-

Home Page
-
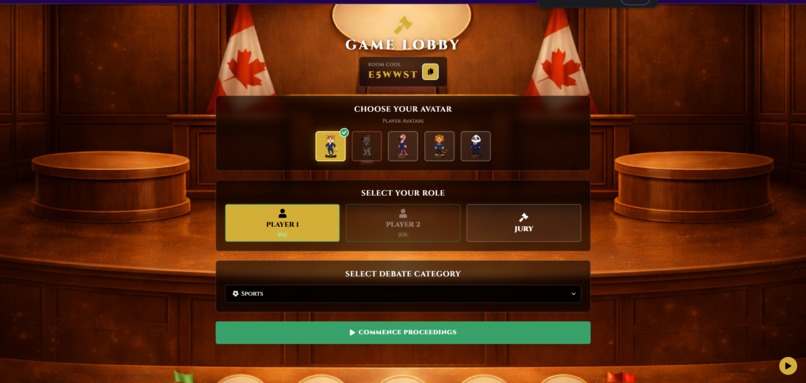
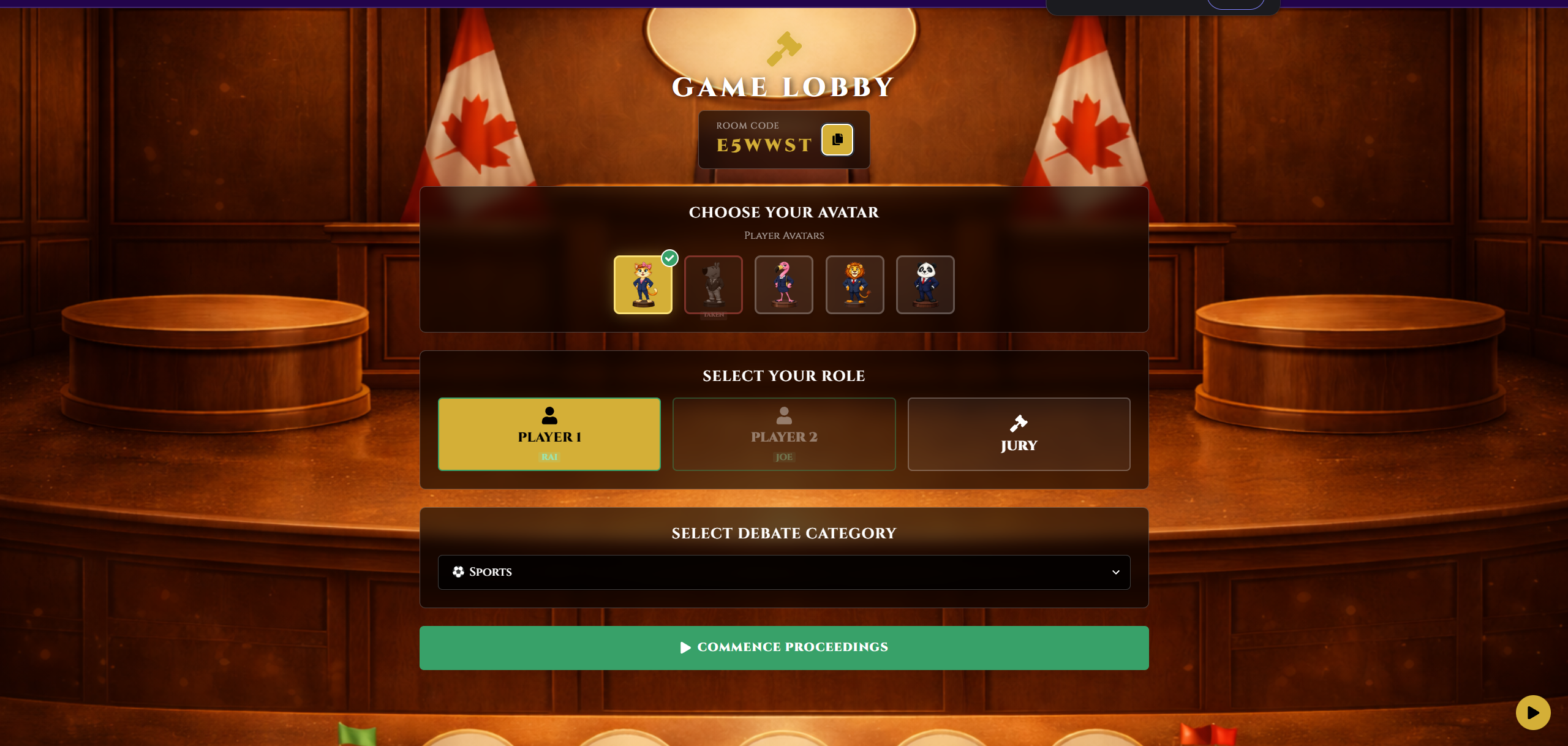
Player Selection
-
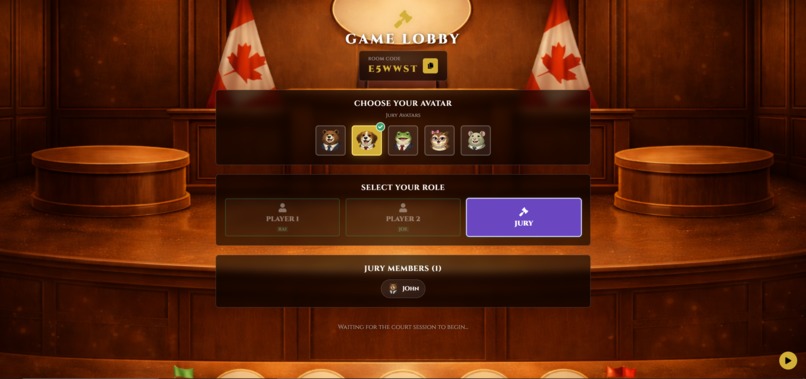
Jury Selection
-

Prompt revealed
-
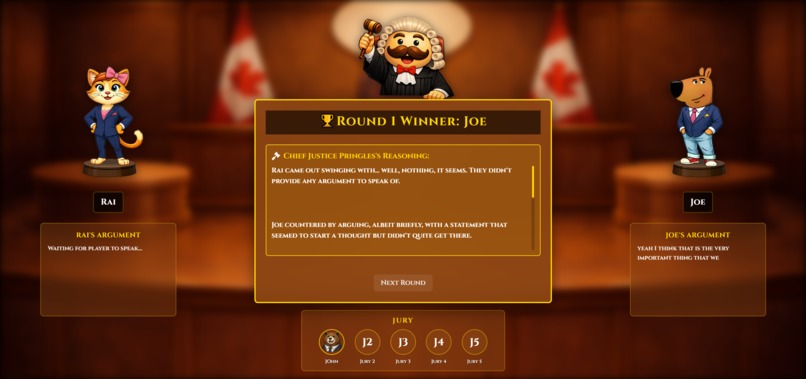
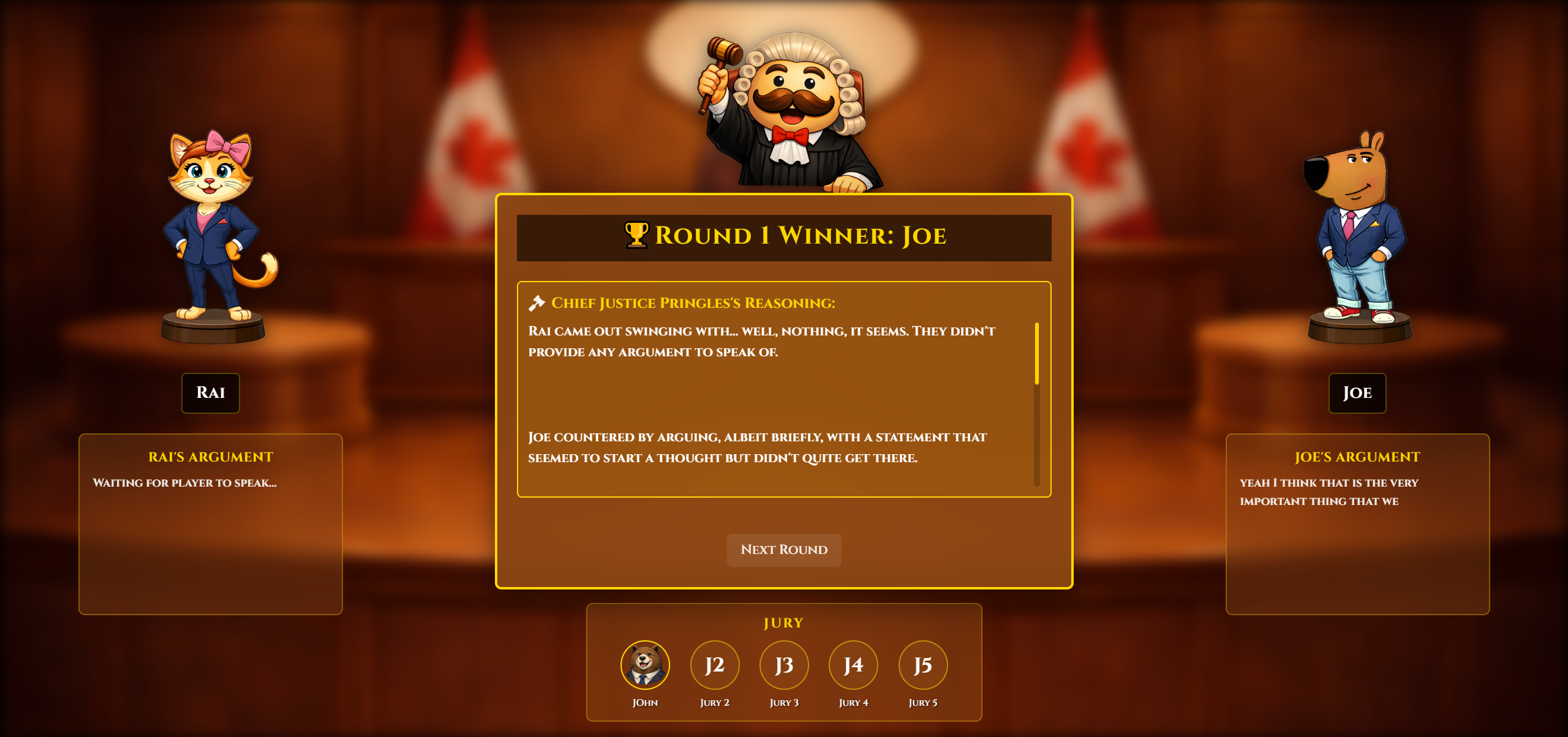
Justice Pringle's Verdict
-
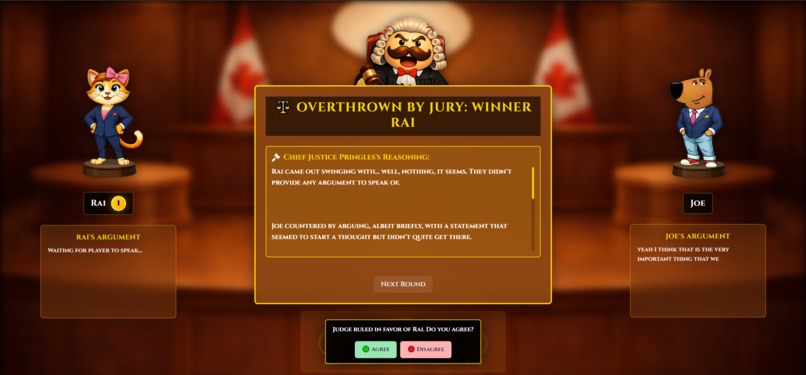
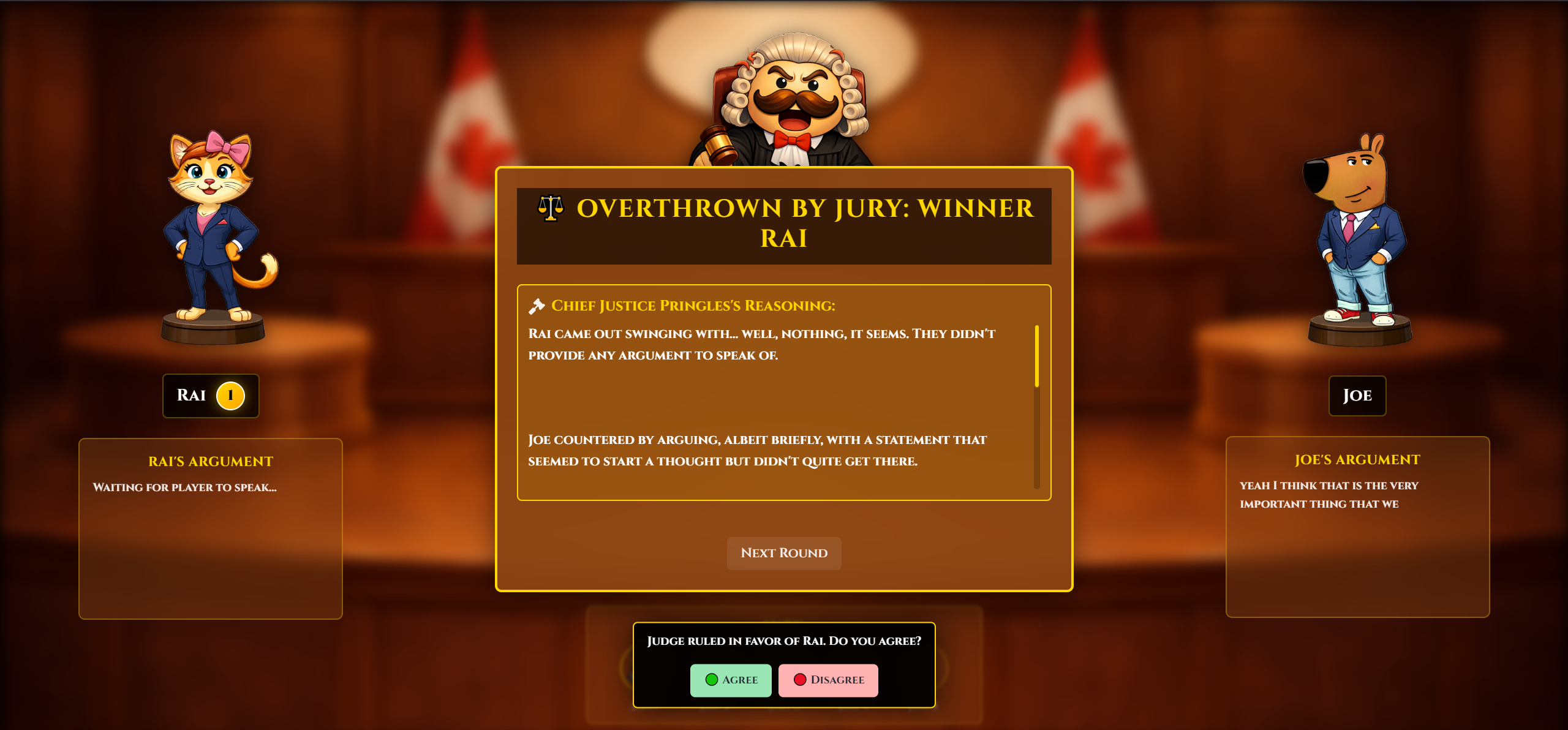
Jury overthrows verdict!
