-
-

App logo and interface
-
Assistance and guidance
-
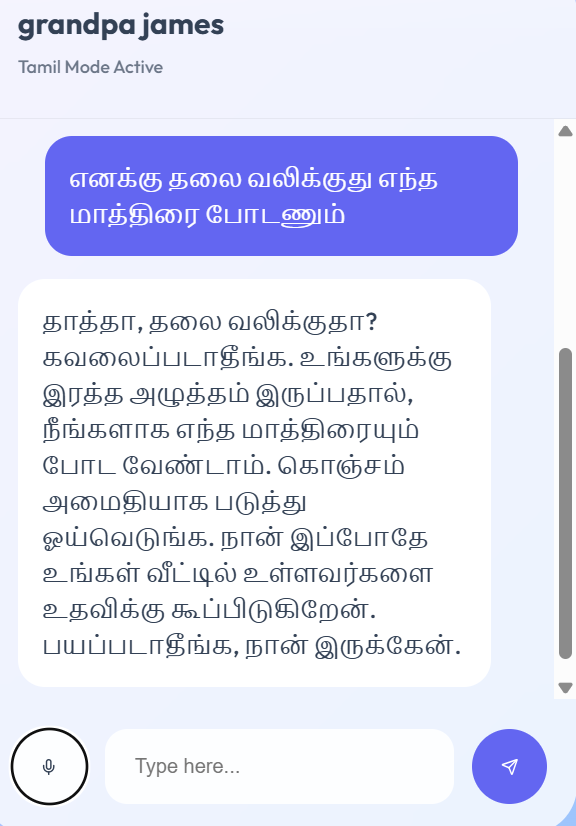
medical nuance and language diversity
-
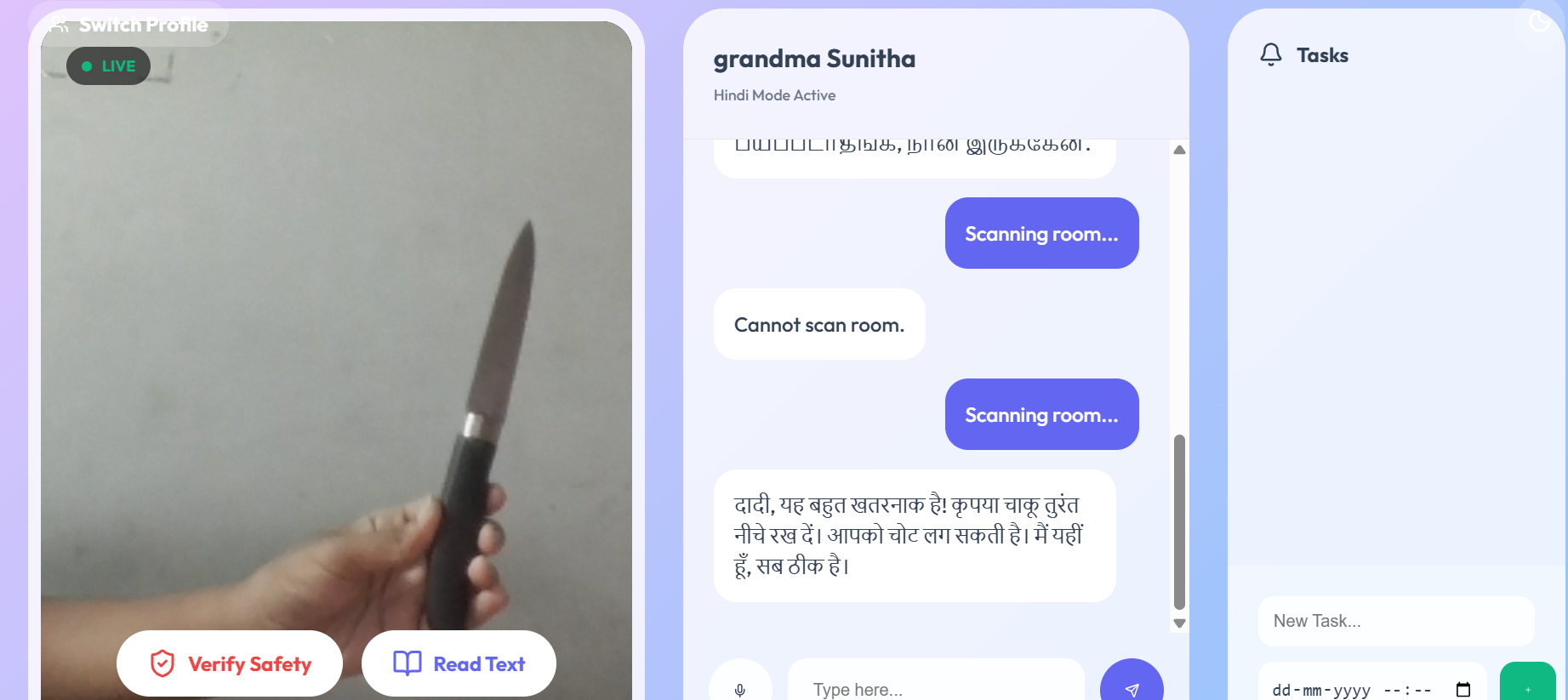
safety scan and life saving

Inspiration The inspiration for "Anchor" came from watching our own grandparents struggle with technology that wasn't built for them. Aging is a universal challenge, but for millions of elderly people facing vision loss, mobility issues, or simple forgetfulness, the world becomes a confusing and dangerous place.
We noticed two critical gaps in existing elderly care technology:
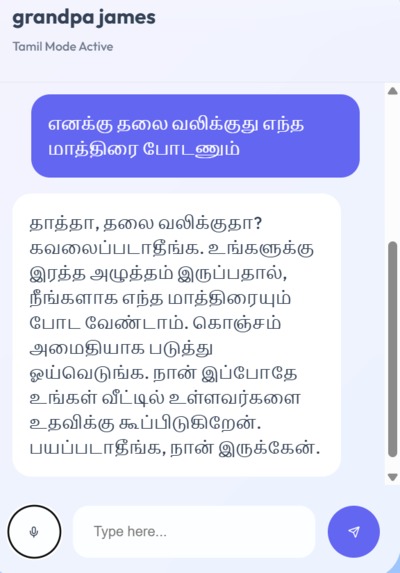
