-
-
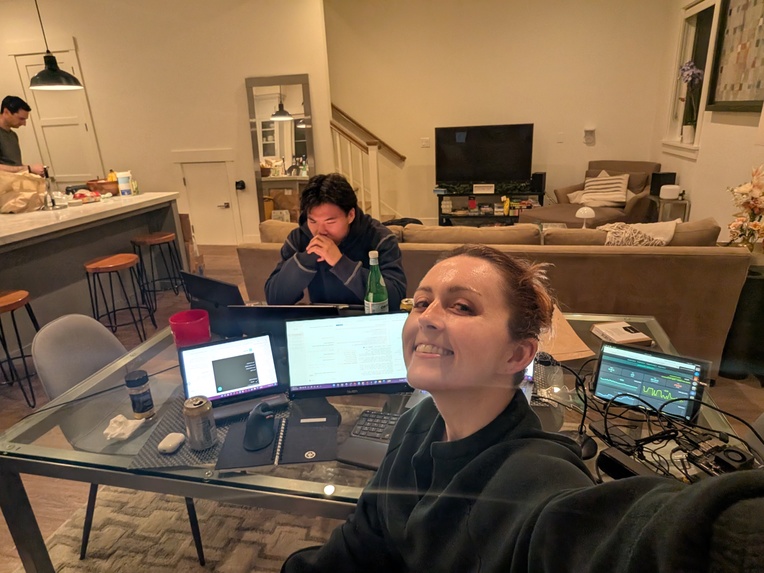
need more screens
-

need more wires
-
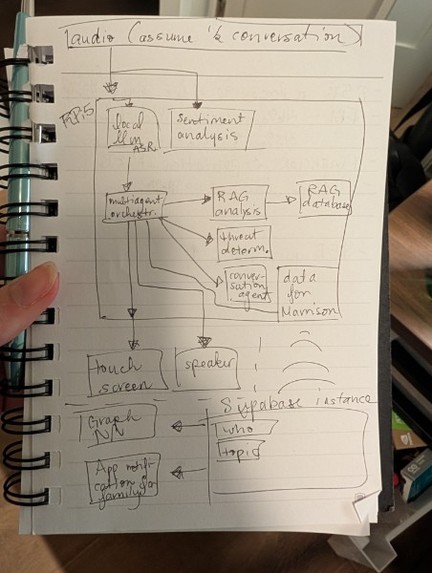
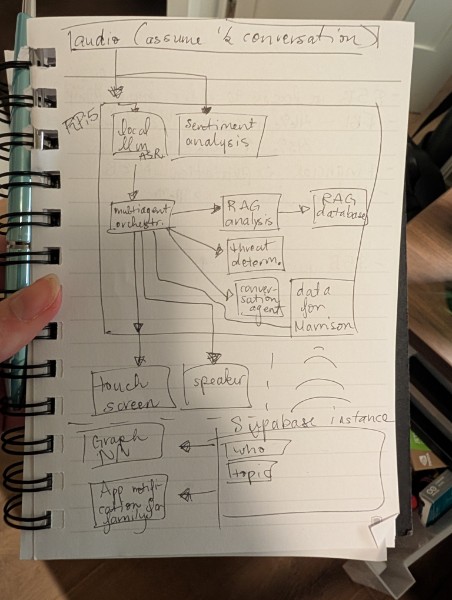
need more block diagrams
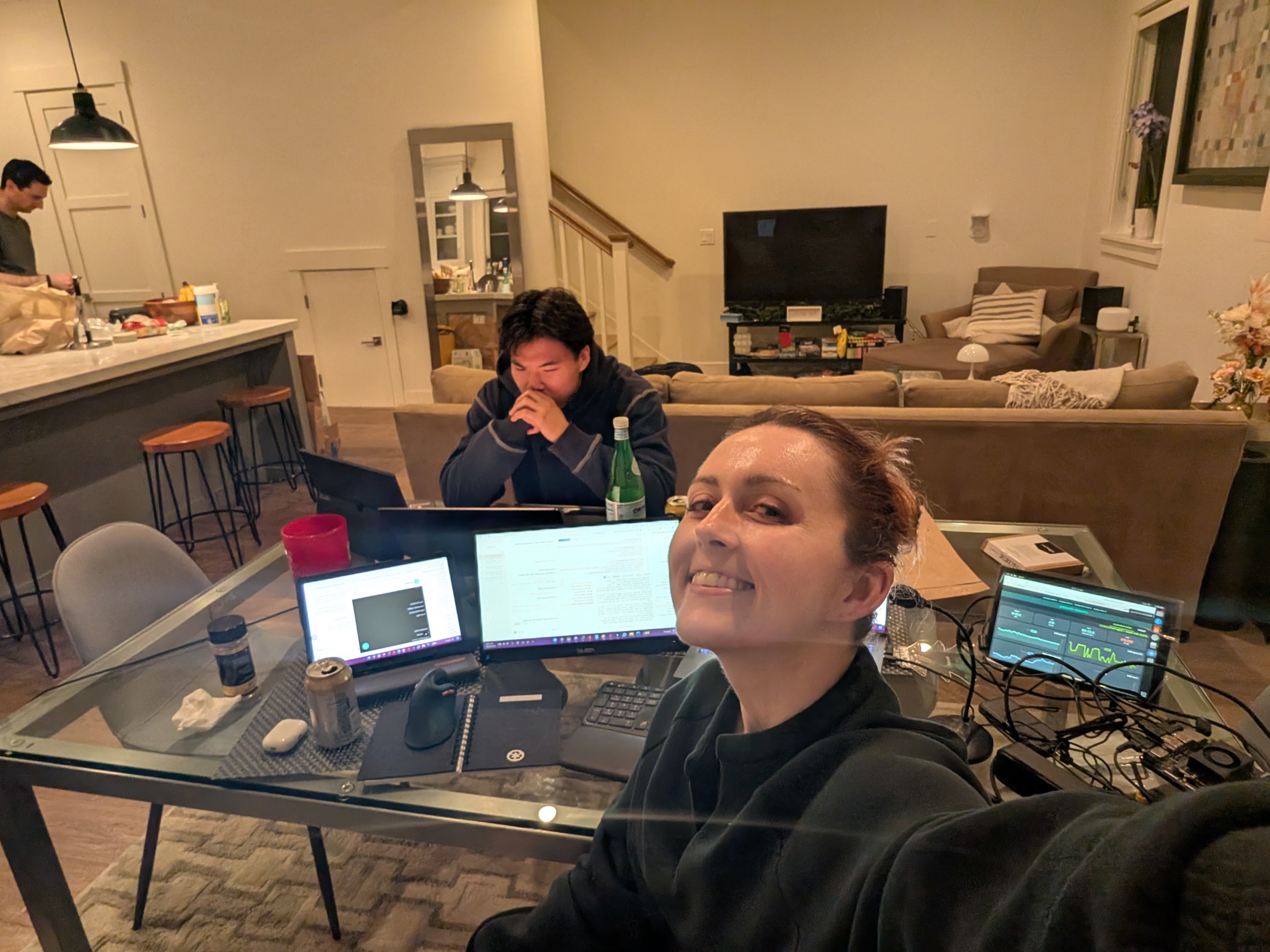

Inspiration
Phone scams are a uniquely high-pressure channel: the victim has to respond in the moment. In 2025, people over 60 reported $5B in losses across 150K complaints to the FBI. Elder abuse is also massively underreported, with one estimate suggesting only 1 in 24 cases are reported to authorities, in part due to victims' shame. As AI voice tools improve, phone-based scams get even more convincing, raising the stakes for real-time intervention for vulnerable populations.
We wanted to build something that prioritized users' dignity, that was immediately useful in a home after 36 hours, and that was hard enough to stretch us.
One-sentence value proposition
Anchor is an ambient phone-call safety layer that detects scam pressure in real time and prompts verification, without requiring an app, broadband, or surveillance.
What we built
Anchor is a physical device that sits near an older adult’s phone and listens only to their side of the conversation. It streams transcriptions and voice stress signals into an on-device risk pipeline and, when risk is high (e.g. "You need the code sent to my phone?"), interrupts with a calm voice prompt that encourages verification before money or credentials