-
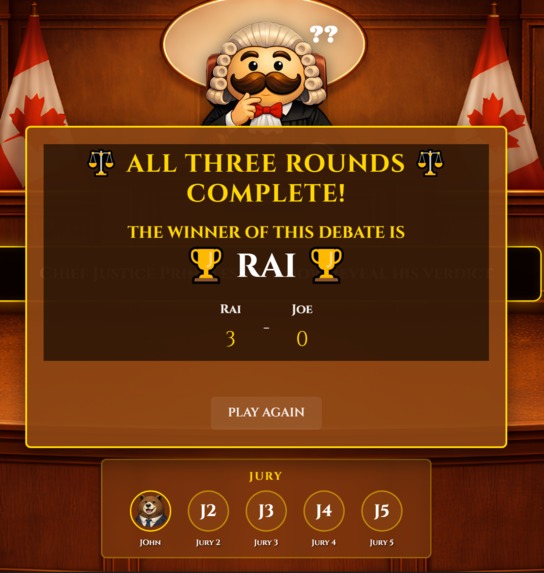
WINNER



About Animal Court: Helping People Find Their Voice Through Debate
What Inspired Us
The idea for Animal Court came from something we've all experienced: having great thoughts but being too nervous to share them. We noticed that so many smart people stay quiet in discussions not because they don't know anything, but because speaking up feels terrifying. Whether it's anxiety, shyness, or just fear of being judged, these barriers prevent people from developing crucial skills like critical thinking and clear communication.
Traditional debates are intimidating. The formal structure, the audience watching, the pressure of putting yourself out there it all creates this wall that keeps beginners away. We started thinking: What if there was a way to practice debating without all that anxiety?
That's where Animal Court came from. We wanted to create a space where anyone could argue their point, get feedback, and improve their skills without the social pressure. By letting users pick fun avatars instead of showing their real identity, we hoped people would feel free to express bold ideas, try new arguments, and build confidence in a low-stakes environment.