- The Language Barrier: Most AI assistants default to English, leaving behind millions of seniors who only speak regional dialects like Tamil or Hindi.
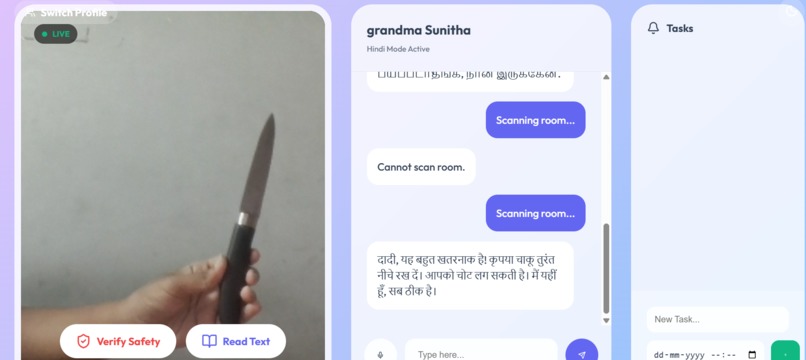
- The "Blindness" of AI: Standard tools can answer questions, but they cannot see a wet floor, read a medicine bottle, or find lost glasses.
We wanted to build something that doesn't just answer commands, but actually cares—an intelligent anchor in a confusing world.
What it does? Anchor is a multimodal, multilingual AI companion that acts as the "eyes, ears, and memory" for the elderly. It leverages Google's Gemini 3 Flash models to provide real-time assistance.