leave the home. We treated “no app, no training, no broadband” as a product requirement, not a nice-to-have. We also prioritized dignity: the goal is a real time auditory intervention, not shaming or constantly notifying family.
The edge device runs a five-stage ZeroMQ microservices pipeline: audio capture with real-time resampling (44.1kHz → 16kHz), Whisper small.en for speech-to-text (~700ms per 2.6s window), a two-tier threat detection system combining exact phrase matching against FBI/FTC scam databases with semantic similarity scoring via sentence-transformer embeddings (all-MiniLM-L6-v2), a quantized LLM (Qwen2.5-0.5B-Instruct, Q4 GGUF, ~500ms inference) for context-aware warning generation, and Piper neural TTS for natural voice output.
If the home has reliable internet, Anchor also supports Connected Mode: a cloud Independence Graph with a Heterogeneous Graph Transformer (HGT) that links events over time, because scams are rarely one-off interactions. The cloud backend scores entity-level risk via HGT plus rule fusion with calibrated thresholds. Connected Mode can alert a trusted loved one when a concerning pattern occurs. Risk scoring runs in-process in the API/worker; Modal is used for GPU-based GNN training (multi-seed structured synthetic sweeps), not live inference, and Claude is used to generate short risk narratives and plain-language explanations from graph motifs and timelines when configured.