We also noticed how much misinformation spreads online and realized that fighting it isn't just about fact-checkers we need people who can think critically and argue with evidence. Animal Court turns that learning process into something fun instead of feeling like homework.
What We Learned
Building this project taught us way more than we expected across multiple areas:
Technical Skills
Real-Time Communication: Getting multiplayer to work smoothly was harder than we thought. We had to learn WebSockets, state management, and how to keep latency low. We discovered that anything over 200ms delay feels noticeably laggy and breaks the immersion. To hit that target, we had to optimize how we send data and make the server the authority on timing.
Working with AI: Different AI models behave really differently. We tested several and learned that raw speed matters less than getting consistent, helpful responses. Writing the right prompts to make the AI sound educational but not preachy took a lot of trial and error. We also figured out how to bake fact-checking into the AI's reasoning so it acts more like a teacher than just a referee.
Audio Processing: Real-time speech-to-text was surprisingly complex. We assumed transcription would "just work," but there's a huge difference between services in terms of speed, accuracy, and how they handle people talking over each other. Getting browser audio converted to the right format for WebSocket streaming meant diving deep into audio encoding, sample rates, and buffer handling. Every millisecond of delay adds up.
Understanding User Behavior
Avatars Reduce Anxiety: When we tested with real users, we saw something cool people who were hesitant to speak up became way more expressive when using avatars. This "hiding behind a character" thing actually helped them be more authentic. They felt safe trying arguments they'd normally keep to themselves.
Game Mechanics Help Learning: The three-round format worked really well for skill development. We watched players who lost round one adapt and improve by round three. The scoring gave clear feedback without making things so competitive that people got discouraged.
The Jury Feature Keeps Everyone Engaged: Letting spectators vote to override the AI turned out to be more powerful than we expected. People told us they felt involved rather than bored watching, and being able to challenge the AI's decision made them think more critically about the reasoning itself.
Educational Impact
Confidence Builds Gradually: During testing, we saw shy people slowly become more articulate over multiple games. One person said, "I'd never speak up in class, but here I can test ideas without feeling dumb." That confirmed our whole theory about safe practice spaces.
Immediate Corrections Stick: When the AI calls out wrong facts right away, people actually remember those corrections. That context-specific feedback seems to work way better than generic advice.
How We Built It
Our Approach
We went with a keep-it-simple philosophy that made sense for a hackathon but could still scale up later. Instead of overcomplicating things with databases, we used efficient in-memory storage that cleans itself up automatically. This let us iterate fast without sacrificing performance.
Frontend
Component Structure: We built it with React and Vite, organizing everything around three main pages, Home for creating rooms, Lobby for setup, and Game for the actual debate. Chakra UI gave us good-looking, accessible components right out of the box, which saved tons of time.
Keeping Everything Synced: The multiplayer aspect required careful state management. We used Socket.io events as the single source of truth, with the frontend updating optimistically so things feel responsive. Every action picking avatars, voting, arguing broadcasts to everyone in the room to keep everyone on the same page.
Capturing Audio: We used the browser's MediaRecorder API to grab microphone input, then converted it to base64-encoded audio for sending over WebSocket. This all happens in the browser, which keeps the server load light while still getting low-latency transcription.
Backend
Server Setup: Built with Node.js and Express, the backend handles all game logic through Socket.io events. Room-based messaging means players only get updates about their own game, so multiple games can run at once without interfering.
Transcription: We hooked up ElevenLabs Scribe v2 for real-time speech-to-text. It uses WebSocket connections that stream audio chunks and send back transcriptions. We handle buffers server-side to make sure each player's audio stays separate.
AI Judge: The AI uses Groq's Llama 3.3 70B model with prompts we carefully designed. We tuned the prompt to make the AI sound educational, prioritize fact-checking, and always give three paragraphs of reasoning. Temperature setting of 0.7 keeps responses varied but consistent.
The AI gets both players' transcripts and the debate topic, then decides: $$ \text{Decision} = f(\text{Prompt}, \text{Transcript}_1, \text{Transcript}_2) $$ where f is the AI's reasoning process, producing:
- Who won
- Three educational paragraphs explaining why
- Fact corrections built into the third paragraph
Making It Personal: After the AI responds, we automatically swap "Player 1" and "Player 2" with actual names so the feedback feels personalized.