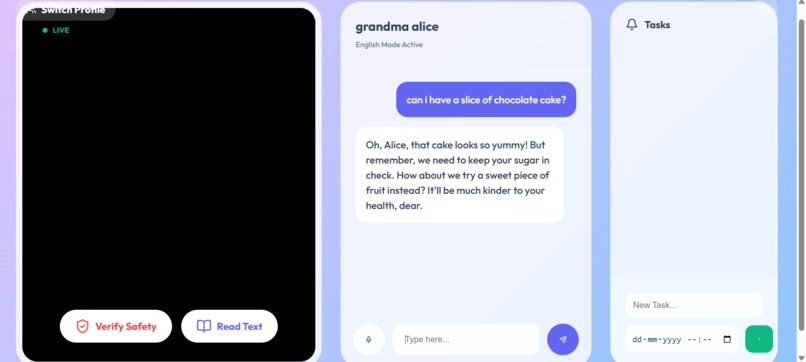
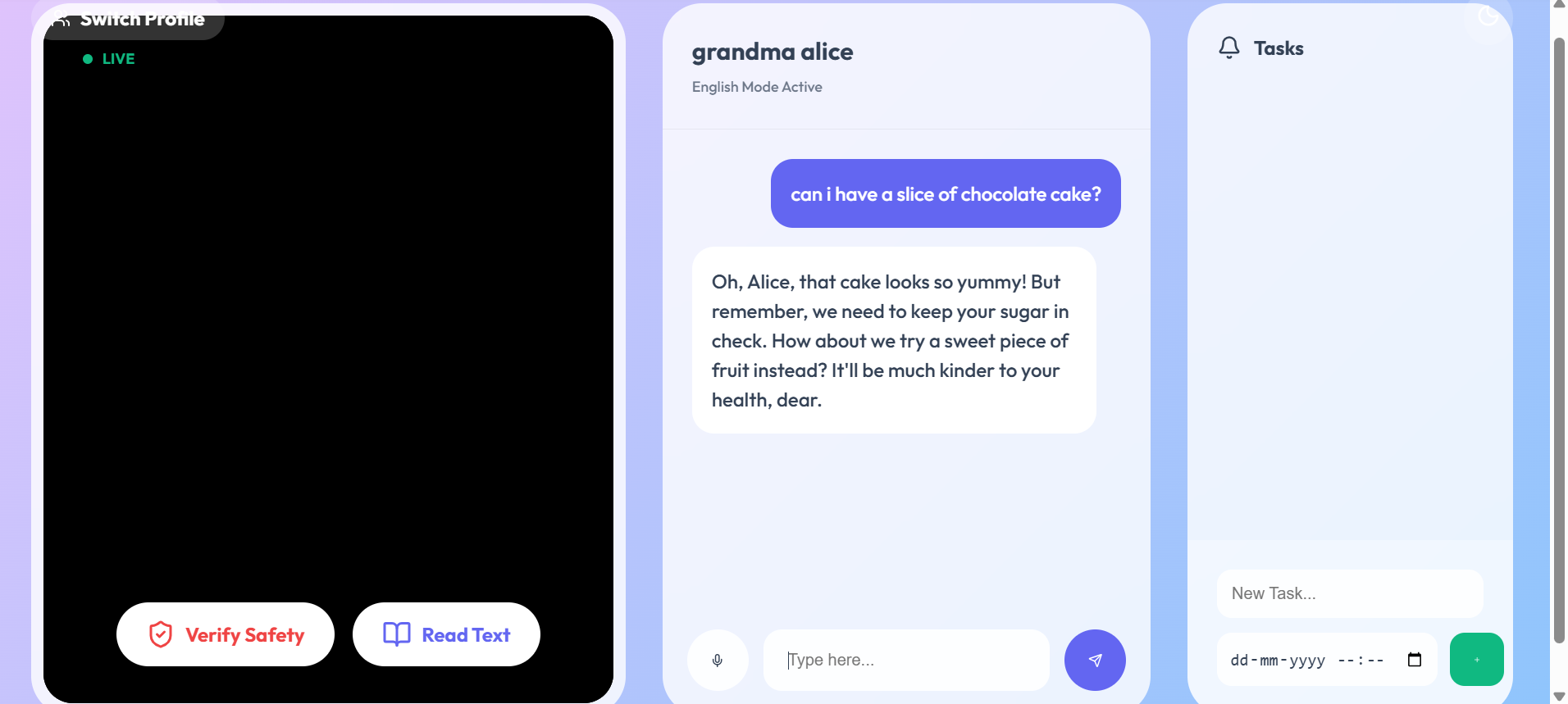
Multilingual Fluency: Anchor speaks the user's native language fluently. It switches instantly between English, Tamil, and Hindi, ensuring that critical health advice is never lost in translation. Visual Safety Checks: Using the camera, Anchor analyses the environment in real-time to identify physical hazards (like obstacles or slippery floors) and helps users locate lost items. Contextual Health Monitoring: It remembers the user's specific medical profile (e.g., Diabetes, Hypertension) and proactively warns them about dietary risks or missed medications. Empathetic Companionship :It adapts its persona—from a "caring grandchild" to a "strict nurse"—to provide emotional support and reduce isolation.
How we built it? We built Anchor using React (Vite) for a high-performance frontend, integrated directly with the Gemini 3 Flash Preview API for ultra-low latency reasoning.
The core intelligence relies on a Multimodal RAG (Retrieval-Augmented Generation) approach where we fuse real-time visual data, audio transcripts, and user medical context to generate a safe, context-aware response.
Challenges we ran into:
The "Model Not Found" Panic: Early in development, we faced critical API connectivity errors due to model versioning mismatches. We solved this by implementing a robust fallback mechanism that automatically switches between the Experimental and Stable Gemini models.
Language Hallucinations: The model initially struggled to stick to one language when medical terms were used (switching to English mid-sentence). We refined the system prompts to strictly enforce the target language output.
Git Security: We had to learn the hard way about securing API keys! We successfully migrated from hardcoded keys to a secure .env architecture to prevent key leakage on GitHub.
Technical Highlights:
Gemini 3 Flash Power: We utilized the Flash Preview model because, in elderly care, a 5-second delay can be dangerous. This model allows us to process video frames and generate safety warnings instantly. System Prompt Engineering: We designed a dynamic "Persona Injection" system that forces the model to adhere to strict safety protocols while maintaining a warm, human-like tone. Secure Deployment: We implemented robust security practices, migrating API keys to server-side environment variables to ensure user data privacy.
Accomplishments that we're proud of:
Real-Time Vision in the Browser: We successfully implemented a live camera feed that sends frames to Gemini and gets a safety analysis back in seconds—all running in a standard web browser. Seamless Language Switching: Seeing the AI switch from a medical analysis in English to a comforting reassurance in Tamil without losing context was a "magic moment" for our team. Deploying a Live Product: We went from a broken local prototype to a fully deployed application on Vercel that anyone can test right now.
What we learned
Speed is Safety: When building for the elderly, low latency isn't just a "nice to have"—it's a safety requirement. Empathy is an Engineering Constraint: We discovered that adjusting the "temperature" and persona of the model is just as important as the code itself. An AI that sounds like a robot will not be trusted by a grandmother. The Future is Multimodal: Text is not enough. To truly care for someone, an AI must be able to see what they see.
What's next for Anchor?
Voice-to-Voice Integration: We plan to implement Gemini's native audio capabilities for a completely hands-free experience. Smart Home Connectivity: Connecting Anchor to IoT devices so it can physically assist users (e.g., turning on lights if it sees a dark room). Wearable Support: bringing Anchor to smart glasses for always-on vision assistance.

Log in or sign up for Devpost to join the conversation.