Inspiration Dementia doesn't just take memory — it takes continuity. Families end up trying to keep a 24/7 watch they can't possibly sustain. Today's answer is a subscription camera streaming grainy frames to a cloud call center in another country: privacy gone, latency high, dignity zero.
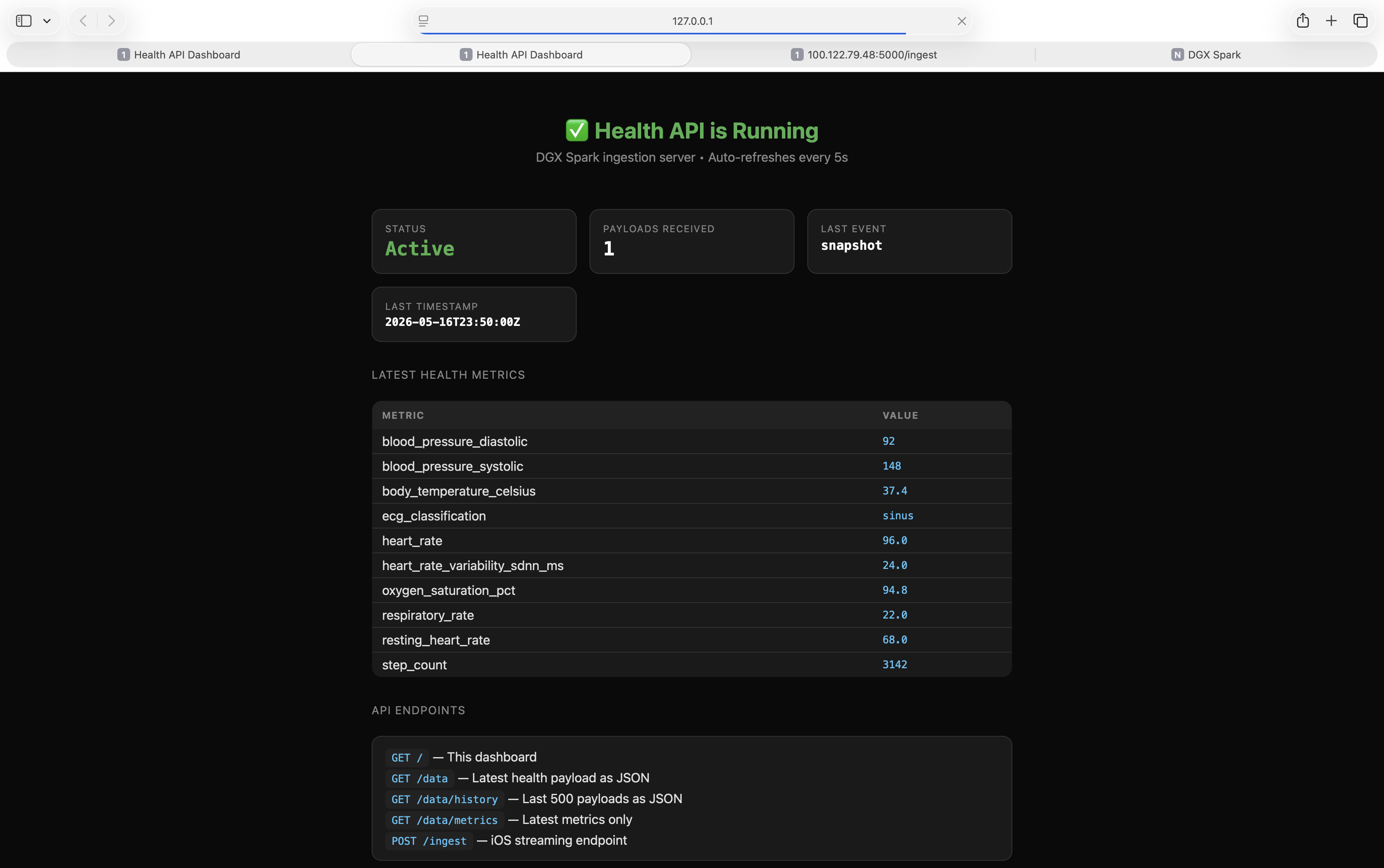
Then we put our hands on an ASUS Ascent GX10 — DGX Spark, GB10 silicon, 121 GB unified LPDDR5x memory. That's enough headroom to keep an entire dementia-care stack — perception, reasoning, kernel-enforced privacy, and the family loop — on a single living-room box.
We asked one question: what if nothing about the patient ever had to leave the room?
What it does Anchor sits in the patient's home with a small camera and an Apple Watch. Every three seconds:
Nemotron-3 Nano-Omni 30B reads the frame through a clinical-observer prompt — not a generic captioner — and emits structured JSON: scene, activity, clinical concern, and dementia tags (freezing, pacing, wandering, exit_seeking, confusion_posture, nighttime_disorientation, sundowning). The Apple Watch / HealthKit stream contributes heart rate, HRV, and SpO2 at 1 Hz against an 82-year-old-at-rest baseline, so behavior and biometrics tell one story instead of two. When the same tag fires in three or more consecutive frames — textbook repetitive dementia behavior — Anchor wakes Nemotron-3 Super-123B, which streams a five-section clinical paragraph. A bidirectional Telegram bot sends one calm message to the daughter. She can text back /room1, /room2, /status, /escalations and pull a live sitrep — not just receive pushes. NemoClaw's OpenShell kernel sandbox enforces what can leave the box. Landlock for filesystem, netns for network, seccomp for syscalls, an L7 proxy for credential injection. Privacy isn't promised — it's kernel-mediated. The operator console exposes six surfaces: /operator, /split (live camera + dignity silhouette + clinical evaluation), /family, /doctor, /livingroom, and /audit (every model call and kernel deny, append-only JSONL).