Architecture (two layers)
Edge baseline (offline-first):
- Microphone capture → on-device speech recognition → stress/activation signals → tactic scoring
- Runs on NVIDIA Jetson Orin Nano (6-core ARM, 1024 CUDA cores, 8GB unified memory) with total pipeline memory footprint of ~2.1GB and power draw of ~6W
- Two-tier threat detection: Tier 1 uses regex/substring matching against 100+ known scam phrases for instant (<1ms) high-confidence triggers; Tier 2 computes cosine similarity between transcript embeddings and 50+ scam scenario descriptions
- Real-time loop ends in a voice intervention (not a text notification the elder won’t see)
Connected Mode (cloud graph):
- Converts “concerning event summaries” into nodes/edges in an Independence Graph
- Uses a Heterogeneous Graph Transformer (HGT) over the same schema (entity, session, event, utterance nodes; co_occurs, next_event, mentions edges) to score longitudinal risk
- Fuses rule-based motif scoring with calibrated HGT outputs (with optional conformal decision bands) to drive bounded escalation
- Generates bounded, action-oriented alerts to a trusted contact (help, not surveillance)
User flow (example: “bank security” scam)
1) Anchor is ambient: It’s a physical device by the older adult’s phone. It listens only to the older adult’s side. 2) On-device detection (Jetson): During a call, the Whisper model transcribes the elder's speech in real-time while the two-tier detection system analyzes each utterance—Tier 1 flags exact scam phrases instantly, Tier 2 computes semantic similarity against known manipulation patterns. Anchor detects risk signals from the older adult's words and voice state (e.g., "a verification code just came to my phone," "should I read it to you?" + rising stress/urgency). 3) Dignity-first interruption: When risk exceeds the intervention threshold, the Qwen LLM generates a context-specific warning (e.g., tailored to gift card vs. tech support vs. government impersonation tactics), and Piper TTS speaks it through the device's speaker. Anchor calmly inserts a “pause to verify” prompt:
- “Quick safety check—before sharing any code, let’s hang up and call the bank using the number on your card.” 4) Help without surveillance: If risk is severe or the older adult asks for help, Anchor sends a bounded alert to a designated loved one with suggested next steps (no raw audio sharing). 5) Connected Mode (cloud Independence Graph + HGT): With reliable internet, Anchor uploads bounded event summaries to the cloud, where an HGT scores entity-level risk across linked sessions (repeat contact, escalating urgency, isolation → payment pressure), and rule + model fusion determines escalation.
User-driven decisions, focusing on users' dignity first
We designed around real constraints: many older adults won’t maintain an app, and they don’t want to be surveilled. In Pew’s most recent broadband tracking (June 2025), only 70% of adults 65+ report having home broadband, and adoption drops to 54% in households earning under $30k, which is exactly the cohort for whom a single scam can be financially devastating (so Anchor can’t depend on always-on internet).
That led to:
- Offline-first safety path on the device
- One-sided listening as a privacy boundary
- Minimal disclosure: alerts focus on “what to do next,” not full call content
Roadblocks + what we changed
We had to trade off accuracy and latency across distributed hardware. Early on we were too ambitious with overlapping agents; they duplicated work and struggled to reach consensus under real-time constraints. On the edge side, we initially tried running a larger LLM (Qwen2.5-1.5B) which took 13+ seconds per inference. We decomposed the threat detection into 4 stages (described in the architecture section), and we found template-completion prompting with a 0.5B model reduced latency to ~500ms while preserving context-awareness. We also discovered that semantic similarity alone produced false positives on benign phrases like "gift card for grandson's birthday," so we added explicit benign context pattern matching as an override layer. We refocused on user needs and separated responsibilities cleanly through fast on-device detection + a cloud graph layer for longitudinal patterns. We also separated training (Modal GPU HGT runs, structured synthetic data sweeps) from in-process inference (rule + HGT fusion in the API/worker) to keep latency predictable and infrastructure simpler.
Privacy approach
We avoided building a monitoring tool. Anchor is designed around minimum necessary disclosure:
- No raw audio retention
- No full transcript sharing to third parties
- Only bounded summaries for concerning events (and only to a designated trusted contact)
What we’d do next
Finish the edge → cloud integration so the device can reliably stream event summaries into the Independence Graph and the GNN can improve longitudinal detection. We’d also expand scenario coverage and tune the intervention ladder to reduce false positives without humiliating the older adult.




Log in or sign up for Devpost to join the conversation.