Testing Different Technologies
Trying Transcription Services: We actually implemented and tested three different options:
- ElevenLabs Scribe v2: Got 150ms latency with solid accuracy this is what we went with
- Deepgram: Tested it for reliability but it was a bit slower
- Web Speech API: Browser-built-in option we tried as a free alternative, but accuracy was too inconsistent
Comparing AI Models: We seriously tested four different providers:
- Groq (Llama 3.3 70B): Super fast responses with good reasoning—our final pick
- IBM watsonx.ai: Great at explaining itself but slower
- Google Gemini 1.5 Flash: Good features but less consistent in tone
- Anthropic Claude: Best reasoning quality but too slow and expensive for a hackathon
We picked based on speed, how educational it sounded, and cost.
Challenges We Ran Into
Technical Problems
Syncing Audio: Our first version let both players record at once, but we found that different internet speeds meant audio arrived at the server at different times. If one player's audio showed up 300ms before the other's, the transcriptions got misaligned with the timer. We fixed this by adding server-side timestamps and buffering early arrivals.
Voting Bugs: The jury voting initially had race conditions. If someone changed their vote really fast, the system sometimes counted wrong. We fixed it by making vote updates atomic with proper acknowledgment.
AI Being Inconsistent: Early on, the AI would sometimes give two paragraphs, sometimes four, and put the verdict in random places. This broke our frontend. We solved it with stricter prompt instructions and validation before sending responses.
Transcription Lag Building Up: At first we sent every audio chunk right away, but network delays stacked up and created noticeable lag. Switching to batched sending with 200ms delays cut perceived lag by 60% without hurting accuracy.
User Experience Issues
Confusing Role Selection: Early testers got confused between "Player" and "Jury" roles. We redesigned the lobby with clearer labels, visual differences, and grayed-out buttons for filled spots. This made onboarding way smoother.
Timer Stress: Some people said 20 seconds felt too short and made them panic. But when we tried 60 seconds, people rambled and got bored. 20 seconds ended up being the sweet spot short enough to keep focus, long enough to make a point. We added a countdown animation to make it feel less stressful.
Spoiling the Results: Showing scores right after each round accidentally revealed the winner before the AI's explanation appeared, ruining the suspense. We made score badges only animate after jury voting finishes, keeping the drama intact.
Design Decisions
Avatar Continuity: We debated whether avatars should stay the same between games or reset each time. Staying the same helps friends recognize each other, but resetting adds more anonymity. We went with session-based avatars to prioritize psychological safety for newcomers.
AI vs. Jury Power: Balancing AI authority with jury democracy was tricky. At first we required unanimous jury votes to override, but one stubborn person could block fair corrections. Simple majority voting worked way better in practice.
How Hard to Push Back on Bad Facts: We struggled with how firmly the AI should correct misinformation. Too harsh and people get discouraged; too gentle and wrong info slides. We landed on embedding corrections in educational context like: "While that was a strong argument, it's actually the case that [correction]. With that in mind..." This corrects without making people feel bad.
The Human Side
Beyond all the technical stuff, Animal Court's real success is how it affects people's confidence. We saw users who started by typing in chat (too nervous to speak) gradually start using their voice first hesitantly, then with real confidence. The avatars gave what one person called "a mask to hide behind until I didn't need it anymore."
It was especially powerful for people who aren't native English speakers. They said they felt less self-conscious about accents when playing a fun character. Several people told us they practiced in Animal Court before giving class presentations, using it as a "safe rehearsal space" where mistakes don't matter.
This proved what we believed from the start: technology works best when it helps human connection rather than replacing it. We're giving people scaffolding to find their voice so they can eventually speak confidently anywhere.
What's Next
Animal Court is our take on what educational tech should be: fun but meaningful, easy to use but challenging, technically solid but focused on people. We didn't just build a debate game we built a tool for personal growth where every round helps you develop the skills democracy needs: critical thinking, evidence-based reasoning, and the guts to speak up.
The challenges we faced taught us that making good educational tools means balancing technical excellence with understanding psychology. Every optimization, every tweaked prompt, every UX improvement serves one goal: helping people realize they have valuable ideas worth sharing.
With misinformation everywhere and people talking past each other online, we think the solution isn't silencing voices but empowering quieter ones giving everyone the tools, practice, and confidence to engage thoughtfully. Animal Court is our attempt at making that happen.
Built With
- chakra-ui
- cloudflare
- elevenlabs-scribe-v2-api
- express.js
- gemini
- groq-api-(llama-3.3-70b)
- howler.js
- node.js
- react
- react-router
- socket.io
- uuid
- vite
- watsonx
- whisper




Log in or sign up for Devpost to join the conversation.