How we built it Hardware. One Spark. Both Nemotrons co-resident in the unified pool with KV cache pinned small (num_ctx = 8192): 27 GB for Nano-Omni + 86 GB for Super-123B + ~6 GB KV cache fits inside the 121 GB pool with headroom for the web stack.
Inference pacing. Display and inference are decoupled — the video shouldn't lag because the model is slow. Display ticks at 5 Hz; perception fires every 30 ticks (~6 s); biometrics every 5 ticks (~1 s). Speculative decoding on the Super-123B stream cuts wall-clock token latency so the family update lands in seconds, not a minute.
Perception loop. The Nano-Omni client posts JPEGs to Ollama's /api/chat with format=json and think=False. The system prompt frames the model as a clinical observer with explicit decision rules — standing-not-engaged must be tagged as one of freezing, pacing, wandering, exit-seeking, or confusion-posture. To survive sampling drift, a deterministic caption-to-tag alignment pass guarantees that if the caption mentions "freezing," the freezing tag appears in the anomaly list.
Reasoning loop. Super-123B streams a five-section paragraph (current state, trajectory, risk, next action, family note) directly to /doctor, /reasoning, and Telegram.
Sandbox loop. Every tool dispatch passes through one chokepoint that consults the policy YAML and emits an audit row. The OpenShell L7 proxy validates HTTP egress — only Ollama on localhost, Telegram's API, and the local web port are reachable. Anchor is registered as a NemoClaw agent (manifest, policy-additions, preset, start.sh) and shows up in nemoclaw list next to NVIDIA's reference hermes and openclaw.
Family loop. The Telegram listener long-polls getUpdates; commands are dispatched only for the authorized chat ID loaded from .env. Outbound alerts always traverse the same policy-gated dispatcher so they show up in the audit log as receipted events.
Challenges we ran into Three vision models, two graveyards. Qwen3-VL hung Ollama in every variant; Cosmos-Reason crashed llama.cpp when paired with a separate mmproj. We landed on Nemotron-3 Nano-Omni. Generic captioning death spiral. Out of the box, Nemotron drifted into things like "A person stands with hands behind their head while another person sits nearby." Useless. We rewrote the prompt as a clinical-observer brief and added deterministic keyword-to-tag alignment so the tags can't disagree with the caption. DNS hijack. Our hackathon network resolved api.telegram.org to the wrong IP and the request timed out. Fixed with a /etc/hosts override. Telegram parse_mode booby trap. Markdown blew up on underscores in URLs. Switched to HTML parse mode with a small escape helper. Phone spam. The biometric autoalert had a 6-second cooldown — the judge would've gotten ten buzzes in their first minute. Added a master kill-switch and routed every autonomous trigger through one dispatch so cooldowns can't be bypassed. 180-second cold start. Nano-Omni warmup blocked the heartbeat. Moved warmup to a background task; heartbeat now boots in ~2 seconds. Audit log drowning. The 1 Hz biometric tool wrote three audit rows per second. Added a quiet=True flag — denials and errors still log, routine successes don't. Accomplishments that we're proud of All four NemoClaw isolation layers active and kernel-enforced, with the boundary tests visible live in the /probe view. End-to-end closed loop in 60 seconds on stage: camera, Nemotron, tags, repetition detector, policy gate, Telegram, daughter's phone — every step receipted in the audit log. Two Nemotrons co-resident on one Spark. The larger model alone is 86 GB. A bidirectional family bot, not just a notifier. The daughter can pull a sitrep at 3 AM without waking anyone. Decoupled display from inference cadence so the live stream stays smooth even while a 30B vision model is mid-call. An honest dignity filter — silhouette plus caption only, no faces, no clothing, anatomy-neutral language by prompt construction. What we learned Prompt engineering beats model swapping for clinical tasks. The same Nemotron checkpoint went from useless to clinical-grade with a rewritten system prompt and a small deterministic alignment pass. Display cadence is not inference cadence. Conflating them is the fastest way to make on-device AI feel laggy. Kernel-level privacy is more credible than policy-level privacy. "We promise not to send it" is a sentence; Landlock denying a syscall is a receipt. Unified memory changes what fits in "edge." A 123B reasoning model running next to a 30B vision model on one box is now a tractable target, not a server-room fantasy. Audit logs are pitch material. Showing the judge a JSONL row that says policy_decision · telegram_alert · allowed was more persuasive than any slide. What's next for Anchor Move Anchor fully inside the OpenShell container so even the web process is kernel-confined, not just its tool calls. Replace the mock biometric stream with real Apple Watch / HealthKit ingest — the API surface is already wired. More scenarios: medication adherence, fall recovery, reminiscence playback as a calming intervention. Multi-patient households (the persona registry already supports it). Caregiver voice intent. Whisper is wired; the next step is letting the family talk to Anchor, not just text. Tune the speculative-decoding draft model for our prompt distribution. Doctor handoff: ship the structured clinical summary into an EHR via a FHIR shim.
Built With
- asus-ascent-gx10
- asyncio
- bash
- docker
- ffmpeg
- flask
- flask-sock
- gb10
- getusermedia
- healthkit
- html
- httpx
- javascript
- jinja
- jsonl
- landlock
- makefile
- nemoclaw
- nemotron-3-nano-omni-30b
- nemotron-3-super-123b
- netns
- nvidia-dgx-spark
- ollama
- openshell
- pillow
- python
- seccomp
- smtp
- speculative-decoding
- sqlite
- tailscale
- telegram-bot-api
- websocket
- whisper
- yaml

Log in or sign up for Devpost to join the conversation.