custom webview sidebars for Git history. We allocated a lot of time to address this challenge as we knew this was one of our highest priorities.
Accomplishments that we're proud of
- Production Readiness: We’re proud that we were able to create and implement such a production ready project with features at a level we were satisfied with. There were additionally no obvious bugs or problems at the time of submission.
- Deep Integration: We’re proud that our project has such a high level of integration with vscode. We carefully decided on technologies such as CodeLenses library, Source Control API, and Github API to create an extension that feels native to VS Code.
- User-Friendly Interface: Since our initial inspiration for the project was to solve problems we had encountered firsthand, we're proud of how user-friendly and intuitive the final interface was.
What we learned
- Deployment: We learned plenty about the VS Code extensions marketplace, including how to deploy, maintain, and push seamless updates for the extensions.
- Vector Databases: We learned how to use vector databases like Astra DB for vector embeddings and Retrieval-Augmented Generation (RAG). We also learned how to generate vector embeddings locally using
@xenova/transformersto feed LLMs exact context to prevent hallucination. - Infrastructure Scaling: Building an AI project heavily reliant on external APIs taught us important lessons on how to handle API rate limits, scale infrastructure, and optimize our token usage to ensure the extension continues working.
What's next for Annotate.ai
- Customization: We plan to implement a robust configuration system that allows users to define custom prompts, enforce specific output rules, and change the tone and verbosity of generated text.
- Intelligent Routing: Annotate.ai currently relies on a single model for all operations. We plan to implement an intelligent routing system that selects the most appropriate AI model based on the specific task. For trivial actions like generating a short inline comment, we can utilize a smaller model whereas for complex files and reviews, we can use more powerful reasoning models. This will optimize both computation power and API costs relative to the complexity of the problem.
- Optimization: Our current extension is roughly 250MB, primarily due to bundling
@xenova/transformersand its associated models. We want to explore strategies to optimize the storage in the future, such as by using smaller, more specialized models.
AI Usage
Yes
Built With
- astradb
- axios-library
- cross-keychain-library
- diff-library
- git-cli
- github-api
- groq
- hugging-face-transformers
- javascript
- node.js
- typescript
- vs-code-extensions-api


Log in or sign up for Devpost to join the conversation.